文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 加载自带数据](#2.1 加载自带数据)
-
- [2.1.1 查看MNIST数据集](#2.1.1 查看MNIST数据集)
- [2.1.2 加载MNIST数据集](#2.1.2 加载MNIST数据集)
- [2.1.3 转换成Dataset对象](#2.1.3 转换成Dataset对象)
- [2.2 加载外部文件](#2.2 加载外部文件)
-
- [2.2.1 加载CSV文件](#2.2.1 加载CSV文件)
- [2.2.2 加载TFRecord文件](#2.2.2 加载TFRecord文件)
- [2.2.3 加载文本文件](#2.2.3 加载文本文件)
- [2.2.4 加载文件集](#2.2.4 加载文件集)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
- 本次实战系统演示了 TensorFlow 中多种数据集的加载与处理方法。内容涵盖从 Keras 内置的 MNIST 数据集,到本地的 CSV、TFRecord、文本文件,以及复杂的图片文件夹结构。重点讲解了如何利用
tf.data.DatasetAPI 将原始数据(如路径、标签)转化为高效的流式输入管道,为模型训练奠定了数据基础。
2. 实战步骤
2.1 加载自带数据
- MNIST数据集:MNIST(改进版美国国家标准与技术研究院数据库)是机器学习领域的"Hello World"级基准数据集,包含70,000张28×28像素的手写数字灰度图像(0-9)。其中60,000张为训练集,10,000张为测试集。它广泛用于验证算法性能及深度学习入门教学。
2.1.1 查看MNIST数据集
C:\Users\Administrator\.keras\datasets\mnist.npz
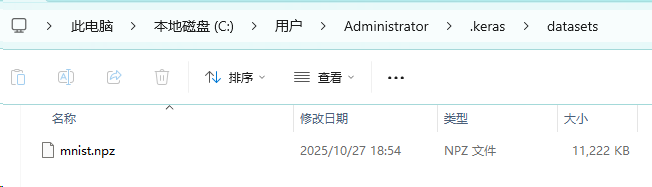
- 展示了Keras框架的本地数据集存储目录,路径位于
C:\Users\Administrator\.keras\datasets。文件夹中包含一个名为mnist.npz的文件(约11MB),这是著名的MNIST手写数字数据集的压缩格式。当代码调用keras.datasets.mnist.load_data()时,系统会优先在此处查找,若文件存在则直接加载,无需重新从网络下载,从而提升效率。
2.1.2 加载MNIST数据集
-
执行代码
pythonimport tensorflow as tf import pandas as pd from tensorflow.keras import datasets # 导入经典数据集 # 加载MNIST数据集 (x, y), (x_test, y_test) = datasets.mnist.load_data() print(f'x: {x.shape}, y: {y.shape}, x_test: {x_test.shape}, y_test: {y_test.shape}')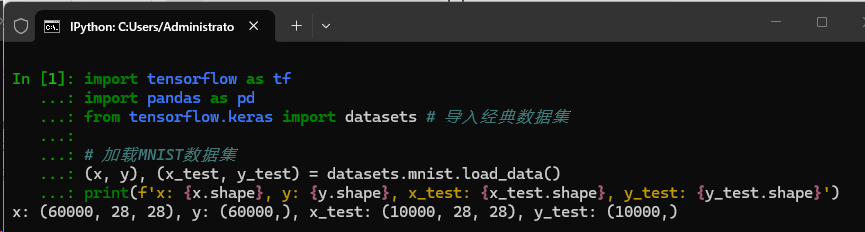
-
代码说明 :代码首先导入 TensorFlow、Pandas 及数据集模块,随即调用
