目录
ANN = Artificial Neural Network -人工神经网络
一、神经网络搭建设计思路
1、构建数据集
2、构建模型
3、模型训练
4、模型评估5、模型优化
二、案例需求分析
小明创办了一家手机公司,他不知道如何估算手机产品的价格。为了解决这个问题,他收集了多家公司的手机销售数据。该数据为二手手机的各个性能的数据,最后根据这些性能得到4个价格区间,作为这些二手手机售出的价格区间。主要包括:

我们需要帮助小明找出手机的功能(例如:RAM等)与其售价之间的某种关系。我们可以使用机器学习的方法来解决这个问题,也可以构建一个全连接的网络。
需要注意的是: 在这个问题中,我们不需要预测实际价格,而是一个价格范围,它的范围使用 0、1、2、3 来表示,所以该问题也是一个分类问题。接下来我们还是按照步骤来完成这个任务。
设计要求:
构建全连接神经网络来进行手机价格分类,该网络主要由三个线性层来构建,使用relu激活函数。 网络共有 3 个全连接层, 具体信息如下:
第一层: 输入为维度为 20, 输出维度为: 128
第二层: 输入为维度为 128, 输出维度为: 256
第三层: 输入为维度为 256, 输出维度为: 4
三、分步搭建神经网络
1、构建数据集
(1) 导入数据
(2) 数据类型转换
(3) 数据集切分
(4) 数据集转换为张量数据集
(5) 返回数据
代码如下:
python
# 导入相关模块
import torch
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torch.nn as nn
from torchsummary import summary
import torch.optim as optim
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import time
# todo:1-构建数据集
def create_dataset():
print('===========================构建张量数据集对象===========================')
# todo:1-1 加载csv文件数据集
data = pd.read_csv('data/手机价格预测.csv')
print('data.head()->', data.head())
print('data.shape->', data.shape)
# todo:1-2 获取x特征列数据集和y目标列数据集
# iloc属性 下标取值
x, y = data.iloc[:, :-1], data.iloc[:, -1]
# 将特征列转换成浮点类型
x = x.astype(np.float32)
print('x->', x.head())
print('y->', y.head())
# todo:1-3 数据集分割 8:2
x_train, x_valid, y_train, y_valid = train_test_split(x, y, train_size=0.8, random_state=88)
# todo:1-4 数据集转换成张量数据集
# x_train,y_train类型是df对象, df不能直接转换成张量对象
# x_train.values():获取df对象的数据值, 得到numpy数组
# torch.tensor(): numpy数组对象转换成张量对象
train_dataset = TensorDataset(torch.tensor(data=x_train.values), torch.tensor(data=y_train.values))
valid_dataset = TensorDataset(torch.tensor(data=x_valid.values), torch.tensor(data=y_valid.values))
# todo:1-5 返回训练数据集, 测试数据集, 特征数, 类别数
# shape->(行数, 列数) [1]->元组下标取值
# np.unique()->去重 len()->去重后的长度 类别数
print('x.shape[1]->', x.shape[1])
print('len(np.unique(y)->', len(np.unique(y)))
return train_dataset, valid_dataset, x.shape[1], len(np.unique(y))
if __name__ == '__main__':
train_dataset, valid_dataset, input_dim, class_num = create_dataset()2、构建模型
(1) 构造神经网络__init__方法
(2) 前向传播方法forward()
代码如下:
python
# todo:2-构建神经网络分类模型
class PhonePriceModel(nn.Module):
