词频统计可通过MapReduce、Hive SQL、Spark RDD和Spark SQL等多种方式实现。在Spark开发中,版本选择至关重要,需注意Spark内核与Scala版本的兼容性,如Spark 3.1.3配合Scala 2.12和JDK 8可确保本地运行和集群部署的一致性。实战准备包括启动HDFS和Spark集群服务,以及准备测试数据文件(words.txt)并上传至HDFS分布式存储中,为后续的词频统计分析奠定基础。
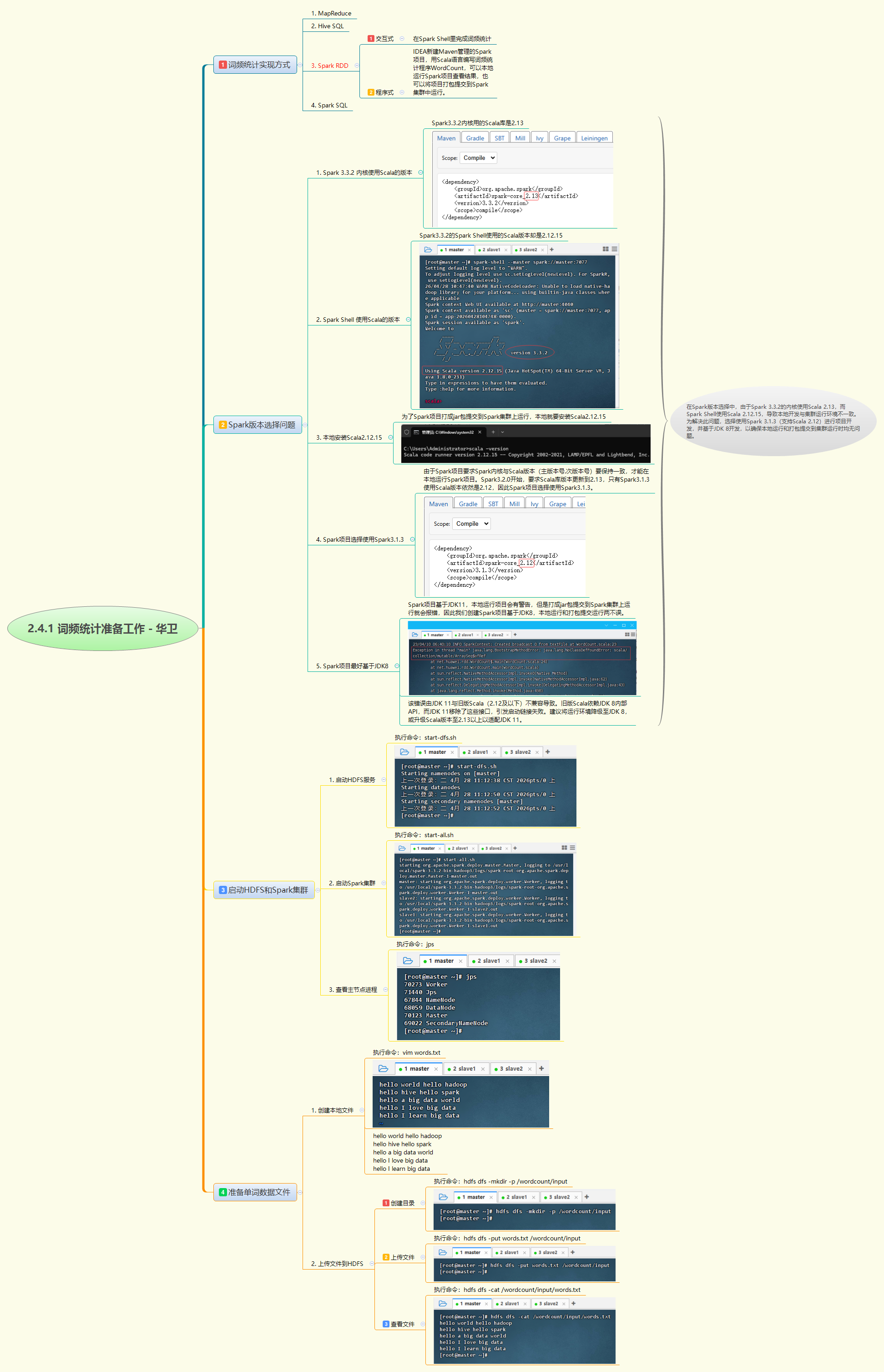
词频统计可通过MapReduce、Hive SQL、Spark RDD和Spark SQL等多种方式实现。在Spark开发中,版本选择至关重要,需注意Spark内核与Scala版本的兼容性,如Spark 3.1.3配合Scala 2.12和JDK 8可确保本地运行和集群部署的一致性。实战准备包括启动HDFS和Spark集群服务,以及准备测试数据文件(words.txt)并上传至HDFS分布式存储中,为后续的词频统计分析奠定基础。