datasets.mnist.load_data()加载 MNIST 数据集并自动划分为训练集与测试集。打印结果显示,成功获取了 60,000 张训练图像与 10,000 张测试图像(尺寸均为 28x28),完成了数据准备。
2.1.3 转换成Dataset对象
-
执行代码
pythontrain = tf.data.Dataset.from_tensor_slices((x, y)) test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
-
代码说明 :这两行代码利用
tf.data.Dataset.from_tensor_slices将 NumPy 数组形式的训练数据(x, y)和测试数据(x_test, y_test)封装成了 TensorFlow 的 Dataset 对象。这一步构建了高效的输入管道,将数据切片并转化为模型可直接迭代读取的格式,为后续的批量训练与评估做好了准备,而下方的日志仅为 CPU 指令集优化的提示信息。
2.2 加载外部文件
2.2.1 加载CSV文件
- 泰坦尼克号乘客数据集titanic_file.csv:泰坦尼克号乘客数据集记录了1912年沉船事故中乘客的生存情况及相关信息,包含乘客ID、船舱等级、姓名、性别、年龄、同行家属数、船票价格、登船港口等特征。该数据集常用于机器学习分类任务,预测乘客是否生还,是数据科学入门的经典案例。
-
使用Pandas库中的read_csv函数加载数据
-
执行代码
python# 1. 使用 pandas 读取 CSV 文件 # 注意:请确保文件路径 'e:/csvfiles/titanic_file.csv' 在你的电脑上真实存在 titanic_file = pd.read_csv('e:/csvfiles/titanic_file.csv') # 2. 将 DataFrame 转换为 TensorFlow Dataset # dict(titanic_file) 将 pandas DataFrame 转换为字典形式,键为列名,值为列数据 titanic_slices = tf.data.Dataset.from_tensor_slices(dict(titanic_file)) # 3. 遍历数据集 # take(1) 表示只取出一个批次(即第一行数据)进行演示 for feature_batch in titanic_slices.take(1): # feature_batch 是一个字典,包含当前行所有特征的键值对 for key, value in feature_batch.items(): # {!r:20s} 表示将键转换为 repr 字符串并占用 20 个字符宽度 # {} 表示直接打印值 print('{!r:20s}: {}'.format(key, value))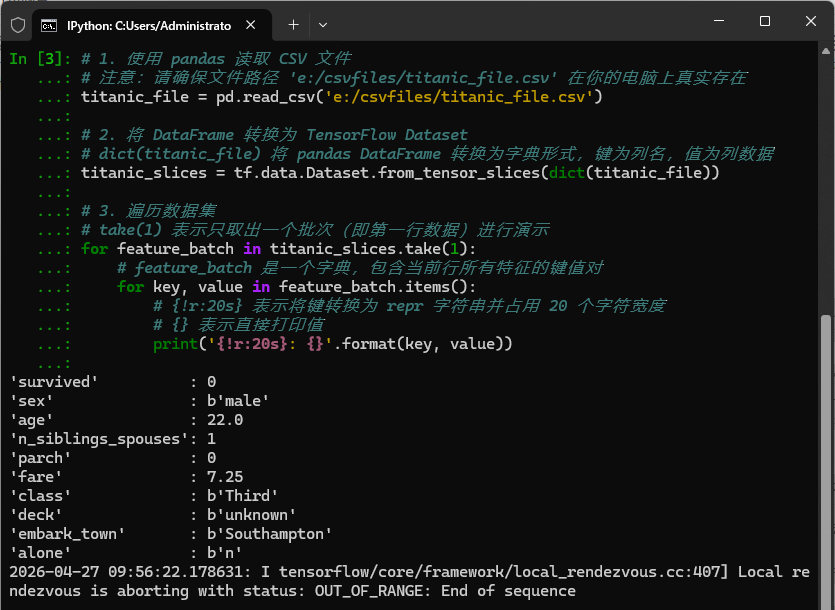
-
代码说明 :这段代码演示了如何用 Pandas 读取 Titanic CSV 数据,并通过
tf.data.Dataset.from_tensor_slices转换为 TensorFlow 数据集。随后,利用take(1)取出首个样本,遍历并打印其所有特征(如性别、年龄、票价等)及生存标签,验证了数据从 Pandas DataFrame 到 TF Dataset 的转换与单样本访问流程。
-
-