print('===========================构建神经网络分类模型===========================')
# todo:2-1 构建神经网络 __init__()
def __init__(self, input_dim, output_dim):
# 继承父类的构造方法
super().__init__()
# 第一层隐藏层
self.linear1 = nn.Linear(in_features=input_dim, out_features=128)
# 第二层隐藏层
self.linear2 = nn.Linear(in_features=128, out_features=256)
# 输出层
self.output = nn.Linear(in_features=256, out_features=output_dim)
# todo:2-2 前向传播方法 forward()
def forward(self, x):
# 第一层隐藏层计算
x = torch.relu(input=self.linear1(x))
# 第二层隐藏层计算
x = torch.relu(input=self.linear2(x))
# 输出层计算
# 没有进行softmax激活计算, 后续创建损失函数时CrossEntropyLoss=softmax+损失计算
output = self.output(x)
return output
# todo:3-模型训练
# todo:4-模型评估
if __name__ == '__main__':
# 创建张量数据集对象
train_dataset, valid_dataset, input_dim, class_num = create_dataset()
# 创建模型对象
model = PhonePriceModel(input_dim=input_dim, output_dim=class_num)
# 计算模型参数
# input_size: 输入层样本形状
summary(model, input_size=(16, input_dim))重点知识点:计算模型参数
通过torchsummary模块导入summary计算模型参数
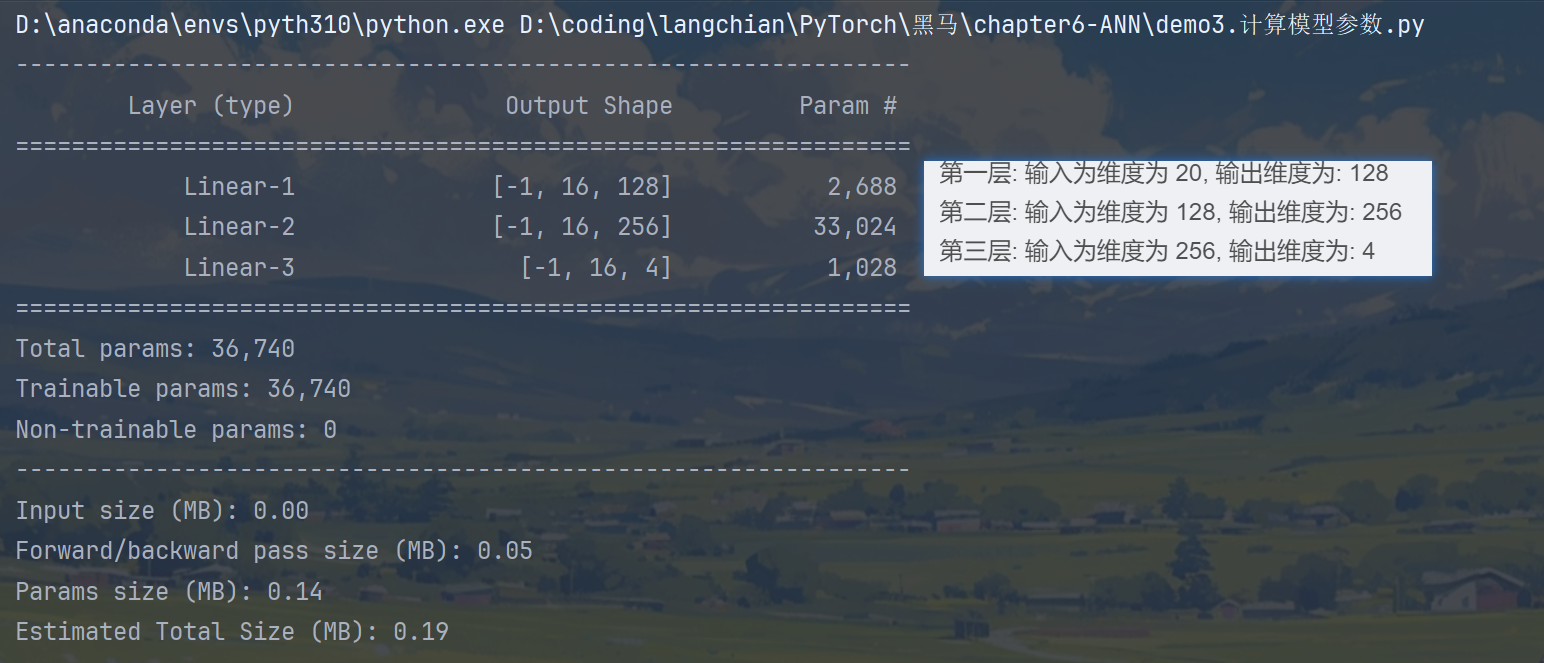
然后我们结合设计的模型计算一下参数:
输入层: 20+1= 21
隐藏层1:21 * 128 =2688
隐藏层2: 129 * 256=33024
输出层: 257 *4 = 1028
总参数:2688+33024+1028 = 36740
3、模型训练
(1) 创建数据加载器 批量训练
(2) 创建神经网络模型,初始化w和b
(3) 创建损失函数对象 多分类交叉熵损失=softmax+损失计算
(4) 创建优化器对象 SGD
(5) 模型训练 min-batch 随机梯度下降
代码如下:
python
# todo:3-模型训练
def train(train_dataset, input_dim, class_num):
print('===========================模型训练===========================')
# todo:3-1 创建数据加载器 批量训练
dataloader = DataLoader(dataset=train_dataset, batch_size=8, shuffle=True)
# todo:3-2 创建神经网络分类模型对象, 初始化w和b
model = PhonePriceModel(input_dim=input_dim, output_dim=class_num)
print("======查看模型参数w和b======")
for name, parameter in model.named_parameters():
print(name, parameter)
# todo:3-3 创建损失函数对象 多分类交叉熵损失=softmax+损失计算
criterion = nn.CrossEntropyLoss()
# todo:3-4 创建优化器对象 SGD
optimizer = optim.SGD(params=model.parameters(), lr=1e-3)
# todo:3-5 模型训练 min-batch 随机梯度下降
# 训练轮数
num_epoch = 50
for epoch in range(num_epoch):
# 定义变量统计每次训练的损失值, 训练batch数
total_loss = 0.0
batch_num = 0
# 训练开始的时间
start = time.time()
# 批次训练
for x, y in dataloader:
# 切换模型模式
model.train()
# 模型预测 y预测值
y_pred = model(x)
