达梦数据库体系结构描述
一、背景
常见的主流关系型数据库 oracle、mysql、postgresql,随着信创国产化软件发展,某些项目对于新创安全等级有一定的要求。下面我将简单介绍一下我了解的国产数据库软件-达梦数据库
二、不同版本的区别
根据不同的应用需求与配置, DM 提供了多种不同的产品系列
-
DM Standard Edition标准版提供了数据库管理、安全管理、开发支持等所需的基本功能,对于资源的使用有一定的限制,可以升级到企业版。
-
DM Enterprise Edition企业版DM 企业版支持
OLTP、OLAP,PB级海量数据分析,大量的并发用户访问,并为高端应用提供了数据复制、数据守护等高可靠性、高性能的数据管理能力,完全能够支撑各类企业应用。 -
DM Security Edition安全版DM 安全版拥有企业版的所有功能,加强了其安全特性,引入强制访问控制、四权分立、多种身份验证、加密存储、审计控制等功能。
详情请见:版本区别 | 达梦技术文档
三、体系结构
3.1 单机版安装部署
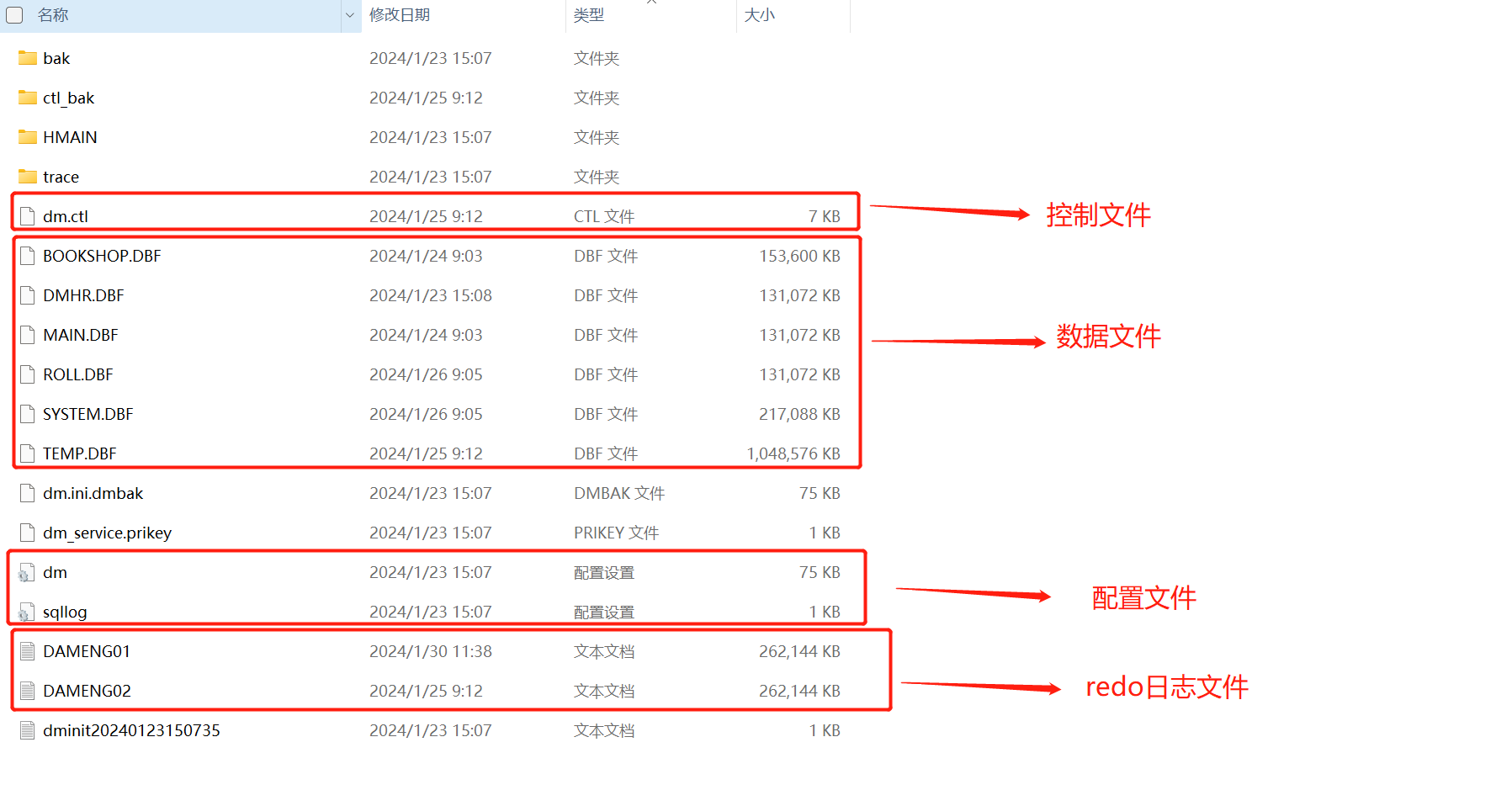
3.2 数据库目录结构介绍
数据库软件默认安装路径是 /home/dmdba/dmdbms,(安装时可自定义,等同于 PG 的 $PGHOME)
bash
[dmdba@localhost dmdbms]$ ll /home/dmdba/dmdbms
总用量 44
drwxr-xr-x 9 dmdba dmdba 8192 4月 22 15:15 bin
drwxr-xr-x 2 dmdba dmdba 30 4月 22 14:55 bin2
drwxr-xr-x 3 dmdba dmdba 19 4月 22 14:55 desktop
drwxr-xr-x 2 dmdba dmdba 4096 4月 22 14:55 doc
drwxr-xr-x 13 dmdba dmdba 149 4月 22 14:55 drivers
drwxr-xr-x 2 dmdba dmdba 4096 4月 22 14:55 include
