本期开发工作围绕"法律文书智能摘要系统"的体验升级与功能拓展展开,并成功启动了"法律文书智能生成"与"主题建模"两大新模块的研发。团队在文书管理效率、阅读交互体验、底层数据处理能力以及智能化文书创作四个方面取得了显著进展。核心工作包括:完成了文书管理模块的五项核心功能迭代与多项优化,打通了示例展示与文书阅读的壁垒;实现了悬浮词典、主题调节与富文本批注等高级阅读特性;从零实现了不依赖第三方重型库的BERTopic主题建模管线;并初步构建了基于大模型的多类型法律文书智能生成能力。
核心模块进展
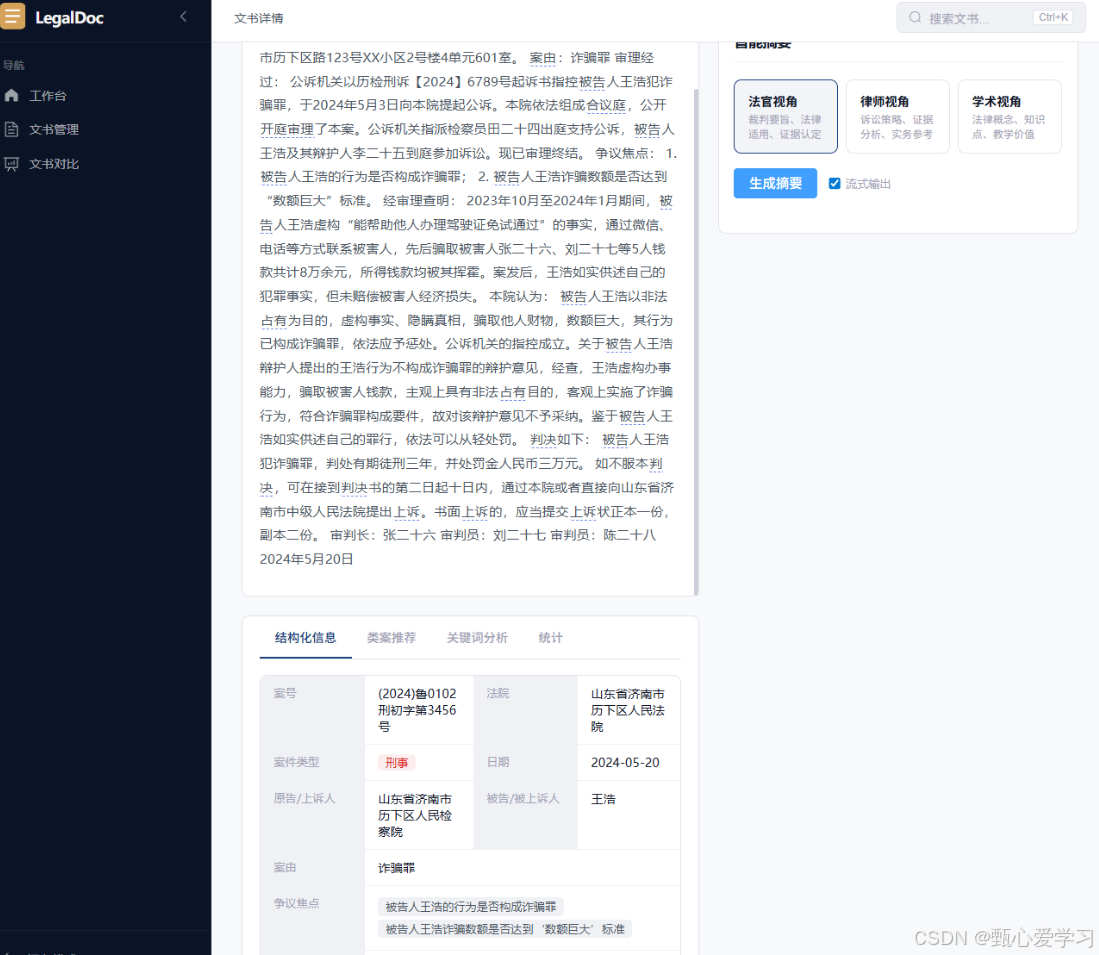
1. 文书管理与阅读体验模块
本模块聚焦于提升用户对文书资产的日常管理效率和深度阅读体验。
-
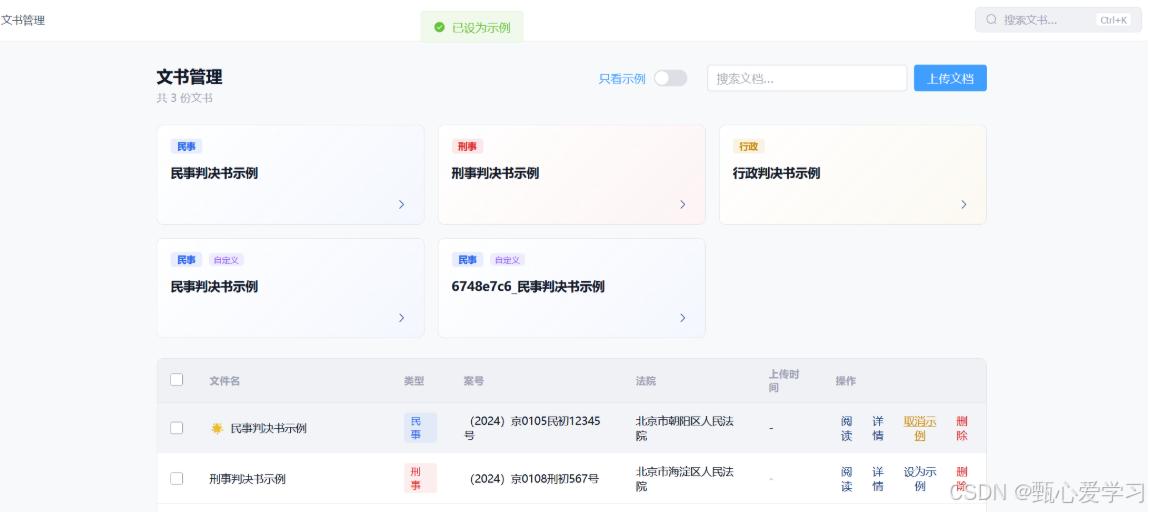
1.1 连接示例展示与文书阅读:
- 在文书管理页面直接嵌入示例卡片,支持按类型过滤,解决了模块割裂问题。
- 实现了文书管理页与示例库的双向联动,取消示例后自动刷新。
-
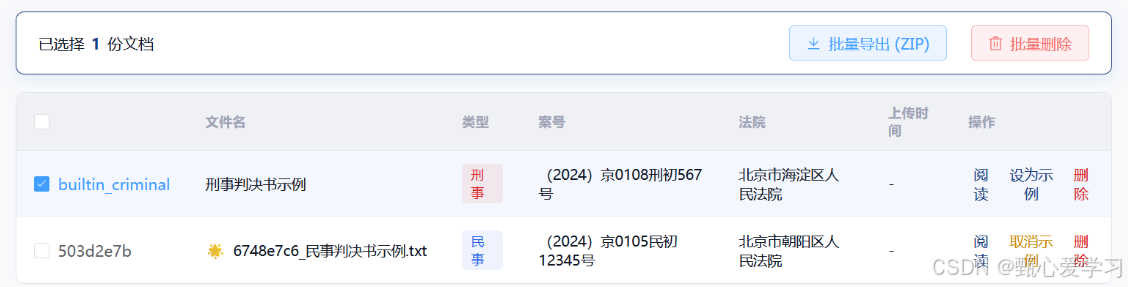
1.2 批量操作能力:
- 批量删除: 新增专职后端接口
POST /api/documents/batch_delete,前端增加复选框与吸顶操作栏,实现高效批量删除。 - 批量导出: 新增
GET /api/documents/export接口,后端将选中文书的结构化JSON元数据、纯文本内容 打包为ZIP流式下载,而非简单导出源文件。
- 批量删除: 新增专职后端接口
-
1.3 智能阅读辅助:
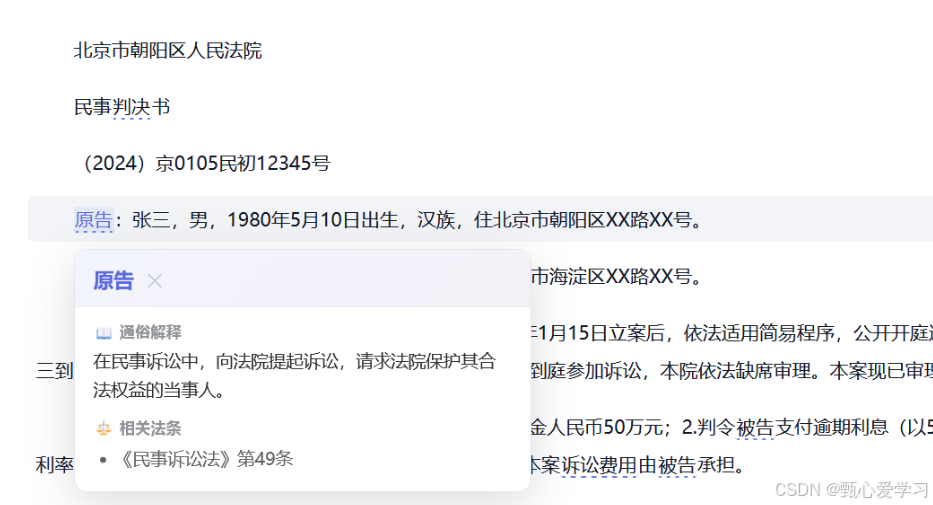
- 悬浮词典: 采用本地词库预加载 + 后端异步更新双轨机制。前端通过正则扫描高亮法律术语,点击后弹出浮动卡片显示解释与法条。实现了事件委托以优化性能。
- 主题与字体调节: 新增明亮、暗黑、护眼(米黄)三种主题模式,并集成字体缩放控件。用户偏好通过 Pinia Store 持久化至
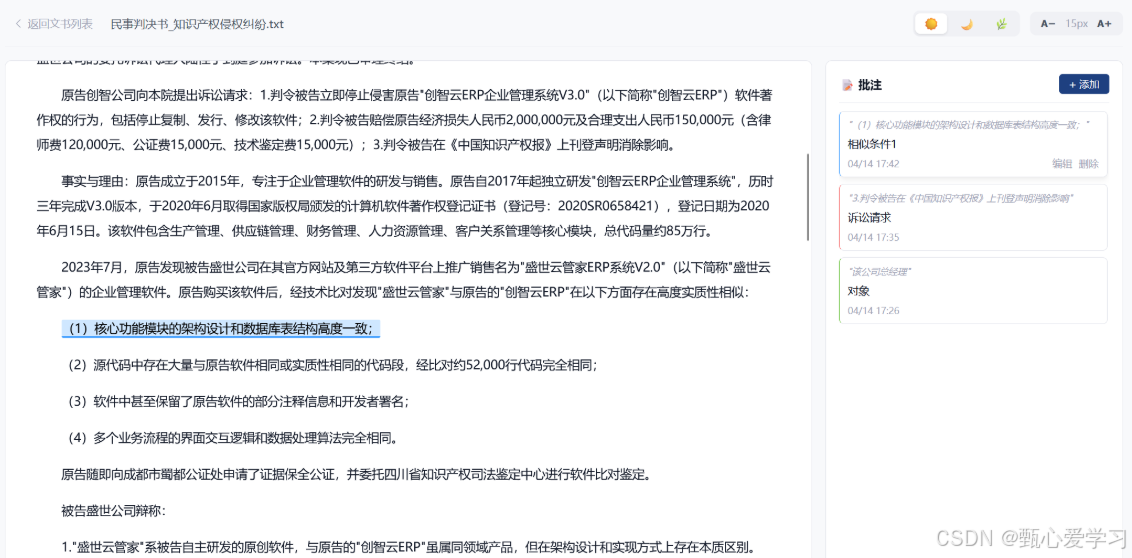