# print('y_pred->', y_pred)
# 计算损失值
loss = criterion(y_pred, y)
# print('loss->', loss)
# 梯度清零
optimizer.zero_grad()
# 计算梯度
loss.backward()
# 更新参数 梯度下降法
optimizer.step()
# 统计每次训练的所有batch的平均损失值和和batch数
# item(): 获取标量张量的数值
total_loss += loss.item()
batch_num += 1
# 打印损失变换结果
print('epoch: %4s loss: %.2f, time: %.2fs' % (epoch + 1, total_loss / batch_num, time.time() - start))
# todo:3-6 模型保存, 将模型参数保存到字典, 再将字典保存到文件
torch.save(model.state_dict(), 'model/phone.pth')
if __name__ == '__main__':
# 创建张量数据集对象
train_dataset, valid_dataset, input_dim, class_num = create_dataset()
# 创建模型对象
# model = PhonePriceModel(input_dim=input_dim, output_dim=class_num)
# 计算模型参数
# input_size: 输入层样本形状
# summary(model, input_size=(16, input_dim))
# 模型训练
train(train_dataset=train_dataset, input_dim=input_dim, class_num=class_num)4、模型评估
(1)创建神经网络分类模型对象
(2) 加载训练模型的参数字典
(3) 创建测试集数据加载器
(4) 定义变量, 初始值为0, 统计预测正确的样本个数
(5) 按batch进行预测
代码如下:
python
# todo:4-模型评估
def test(valid_dataset, input_dim, class_num):
# todo:4-1 创建神经网络分类模型对象
model = PhonePriceModel(input_dim=input_dim, output_dim=class_num)
# todo:4-2 加载训练模型的参数字典
model.load_state_dict(torch.load(f='model/phone.pth'))
# todo:4-3 创建测试集数据加载器
# shuffle: 不需要为True, 预测, 不是训练
dataloader = DataLoader(dataset=valid_dataset, batch_size=8, shuffle=False)
# todo:4-4 定义变量, 初始值为0, 统计预测正确的样本个数
correct = 0
# todo:4-5 按batch进行预测
for x, y in dataloader:
print('y->', y)
# 切换模型模式为预测模式
model.eval()
# 模型预测 y预测值 -> 输出层的加权求和值
output = model(x)
print('output->', output)
# 根据加权求和值得到类别, argmax() 获取最大值对应的下标就是类别 y->0,1,2,3
# dim=1:一行一行处理, 一个样本一个样本
y_pred = torch.argmax(input=output, dim=1)
print('y_pred->', y_pred)
# 统计预测正确的样本个数
print(y_pred == y)
# 对布尔值求和, True->1 False->0
print((y_pred == y).sum())
correct += (y_pred == y).sum()
print('correct->', correct)
# 计算预测精度 准确率
print('Acc: %.5f' % (correct.item() / len(valid_dataset)))
if __name__ == '__main__':
# 创建张量数据集对象
train_dataset, valid_dataset, input_dim, class_num = create_dataset()
# 创建模型对象
# model = PhonePriceModel(input_dim=input_dim, output_dim=class_num)
# 计算模型参数
# input_size: 输入层样本形状
# summary(model, input_size=(16, input_dim))
# 模型训练
# train(train_dataset=train_dataset, input_dim=input_dim, class_num=class_num)
# 模型评估
test(valid_dataset=valid_dataset, input_dim=input_dim, class_num=class_num)完整代码如下:
