机器学习
定义类别 类别A 类别B 类别C
收集数据 A类文本 B类文本 C类文本
模型训练 分类器
预测 未知类别文本 预测文本
贝叶斯算法
全概率公式:
设事件组{Bi} 是样本空间的一个划分, 且P(Bi) >0(i=1,2,...n)则对任一事件,有P(A) = P(Bi)P(A|Bi) (i=1,2,3,...n)
举例
P(B1) = 结果为奇数
P(B2) = 结果为偶数
P(A) = 结果为5
P(A) = P(B1)*P(A|B1) + P(B2)*P(A|B2)
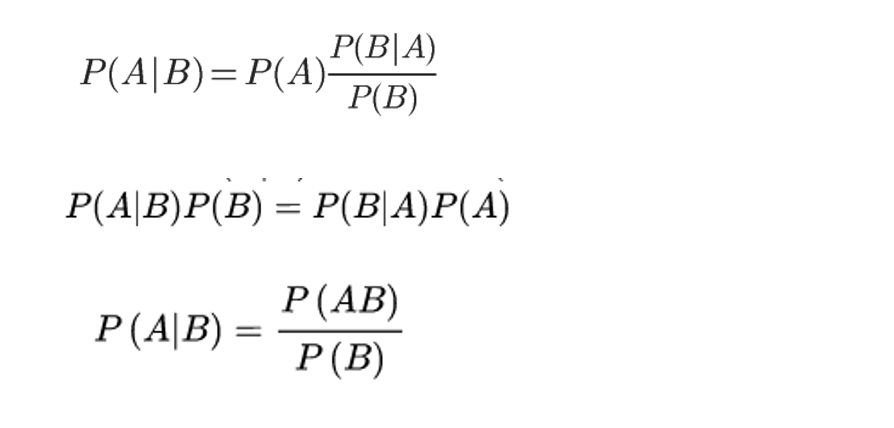
贝叶斯公式在NLP中的应用
用贝叶斯公式处理文本分类任务
一个合理假设:
文本属于哪个类别,与文本中包含哪些词相关
任务:
知道文本中有哪些词,预测文本属于某类别的概率
文本分类
假定有3个类别 A1,A2,A3