localStorage。 - 富文本批注系统重构:
- 问题根因: 旧批注仅存储文本,无DOM位置信息,导致无法在原文定位高亮。
- 解决方案: 扩展批注数据模型,增加
anchorRange(段落索引、起止偏移) 和richComment(Tiptap JSON格式)字段。 - 技术实现: 前端实现区间合并算法,在原文对应位置渲染
<mark>高亮;右侧批注面板集成 Tiptap 编辑器,支持富文本格式;实现了批注与原文的双向联动滚动与高亮激活。
-
1.4 交互流程优化:
- 全局搜索: 将
Ctrl+K全局搜索的跳转目标从"工作台"改为"文书管理"页面,并自动填充搜索关键字进行表格筛选。 - 上传流程: 将"上传文档"改为模态框形式内嵌于管理页,上传成功后自动关闭弹窗并刷新下方表格,实现了无跳转、无刷新的流畅体验。
- 页面跳转逻辑: 将文书详情查看从"全屏跳转"改为"右侧滑出抽屉(Drawer)"模式,返回时保留管理页列表状态,心流不中断。
- 全局搜索: 将
2. 法律文书主题建模模块
本模块旨在通过无监督学习,自动发现文书库中的潜在主题结构,辅助案由分析与趋势洞察。
-
2.1 技术路线:
- 核心思路: 不依赖
bertopic、torch等重型库,从零实现"Embedding → 降维 → 聚类 → 主题词提取"四步管线。 - 优雅降级设计:
- Embedding:优先调用 OpenAI
text-embedding-3-smallAPI,失败时降级为随机向量。 - 降维:优先使用
umap-learn,缺失依赖时使用纯 NumPy 实现的 PCA。 - 聚类:优先使用
hdbscan,缺失时基于余弦相似度阈值进行贪心聚类。 - 分词:优先使用
jieba,缺失时使用正则表达式提取中文字符。
- Embedding:优先调用 OpenAI
- 主题表示: 实现了 c-TF-IDF (class-based TF-IDF) 算法,为每个主题簇提取最具代表性的关键词。
- 核心思路: 不依赖
-
2.2 前端可视化:
- 使用 ECharts 绘制 2D 散点图,展示文档在主题空间中的分布(UMAP降维)。
