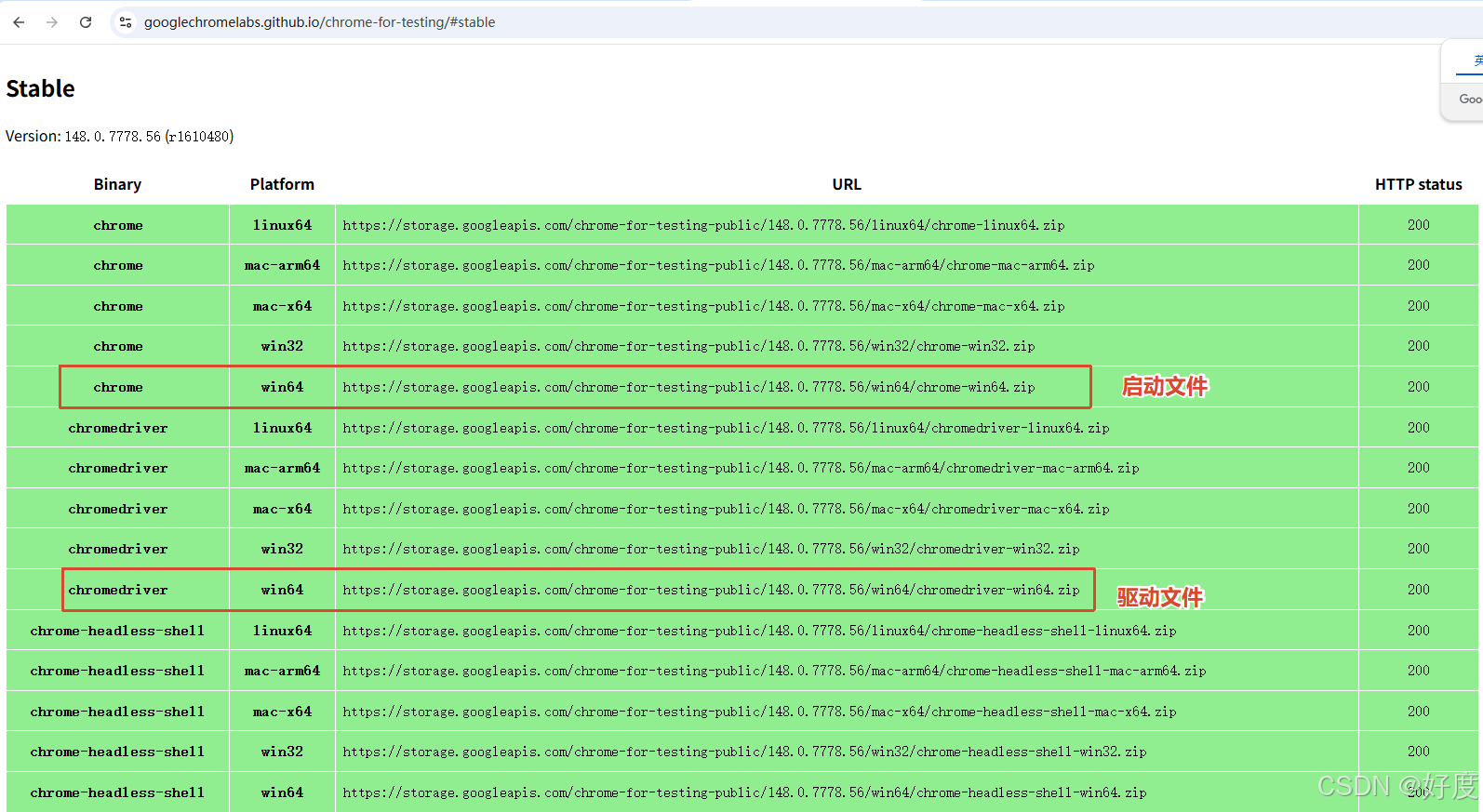
- 封装之前需要下载好(浏览器驱动)和(浏览器启动文件),并将其放置到data/browser_driver目录下
下载链接:https://googlechromelabs.github.io/chrome-for-testing/#stable
- 创建common目录(公共工具层),在这之下创建browser_start_config.py文件(浏览器启动配置)
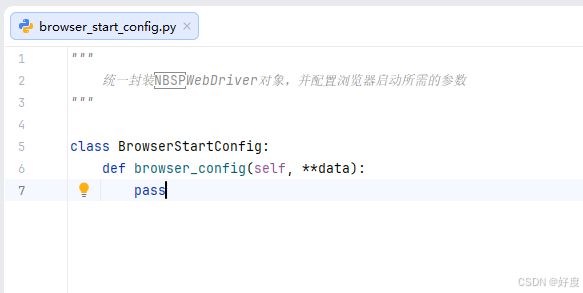
- 统一封装 WebDriver对象,并配置浏览器启动所需的参数
● 安装依赖库:Options、
● 首先先创建一个BrowserStartConfig类(名称自定义),然后创建一个browser_config方法(名称自定义),传参使用"**dada"(方便后续传多个参数)
python
"""
浏览器启动参数配置:统一封装 WebDriver(网页自动化)和 AppiumDriver(移动端自动化)的启动、关闭、复用逻辑,给框架提供一个"标准的驱动入口"。
"""
import time
# 导入Chrome驱动
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 共同工具类
from common.utils import Utils
# 文件操作类
from common.file_operations import FileOperations
class BrowserStartConfig:
utils = Utils()
file_operations = FileOperations()
# WebDriver--------------------------------------------------------------------------------------------------------
def browser_config(self, **data):
"""
简化版 browser_config,所有可选参数通过 **data 传入。
支持的键(都为可选):
- add_argument (bool) : 是否开启无痕模式(兼容你原名),默认 False
- binary_location (str): Chrome 可执行文件路径
返回:
- webdriver.Chrome 实例(并把它绑定到 self.driver)
"""
# 获取项目所在路径
project_path = self.utils.get_project_root()
# 创建一个ChromeOptions对象,用于指定Chrome浏览器的启动选项
chrome_options = Options()
# 1. 是否开启无痕, 默认不开启,True开启, False不开启
if data.get('add_argument', False):
# 开启无痕
chrome_options.add_argument('--incognito')
# 2. 指定浏览器的启动文件路径,如果不传入,就指定默认路径【注意不是驱动路径,而是浏览器软件的启动文件】
binary_location = data.get('binary_location', rf"{project_path}\data\Browser_related_files\chrome-win64\chrome.exe")
chrome_options.binary_location = binary_location
# 3. 禁用提示
# 隐藏"Chrome正受到自动测试软件控制"提示
chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])
# 当启动 Chrome 时,默认会自动加载一个名为 "自动化扩展" 的内部插件。这个插件的作用是帮助 WebDriver 控制浏览器,但会带来两个问题:顶部会显示一条提示、暴露出自动化特征,容易被反爬
chrome_options.add_experimental_option('useAutomationExtension', False)
# 告诉 Chrome 启动时不要检查它是否被设置为系统的默认浏览器
chrome_options.add_argument("--no-default-browser-check")