一个文本S有n个词组成,W1,W2,W3...Wn
想要计算文本S属于A1类别的概率P(A1|S) = P(A1|W1,W2,W3..Wn)
贝叶斯公式
P(W1,W2..Wn|A3) 就是 P(W1|A3) 可能会出现0,那么就会出现平滑问题

贝叶斯算法的缺点
如果样本不均衡就会极大影响先验概率
对于未见过的特征或样本,条件概率为零,失去预测的意义(可以引入平滑)
特征独立假设只是个假设
4.没有考虑语序,也没有词义
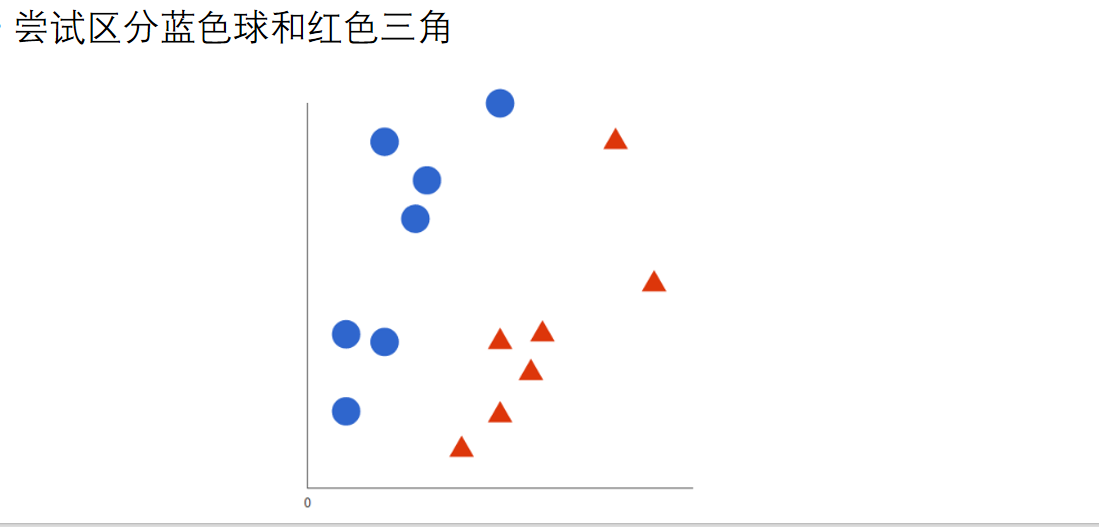
支持向量机
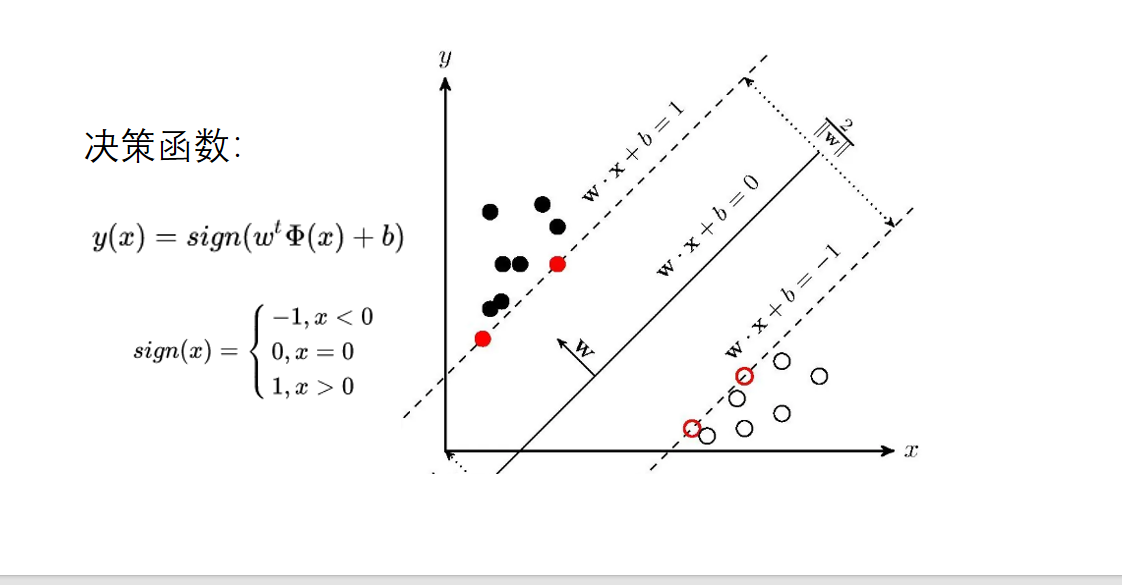
在灰线和黑线我们采取黑线,因为无论离蓝色还是红色距离都比较远
那如果难点呢,上面的问题颜色不同的球差那么远,一条直线就够了,如果两侧都有颜色不同的点,怎么办?
