东三省数模竞赛4月25日正式开赛,本竞赛过去四五届均采用深圳杯的赛题作为竞赛的赛题,由于东三省竞赛本质为省赛,且大部分学校用于国赛队伍选拔,深圳杯题目过于复杂,同时今年深圳杯开赛时间问题,与选拔队伍时间有所冲突。因此,2026年的东三省联赛自行命题,整体难度不大,且比赛时间较长,非常适合大家在未来的半个月慢慢悠悠的,非常清闲的做完这个题目。
本文将为大家带来赛题浅析,讲解一下每个题目涉及的模型、背景以及未来解题中可能会遇到的一些难点问题。整篇文章预计用时5~10分钟,可以快速的了解每个题目的基本情况
赛题难度预估A:B=5:4
选题人数预估A:B=5:4
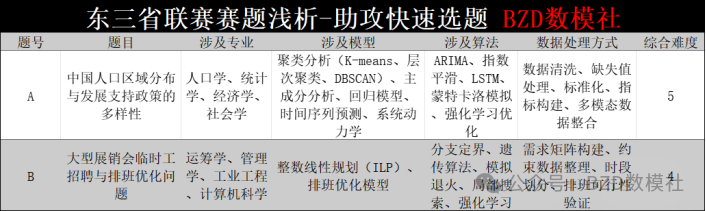
A题:中国人口区域分布与发展支持政策的多样性
问题总览
该问题旨在利用近四次全国人口普查数据,对中国人口的区域分布进行分类、分析人口数量影响因素,并进行未来人口预测与政策量化评估。核心目标是结合人口结构、流动性、教育水平、城乡差异等因素,为政策制定提供科学依据,实现人口高质量发展与现代化建设的支持。本题以第四至七次全国人口普查数据为基础,要求对中国各地区人口进行聚类划分,分析影响因素变化,建立预测模型,并量化政策效果。是一道典型的"数据驱动+机器学习+动力学建模"综合题。
问题1:人口区域分布类别划分
问题描述:利用多维普查指标(性别、年龄、教育、城乡、流动人口等)对全国各省/地区进行聚类分类。
求解思路:基于多维指标构建特征矩阵,先对数据标准化(Z-score),再选取合适的聚类算法划分区域类型,最终给出每类的典型特征画像。
可用模型:
-
K-Means 聚类:最经典,可结合"手肘法"确定最优类别数 K
-
层次聚类(Ward法):可绘制树状图,可解释性强
-
高斯混合模型(GMM):软聚类,适合边界模糊的地区
-
主成分分析(PCA):降维后可视化,辅助判断聚类合理性
创新点:
-
引入空间相关性(Moran's I 指数),检验聚类结果是否具有地理连续性
-
加入经济发展水平(GDP/人均收入)、产业结构比例等非普查辅助变量,使分类更有现实意义
-
将四次普查分别聚类后,追踪同一省份的类别漂移轨迹,揭示人口格局演变
问题2:不同类别影响因素的变化特征量化分析
问题描述:对比各类别在四次普查中,人口影响因素(出生率、老龄化率、受教育程度等)的变化规律,并做量化分析。
求解思路:对各类别分别计算指标的时序变化率,利用回归或相关分析识别关键驱动因素,构建"类别-因素"的量化关系图谱。
可用模型:
-
面板数据回归(Fixed/Random Effects):控制地区个体效应,分析因素影响
-
灰色关联度分析(GRA):衡量各因素与人口变化的关联强度
-
Pearson/Spearman 相关分析:快速筛选强相关因素
-
向量自回归模型(VAR):多变量之间的动态相互影响
创新点:
-
使用**Shapley值(SHAP)**对多因素的贡献度进行可解释性分解
-
引入结构方程模型(SEM),分析教育、流动人口、城镇化之间的路径关系,而非仅做相关分析
问题3:各类别人口数量预测(5/10/30年)
问题描述:对每种区域类别分别建立预测模型,给出未来5、10、30年人口数量的具体预测值。
求解思路:短期(5年)用统计外推,中期(10年)用队列要素法,长期(30年)引入系统动力学或Leslie矩阵,考虑政策和结构性因素。
可用模型:
-
Leslie矩阵模型(核心推荐):按年龄组分解人口结构,精确刻画老龄化动态,适合所有期限
-
GM(1,1) 灰色预测模型:数据量少时效果好,适合5年短期
-
Logistic增长模型:刻画有"人口天花板"的地区(如人口已负增长的东北)
-
ARIMA / SARIMA:纯时序方法,适合趋势平稳地区的短期预测
-
BP神经网络 / LSTM:捕捉非线性趋势,适合数据丰富的长期预测
创新点:
-
采用情景分析法:设置"低、中、高"三种生育率情景,给出区间预测而非点预测,增强结果可信度
-