python
# 导包
import torch # PyTorch框架, 封装了张量的各种操作
from torch.utils.data import TensorDataset # 数据集对象. 数据 -> Tensor -> 数据集 -> 数据加载器
from torch.utils.data import DataLoader # 数据加载器.
import torch.nn as nn # neural network, 封装了神经网络的各种操作
import torch.optim as optim # 优化器
from sklearn.model_selection import train_test_split # 训练集和测试集的划分
import matplotlib.pyplot as plt # 绘图
import numpy as np # 数组(矩阵)操作
import pandas as pd # 数据处理
import time # 时间模块
from torchsummary import summary # 模型结构可视化
# todo 1. 定义函数, 构建数据集.
def create_dataset():
# 1. 加载csv文件数据集.
data = pd.read_csv('./data/手机价格预测.csv')
# print(f'data: {data.head()}')
# print(f'data: {data.shape}') # (2000, 21)
# 2. 获取x特征列 和 y标签列.
x, y = data.iloc[:, :-1], data.iloc[:, -1]
# print(f'x: {x.head()}, {x.shape}') # (2000, 20)
# print(f'y: {y.head()}, {y.shape}') # (2000, )
# 3. 把特征列转成浮点型.
x = x.astype(np.float32)
# print(f'x: {x.head()}, {x.shape}') # (2000, 20)
# 4. 切分训练集和测试集.
# 参1: 特征, 参2: 标签, 参3: 测试集所占比例, 参4: 随机种子, 参5: 样本的分布(即: 参考y的类别进行抽取数据)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=3, stratify=y)
# 5. 把数据集封装成 张量数据集. 思路: 数据 -> 张量Tensor -> 数据集TensorDataSet -> 数据加载器DataLoader
train_dataset = TensorDataset(torch.tensor(x_train.values), torch.tensor(y_train.values))
test_dataset = TensorDataset(torch.tensor(x_test.values), torch.tensor(y_test.values))
# print(f'train_dataset: {train_dataset}, test_dataset: {test_dataset}')
# 6. 返回结果 20(充当 输入特征数) 4(充当 输出标签数)
return train_dataset, test_dataset, x_train.shape[1], len(np.unique(y))
# todo 2. 搭建神经网络.
class PhonePriceModel(nn.Module):
# 1. 在init魔法方法中, 初始化父类成员, 及搭建神经网络.
def __init__(self, input_dim, output_dim): # 输入: 20, 输出: 4
# 1.1 初始化父类成员.
super().__init__()
# 1.2 搭建神经网络.
# 隐藏层1
self.linear1 = nn.Linear(input_dim, 128)
# 隐藏层2
self.linear2 = nn.Linear(128, 256)
# 输出层
self.output = nn.Linear(256, output_dim)
# 2. 定义前向传播方法 forward()
def forward(self, x):
# 2.1 隐藏层1: 加权求和 + 激活函数(relu)
# x = self.linear1(x)
# x = torch.relu(x)
x = torch.relu(self.linear1(x))
# 2.2 隐藏层2: 加权求和 + 激活函数(relu)
x = torch.relu(self.linear2(x))