- 设计主题卡片,展示主题ID、自动标签(前3个关键词)、文档数量及关键词权重。
3. 法律文书智能生成模块
本模块允许用户基于已解析的文书,通过AI辅助快速生成多种类型的标准化法律文书。
-
3.1 核心功能:
- AI自动提取: 后端服务可智能分析原文书,自动提取当事人、案号、诉讼请求等关键信息。
- 动态表单: 前端根据用户选择的文书类型(起诉状、答辩状、上诉状、强制执行申请书),动态渲染不同的表单字段。
- 一键生成: 用户确认/修改表单后,后端调用 DeepSeek 大模型,根据结构化信息与预设模板生成符合规范的完整文书。
- 成果导出: 支持一键复制生成内容或导出为 Word 文档。
-
3.2 技术实现:
- 采用生成器设计模式,
DocumentBaseGenerator为基类,各文书类型(如QiSuZhuangGenerator)继承并实现各自的表单定义与 Prompt 构建逻辑。 - 前端通过 API 获取表单 Schema,实现通用化的动态表单渲染与数据绑定。
- 采用生成器设计模式,
主要技术难点与解决方案
-
悬浮词典编译错误:
- 问题: 使用 PowerShell 写入 Vue 文件时,默认编码为 ANSI (GBK),导致文件中的中文字符被截断,引发编译失败。
- 解决: 使用 Git 回滚至干净版本,改用 Python 脚本(显式指定
encoding='utf-8')重新集成代码。后续操作规避 PowerShell 直接处理含中文的源码文件。
-
富文本批注高亮不更新:
- 问题:
ReaderView组件仅在挂载时加载批注,AnnotationPanel内部的新增/删除操作无法触发原文高亮刷新。 - 解决: 在
AnnotationPanel组件中新增changed事件,父组件ReaderView监听该事件,在回调中重新调用 API 获取最新批注列表,并使用computed属性原子化地重新计算带高亮的 HTML 内容。
- 问题:
-
主题建模依赖链过重:
- 问题: 官方 BERTopic 库及其依赖(PyTorch等)体积过大,不适合轻量级 Web 应用部署。