drwxr-xr-x 2 dmdba dmdba 94 4月 22 14:55 jar
drwxr-xr-x 6 dmdba dmdba 150 4月 22 14:55 jdk
-rwxr-xr-x 1 dmdba dmdba 1143 11月 7 2024 license_chs.txt
-rwxr-xr-x 1 dmdba dmdba 1135 11月 7 2024 license_cht.txt
-rwxr-xr-x 1 dmdba dmdba 1071 4月 21 2023 license_en.txt
drwxr-xr-x 2 dmdba dmdba 4096 4月 22 17:14 log
drwxr-xr-x 6 dmdba dmdba 92 4月 22 14:55 samples
drwxr-xr-x 3 dmdba dmdba 37 4月 22 14:55 script
drwxr-xr-x 10 dmdba dmdba 4096 4月 22 22:01 tool
drwxr-xr-x 3 dmdba dmdba 97 4月 22 14:55 uninstall
-rwxr-xr-x 1 dmdba dmdba 2292 4月 22 14:55 uninstall.sh- bin :存放
disql、dminit、dmrman等可执行程序 - desktop/icons:数据库工具桌面图标
- doc:数据库官方用户手册
- drivers:数据库连接驱动文件
- log:数据库及各类工具运行日志
- samples:各类配置文件示例
- script/root:数据库服务注册、注销脚本工具
- tool :
manager、dbca等图形化管理工具 - uninstall:数据库卸载相关脚本
- web :
DEM运维平台web环境
数据库实例路径:/dmdata/data/DAMENG(初始化可自定义,等同于 PG 的 $PGDATA)
3.3 体系结构
3.3.1 PostgreSQL 数据库体系结构
生产环境上 PG 数据库集群架构