# 2.3 输出层: 加权求和 + 激活函数(softmax) -> 这里只需要做 加权求和.
# 正常写法, 但是不需要, 后续用 多分类交叉熵损失函数 CrossEntropyLoss() 替代
# CrossEntropyLoss() = softmax() + 损失计算
# x = torch.softmax(self.output(x), dim=1)
x = self.output(x)
# 2.4 返回处理结果
return x
# todo 3. 模型训练.
def train(train_dataset, input_dim, output_dim):
# 1. 创建数据加载器, 流程: 数据 -> 张量 -> 数据集 -> 数据加载器
# 参1: 数据集对象(1600条), 参2: 每批次的数据条数, 参3: 是否打乱数据(训练集: 打乱, 测试集: 不打乱)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
# 2. 创建神经网络模型.
model = PhonePriceModel(input_dim, output_dim)
# 3. 定义损失函数, 因为是多分类, 这里用的是: 多分类交叉熵损失函数.
criterion = nn.CrossEntropyLoss()
# 4. 创建优化器对象.
optimizer = optim.SGD(model.parameters(), lr=0.001)
# 5. 模型训练.
# 5.1 定义变量, 记录训练的 总轮数.
epochs = 50
# 5.2 开始(每轮的)训练.
for epoch in range(epochs):
# 5.2.1 定义变量, 记录每次训练的损失值, 训练批次数.
total_loss, batch_num = 0.0, 0
# 5.2.2 定义变量, 表示训练开始的时间.
start = time.time()
# 5.2.3 开始本轮的 各个批次的训练.
for x, y in train_loader:
# 5.2.4 切换模型(状态)
model.train() # 训练模式. model.eval() # 测试模式.
# 5.2.5 模型预测.
y_pred = model(x)
# 5.2.6 计算损失.
loss = criterion(y_pred, y)
# 5.2.7 梯度清零, 反向传播, 优化参数.
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 5.2.8 累加损失值.
total_loss += loss.item() # 把本轮的每批次(16条)的 平均损失累计起来. 第1批次的平均损失 + 第2批次的平均损失 + ...
batch_num += 1
# 5.2.4 至此, 本轮训练结束, 打印训练信息.
print(f'epoch: {epoch + 1}, loss: {total_loss / batch_num:.4f}, time: {time.time() - start:.2f}s')
# 6. 走到这里, 说明多轮训练结束, 保存模型(参数)
# 参1: 模型对象的参数(权重矩阵, 偏置矩阵) 参2: 模型保存的文件名.
# print(f'\n\n模型的参数信息: {model.state_dict()}\n\n')
torch.save(model.state_dict(), './model/phone.pth') # 后缀名用: pth, pkl, pickle均可.
# todo 4. 模型测试.
def evaluate(test_dataset, input_dim, output_dim):
# 1. 创建神经网络分类对象.
model = PhonePriceModel(input_dim, output_dim)
# 2. 加载模型参数.
model.load_state_dict(torch.load('./model/phone.pth'))
# 3. 创建测试集的 数据加载器对象.
# 参1: 数据集对象(400条), 参2: 每批次的数据条数, 参3: 是否打乱数据(训练集: 打乱, 测试集: 不打乱)
test_loader = DataLoader(test_dataset, batch_size=8, shuffle=False)
# 4. 定义变量, 记录预测正确的样本个数.
correct = 0
# 5. 从数据加载器中, 获取到每批次的数据.
for x, y in test_loader:
# 5.1 切换模型状态 -> 测试模式.
model.eval()
# 5.2 模型预测.
y_pred = model(x)
# print(f'y_pred: {y_pred}') # [[0分类概率, 1分类概率, 2分类概率, 3分类概率], [...]...]
# 5.3 根据加权求和, 得到类别, 用argmax()获取最大值对应的下标, 就是类别.
y_pred = torch.argmax(y_pred, dim=1) # dim=1 表示逐行处理.