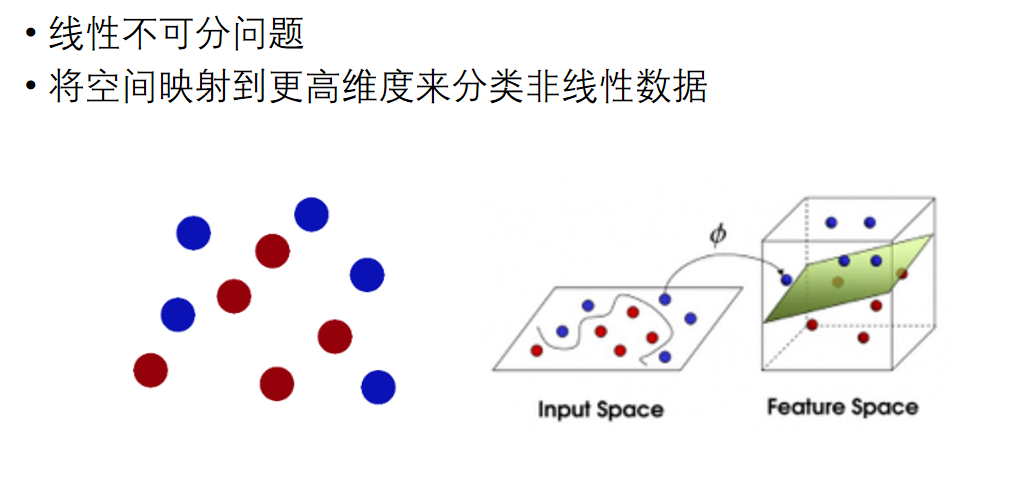
那么怎么做到线性不可分的问题,神经网络的激活函数,可以让模型本身变成非线性模型
那么支持向量机则是通过升维的思想,认为低纬的线性不可分的点变成高维可分的
向高维映射如何解决线性不可分问题?
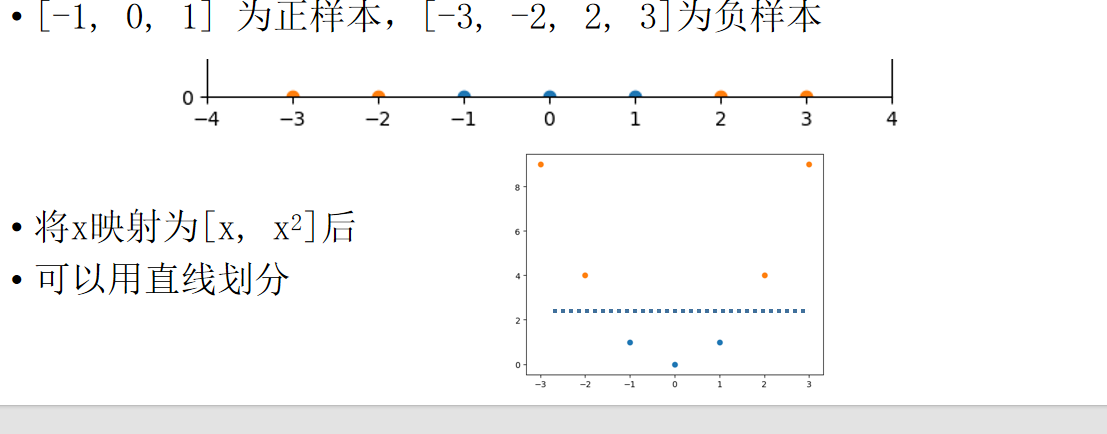
考虑一组一维数据
-1,0,1 为正样本,-3,-2,2,3 为负样本
将x 映射为x,x\^2
可以用直线划分
但是这样出现了一个问题,维度过高的向量计算在进行内积运算非常耗时,而SVM的求解中内积运算很频繁
所以我们希望内有一种方法快速计算 y(x1)*y(x2)
所谓的核函数即为满足条件:K(x1,x2) = y(x1)*y(x2) 的函数统称
那么向量机怎么解决多分类问题呢?