数据库是由实例和数据库文件组成的,实例由内存和进程组成,数据库文件就是数据文件、日志文件、配置文件、参数文件等。
生产环境上,支持 OLTP 业务超高并发、负载均衡、高可用的数据库架构方案。
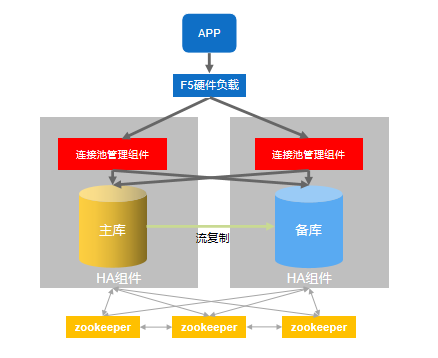
描述:
数据库 HA 组件一般是 patroni,支持数据库的高可用功能,patroni 的元数据信息存放在 zookeeper 集群,连接池组件实现负载均衡和读写分离,F5 硬件负载负责当把客户端的请求分发到多个连接池上。
对于追求极致性能的系统也会涉及分区表甚至是二级分区表。
体系结构
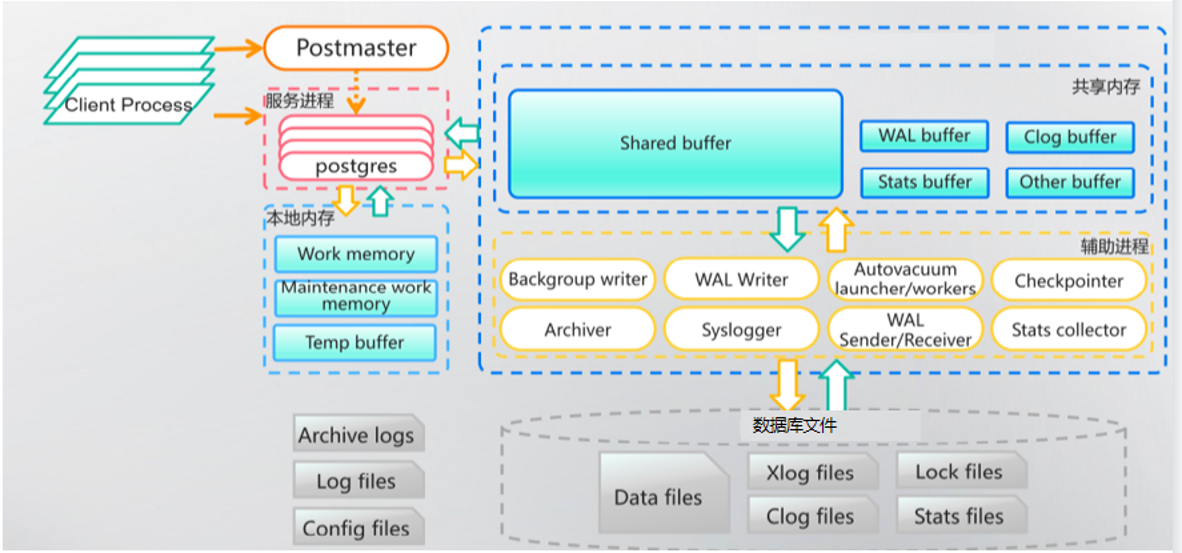
PostgreSQL 数据库是多进程的架构,每一个客户连接都有一个服务进程为其服务,也有共享内存,这一点与 Oracle 数据库是相似的。
运行中的数据库实例是由服务进程、辅助进程、集群管理等进程,及数据、配置、日志等文件构成,进程操作文件、文件支撑进程,共同保障服务稳定。
当用户客户端的请求被 postmaster 进程监听到后,会创建一个 postgres 服务进程,每个服务进程都会分配一定的 work memory 内存,所以 work memory 的大小与 SQL 语句的执行效率有很大的关系。
逻辑结构
PostgreSQL 的逻辑结构分为实例、数据库、schema、对象(对象包括表、索引、视图、序列、函数等)
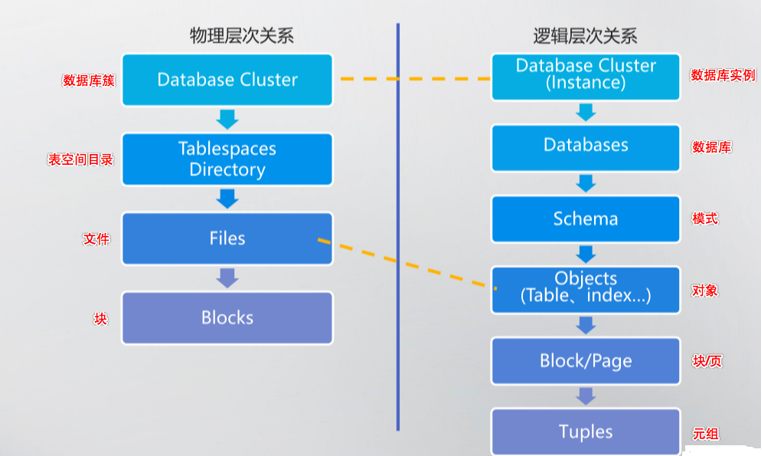
物理结构
在 PostgreSQL 中,将保存在磁盘中的块称为 Page,而将内存中的块称为 Buffer。表和索引称为 Relation,行称为 Tuple 元组。
数据的读写以 Page 为单位,每个 Page 默认大小为 8kB,在编译 PostgreSQL 时指定的 BLCKSZ 大小决定 Page 的大小。
表文件由多个 BLCKSZ 字节大小的 Page 组成,每个 Page 含若干 Tuple。对于 I/O 性能较好的硬件,且以分析为主的数据库,适当增加 BLCKSZ 大小可以小幅提升数据库性能。
