3 HelloWorld
基础知识回顾
位、字节与字
- 位(bit):计算机中最小的数据单位,取值只有 0 或 1。
- 字节(Byte):8 个 bit 组成 1 个字节,是存储空间的基本计量单位。1 个字节能存 1 个英文字母,1 个汉字占 2 个字节。
- 字(Word):由若干字节构成,位数称为"字长"。字长取决于 CPU 架构------8 位机的字长为 8 位(1 字节),16 位机为 16 位(2 字节),32 位机为 32 位(4 字节)。字是 CPU 进行数据处理和运算的基本单位。
ASCII 编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)使用 7 位或 8 位二进制数来表示字符:
- 标准 ASCII:7 位编码,最高位补 0,共表示 128 种字符
- 扩展 ASCII:8 位编码,共表示 256 种字符
- 覆盖范围:所有大小写英文字母、数字 0~9、标点符号、以及美式英语中的特殊控制字符
计算机语言
人与计算机之间的交流通过计算机语言实现,编写程序需要遵循特定的字符和语法规则。按抽象层次由低到高分为三类:
| 类型 | 特点 |
|---|---|
| 机器语言 | 二进制指令,CPU 直接执行,但人几乎无法阅读 |
| 汇编语言 | 用助记符代替二进制操作码,接近硬件,可直接操作底层 |
| 高级语言 | 接近自然语言(如 C、Java),需编译/解释后才能执行 |
汇编语言的价值在于:它让程序员能看到软件层面最底层的操作细节,在逆向工程中尤为常用。
Hello World 程序
一个经典的 C 语言 Hello World 程序:
c
#include <stdio.h>
int main() {
printf("hello, world\n");
return 0;
}这段源码保存为 hello.c 后,需要经过一条完整的编译工具链才能变成可执行文件。
编译过程
从源文件 hello.c 到可执行程序,共经历四个阶段:
hello.c → [预处理器 cpp] → hello.i → [编译器 cc1] → hello.s → [汇编器 as] → hello.o → [链接器 ld] → hello(可执行)
printf.o ↗各阶段产物的格式:
| 阶段 | 输入 | 输出 | 格式 |
|---|---|---|---|
| 预处理 | hello.c(源程序) |
hello.i(修改后的源程序) |
文本 |
| 编译 | hello.i |
hello.s(汇编程序) |
文本 |
| 汇编 | hello.s |
hello.o(可重定位目标文件) |
二进制 |
| 链接 | hello.o + printf.o 等 |
hello(可执行目标文件) |
二进制 |
预处理(Preprocessing)
预处理器(cpp)处理所有以 # 开头的预处理指令,对源文件做文本层面的修改:
bash
gcc -E hello.c -o hello.i以 hello.c 中的 #include <stdio.h> 为例,预处理器会读取系统头文件 stdio.h 的全部内容,把它直接插入到程序文本中,生成扩展名为 .i 的文件。
常见预处理指令:
| 指令 | 作用 | 备注 |
|---|---|---|
#include <stdio.h> |
将头文件内容插入当前位置 | --- |
#define PI 3.14 |
文本替换,把 PI 替换为 3.14 |
纯文本替换,无类型检查 |
#define square(x) ((x)*(x)) |
带参数的宏 | 不加括号时 square(2+1) 会展开为 2+1*2+1,结果出错 |
#ifdef DEBUG ... #endif |
条件编译 | 仅当定义了 DEBUG 时才编译中间的代码 |
__DATE__ / __TIME__ / __FILE__ |
预定义宏 | 分别展开为当前日期、时间、文件名 |
编译(Compilation)