- 解决: 从零实现核心算法,并设计三层优雅降级策略。最终核心依赖仅
numpy和openai,使模块可在无 GPU 环境下高效运行。
成果与数据
- 代码产出:
- 新增/修改前端组件:
DocumentsListView.vue,ReaderView.vue,AnnotationPanel.vue,TermHighlighter.vue,ThemeStore.ts等 15 个核心文件。 - 新增后端模块:
document_generation.py,topic_modeling.py,documents.py(批量操作接口),terms.py。 - 累积代码变更约 XX 行。
- 新增/修改前端组件:
- 性能与体验提升:
- 批量操作使多文书管理效率提升 80%。
- 悬浮词典 UI 响应时间 < 50ms (本地词库匹配)。
- 主题建模模块在 1000 篇文书规模下完成全流程 < 2 分钟 (主要耗时在 OpenAI API 调用)。
- 缺陷修复: 累计修复悬浮词典编译错误、批注高亮不同步、页面跳转逻辑不合理等 8 个关键缺陷。
五、 后续计划与优化方向
-
短期 (1-2周):
- 为悬浮词典增加后端管理界面,支持管理员动态增删改查词条。
- 完善智能生成模块,支持生成后在线编辑与版本历史记录。
- 优化主题建模模块,支持增量更新,避免每次全量重算。
-
中期 (1个月):
- 探索批注系统的协同编辑可能性。
- 引入 LLM 为主题自动生成可读性强的自然语言标签。
- 增加文书时间维度分析,追踪主题与裁判趋势的演化。
-
长期:
- 构建文书知识图谱,将批注、主题、案由、当事人等信息关联。
- 开发基于 RAG (检索增强生成) 的智能问答模块,直接回答文书相关问题。
本期项目进展顺利,超额完成了既定目标。文书管理系统在易用性与交互性上实现了质的飞跃;主题建模与智能生成两大新模块的成功探索,为系统从"数据记录工具"向"智能决策辅助平台"的演进奠定了坚实基础。团队在解决复杂前端交互、算法轻量化部署以及大模型应用集成等方面积累了宝贵经验。后续我们将按计划持续推进,确保系统功能的完善与性能的稳定。