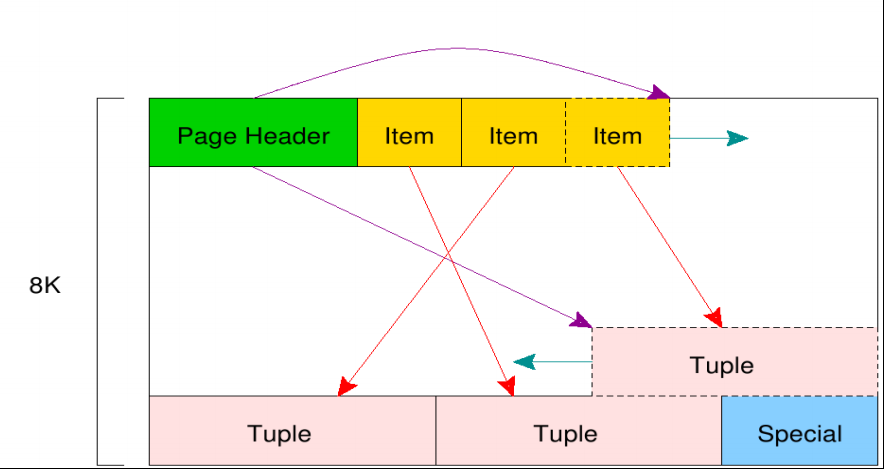
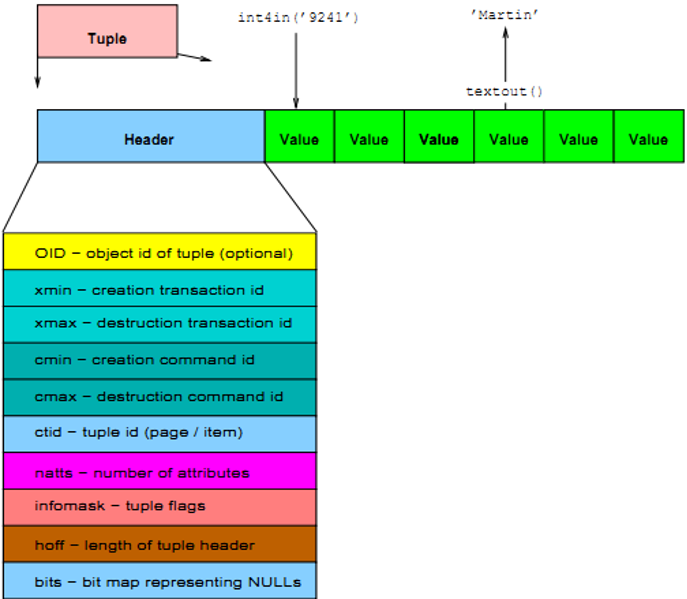
元组
每个 Tuple 含两部分内容,一部分为 HeapTupleHeader,用来保存 Tuple 的元信息(如图 5-4 所示),包含该 Tuple 的 OID、xmin、cmin;另一部分为用户数据,用来保存 Tuple 的数据。
单实例数据库的限制
Limit(限制项) |
Value(数值) |
|---|---|
Maximum Database Size(最大数据库大小) |
Unlimited(无限制) |
Maximum Table Size(最大表大小) |
32 TB |
Maximum Row Size(最大行大小) |
1.6 TB |
Maximum Field Size(最大字段大小) |
1 GB |
Maximum Rows / Table(表最大行数) |
Unlimited(无限制) |
Maximum Columns / Table(表最大列数) |
250-1600 |
Maximum Indexes / Table(表最大索引数) |
Unlimited(无限制 |
3.3.2 DM 达梦数据库体系结构
逻辑结构
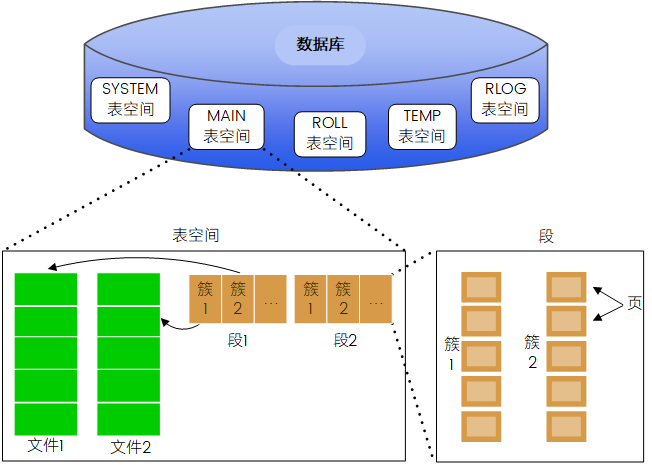
- 数据库由一个或多个表空间组成;
- 每个表空间对应一个或多个文件;
- 每个数据文件由一个或多个簇组成;
- 段是簇的上级逻辑单元,一个段可以跨多个数据文件;
- 簇由磁盘上连续的页组成,一个簇总是在一个数据文件中;
- 页是数据库中最小的分配单元,也是数据库中使用的最小的
IO单元
数据库表中的每一行是一条记录,记录不能跨页存储,这样记录的长度就受到数据页大小的限制,DM 规定每条记录的总长度不能超过页面大小的一半,页的默认大小是 8kb,簇的默认大小 16 个连续的页,段就是具体的数据库对象,比如:回滚段,索引段...
