背景
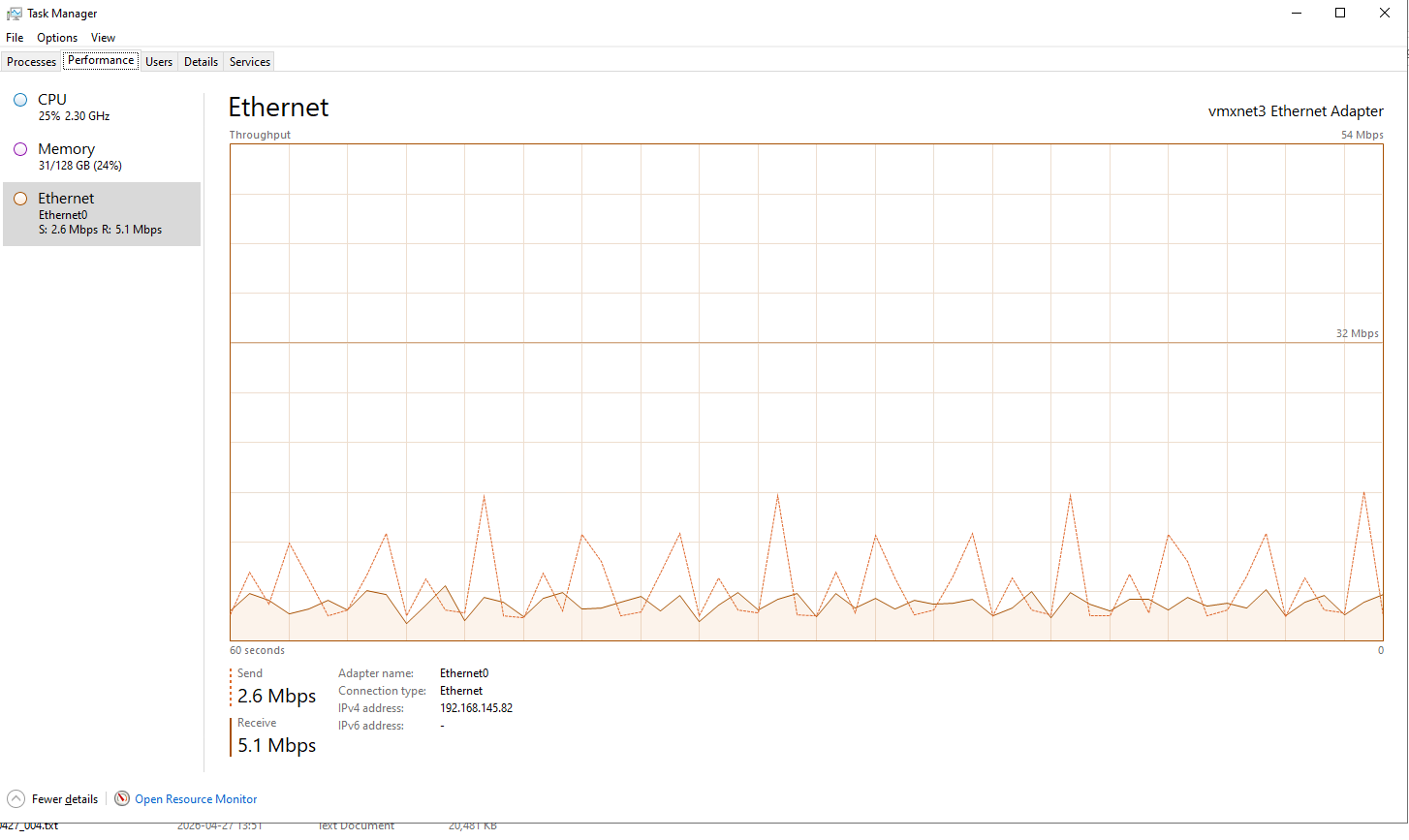
我用.net8 开发的数采和实时数据库产品在一个实际项目中遇到了性能瓶颈,表现为性能监视下网络发送流量出现断流和尖峰的情况,两个进程之间的通讯在断流时会有几秒钟的阻塞,我开始以为是网络的问题,实际是短时大量的Task阻塞了线程池,使得新的请求被迫排队等待,再就是内存开销大造成GC压力较大。
应用场景介绍
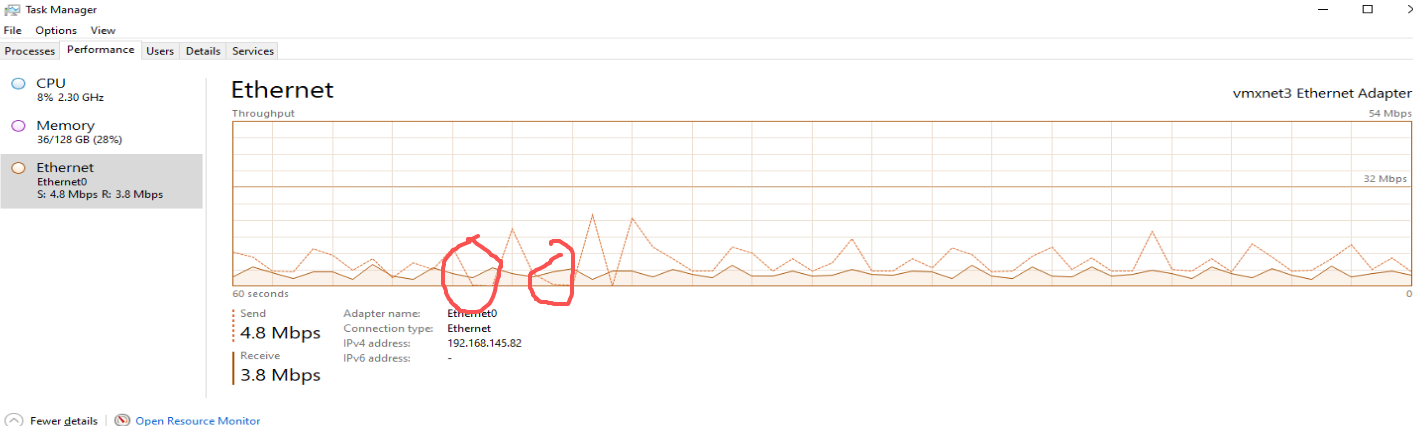
我的数采服务要从EMQX订阅数据后写入到实时数据库,数据量大约17000点/秒,每个点约30个字节,也就是510Kb数据,实际流量看数据格式,从EMQX过来的JSON格式,流量要大好几倍。
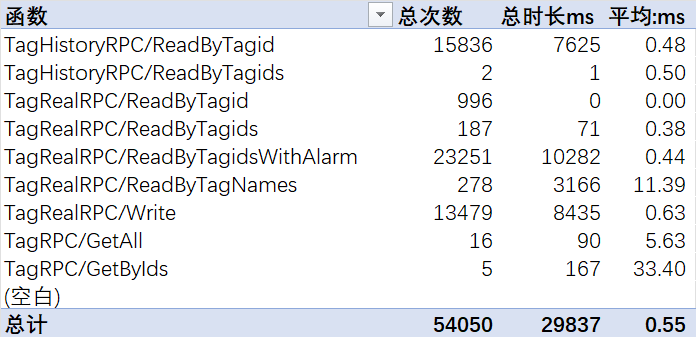
实时数据库要对外提供实时监视和历史曲线,访问频率为90次/秒,实时调用的响应很快,历史数据读取要慢一些,下面是10分钟的调用统计(Excel数据透视表)。
使用dotnet-counters+deepseek 诊断问题
可以下载一个离线dotnet-counters放到服务器的C:\Windows\System32下,然后在dos窗口中执行如下命令,注意process-id换一下
dotnet-counters collect --process-id 12345 --format csv --output counter.csv由于我的问题每分钟出现一两次,我抓了约1分钟数据后,直接丢给deepseek(网页)帮我分析
优化一:减少内存压力
进程收发数据时往往要new 一些集合对象,通讯结束后这些对象就不用了,使用Microsoft.Extensions.ObjectPool 在需要集合对象时Get,使用完Return可以降低这部分内存的频繁分配,结合应用场景介绍里的实时调用有多频繁,你就知道内存分配下降多明显了。
再就是,服务内部实现时,尽量避免把集合放在方法的返回值,而是作为参数,这样外部代码才能使用ObjectPool来降低集合内存分配。更进一步,还可以不适用集合,而是传入一个Action,每次迭代时调用这个Action。
//不好的做法
public List<T> Method<T> Read(DateTime start, DateTime end)
{
var result = new List<T>();
//...
return result;
}
//较好做法
public void Method<T> Read(List<T> result, DateTime start, DateTime end)
{
//...
}
//推荐做法
public void Method<T> Read(Action<T> action, DateTime start, DateTime end)
{
//...