# 禁用通知:谷歌浏览器默认会让网站弹出通知权限,这在自动化中会变成意外的弹窗,干扰流程或导致元素无法操作
chrome_options.add_argument("--disable-notifications")
# 禁用提示:"Chrome 测试版vxxx仅适用于自动测试。若要进行常规浏览,请使用可自动更新的标准版 Chrome。"
chrome_options.add_argument('--test-type=gpu')
# 4. 浏览器文件下载默认目录
download_subdir = rf"{self.utils.get_project_root()}\data\浏览器文件下载目录\{self.utils.data_skew(data_format='%Y%m%d')}"
# 将浏览器的默认下载目录写入yaml文件中,以防后续会有用例用到
self.file_operations.update_yaml(file_name='config.yaml',
update_data_dict={'浏览器下载文件默认路径': download_subdir})
# 5. 浏览器配置项(用户偏好)
prefs = {
'profile': {'password_manager_enabled': False}, # 也是禁用密码保存提示框,确保密码管理彻底关闭
# 是否允许网站自动连续下载多个文件。1允许,0不允许。
"profile.default_content_setting_values.automatic_downloads": 1,
# 是否弹出"保存文件"提示框。False不弹出,True弹出
"download.prompt_for_download": False,
# 指定浏览器下载文件时所保存的目录。
"download.default_directory": download_subdir,
# 这个设置用于升级下载目录的权限。在某些情况下,如果下载目录的权限不足,这个选项可以帮助确保下载能够成功进行。
"download.directory_upgrade": True,
# 这个设置用于控制是否启用安全浏览功能,该功能可以检测并警告用户潜在的恶意网页。在这个场景中,禁用它可以防止下载安全浏览相关的警告或干扰。
"safebrowsing.enabled": False
}
# 将配置项应用到浏览器启动项中
chrome_options.add_experimental_option('prefs', prefs)
# 6. 浏览器窗口最大化
chrome_options.add_argument('--start-maximized')
# 7. 定义(浏览器驱动)文件所在目录
service = Service(executable_path=rf'{project_path}\data\Browser_related_files\chromedriver-win64\chromedriver.exe')
# 8. 设置驱动能力,隐藏自动化特征
driver_s = webdriver.Chrome(service=service, options=chrome_options)
# 另一种隐藏浏览器自动化特征的方法(JS注入)【备用的冗余】
driver_s.execute_script("""
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
""")
# 返回配置项
return driver_s- 创建utils文件(通用工具类),创建"获取项目所在路径"方法
python
# 获取当前项目根目录: 这个函数不要动,所在文件夹名称也不要修改,否则会获取不到
def get_project_root(self):
# 获取当前脚本文件的完整路径
current_file_path = __file__
# 获取当前脚本文件所在的目录路径
current_directory = os.path.dirname(current_file_path)
parts = current_directory.rsplit(os.path.sep, 1) # 分割一次
if len(parts) == 2:
# 如果确实存在分隔符,则parts[0]是除了最后一部分之外的所有路径
new_path = parts[0]
else:
# 如果没有找到分隔符(比如路径是根目录或只有一个部分),则path就是new_path
new_path = current_directory
# 返回项目路径
return new_path- 创建file_operations文件(文件操作类),创建(读取Yaml、指定读取data目录Yaml、写入Yaml、更新Yam)4个方法
python
# 读取yaml文件
def read_yaml(self, yaml_path):
"""
:param yaml_path: yaml文件路径
:return:
"""
# 打开yaml文件
file = open(yaml_path, 'r', encoding='utf-8')
# 读取yaml文件
data = yaml.load(file, Loader=yaml.SafeLoader)
return data
# 写入Yaml文件: 会覆盖整个文件中的数据。输入data目录下的文件名称, 返回该文件内指定文件名的文件中【特殊方法】
def write_data_folder(self, file_name, data):
"""
:param file_name: 文件名称【该文件需要再data目录下】
:param data: 需要写入的数据【需字典格式】
:return:
"""
# 通过文件名称获取(文件路径)
file_path = self.utils.search_file(rf'{self.utils.get_project_root()}\data', rf'{file_name}')
# 打开文件
with open(file_path, 'w', encoding='utf-8') as f:
# 写入文件
yaml.dump(data=data, stream=f, allow_unicode=True)
print('------写入yaml文件成功')
# 更新yaml
# 不会覆盖文件中原有数据,存在则更新,不存在则新增
def update_yaml(self, file_name, update_data_dict):
"""
:param file_name: 需要写入的文件名称, 注意,该文件必须在data目录下才行
:param update_data_dict: 需要写入的数据字典, 如:{'token>uuc_token': '666'...}, token代表父级, uuc_token代表子级,666代表值
:return:
"""
# 读取yaml文件(这个函数是读取yaml函数,可以看上面的)
data = self.read_data_yaml_file(file_name)
# 更新数据
for key, value in update_data_dict.items():
# 将层级管理用>符号分隔开
parts = key.split('>')
current = data
for part in parts[:-1]:
if part not in current:
current[part] = {}
current = current[part]
current[parts[-1]] = value
# 写入yaml文件
self.write_data_folder(file_name, data)在utils文件补上(通过文件名称获取文件路径)方法
python
# 搜索某个文件夹下所有文件, 输入文件名,可以获取该文件的所在绝对路径
def search_file(self, dir_path, file_name):
""" 可以层层往下找
:param dir_path: 文件夹路径
:param file_name: 文件夹内文件的名称,需要加后缀
:return:
"""
for root, dirs, files in os.walk(dir_path):
for file in files:
if file == file_name:
return os.path.join(root, file)
return None- 测试浏览器驱动类是否配置成功,运行"browser_start_config.py"文件里面的"browser_config"方法,如果能弹出如下界面,则说明类封装成功
封装成功