物理存储结构
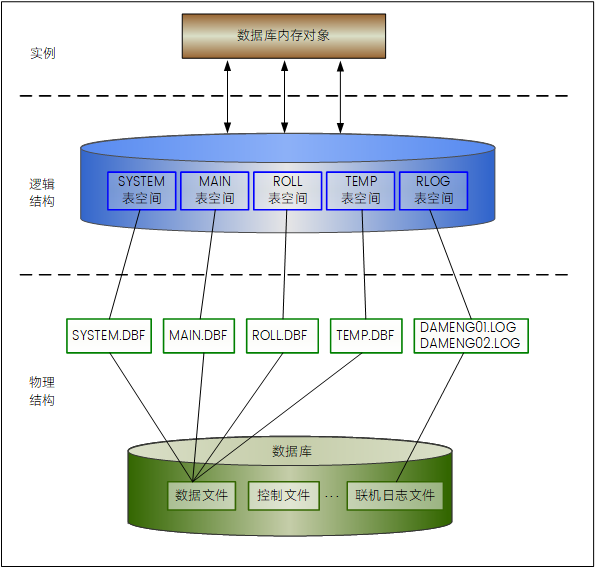
内存结构
DM 数据库管理系统的内存结构主要包括内存池、缓冲区、排序区、哈希区等。根据系统中子模块的不同功能,对内存进行了上述划分,并采用了不同的管理模式。
动态视图 V$MEM_POOL 详细记录了当前系统中所有的内存池的状态,包括内存的使用情况。
共享池
数据库为避免频繁向操作系统申请、释放内存,减少线程切换并提升运行效率,会预先向系统申请大块内存作为共享内存池。业务运行所需的零散内存,均从内存池中分配与回收,不再频繁和操作系统交互。共享池大小的参数为 MEMORY_POOL,MEMORY_EXTENT_SIZE 指定了共享内存池每次扩展的大小,参数 MEMORY_TARGET 则指定了共享内存池扩展到超过该值后,空闲时会收缩到的大小。
当其他的内存运行区不够用的时候,会向共享内存池(主内存池)申请分配内存。
数据缓冲区
数据缓冲区是达梦数据库读写磁盘数据页的核心内存区域,参数配置需合理:设置过小会降低缓存命中率、增加磁盘 IO;设置过大则会占用系统内存,引发资源不足问题。
数据库启动时,会按配置申请连续内存,格式化为标准数据页并纳入自由链管理。缓冲区通过自由链、LRU 链、脏链三类链表,分别管控未使用、已使用、已修改的数据页。
LRU 链按访问时序排序缓存页,自由链耗尽时,优先淘汰长期未访问页面,减少不必要磁盘 IO。
日志缓冲区
日志缓冲区是临时存放重做日志的内存空间,数据库先将日志暂存于此,避免即时磁盘 IO 影响性能。
重做日志因格式、连续写入特性及更高 IO 优先级,需独立缓冲区,不与数据缓冲区共用。
日志缓冲区内存取自共享内存池,可通过 RLOG_BUF_SIZE 参数配置大小。
字典缓冲区
字典缓冲区用于缓存模式、表、列、触发器等数据字典信息,字典访问效率直接决定数据库操作性能。
DM8 按需加载部分字典信息至该缓冲区,通过 LRU 算法管理;由 DICT_BUF_SIZE 控制大小,默认 50MB。
缓冲区过大会浪费内存,过小则频繁触发数据淘汰。
因字典数据存在访问热点,按需加载不影响常规性能;但访问海量分区表时,需适当调大该参数。
排序区
哈希区
SQL 缓冲区
SQL 缓冲区为 SQL 执行提供内存,缓存执行计划、语句与结果集。
- 计划重用:缓存重复
SQL及执行计划,提升执行效率、增加内存开销;由USE_PLN_POOL开关控制,CACHE_POOL_SIZE配置缓冲区大小。 - 服务端结果集缓存:需同时开启
RS_CAN_CACHE与计划重用才可生效。 - 客户端结果集缓存:在
dm_svc.conf配置启用、容量、缓存校验周期,配合服务端CLT_CACHE_TABLES指定缓存表;FIRST_ROWS限制可缓存结果集行数。
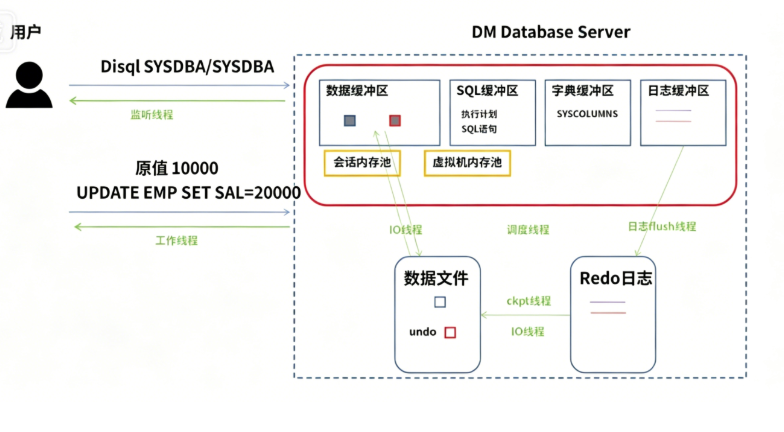
DM 线程结构
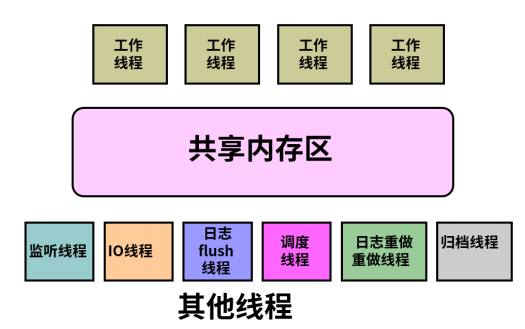