将人口迁移流量作为类别间的耦合项,建立跨类别联动预测系统,避免各类别孤立预测
问题4:政策量化分析(有无政策对比)
问题描述:针对各类别给出差异化生育/人口支持政策,量化有无政策情景下未来5/10/30年的人口差异。
求解思路:将政策效果转化为模型参数的变动(如生育率提升幅度、城乡迁移率变化),在预测模型中对比"基准情景"与"政策情景"的人口轨迹差异。
可用模型:
-
系统动力学模型(SD):将政策作为反馈环路中的调控变量,适合30年长期模拟
-
双重差分法(DID):若历史上有政策试点地区,可估计政策的真实净效应
-
蒙特卡洛模拟:引入政策实施不确定性,输出概率分布意义上的预测区间
-
Leslie矩阵扩展版:在矩阵元素中加入政策调节系数(生育率弹性)
创新点:
-
参考计量经济学中的反事实分析框架,用合成控制法(Synthetic Control)构造"假如没有政策"的对照组
-
对政策成本(财政补贴等)做成本-效益分析,计算每提升1万人口所需的政策投入,为政策优先级排序提供依据
B题:大型展销会临时工招聘与排班优化问题
问题总览
该问题聚焦大型展销会的临时工排班优化,目标是在满足各小组每日各时段临时工需求的同时,最小化招聘人数,并考虑工作连续性、休息要求及灵活分配策略。问题有三个层次的约束复杂度:固定小组、跨天小组、跨天及跨时段小组。这是一道经典的人员排班(Workforce Scheduling)运筹优化题。核心目标是在满足所有小组每小时用工需求的前提下,最小化招聘临时工总人数。三个问题的约束条件逐步放宽(灵活性递增),建模复杂度依次提升。
问题1:每人只服务同一小组(10天绑定)
问题描述:每名工人全程只属于一个小组,需在10天内工作8天(休息2天),每天工作连续8小时(两个连续4小时段)。
求解思路:对每个小组独立建立整数线性规划(ILP),决策变量为:每种"工作日组合×每天工作时段组合"的工人人数,目标为最小化该小组的工人总数。10个小组独立求解后汇总即为总人数。
可用模型:
·整数线性规划(ILP):最直接,用 CPLEX / Gurobi / Python PuLP 求解
·列生成法(Column Generation):当班次变量爆炸时,动态生成可行排班列
关键约束:每天每小时实际在岗人数≥ 需求量;每人工作天数 = 8;每天工作时段为连续8小时(即连续两个4小时块)。
创新点:
·建立灵敏度分析:找出哪些小时段是"瓶颈时段"(需求最难满足),指导运营管理重点关注
问题2:跨天可换小组(日内绑定)
问题描述:同一天内一个工人只能服务一个小组,但不同天可服务不同小组,灵活性增加。
求解思路:建立统一的全局ILP,引入工人-天-小组的三维分配变量,利用跨小组调配减少总招聘人数。
可用模型:
·混合整数线性规划(MILP):全局统一建模,变量规模较大但结构规则
·网络流模型:将工人的工作-休息安排抽象为有向图上的流量问题,可利用网络流的多项式算法高效求解
创新点:
·利用问题结构(需求矩阵的稀疏性)进行预处理剪枝,大幅缩减搜索空间
·对比问题1的最优解,量化"跨组调配"带来的节省工人数量,体现灵活排班的价值
问题3:同天可跨2组 + 休息2小时约束
问题描述:一天内可服务至多2个小组,各工作4小时,两段之间至少有2小时休息(即工作时段不相邻,至少隔2格)。
求解思路:首先枚举所有合法的"单日班次"(满足4+休息2+4约束),然后在全局MILP中以合法班次为决策单元,最优化分配。
可用模型:
·集合覆盖/划分模型(Set Covering):以合法班次为列,以每小时需求满足为行约束,是这类排班问题的标准范式
·启发式算法(遗传算法/模拟退火):当精确求解因规模过大而超时,可用元启发式算法求近优解
·列生成+分支定价(Branch & Price):求解大规模集合覆盖的标准工业方法
创新点:
·引入鲁棒优化框架:考虑实际场景中工人可能临时缺勤,设计有一定冗余的鲁棒排班方案
·建立多目标优化:同时最小化招聘人数和最小化工人负荷方差(公平性),用Pareto前沿展示二者的权衡关系