
引言
站在2025年的尾巴上,全球AI行业呈现出一种令人眩晕的撕裂感。
在旧金山,耗资数倍算力训练出来的GPT-5并没有像GPT-4那样带来预期中的、断层式的跃迁。
在山景城,Google的Gemini 3 Pro却席卷全球,助推母公司Alphabet的市值逼近4万亿美元大关。
如果我们仅仅根据GPT-5的表现就断言Scaling Law失效,那是短视的。
如果我们因为Google的股价就盲目乐观,那更是无知的。
Scaling Law
同样的算力洪流,却给出了完全不同的答案。
这不是巧合,而是一层正在缓慢下沉的迷雾。
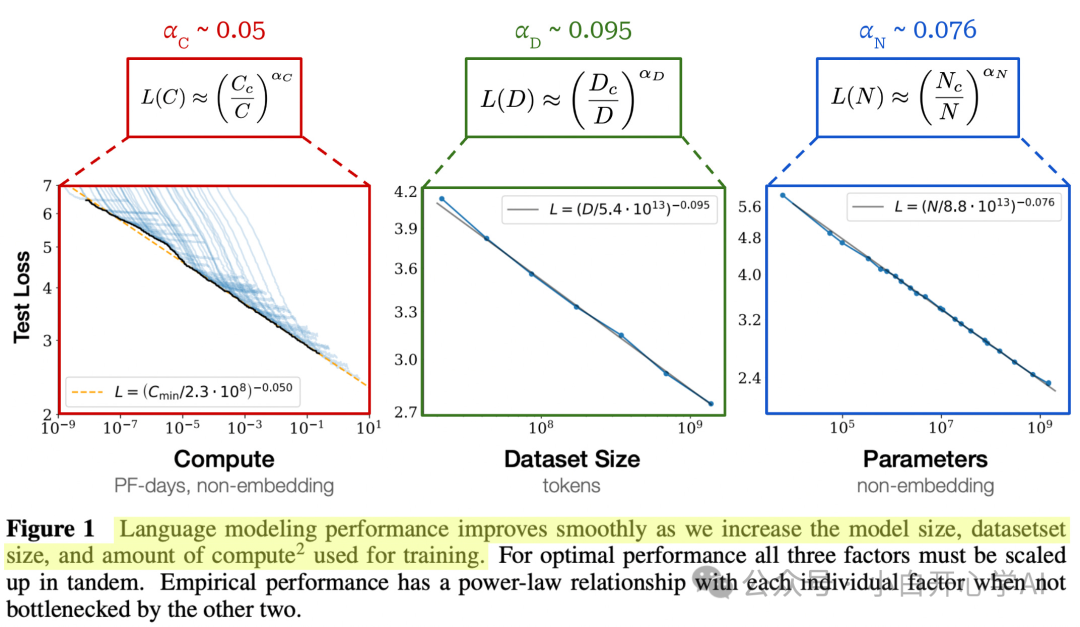
让我们回到那个著名的经验公式Scaling Law(缩放定律):
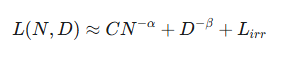

这个公式曾向我们承诺,只要把参数、数据、算力往上推,模型误差就能下降,智能就一定会涌现。
这就像是物理学定律一样,给了投资人们无限的信心,让他们敢于在沙漠里建设核电站级别的数据中心。
在科学家的对数世界里,Scaling Law是一条通往天堂的直线。
但在工程师的线性世界里,它是一条通往地狱的收益递减曲线。
Power Law
模型的误差L与参数量N、数据量D之间,是一个幂律关系(Power Law)。
这意味着,它们在双对数坐标系(Log-Log Plot)下才是一条直线。
这就是所谓的视觉欺骗,也是对数陷阱的来源。
在AI发展的早期,从1亿参数到100亿参数,算力的指数级增长带来了智能的肉眼可见的飞跃。
我们习惯了这种投入一分,收获一分的线性快感。
但当我们迈入10万亿参数的深水区时,数学规律露出了另外的一面。
要想获得同样的线性智力增长,需要10倍、100倍甚至更多的算力。
在万亿参数区间,数据难度与优化地形发生结构性变化,使得幂律的有效斜率开始随规模降低。
我们正在进入一个可怕的区间,边际收益逼近边际成本。
这到底是黎明前的迟滞?