使用make_csv_dataset函数加载数据
-
执行代码
python# 1. 构建 CSV 数据集 # file_pattern: CSV 文件路径 # batch_size: 每个批次包含的样本数量 (这里设为 4) # label_name: 指定哪一列作为标签 (这里指定 'survived' 列) # 该函数会自动推断列的数据类型,并返回一个包含 (特征, 标签) 的数据集 titanic_batches = tf.data.experimental.make_csv_dataset( 'e:/csvfiles/titanic_file.csv', batch_size=4, label_name='survived' ) # 2. 遍历数据集 # take(1) 表示只从数据集中取出一个批次(batch)进行演示 for feature_batch, label_batch in titanic_batches.take(1): # 打印标签数据 (即 survived 列的值,形状为 [4]) print('survived: {}'.format(label_batch)) print('features:') # 3. 遍历特征字典 # feature_batch 是一个 OrderedDict,键是列名,值是该列的数据张量 for key, value in feature_batch.items(): # 修正了原代码中的拼写错误 feature_batches # 打印列名(键)和对应的数据(值) # {!r:20s} 格式化输出:使用 repr 形式,占位 20 字符宽度 print('{!r:20s}: {}'.format(key, value))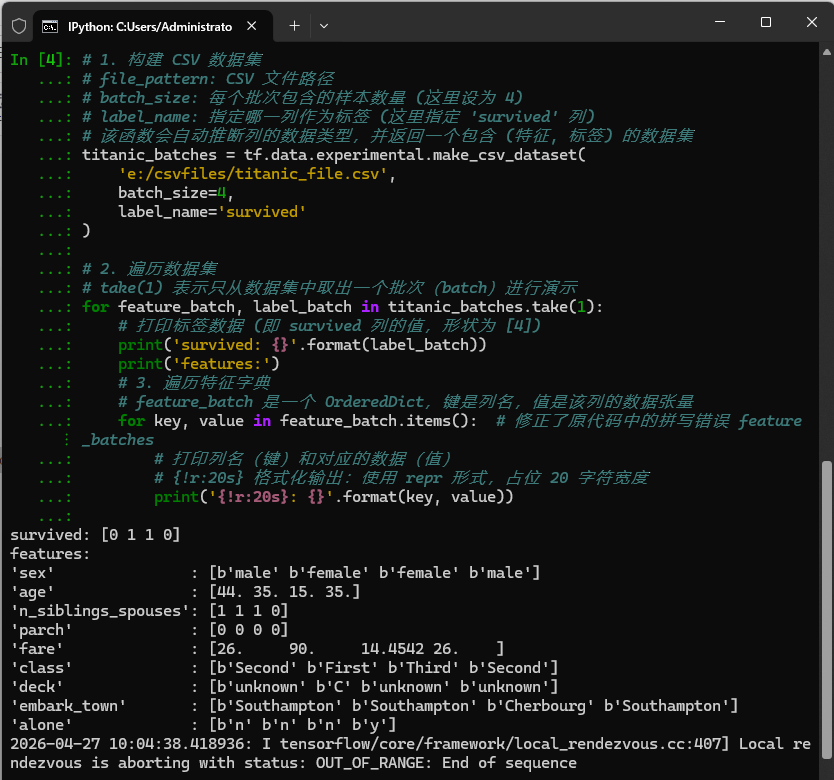
-
代码说明 :这段代码演示了如何使用 TensorFlow 的
make_csv_dataset从 CSV 文件构建数据集。它成功读取了一个批次(4 个样本)的泰坦尼克号数据,将survived列作为标签,其余列为特征。输出显示了每个特征列的名称及其对应的张量值,包括字符串和数值类型,验证了数据加载和预处理流程的正确性。
-
2.2.2 加载TFRecord文件
- FSNS概述:FSNS(Google Street View 法语签名数据集)是用于文本识别的公开数据集,包含 100 万张法国街道名称图像。每张图像通常包含四个视角,标注了对应的路名文本(如"Rue Perreyon")。该数据集广泛用于训练 OCR 模型,解决街景图片中的序列识别问题。
-
加载数据
-
执行代码
pythondataset = tf.data.TFRecordDataset(filenames =['d:/data/fsns.tfrec']) print(dataset)
-
代码说明 :这段代码使用
tf.data.TFRecordDataset从指定路径(d:/data/fsns.tfrec)加载 TFRecord 文件,创建了一个 TensorFlow 数据集对象。打印结果显示该数据集的元素类型为标量字符串(TensorSpec(shape=(), dtype=tf.string)),表明数据以序列化的字符串形式存储,后续需要解析才能获取具体特征。
-
-
解码数据
-
执行代码