DM 服务器使用"对称服务器构架"的单进程、多线程结构。这种对称服务器构架在有效地利用了系统资源的同时又提供了较高的可伸缩性能,这里所指的线程即为操作系统的线程。服务器在运行时由各种内存数据结构和一系列的线程组成,线程分为多种类型,不同类型的线程完成不同的任务。线程通过一定的同步机制对数据结构进行并发访问和处理,以完成客户提交的各种任务。DM 数据库服务器是共享的服务器,允许多个用户连接到同一个服务器上,服务器进程称为共享服务器进程。
DM 进程中主要包括监听线程、IO 线程、工作线程、调度线程、日志线程等,以下分别对它们进行介绍。
bash
查看数据库对应的线程:
[dmdba@KylinDCA03 DM]$ ps -T -p 1750
PID SPID TTY TIME CMD
1750 1750 ? 00:00:01 dmserver
1750 1877 ? 00:00:00 dm_quit_thd常规动态试图
sql
select * from V$process; -- 查看数据库进程信息
select * from V$threads; -- 查看数据库所有线程信息
select * from V$sessions; -- 查看会话及对应会话线程ID监听线程(dm_lsnr_thd)
持续监听服务端口,接收客户端连接请求,创建会话线程并将任务放入工作队列。
会话线程(dm_sql_thd)
独立对应每一个数据库会话,负责处理当前会话的各类 SQL 请求与交互操作。
工作线程(dm_tskwrk_thd、dm_wrkgrp_thd)
数据库核心业务线程,默认 16 个,负责消费任务队列,处理各类数据库核心业务请求。
IO 线程(dm_io_thd)
负责数据文件读写,完成物理读、脏页写入、检查点数据落盘等磁盘 IO 操作。
日志刷新线程(dm_redolog_thd)
事务提交或触发检查点时,将日志缓冲区的 REDO 日志刷盘写入联机日志文件。
日志归档线程(dm_rsyswrk_thd)
读取联机重做日志,按照归档策略完成日志归档,保障数据备份与恢复能力。
日志重做线程
数据库故障重启后,解析 REDO 日志,并行执行日志重做,完成实例故障恢复。
调度线程(dm_sched_thd)
后台定时调度管理,负责缓存清理、缓冲区动态伸缩、自动检查点、会话超时检测等。
检查点线程(dm_chkpnt_thd)
定期触发检查点事件,协调落盘机制,批量将内存脏页持久化至磁盘,缩短故障恢复时间。
SQL 语句执行过程
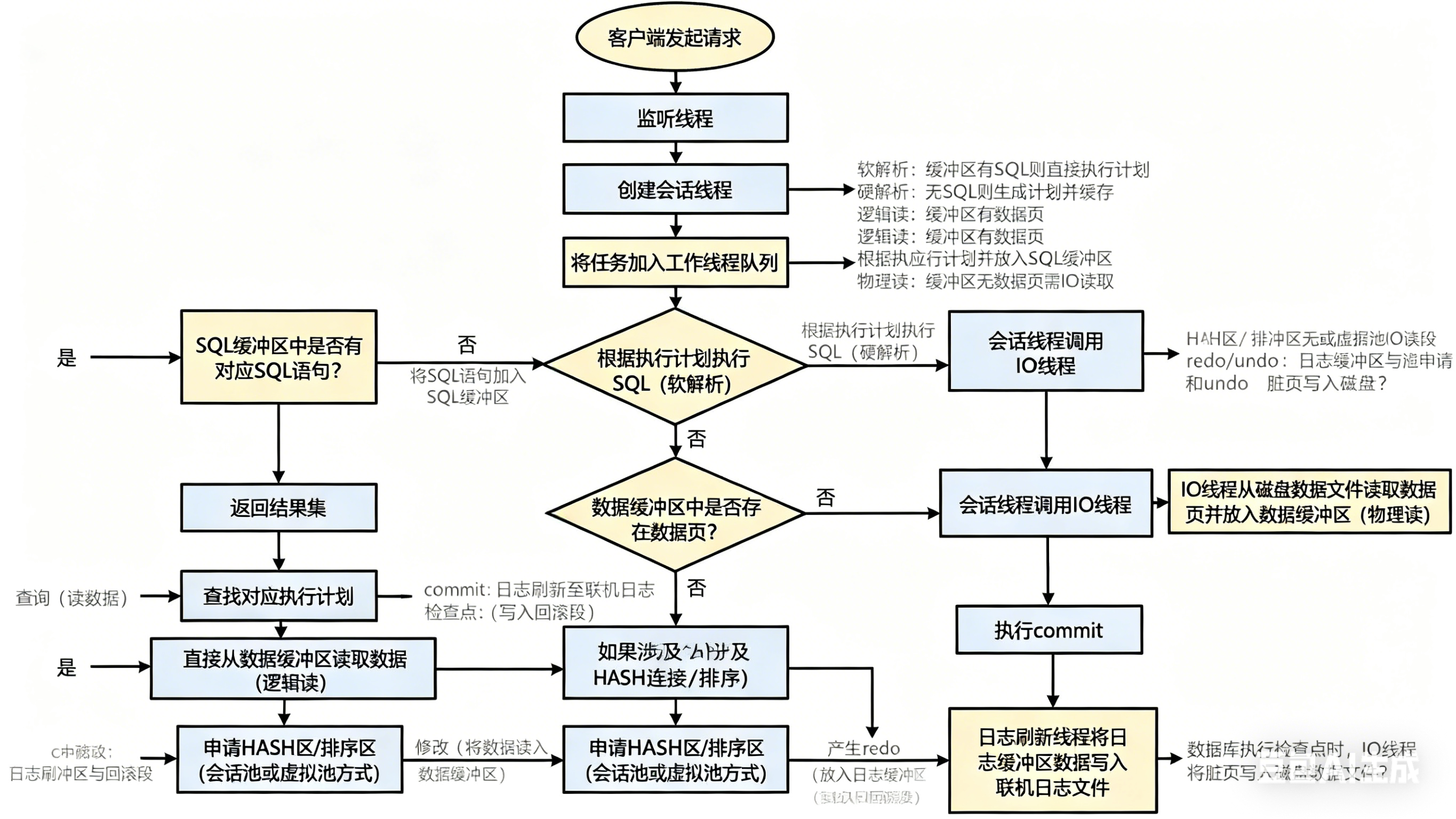
一个 sql 的执行过程:
当客户端发起请求,首先到达监听线程,监听线程创建一个会话线程,将任务加入工作线程队列。
Sql 语法语义权限解析(字典缓冲区,语法语义校验,权限校验):
首先在 sql 缓冲区中查找是否有对应的 sql 语句,
如果找到,再查找对应的执行计划,找到执行计划,根据执行计划执行 sql,这个过程称为软解析;
如果 sql 缓冲区中没有找到对应 sql 语句,会将该 sql 语句加入 sql 缓冲区,并生成对应执行计划,执行计划放入 sql 缓冲区,根据执行计划执行 sql 语句,返回结果集,这个过程称为硬解析)。
从系统性能提升来说,要减少硬解析。