还是宇宙给智能设置的物理上限?
为什么Scaling Law会出现动摇?
为什么投入了天文数字的算力,Loss曲线(误差)却有时拒绝下降,甚至莫名其妙地发散?
如果我们只是简单地将其归结为算力不够或数据不够,那就太傲慢了。
真正的问题在于,我们在用三维世界的直觉,去揣测万亿维空间的几何结构。
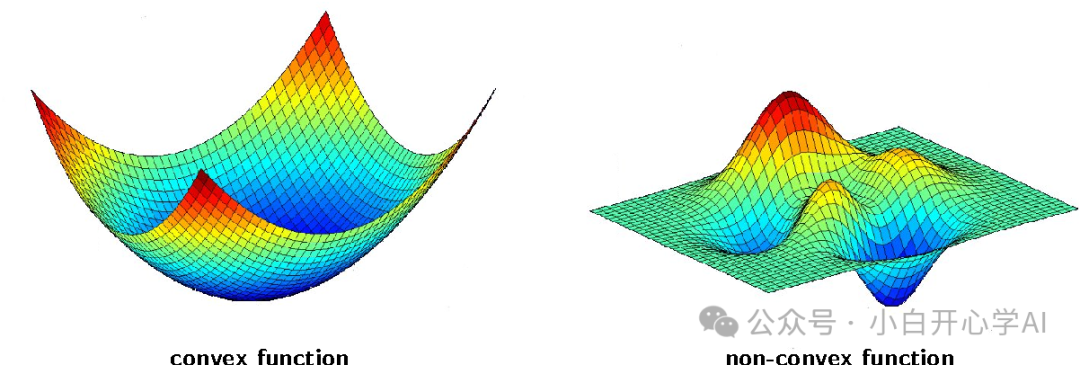
从碗到迷宫
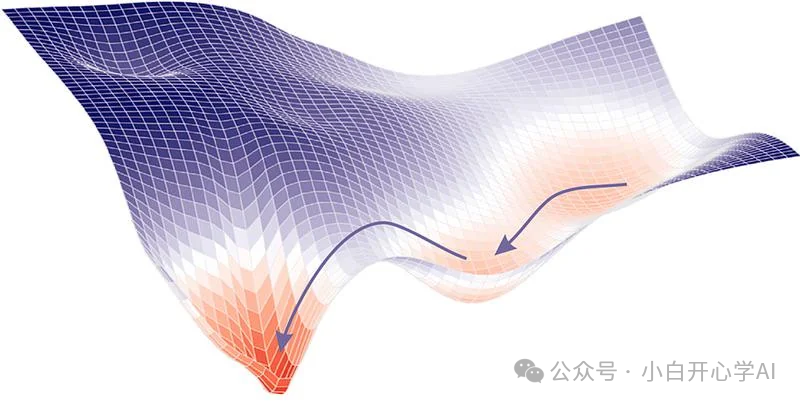
在教科书里,或者在简单的机器学习模型中,我们习惯了凸优化 (Convex Optimization)的思维。
哪怕是三维空间,损失函数的曲面看起来就像一个光滑的碗。只要你沿着坡度(梯度)往下滚,无论你从哪里出发,最终一定能滚到碗底(全局最优解)。
但在拥有10万亿参数的大模型里,这个地形图变成了10万亿维。
这是一个极其诡异、反直觉的非凸 (Non-convex)世界。它不是一个碗,它是喜马拉雅山脉的褶皱里藏着无数个马里亚纳海沟,如同迷宫一般。