# print(f'y_pred: {y_pred}') # [第1条数据的预测分类, ...]
# print(f'y: {y}')
# 5.4 统计预测正确的样本个数.
# print(y_pred == y) # tensor([ True, True, True, True, False, False, True, False])
# print((y_pred == y).sum()) # True:1, False:0
correct += (y_pred == y).sum()
# 6.走到这里, 模型预测结束, 打印准确率即可.
print(f'准确率(Accuracy): {correct / len(test_dataset):.4f}')
# todo 5. 测试
if __name__ == '__main__':
# 1. 准备数据集.
train_dataset, test_dataset, input_dim, output_dim = create_dataset()
# print(f'训练集 数据集对象: {train_dataset}')
# print(f'测试集 数据集对象: {test_dataset}')
# print(f'输入特征数: {input_dim}') # 20
# print(f'输出标签数: {output_dim}') # 4
# 2. 构建神经网络模型.
# model = PhonePriceModel(input_dim, output_dim)
# 计算模型参数
# 参1: 模型对象. 参2: 输入数据的形状(批次大小, 输入特征数), 每批16条, 每条20列特征
# summary(model, input_size=(16, input_dim))
# 3. 模型训练
# train(train_dataset, input_dim, output_dim)
# 4. 模型测试.
evaluate(test_dataset, input_dim, output_dim)运行结果如下图:
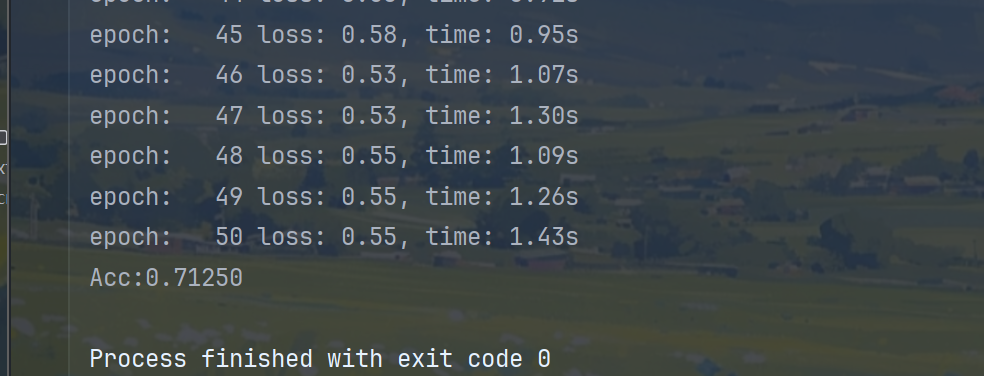
四、模型优化
**输入层数据进行标准化
- 神经网络层数增加, 神经元个数增加
- 梯度下降优化方法由SGD调整为Aam
- 学习率由1e-3调整为1e-4
- 正则化
- 增加训练轮数**
优化后代码如下:
python
import torch
import torch.nn as nn
import pandas as pd
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torch.optim as optim
import numpy as np
import time
from sklearn.preprocessing import StandardScaler
# 构建数据集
def create_dataset():
# 使用pandas读取数据
data = pd.read_csv('./data/手机价格预测.csv')
# 特征值和目标值
x, y = data.iloc[:, :-1], data.iloc[:, -1]
# 类型转换:特征值,目标值
x = x.astype(np.float32)
y = y.astype(np.int64)
# 数据集划分
x_train, x_valid, y_train, y_valid = train_test_split(x, y, train_size=0.8, random_state=88, stratify=y)
# 优化①:数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_valid = transfer.transform(x_valid)
# 构建数据集,转换为pytorch的形式
train_dataset = TensorDataset(torch.from_numpy(x_train), torch.tensor(y_train.values))
valid_dataset = TensorDataset(torch.from_numpy(x_valid), torch.tensor(y_valid.values))
# 返回结果
return train_dataset, valid_dataset, x_train.shape[1], len(np.unique(y))
# 构建网络模型
class PhonePriceModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(PhonePriceModel, self).__init__()
# 优化②:增加网络深度
# 1. 第一层: 输入为维度为 20, 输出维度为: 128
self.linear1 = nn.Linear(input_dim, 128)
# 2. 第二层: 输入为维度为 128, 输出维度为: 256
self.linear2 = nn.Linear(128, 256)
# 3. 第三层: 输入为维度为 256, 输出维度为: 512
self.linear3 = nn.Linear(256, 512)