假设要解决一个K分类问题,即有K个目标类别
one VS one 方式
建立 K(K-1)/2 个svm分类器,每个分类器负责k个类别中的两个类别,判断1输入样本属于哪个类别
对于一个待预测的样本,使用所有分类器进行分类,最后保留被预测词数最多的类别
假设类别有A,B,C
X - > SVM(A,B) ->A
X - > SVM(A,C) ->A
X - > SVM(B,C) ->B
最终判断 X->A
还有另一方法

深度学习
代码框架
config.py 输入模型配置参数,如学习率
loader.py 加载数据集,做预处理,为训练做准备
model.py 定义神经网络模型结构
evaluate.py 定义评价指标,每轮训练后做评测
main.py 模型训练主流程
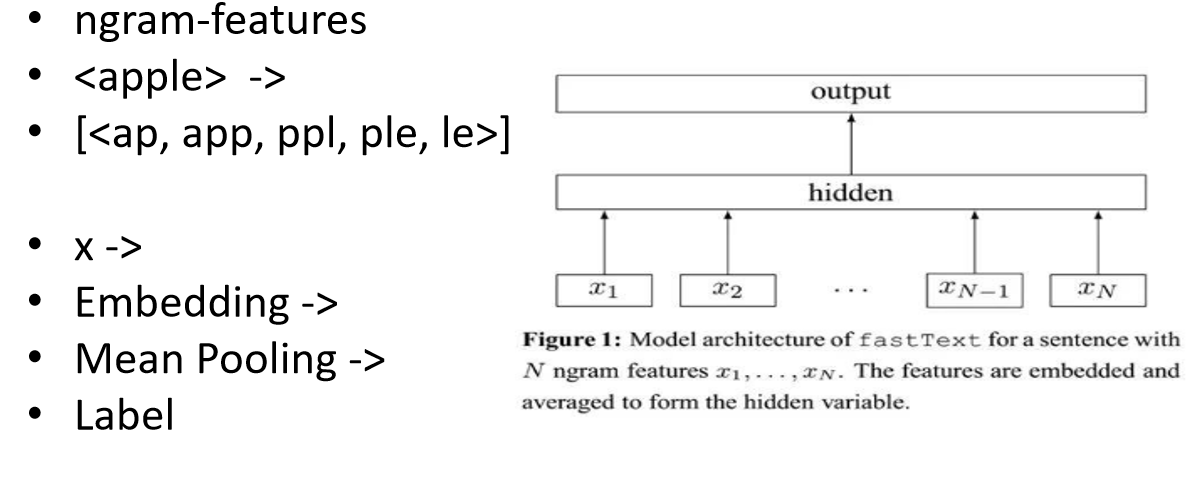
文本分类 - fastText
文本分类 -TextRNN
使用RNN对文本进行编码,使用最后一个位置的输出向量进行分类
x -> embedding ->BiLSTM ->Dropout - >LSTM ->Linear ->softmax - >y
RNN虽然能解决上下文问题,但是依然存在长期依赖问题不足,而LSTM则是加强版的RNN
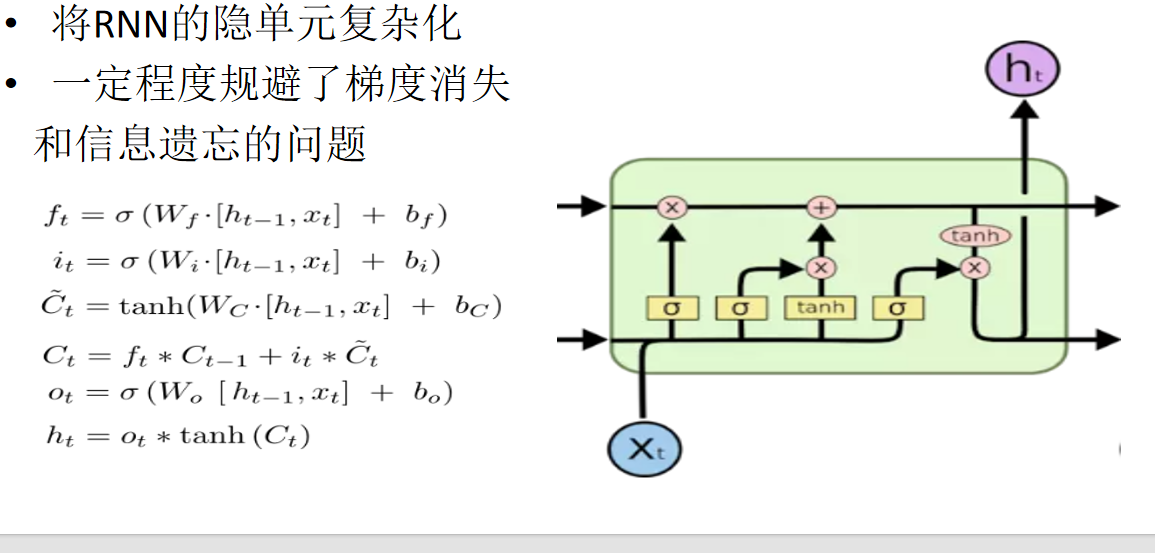
文本分类-LSTM
将RNN的隐单元复杂化
一定程度上规避了梯度消失和信息遗忘问题
ft 是遗忘门 it是输入们 ot是输出们 Ct是细胞状态 ht隐藏状态