在这个高维世界里,SGD(随机梯度下降)算法就像一个被蒙住双眼的登山者。
他手里没有地图,看不见远方,只能靠脚底板感受到的那一点点坡度,来决定下一步往哪走。
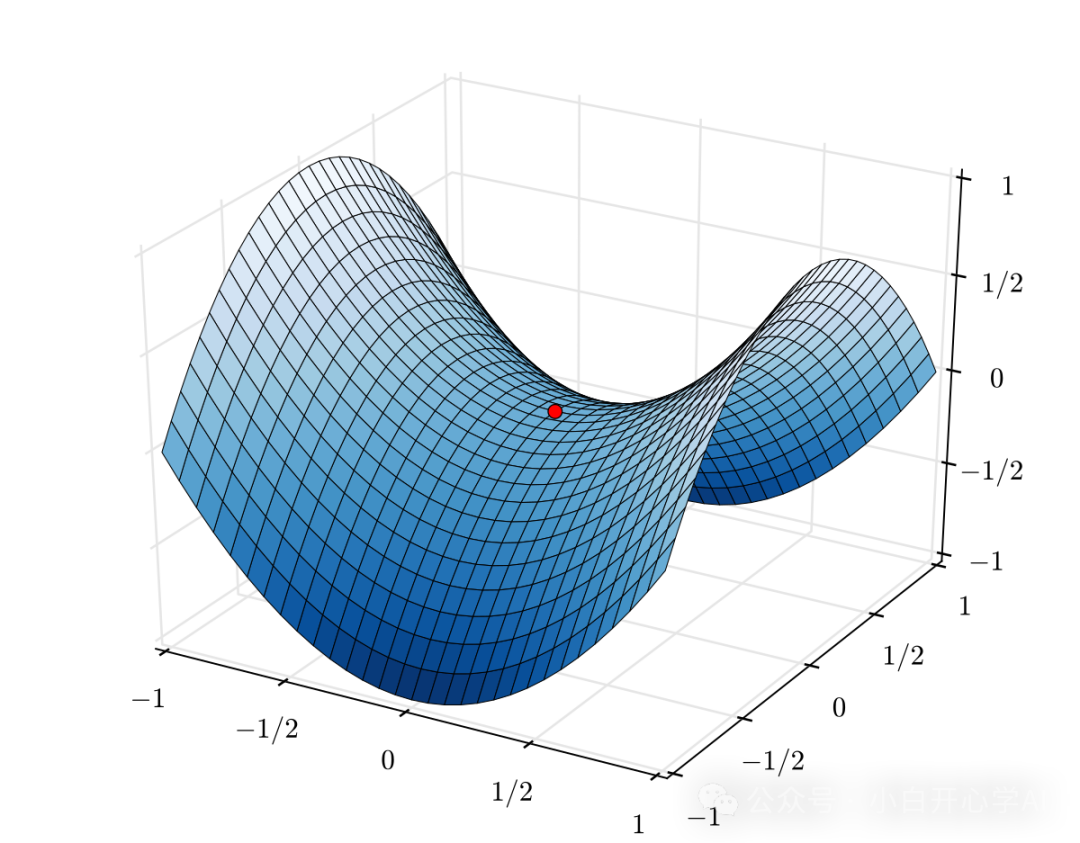
鞍点的迷魂阵
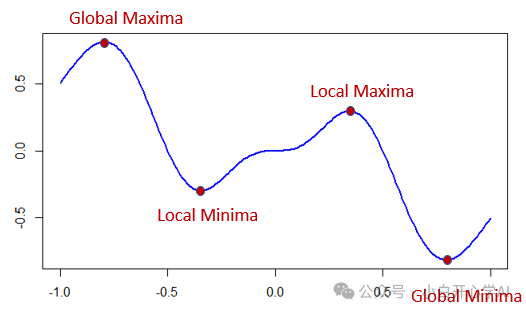
在这个高维迷宫中,最大的敌人甚至不是悬崖(梯度爆炸),而是鞍点 (Saddle Point)。
想象一下马鞍的形状,前后是翘起来的,左右是耷拉下去的。中心点是平的。
在高维数学中,存在一个反直觉的现象。维度越高,出现局部死胡同(局部最小值)的概率反而越低,但出现鞍点的概率呈指数级上升。
这构成了迷雾的核心,平庸的广阔性。
当我们的优化算法(SGD)走到这里时,它会发现,脚下是平的,四周也是平的,梯度消失了,指南针(导数)指向了零。
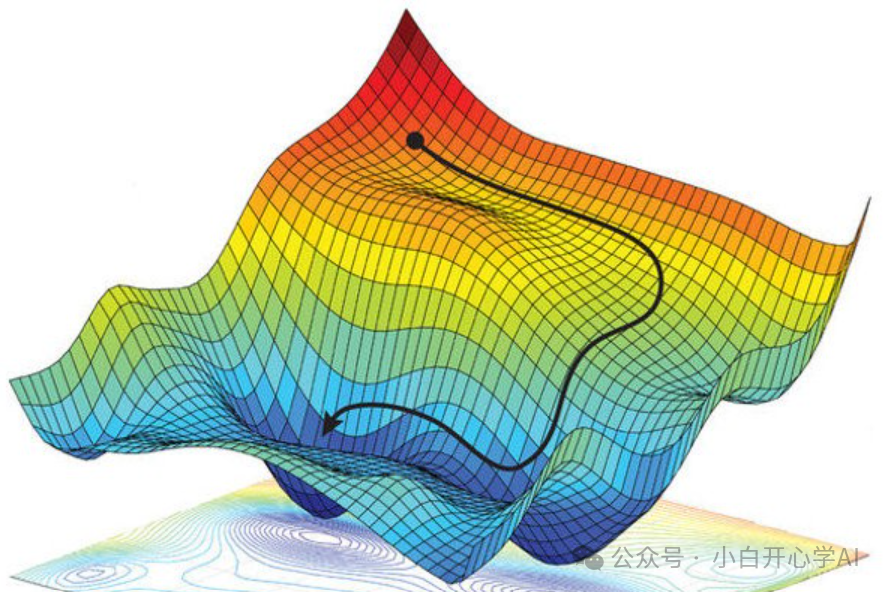
算法的鬼打墙
此刻,我们就陷入了所谓的高维鬼打墙。
工程师看到Loss不动,只能两种猜测:
-
猜测一:我们真的已经到达了谷底(收敛),模型已经学尽了数据里的所有智慧,再训练下去就是过拟合。
-
猜测二:我们只是被困在了半山腰的一片巨大平原(鞍点)上,而在平原的边缘,也许就藏着通往超级智能的、更深邃的峡谷。
这就是迷雾的本质,我们失去了坐标系,无法区分是到了终点还是困在半路。
在万亿维度的黑暗森林里,我们拿着手电筒(算力),却照不到地图的边界。
这时候,单纯地堆算力,加大Batch Size或学习率,就像是在平原上从走路变成了狂奔。
但这有用吗?
也许你跑得更快了,能冲出这片平原,发现新大陆(Grokking,顿悟现象)。
也许你只是在原地打转得更快了,甚至因为惯性太大,冲出了安全的边界,导致模型崩溃。
我们不知道前面是死路,还是转角。

Langevin Dynamics
面对这个让数学家头秃的高维迷宫,物理学家们却会心一笑:
这不就是分子的布朗运动吗?