查询(读数据,数据缓冲区,如果数据缓冲区中存在数据页,则直接从数据缓冲区中读取数据,称为逻辑读;如果数据缓冲区中不存在该数据页,会话线程调用 IO 线程,IO 线程从磁盘上的数据文件中读取数据页并放入到数据缓冲区,称为物理读。从系统性能考虑,应减少物理读,提高逻辑读),如果查询涉及 HASH 连接等,会占用 HASH 区,如果涉及到排序,少量的数据排序(内存中能排下的)则占用排序区,HASH 区和排序区以会话池或虚拟池的方式申请。
修改(将数据读入数据缓冲区,此过程同上,在数据缓冲区中修改,修改会产生 redo 和 undo,redo 放在日志缓冲区中,undo 写入回滚段; 修改完成后,执行 commit,日志刷新线程将日志缓冲区中的数据写入联机日志文件;当数据库执行检查点时,IO 线程会将脏页写入磁盘数据文件。
四、模式对象管理
4.1 PostgreSQL 用户与模式
PostgreSQL 的基于角色的访问控制机制,通过角色关联用户与权限,简化权限管理。给同权限用户授权时,可先授权限给角色再将角色授给用户;修改权限只需改角色权限,其下用户权限自动更新对于 PostgreSQL 来说用户和角色是完全相同的两个对象,拥有 LOGIN 权限的角色可以认为是一个用户。
4.2 DM 达梦用户与模式
模式与用户之间的关系:
模式定义:模式是一个特定的对象集合,在概念上可将其看作是包含表、视图、索引等若干对象的对象集
模式对象:表、视图、约束、索引、序列、触发器、存储过程/函数、包、同义词、类、域
模式与用户之间的关系:当系统建立一个用户时,会自动生成一个同名的模式,用户还可以建立其他模式,DM 中用户和模式是一对多的关系,一个用户可以拥有多个模式,一个模式仅能归属于一个用户。
Oracle 中用户和模式是一对一的关系。
sql
--查询模式和用户的对应关系:
select a.id scheid, a.name schename, b.id userid, b.name username
from SYS.SYSOBJECTS a, SYS.SYSOBJECTS b
where a."TYPE$" = 'SCH' and a.pid = b.id;
create schema hrtest01 AUTHORIZATION HRTEST;
create table hrtest01.t_test(id int, name varchar(20));
--查看当前模式和当前用户
select sys_context('USERENV','CURRENT_SCHEMA');
select sys_context('USERENV','CURRENT_USER'); 或 select user;
--切换模式(仅对当前会话生效)
set SCHEMA dmhr;五、多版本并发控制
5.1PostgreSQL多版本并发控制MVCC
PostgreSQL 的并发控制旨在让多个会话高效访问同一数据并维护数据完整性。它通过多版本并发控制(MVCC),让每个事务看到事务开始前的数据快照,避免数据不一致 。同时,还借助表行级锁和会话锁机制,解决MVCC 无法覆盖的并发情况(mvcc主要是解决读-写冲突,减少锁争用,无法解决写-写冲突,需要引入锁机制控制并发)。
多版本并发控制的例子,如表 7-11 所示
| 事务 T1 | 事务 T2 | 表 A 的变化 | 事务 T2 的查询结果 |
