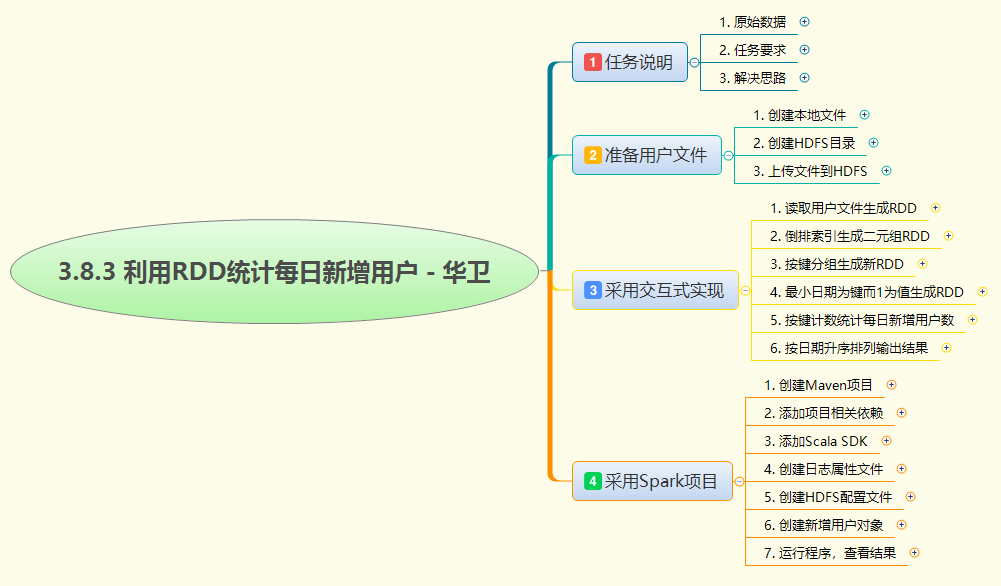
本次实战旨在使用Apache Spark的弹性分布式数据集(RDD)来解决一个典型的用户增长分析问题:根据用户访问日志,精确统计出每日新增的独立用户数量。核心思想是"倒排索引"与"去重取最小值"。
首先,读取存储在HDFS上的原始数据文件(包含访问日期和用户名),将其转换为 (用户名, 访问日期) 的键值对RDD。接着,利用 groupByKey() 按用户名聚合,得到每个用户的所有访问日期列表。关键一步是,对每个用户的日期列表应用 min() 函数,找出其最早的访问日期(即新增日期),从而形成 (新增日期, 1) 的新RDD。最后,通过 countByKey() 对相同日期进行计数,即可得出每日新增用户数。整个流程充分体现了RDD链式操作的优势,将复杂的去重和关联逻辑简化为一系列高效的分布式转换和动作算子,最终输出按日期升序排列的统计结果,清晰反映用户增长趋势。