在物理学中,描述微小粒子在流体中受到随机撞击而运动的朗之万动力学 (Langevin Dynamics),竟然揭示了AI训练最底层的秘密。
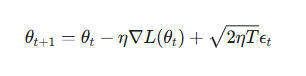

这个公式可以拆解成两股力量的博弈:
SGD = 梯度下降 + 随机扰动。
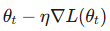
这部分是确定性的。它就是我们熟悉的梯度下降,指引着登山者往山谷的方向走。

这部分是随机性的。它是一个随机的推力,就像水分子的布朗运动在不停地撞击花粉,让系统获得能量跳出浅坑。
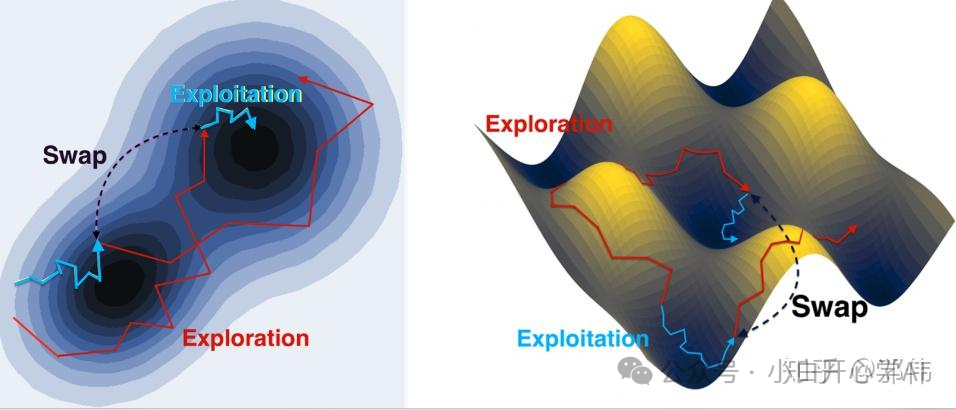
探索与利用的永恒矛盾
这构成了AI训练中最大的物理迷雾,温度的博弈。
高温状态(Small Batch Size):
-
当我们使用较小的Batch Size时,噪声很大,系统温度很高。登山者像是一个喝醉了酒的疯子(布朗运动),步履蹒跚。
-
代价:训练效率极低,算力无法跑满,甚至可能在原地打转。
-
红利:正是这种乱动的能量,让他有机会跳出那些平庸的局部最优解(Local Minima),误打误撞地发现通往更深谷底(更高智能)的新路径,避免冻死在平庸里。这是探索的胜利。
低温状态(Large Batch Size):
-
为了喂饱万卡集群,为了追求极致的训练速度,我们被迫疯狂加大 Batch Size。这相当于我们在人为地给系统降温。
-
红利:登山者变得极其理性、稳重,沿着当前的坡度全速冲刺,效率拉满。
-
代价:当温度逼近绝对零度,模型就失去了乱动的权利。一旦它掉进了一个看似不错、但实则平庸的坑里,它就再也没有能量跳出来了。这是利用的诅咒。
这就解释了AI训练中那个著名的悖论,为什么有时候不准确的小Batch,反而能训练出更好的模型?
因为当模型掉进一个浅浅的局部最优坑(Local Minima)时,高温(小Batch)引起的热噪声的能量,可以把它踢出来,让它有机会继续寻找更深的山谷(全局最优,Global Minima)。

临界点在哪里?
在万卡集群中,小Batch会导致吞吐骤降,工程师们不得不疯狂地加大Global Batch Size,从几千增加到几百万。
在物理学上,这是一个极其危险的操作。
我们在疯狂地给系统降温!
设想一下,当Batch Size趋向于无穷大时,公式里的噪声项将趋近于零,系统温度降到了绝对零度。
模型将变成了一个绝对理性的、但也绝对僵化的登山者。
他每一步都走得无比精确,但也正因为如此,一旦他掉进了一个平庸的鞍点或者小坑,他就再也没有能量跳出来了。
大模型在此时表现出的梯度消失、更新频率降低、顿悟减少,与过冷态(Supercooling)惊人一致。
我们可能正处在这样一个危险的临界点,算力越多、Batch越大,系统反而越难以涌现更高智能。

未知的相变
也许,在足够大的超高维空间里,地形会发生某种神奇的拓扑相变,最后只剩下一个通往真理的全局最优?
如果那样,现在的降温就是正确的。
但如果不是呢?
这就是迷雾的核心,我们不知道自己是在冻结,还是在逼近相变?