pythonraw_example = next(iter(dataset)) parsed = tf.train.Example.FromString(raw_example.numpy()) print(parsed.features.feature['image/text'])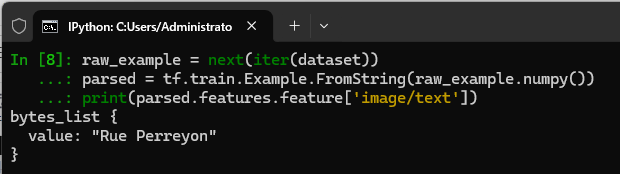
-
代码说明 :这段代码从
dataset中提取了一条原始 TFRecord 样本,并将其从序列化字符串反序列化为Example对象。随后,它访问并打印了其中名为'image/text'的特征。输出结果显示该样本的文本标签为 "Rue Perreyon",这通常对应于 FSNS 数据集中街景图像上的路名文本。
-
2.2.3 加载文本文件
-
查看cowper.txt文件
-
加载cowper.txt文件
-
执行代码
pythoncowper = tf.data.TextLineDataset('d:/data/cowper.txt') for line in cowper.take(5): print(line.numpy())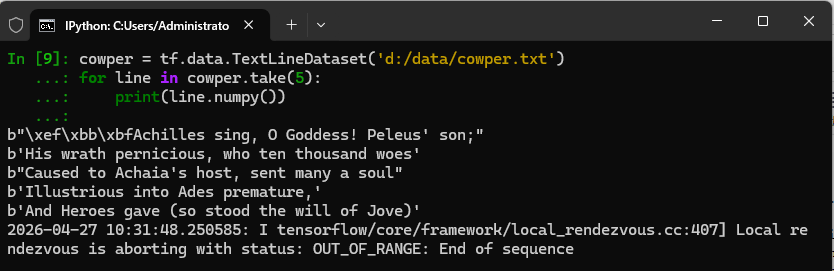
-
代码说明 :这段代码利用 TensorFlow 的
TextLineDataset接口读取指定路径下的文本文件(cowper.txt),构建了一个按行存储的数据集。随后,代码调用take(5)方法从中截取前 5 行数据,并通过循环将字节流解码打印。输出结果展示了《伊利亚特》译本的前五行诗句,最后的日志提示数据序列已读取完毕。
-
2.2.4 加载文件集
-
花卉数据集
- flower_photos 是由 Google 发布的经典花卉图像数据集,包含约 3,670 张高分辨率图片,分为雏菊、蒲公英、玫瑰、向日葵和郁金香 5 个类别。该数据集结构规范,广泛用于图像分类、迁移学习及深度学习入门教学。
- 641张玫瑰图像
- 699张向日葵图像
- flower_photos 是由 Google 发布的经典花卉图像数据集,包含约 3,670 张高分辨率图片,分为雏菊、蒲公英、玫瑰、向日葵和郁金香 5 个类别。该数据集结构规范,广泛用于图像分类、迁移学习及深度学习入门教学。
-
获取图片路径并查看
-
执行代码
pythonimport random import pathlib data_path = pathlib.Path('d:/data/flower_photos') all_image_paths = list(data_path.glob('*/*')) all_image_paths = [str(path) for path in all_image_paths] random.shuffle(all_image_paths) # 打散数据 image_count = len(all_image_paths) print(f'图片总数:{image_count}') print('10张图片路径:') for path in all_image_paths[:10]: print(path)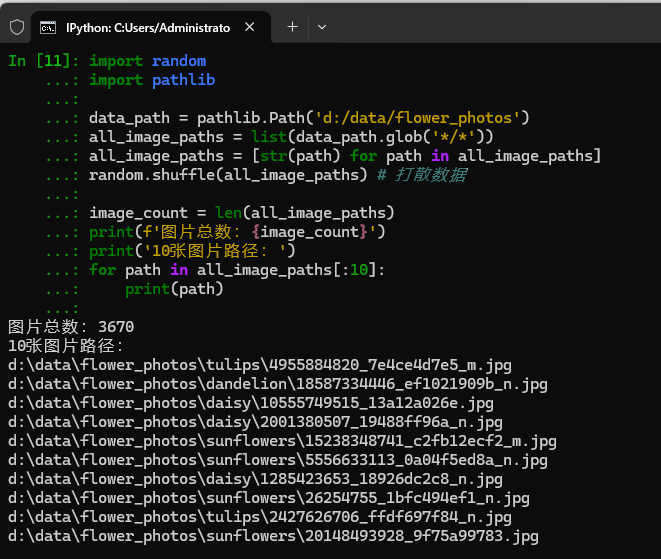
-
代码说明 :这段代码利用