编译器(cc1)将预处理后的 .i 文件翻译为汇编语言 .s 文件:
bash
gcc -S hello.i -o hello.s这个阶段编译器做三件事:
- 检查代码规范性
- 检查是否有语法错误
- 确定代码实际要做的工作,翻译成汇编语言
生成的汇编代码示例(AT&T 语法):
asm
main:
subl $8, %esp
movl $LC0, %edi
call puts
movl $0, %eax
addl $8, %esp
ret汇编(Assembly)
汇编器(as)把汇编语言的 .s 文件翻译成机器指令,打包为二进制的可重定位目标文件 .o:
bash
gcc -c hello.s -o hello.o.o 文件已经是二进制格式,人无法直接阅读。
链接(Linking)
链接器(ld)将多个目标文件组合成一个可执行文件:
bash
gcc hello.o -o hello.out为什么需要链接?因为汇编完成后仍有未解决的问题:
- 一个源文件中的函数可能引用了另一个源文件中定义的符号(变量或函数)
- 程序中可能调用了库文件中的函数(如
printf来自printf.o)
链接器的核心工作:将一个文件中引用的符号与该符号在其他文件中的定义关联起来,把所有目标文件整合成一个可以加载执行的统一整体。
理解编译系统的意义
掌握编译系统的工作过程有助于:
- 优化程序性能------知道编译器如何翻译代码,才能写出对编译器友好的高效代码
- 理解链接错误------符号未定义、重复定义等链接报错,本质上都是链接器在符号解析阶段遇到了矛盾
- 避免安全漏洞------缓冲区溢出等底层漏洞的根源在于对编译和内存模型的理解不足
系统组成
一个典型计算机系统的硬件结构包含以下部件:
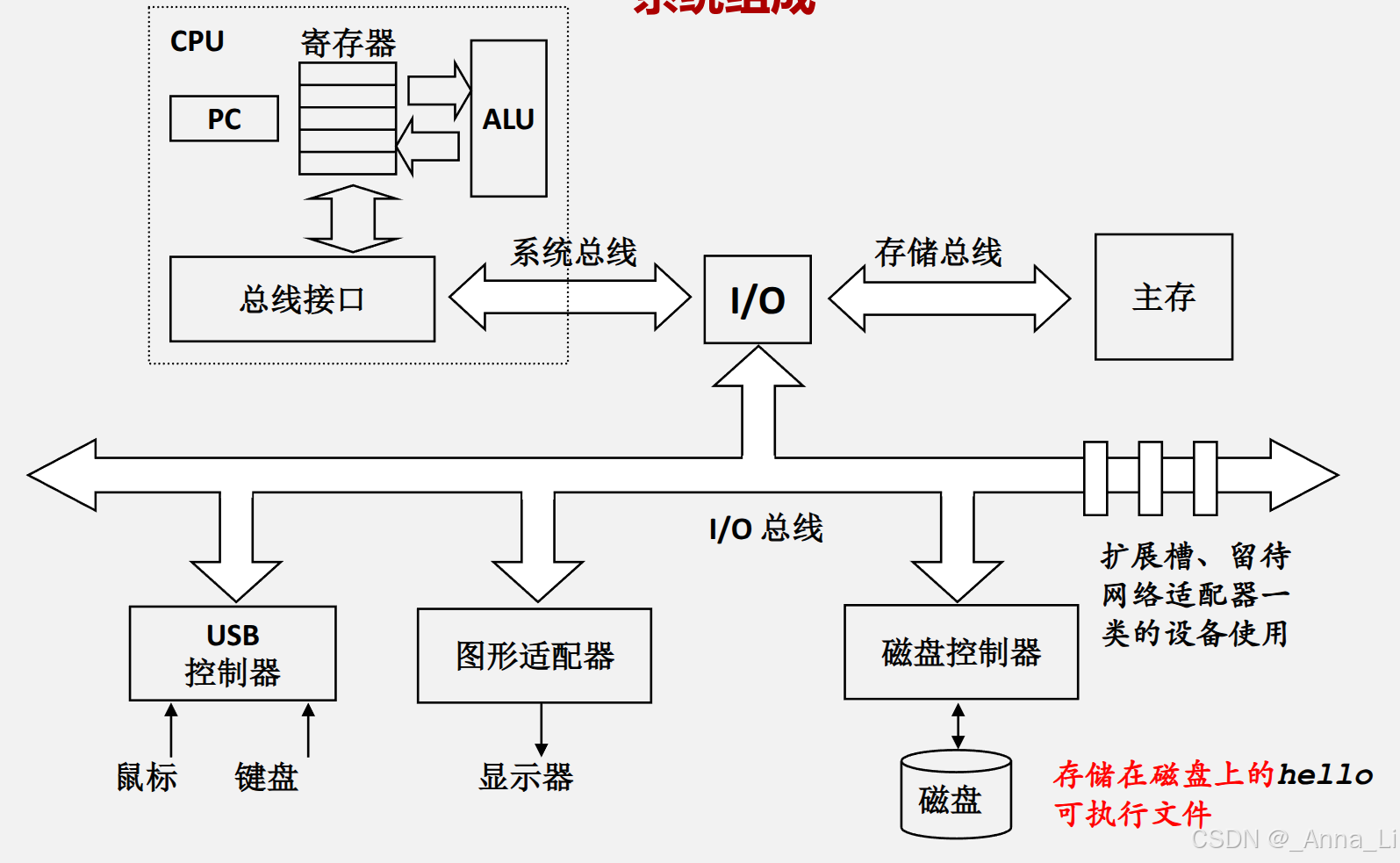
各部件的职责:
| 部件 | 功能 |
|---|---|
| CPU | 执行指令的引擎 |
| PC(程序计数器) | 存放下一条要执行的指令的地址 |
| 寄存器组(Register File) | CPU 内部的高速暂存单元 |
| ALU(算术逻辑单元) | 执行算术和逻辑运算 |
| 主存(Main Memory) | 临时存放程序和数据,按字节编址 |
| I/O 总线 | 连接各种 I/O 设备(磁盘控制器、USB 控制器、图形适配器等) |
| 系统总线 / 存储总线 | 连接 CPU 与主存 |
| 扩展槽 | 预留给网络适配器等扩展设备 |
程序运行过程
以在 shell 中执行 ./hello 为例,Hello World 程序的运行分为三个阶段:
1. 从键盘读取命令
用户在 shell 中逐字符输入 ./hello,每敲一个字符,shell 程序就将其从键盘 → I/O 总线 → CPU 寄存器 → 系统总线 → 主存,逐一存入内存缓冲区。
2. 从磁盘加载可执行文件
用户按下回车后,shell 识别出命令,将 hello 可执行文件的代码和数据从磁盘 → I/O 总线 → 存储总线 → 主存,利用 DMA(直接内存访问)技术,数据不经过 CPU 直接搬运到主存中。
3. 执行并输出结果
CPU 从主存取指令执行,当执行到输出语句时,将字符串 "hello, world\n" 从主存 → 系统总线 → I/O 总线 → 图形适配器 → 显示器,最终显示在屏幕上。
本节小结
- 基本概念:位是最小数据单位,8 位组成字节,若干字节组成字。ASCII 用 7/8 位二进制表示 128/256 种字符。
- 编译四阶段 :预处理(cpp,处理
#指令,文本替换和头文件展开)→ 编译(cc1,语法检查并翻译为汇编)→ 汇编(as,翻译为二进制目标文件)→ 链接(ld,符号解析并合并为可执行文件)。 - 系统硬件结构:CPU(PC + 寄存器 + ALU + 总线接口)通过系统总线和存储总线连接主存,通过 I/O 总线连接磁盘、键盘、显示器等外设。
- 程序执行流程:键盘输入 → 加载到主存 → CPU 取指执行 → 输出到显示器,数据在 CPU、主存和 I/O 设备之间沿总线流动。