在前面的文章中,我们主要学习了 Kafka 服务端的相关知识。从本文开始,我们将视角转到客户端。
分区的核心逻辑
在从零学习Kafka:集群架构和基本概念一文中,我们了解了 Kafka 中分区的概念,它的主要作用一个是支持系统的可伸缩性,另一个是负载均衡。
生产者在写入数据时,实际是要写入到指定的分区。换句话说分区是 Kafka 中消息组织的最基础的单位。除了做负载均衡外,分区还有一个作用就是保证业务消息的处理顺序。
当你调用 producer.send(record) 时,Kafka 需要先确定数据要写到哪个分区。具体逻辑如下:
- 如果显示指定了 Partition:直接把数据写到指定分区
- 如果没有显示指定 Partition,但指定了 Key:把数据写到 Key 所对应的分区
- 既没有指定 Partition,也没有指定 Key:使用 Kafka 的默认策略来分配数据
分区策略
到这里你可能想问,Kafka 到底是如何判断一条数据应该分配到哪个分区的呢?别急,我们现在就来介绍 Kafka 的分区策略。
按 Key 分配策略
如果我们在消息中指定了消息键,Kafka 会将相同 Key 的消息发送到相同的分区。具体方式是使用 murmur2 算法对 Key 进行 Hash,即 abs(murmur2(key)) % numPartitions。这个策略是为了实现局部有序性。
轮询策略
如果没有指定 Key,在旧版本中,Kafka 默认使用的是轮询策略,也就是对消息按顺序分配。如下图第一条消息分配到 partition0,第二条消息分配到 partition1,第三条消息分配到 partition2。
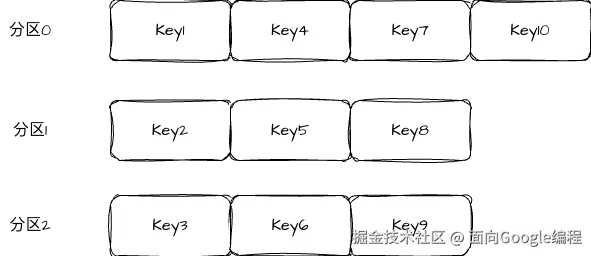
轮询策略的好处就是负载非常均衡,它能最大限度保证消息被平均分配到所有分区上,但它的缺点也比较明显,这样分配会导致每个批次都很小,会有很多小请求,从而影响吞吐量。
粘性策略
为了解决轮询策略的问题,Kafka 又引入了新的分区策略------粘性策略。它的逻辑是消息默认跟随上一个消息的分区,直到批次被填满,或者等待时间到了。这样做的好处是可以极大的提高消息的批处理效率。
随机策略
旧版本的 Kafka 也支持随机策略,它的逻辑就是每次生成一个随机数,然后计算出对应的分区。这个策略本身的目的也是希望能做到负载均衡,但是实际效果不如轮询策略,因此在新版本中就不会使用了。
自定义策略
最后再介绍一下自定义策略,自定义分区策略的方法也很简单。只需要在自定义类中实现接口 org.apache.kafka.clients.producer.Partitioner,然后在 partition() 方法中实现自己的分区逻辑。
partition 方法提供了很多入参,包括消息相关的 topic、key、keyBytes、value、valueBytes,也包括集群相关的 cluster。一般情况下这么多信息足够你计算出对应消息需要发送到哪个分区。
vbnet
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);关键参数
介绍完了分区策略之后,我们再看几个分区相关的配置参数。
第一个是 batch.size,在介绍粘性策略时,我们提到了批次填满时,消息会分配到新的分区。这个参数就是用来控制批次大小的,默认是 16KB,批次越大,吞吐量越高。
第二个参数是 linger.ms,也是用于粘性策略的。它控制的是等待时间,默认是 0ms。生产环境可以设置成 5 - 100 ms。
总结
本文我们的视角从服务端过渡到了客户端,先从生产者的分区机制入手。了解了为什么需要分区,以及分区的几种策略,最后又介绍了两个配置参数。下一节我们将一起了解生产者端的性能提升利器------压缩。