pathlib库读取d:/data/flower_photos目录下的所有图像文件路径,并将其转换为字符串列表。随后,代码使用random.shuffle对数据进行随机打乱,以消除原始数据的顺序偏差。最后,它统计并打印了数据集的图片总数(3670张),并展示了打乱后的前10张图片的具体路径,验证了数据加载与洗牌的效果。
-
-
图片与标签对应
-
执行代码
python# 提取分类名 label_names = sorted(item.name for item in data_path.glob('*/') if item.is_dir()) print(f'分类名:{label_names}') # 创建标签 label_to_index = dict((name, index) for index, name in enumerate(label_names)) print(f'标签:{label_to_index}') # 将图片与标签对应 all_image_labels = [label_to_index[pathlib.Path(path).parent.name] for path in all_image_paths] for image, label in zip(all_image_paths[:10], all_image_labels[:10]): label_name = label_names[label] print(f'{image} ---> {label} : {label_name}')
-
代码说明 :这段代码主要完成了图像数据的标签构建与验证。首先从数据目录中提取出5个花卉分类名称(如 daisy、roses 等),并按字母顺序排序后建立名称到数字索引的映射字典。接着遍历前10张图片路径,通过读取图片所在的父文件夹名称,从字典中查找对应的数字标签。最终打印图片路径、数字ID及分类名称,验证了数据与标签的准确对应关系。
-
-
将加载后的图片转换为Dataset对象
- 执行代码:
ds = tf.data.Dataset.from_tensor_slices((all_image_paths, all_image_labels))

- 代码说明 :这行代码使用
tf.data.Dataset.from_tensor_slices创建了一个 TensorFlow 数据集对象ds。它将图片路径列表all_image_paths和对应的标签列表all_image_labels打包在一起,构建出"(图片路径, 标签)"的数据对。这一步将原始数据转换为 TensorFlow 可高效处理的流式数据集格式,为后续的批量读取、打乱顺序及模型训练做好了准备。
- 执行代码:
3. 实战总结
- 本次实战深入剖析了 TensorFlow 的数据处理全流程。首先,我们掌握了加载内置数据(MNIST)的便捷方式;其次,针对结构化数据(CSV),学会了使用 Pandas 预处理或直接构建批次;对于非结构化数据,我们实践了读取文本行(TextLineDataset)和解析二进制记录(TFRecord)的技术。最后,实战的核心在于处理图像分类任务。我们通过
pathlib遍历文件夹获取路径,构建了路径与标签(数字索引)的映射关系,并最终利用tf.data.Dataset.from_tensor_slices将离散的路径和标签整合为统一的 Dataset 对象。这一过程不仅实现了数据的规范化,更构建了高效、可迭代的输入流水线,完美适配了后续的深度学习模型训练需求。