本次实战通过代码验证了 RDD 的窄依赖与宽依赖特性。窄依赖以 map 算子为例,Spark UI 显示仅有一个 Stage,无 Shuffle 读写,且操作前后分区数(2)和元素数(5)保持不变,体现了一对一的高效流水线计算。宽依赖以 reduceByKey 为例,UI 显示作业被切分为两个 Stage,存在 Shuffle 读写数据,验证了"一对多"的重分布过程;操作后分区数虽保持为 2,但元素数由 5 减至 3,体现了聚合功能。
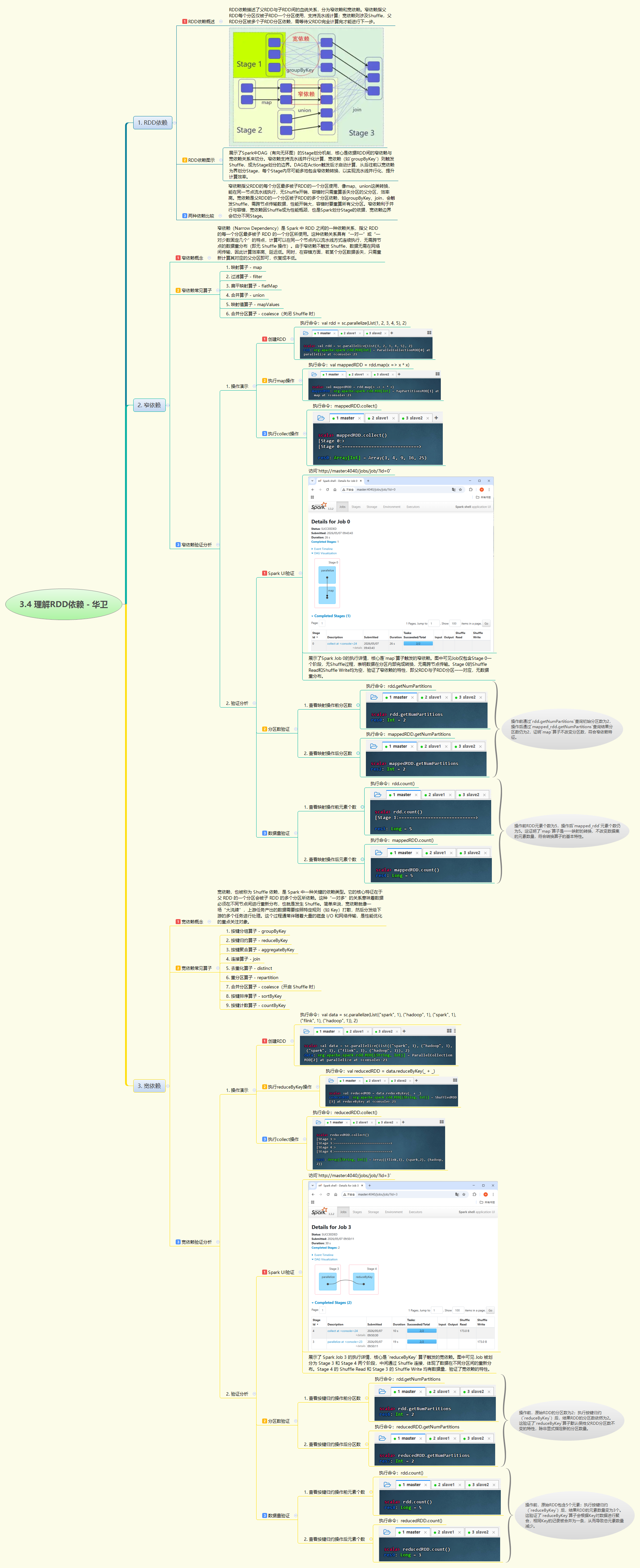
本次实战通过代码验证了 RDD 的窄依赖与宽依赖特性。窄依赖以 map 算子为例,Spark UI 显示仅有一个 Stage,无 Shuffle 读写,且操作前后分区数(2)和元素数(5)保持不变,体现了一对一的高效流水线计算。宽依赖以 reduceByKey 为例,UI 显示作业被切分为两个 Stage,存在 Shuffle 读写数据,验证了"一对多"的重分布过程;操作后分区数虽保持为 2,但元素数由 5 减至 3,体现了聚合功能。