# 4. 第四层: 输入为维度为 512, 输出维度为: 128
self.linear4 = nn.Linear(512, 128)
# 5. 输出层: 输入为维度为 128, 输出维度为: 4
self.linear5 = nn.Linear(128, output_dim)
def forward(self, x):
# 前向传播过程
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
x = torch.relu(self.linear3(x))
x = torch.relu(self.linear4(x))
# 后续CrossEntropyLoss损失函数中包含softmax过程, 所以当前步骤不进行softmax操作
output = self.linear5(x)
# 获取数据结果
return output
# 编写训练函数
def train(train_dataset, input_dim, class_num):
# 固定随机数种子
torch.manual_seed(0)
# 初始化数据加载器
dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8)
# 初始化模型
model = PhonePriceModel(input_dim, class_num)
# 损失函数 CrossEntropyLoss = softmax + 损失计算
criterion = nn.CrossEntropyLoss()
# 优化③:使用Adam优化方法, 优化④:学习率变为1e-4
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 遍历每个轮次的数据
num_epoch = 50
for epoch_idx in range(num_epoch):
# 训练时间
start = time.time()
# 计算损失
total_loss = 0.0
total_num = 0
# 遍历每个batch数据进行处理
for x, y in dataloader:
model.train()
output = model(x)
# 计算损失
loss = criterion(output, y)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 损失计算
total_num += len(y)
total_loss += loss.item() * len(y)
# 打印损失变换结果
print('epoch: %4s loss: %.2f, time: %.2fs' %
(epoch_idx + 1, total_loss / total_num, time.time() - start))
# 模型保存
torch.save(model.state_dict(), './model/phone-price-model2.pth')
def evaluate(valid_dataset, input_dim, class_num):
# 加载模型和训练好的网络参数
model = PhonePriceModel(input_dim, class_num)
# load_state_dict:将加载的参数字典应用到模型上
# load:加载用来保存模型参数的文件
model.load_state_dict(torch.load('./model/phone-price-model2.pth'))
# 构建加载器
dataloader = DataLoader(valid_dataset, batch_size=8, shuffle=False)
# 评估测试集
correct = 0
# 遍历测试集中的数据
for x, y in dataloader:
# 将其送入网络中
model.eval()
output = model(x)
# 获取预测类别结果
y_pred = torch.argmax(output, dim=1)
# 获取预测正确的个数
correct += (y_pred == y).sum()
# 求预测精度
print('Acc: %.5f' % (correct / len(valid_dataset)))
if __name__ == '__main__':
train_dataset, valid_dataset, input_dim, class_num = create_dataset()
train(train_dataset, input_dim, class_num)
evaluate(valid_dataset, input_dim, class_num)优化后结果如下图:
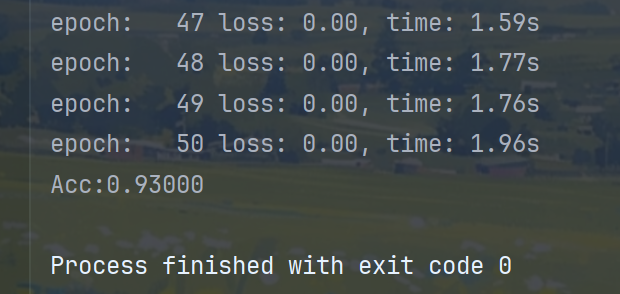
两者对比:

以上就是用神经网络进行手机价格分类处理的全过程。开始训练的准确率可能因为未设置随机种子导致每次训练结果不一致,每次执行的结果会有差异。但是最终优化完的输出结果应该是一致的。
案例总结:
1、通过优化策略,手机分类模型的准确率明显提高了20%左右。
2、开始几次损失下降最快,并且用时较少,后续逐渐平缓。