当前训练模式更像是快速淬火而不是缓慢退火,系统在降温过程中失去跳出次优区域的能力。
你想用大Batch和快收敛来走捷径,宇宙就给你一个局部最优的残次品。
你想得全局最优的正果,你就必须忍受漫长的、充满波动与噪声的修行。
没有噪声,就没有探索。
没有探索,就没有涌现。
这就是热力学给AI设下的终极防线。

三条路径
面对Scaling Law的迷雾,行业并没有达成共识,反而分裂出了三条截然不同的探险路径。
每一条路径背后,都站着一位拥有顶级大神。
Ilya Sutskever:向内求索
作为深度学习的教父,Ilya 的转身最为决绝。
他那句"Scaling时代结束了",并非是指算力无用,而是指单纯通过堆砌数据来进行预训练(Pre-training)的边际效益已经归零。
他的逻辑:人类互联网上的高质量数据已经枯竭。继续喂给模型垃圾数据,只会导致模型塌陷。
他的赌注:System 2(慢思考)与价值对齐。
-
他认为智能的飞跃不再来自于读更多的书,而来自于更深刻的思考。
-
他试图通过重构算法,让模型学会像人类一样进行长链条的逻辑推理,学会自我反思和顿悟。
本质:这是一条生物学路线。他试图在硅基芯片上,复刻人类大脑从直觉到逻辑的进化过程。
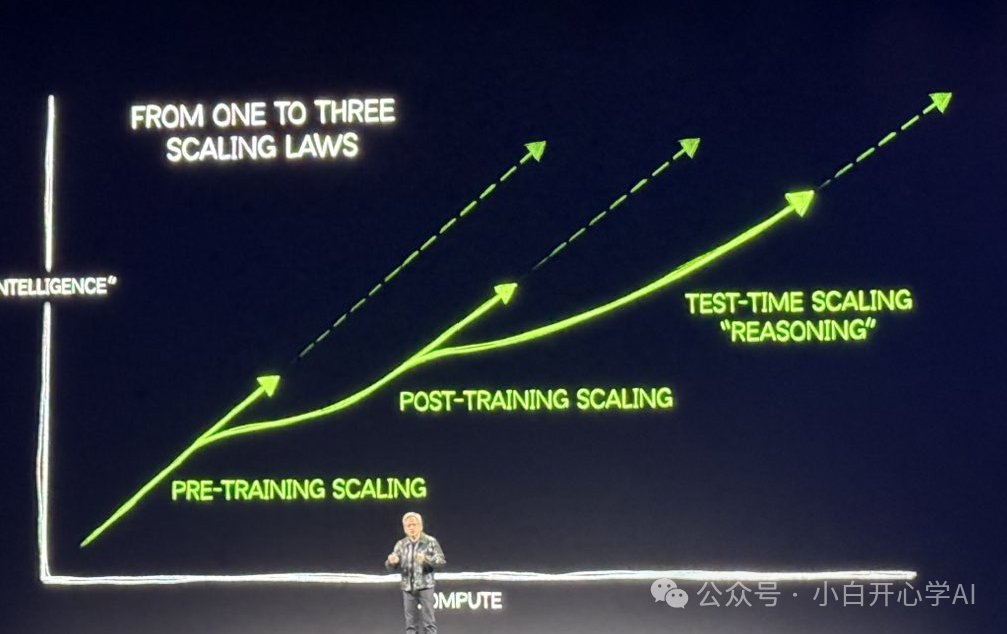
黄仁勋:向外扩张
黄仁勋抛出了一张三级火箭图,向世界宣告:算力的需求正在从单一的预训练,裂变为预训练+后训练+推理的三重叠加。
特别是Test-time Scaling(推理时扩展),它意味着未来AI的思考过程本身,就是一个巨大的算力黑洞。
他在告诉全世界的投资者和客户,别担心Scaling Law失效,别担心你们买的GPU会闲置。
只要你们想让AI具备逻辑推理能力(Reasoning),你们不仅需要买卡做预训练,还需要买更多的卡做后训练,更需要买海量的卡做推理!