另外 W的权重是4个拼起来的
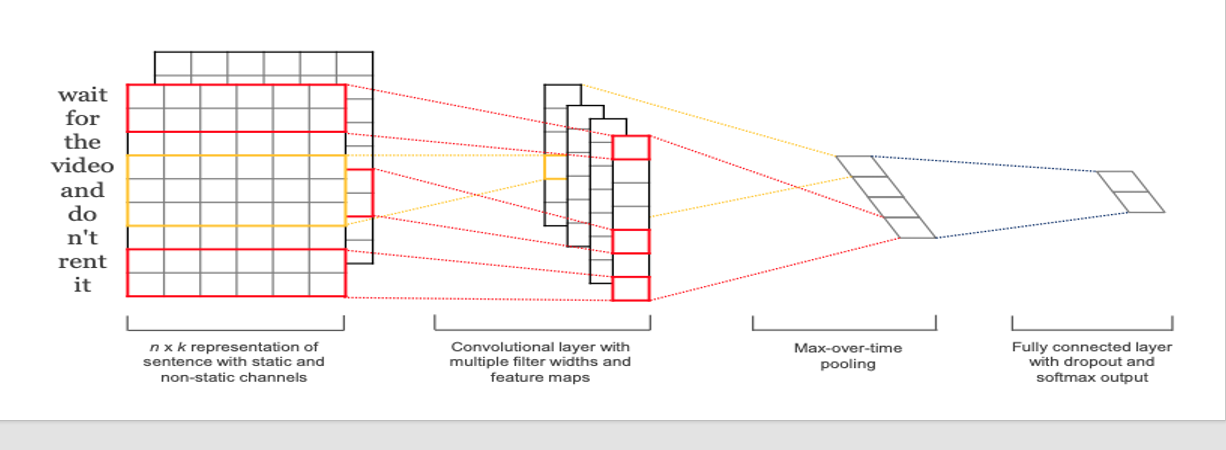
文本分类 -TextCNN 卷积神经网络 不是只能用于图像,也可以用于文本
利用一维卷积对文本进行编码
编码后的文本矩阵通过pooling转化为向量,用于分类
文本分类 -TextRCNN 就是 先过RNN再过CNN
文本分类 - Bert
Bert作为Encoder将文本转化为向量或矩阵
对于Bert的编码结果,有多种的使用方式
去cls token对应的向量
将整句话的向量取max/average pooline
将Bert编码后的向量再输入LSTM或CNN
将Bert中间层的结果取出加入运算等
数据稀疏问题
训练数据量小,模型在训练样本上能收敛,但预测准确率很低
解决方案:
1.标注更多的数据
尝试构造训练样本(数据增强)
更换模型(如使用预训练模型等) 减少数据需求
增加规则弥补
调整阈值,用召回率换准确率
重新定义类别(减少类别)
标签不平衡问题
部分类别样本充裕,部分类别样本极少
解决办法:
解决数据稀疏的所有的方法依然适用
1.过样本: 复制指定类别的样本,在采样中重复
2.降样本 减少多样本类别的采样,随机使用部分
3.调整样本权重 通过损失函数权重调整来体现
多标签分类
多标签问题的转化
1.分解为多个独立的二分类问题
2.将多标签分类问题转换为多分类问题
3.更换loss直接由模型进行多标签分类 (BCELOSS)
多标签不同于多分类
多标签 是 m选n
多分类 是 n选一