一、概要
普通 Mean Teacher 只有一个 teacher,容易产生错误伪标签并不断强化错误;而普通双教师又容易两个 teacher 太相似,所以作者提出让两个 teacher 交替、随机、差异化更新,并且让 student 学习两个 teacher 的一致区域和冲突区域。
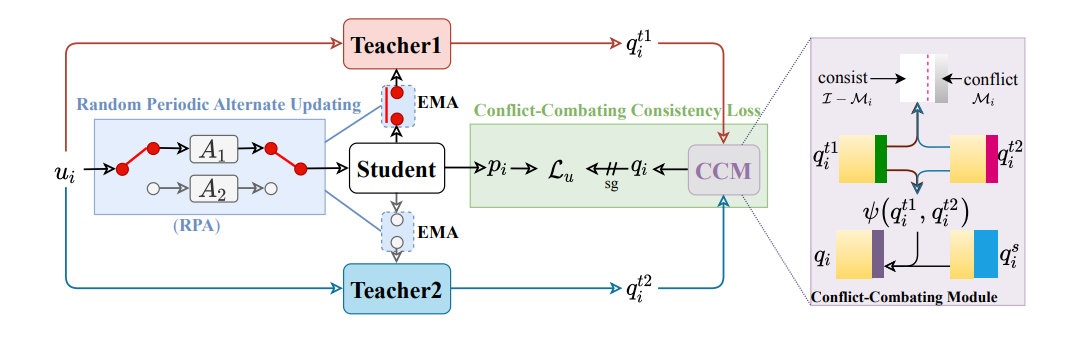
二、整体结构
AD-MT 有三个模型:Student, Teacher1, Teacher2
其中:
- Student 是可训练的;
- Teacher1 和 Teacher2 不反向传播;
- 两个 teacher 都由 student 通过 EMA 更新;
- 但不是每次都同时更新两个 teacher,而是 交替更新。
整体结构可以理解为:
或
每个 iteration 只更新其中一个 teacher。
三、RPA 随机周期交替更新
RPA 全称是 Random Periodic Alternate Updating Module。
它的作用是让两个 teacher 不要太像。
作者用了三种策略制造差异:
第一,交替更新。每次只更新一个 teacher,而不是两个 teacher 同时 EMA 更新。
第二,不同增强策略。Teacher1 和 Teacher2 对应不同的数据增强,例如论文中 Teacher1 使用 color jitter,Teacher2 使用 copy-paste。
第三,随机切换周期。不是固定每隔多少 iteration 切换 teacher,而是在一个最大周期内随机选择切换时间。
这样做的目的就是让两个 teacher 形成不同的"教学视角"。
四、CCM 冲突处理模块
CCM 全称是 Conflict-Combating Module。
普通双教师方法通常会:
- 对两个 teacher 平均;
- 或者只保留两个 teacher 一致的预测;
- 对冲突区域直接丢弃。
但 AD-MT 认为:
teacher 之间的冲突区域并不一定没用,反而可能包含更有价值的不确定信息。
所以 CCM 做了两件事:
第一,处理一致区域
如果两个 teacher 预测一致,就用两个 teacher 的集成结果作为伪标签。
集成方式不是简单平均,而是基于熵加权:
熵越低,说明越自信,权重越大。
第二,处理冲突区域
如果两个 teacher 预测冲突,作者不是直接丢弃,而是比较:
- teacher ensemble 的熵;
- student 自己预测的熵。
谁的熵更低,就用谁作为最终监督信号。
也就是说:
当 teacher 有冲突时,如果 student 自己更确定,就允许 student 的判断参与伪标签生成。
这是 AD-MT 比普通双教师更有意思的地方。
五、损失函数
总体损失为:
其中: 是有标签数据上的监督损失,一般是 Dice + CE。
是无标签数据上的一致性损失,由两个 teacher 和 CCM 生成最终伪标签后监督 student。