他的逻辑:如果把模型练得更聪明变得很难,那我们就让它在考试时多想一会儿。
为了回答一个难题,模型可以在后台生成一万种解法,进行自我博弈、验证、搜索,最后输出一个最佳答案。
他的赌注:暴力穷举。
以前推理只需要几毫秒,现在可能需要几分钟。算力消耗不仅没有减少,反而指数级上升了。
本质:这是一条工程学路线。既然质变太难,那就用量变,无限的计算时间,来模拟质变。
Demis Hassabis:系统融合
DeepMind 的掌舵人Demis,则站在了两者之间,试图构建一个混合系统。
他的逻辑:大模型(LLM)只是大脑的语言中枢,负责直觉和表达,它天生缺乏逻辑和规划能力。试图让语言模型学会做数学,本身就是一种错配。
他的赌注:AlphaGo范式。
50%Scaling(保持直觉的敏感度) + 50% 搜索/规划算法(引入逻辑的严密性)。
他试图将蒙特卡洛树搜索(MCTS)植入大模型,让AI在回答问题前,先在思维空间里推演未来的几步棋。
本质:这是一条系统论路线。他不相信单一模型的全能,他相信结构的力量。

分歧
在这个十字路口,人类最顶尖的智慧发生了分歧。
这恰恰说明,我们对于智能本质的理解,依然处于盲人摸象的阶段。
智能是压缩?
如Ilya认为是从海量信息中提取规律。
是搜索?
如Demis和黄仁勋认为是在可能性空间中寻找最优解。
还是涌现?
如Scaling派认为是量变引起质变。
每一个流派,可能都只是摸到了真理的大象的一部分。
Ilya摸到了认知,黄仁勋摸到了计算,Demis摸到了结构。
也许他们最终会在山顶汇合,但在迷雾消散之前,每一条路都充满了巨大的风险与诱惑。

中美竞争
尽管理论的迷雾如此浓重,尽管路线的争论如此激烈,但在现实的物理世界里,我们看到的却是一幅更加疯狂、甚至带有某种宗教狂热色彩的景象。
在美国,OpenAI正在规划耗资千亿美元的星际之门 (Stargate)计划。
白宫的创世纪任务(Genesis Mission),直接将AI研发提升到了曼哈顿计划的战略高度,并拿出了能源部、NASA、NIH等的几十年积累的联邦科学数据集。
但是,如果物理墙是刚性的,这将成为一场消耗巨大、产出寥寥的建设。
在中国,国家机器正在编织一张跨越几千公里的算力巨网,试图将西部的风与光,转化为东部的智能。
政府发布了《人工智能+行动意见》,选择了工程化落地与产业赋能,试图用AI重塑实体经济的每一个细胞。
但是,实用主义路线可能会在通往AGI的圣杯之战中,因缺乏极致的单点突破而落后。
这是一个极其有趣的现象。
在科学上,Scaling Law的边际效应正在递减,Loss曲线正在变平。
但在工程上,人类对算力的投入却在呈指数级增长。
为什么在迷雾最浓的时候,中美两个超级大国,都不约而同地选择了把油门踩死?
因为智能的涌现是非线性的,对国家而言,算力是确定性投资,而模型能力提升是随机变量。
在不对称风险下,最优策略是先确保平台,再赌突破。
另外,如果竞争对手做到了,而我们没做到,那就可能是灭顶之灾。
这是一场以力破巧的终极实验。
我们试图用人类工业文明的极限,去点燃智能时代的第一级火箭。

总结
未来的竞争可能不仅仅是算力规模,而是如何在保持高噪声探索能力的前提下,继续扩展规模。
Scaling Law的动摇,更像是宇宙给人类的一个警醒。
哪怕我们拥有了富可敌国的财富,哪怕我们动用了国家机器的雷霆手段,在客观的数学法则与物理定律面前,我们依然微不足道。
我们要敬畏规律,但我们更要保持行进。
科学的历史,本就是一部在迷雾中摸索的历史。
牛顿不知道引力的本质,但他写出了万有引力定律。卡诺不知道分子的存在,但他推导出了热力学第二定律。
经验公式(Scaling Law)是我们手中唯一的火把。
虽然它可能会摇曳,甚至可能会熄灭,但在那之前,我们别无选择。
迷雾的尽头,也许是吞噬万亿财富的深渊,也许是通往新大陆的桥梁。
但人类这种生物,最擅长的,就是在深渊之上,架起桥梁。
因为,只有触碰到了边界,我们才知道自己究竟能飞多高。