}优化二:减少大对象分配(LOH)
单个对象超过 85,000 字节会进入 LOH,LOH 不自动压缩(除非显式压缩或 Full GC),大对象分配失败会触发更昂贵的 Full GC。我在采集到数据后,会通过gRPC批量发送给Tagdb,之前设置的批上限是10000条,约300Kb,超过了85Kb,达到批量上限时发送和接收都会使用LOH,把这个改成2000条了。
优化三:并发使用Parallel.ForEach 而不是Task\[\]
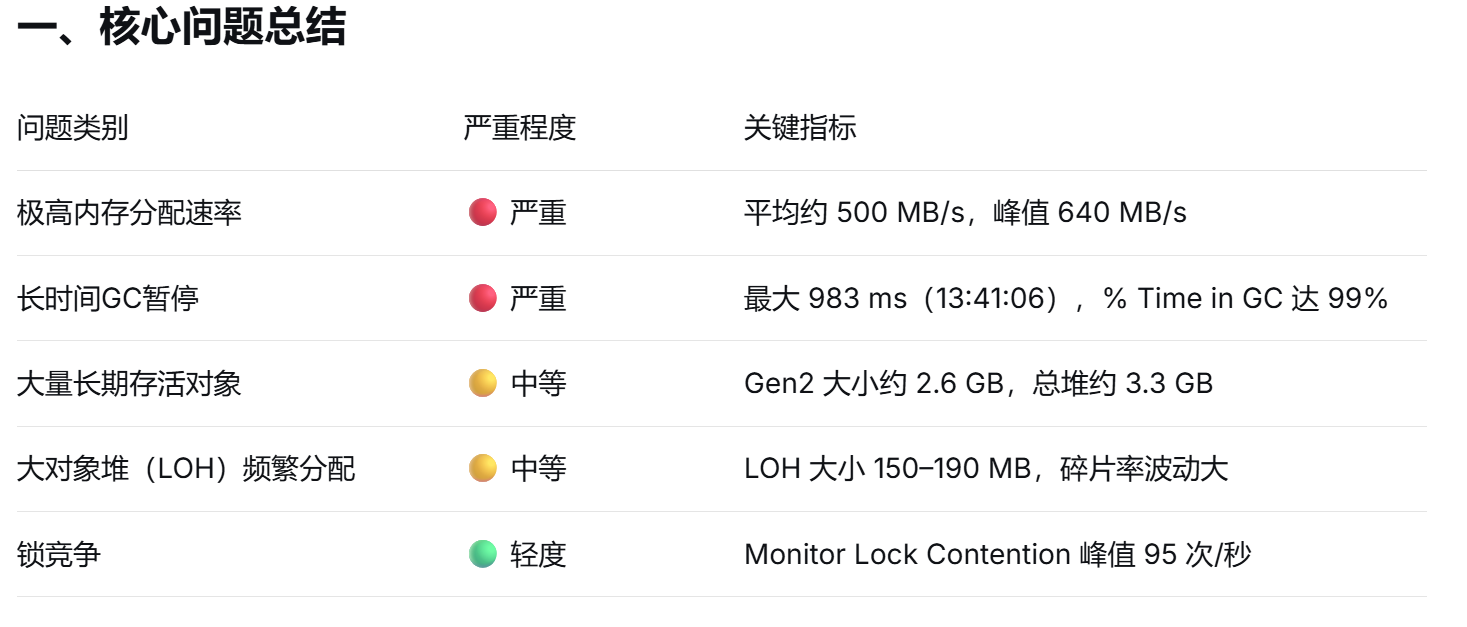
在进行了前2个优化问题还在,deepseek提示线程池排队严重,"在 11:01:49 出现 ThreadPool Queue Length = 101,表明瞬时请求超过处理能力",我根据它的建议,把代码中所有Task\[\]都改成了Parallel.ForEach,options参数传入 new ParallelOptions{MaxDegreeOfParallelism = Environment.ProcessorCount},这样可以限制并发的Task数量。
我看了日志,对于脚本计算,一批数据有可能触发100个以上,之前的逻辑会一次创建这么多Task,然后WaitAll,这会使线程池排队。
优化四:自适应内存缓存
通过日志发现,某些特定功能需要定时读取超过1小时的历史数据,而我的实时数据库只在内存缓存最近1小时的历史数据,这导致较大的IO开销和CPU压力(要解压缩),我重新设计了缓存机制,根据读取来动态分配缓存,超过有效期后清除缓存,定时清理缓存中的旧数据,这样可以适应多变的用户读取行为,使服务的性能越来越好,也降低了默认1小时缓存所有点的内存占用。
效果总结
通过1周的分析和优化,网络流量规律多了,内存占用也降低了不少。