|---|---|---|---|
| BEGIN | SELECT * FROM A; | A | A |
| UPDATE | A→AA | ||
| SELECT * FROM A; | A | ||
| COMMIT | |||
| SELECT * FROM A; | AA |
使用多版本并发控制的主要优点是对检索(读取)数据的锁请求与写数据的锁请求并不冲突,所以读不会阻塞写,而写也从不阻塞读。这就极大地提高了并发处理能力。
在 PostgreSQL 系统中,更新数据时(DML操作)并不是用新值覆盖旧值,而是在表中另开辟一片空间来存放新的元组,让新值与旧值同时存放在数据库中,通过设置一些参数,让系统识别它们。一个新元组被保存在磁盘中的时候新元组的 t_ctid 初始化为自身存储位置,元组更新后 t_ctid 指向新元组;判断元组是否为最新版本,可通过其 xmax 是否为空或 t_ctid 是否指向自身来确定;要找元组最新版本(只能说是元组的最新版本,不一定对其他事务可见,还需要去判断 t_infomask 中的信息),遍历 t_ctid 构成的链表即可
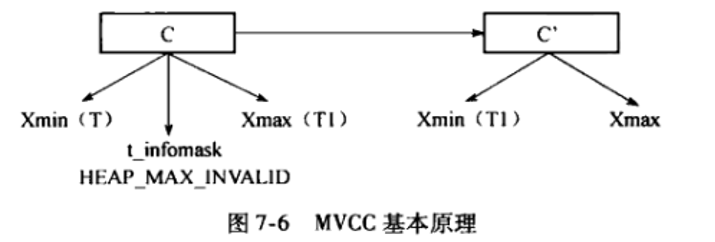
MVCC 的基本原理如上图所示:
有两个并发执行的事务 T1、T2,T1 将元组 C 更新为 C',但 T1 没有提交,此时假如事务 T2 要对该元组进行查询,它会通过 C 和 C' 中的头信息中的 Xmin 和 Xmax 及 t_infomask 来判断出 C 为其有效版本,而 C' 为无效版本。
5.2 DM达梦多版本并发控制
多版本并发控制(MVCC)可以确保数据库的读操作与写操作不会相互阻塞,大幅度提升数据库的并发度以及使用体验,大多数主流商用数据库管理系统都实现了 MVCC。DM 的多版本并发控制实现策略是:数据页中只保留物理记录的最新版本数据,通过回滚记录维护数据的历史版本。
每一条物理记录中包含了两个字段:TID 和 RPTR。TID 保存修改记录的事务号,RPTR 保存回滚段中上一个版本回滚记录的物理地址。插入、删除和更新物理记录时,RPTR 指向操作生成的回滚记录的物理地址。
回滚记录与物理记录一样,也包含了 TID 和 RPTR 这两个字段。TID 保存产生回滚记录时物理记录上的 TID 值(也就是上一个版本的事务号),RPTR 保存回滚段中上一个版本回滚记录的物理地址。
每一条记录(物理记录或回滚记录)代表一个版本。如下图所示:
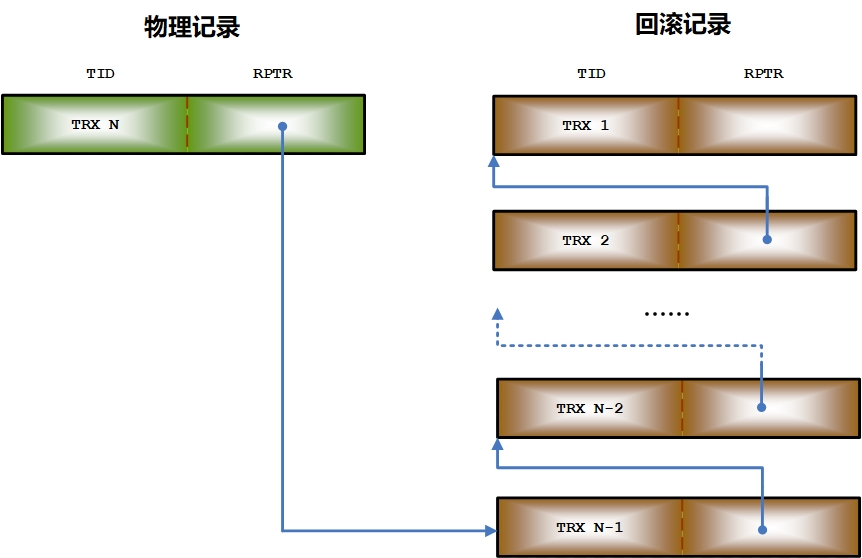
图4.1 各版本之间的关系
如何找到对当前事务可见的特定版本数据,进行可见性判断,是 DM 实现多版本并发控制的关键。根据事务隔离级别的不同,在事务启动时(串行化),或者语句执行时(读提交),收集这一时刻所有活动事务,并记录系统中即将产生的事务号 NEXT_TID。DM 多版本并发控制可见性原则:
- 物理记录 TID 等于当前事务号,说明是本事务修改的物理记录,物理记录可见
- 物理记录 TID 不在活动事务表中,并且 TID 小于 NEXT_TID,物理记录可见
- 物理记录的 TID 包含在活动事务表中,或者 TID>=NEXT_TID,物理记录不可见