系列说明:本系列共四篇,本篇为第二篇,聚焦 YOLOv3 的多尺度检测架构,以及如何使用 LabelMe 工具完成自定义数据集的标注、格式转换与模型训练全流程。
一、YOLOv3 核心改进概览
论文 :《YOLOv3: An Incremental Improvement》(2018)
作者:Joseph Redmon & Ali Farhadi
YOLOv3 相比 YOLOv2 没有颠覆性变化,但通过一系列精心设计的改进,在精度上大幅提升,尤其是对小目标的检测能力显著增强。
核心改进点:
| 改进点 | YOLOv2 | YOLOv3 |
|---|---|---|
| 主干网络 | Darknet-19 | Darknet-53(引入残差结构) |
| 检测尺度 | 单尺度(13×13) | 三尺度(13×13、26×26、52×52) |
| 分类器 | Softmax(互斥) | 独立 Logistic(支持多标签) |
| 先验框数量 | 5 个 | 9 个(分 3 组,每组 3 个) |
二、Darknet-53:强大的特征提取骨干
2.1 架构设计
YOLOv3 使用 Darknet-53 作为骨干网络,其命名来自网络共有 53 个卷积层。相比 Darknet-19,它引入了 ResNet 中的残差连接(Residual Block):
输入 x
│
├─ Conv(1×1) → Conv(3×3) → 特征输出
│
└─ shortcut(直连)
↓
输出 = 特征输出 + x(残差相加)残差连接的好处:
- 有效缓解梯度消失问题;
- 支持构建更深的网络;
- 特征可以在层间自由流动。
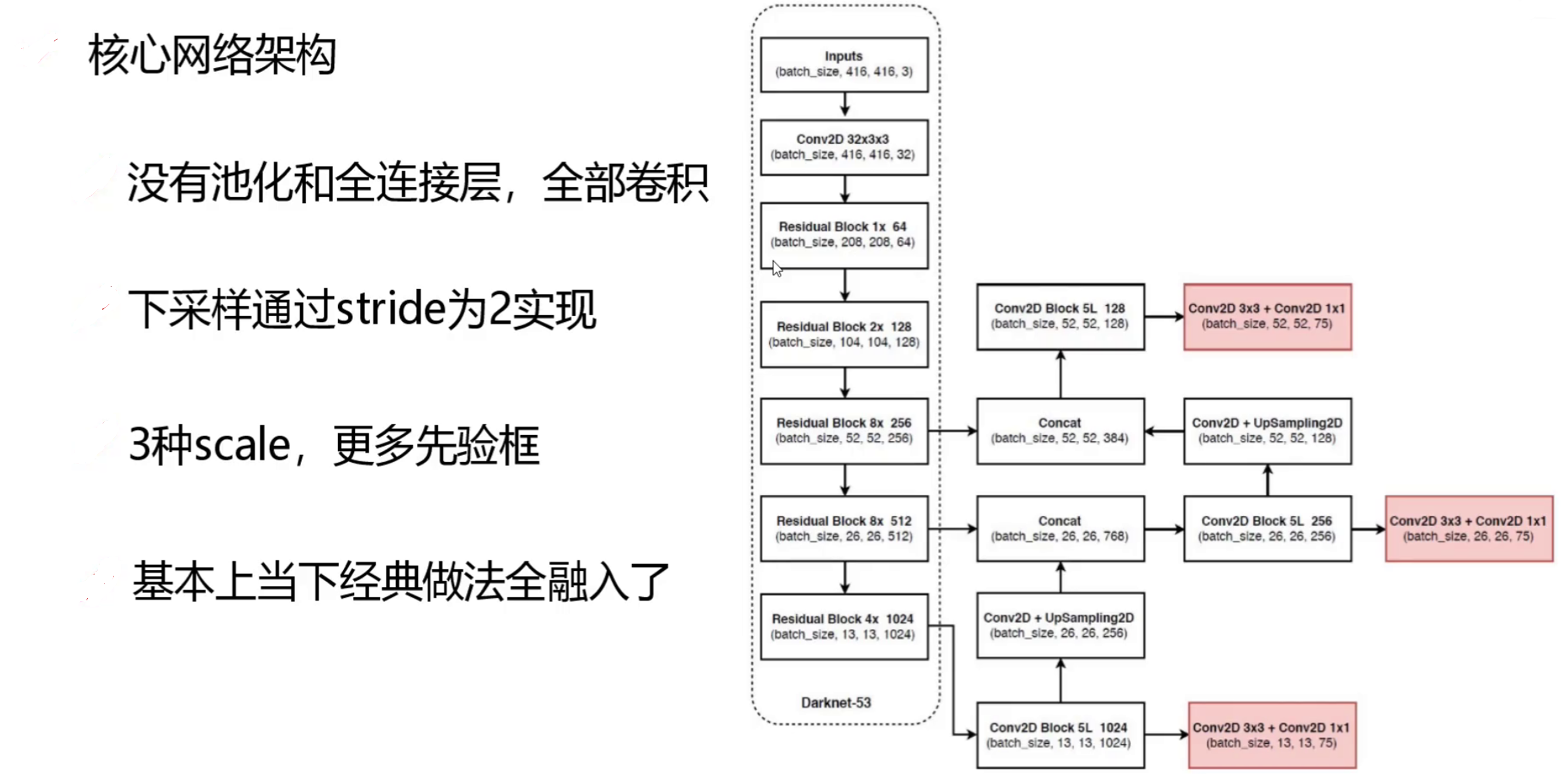
图1:Darknet-53 由卷积模块(Conv Block)和残差块(Residual Block)交替构成
2.2 特征图尺寸变化
以 416×416 输入为例,经过 Darknet-53 后:
416×416 → 208×208 → 104×104 → 52×52 → 26×26 → 13×13YOLOv3 从最后三个尺度(13×13、26×26、52×52)分别引出特征图用于检测。
三、多尺度检测:FPN 思想的应用
3.1 为什么需要多尺度检测?
- 大目标:在下采样后的小分辨率特征图(13×13)上检测,感受野大;
- 中等目标:在中等分辨率特征图(26×26)上检测;
- 小目标:在高分辨率特征图(52×52)上检测,空间分辨率高,保留了更多细节。
这正是**特征金字塔网络(FPN)**的核心思路。
3.2 多尺度特征融合
YOLOv3 采用自顶向下的特征融合方式:
Darknet-53特征提取
│
13×13特征图 ──────────────────────────── 检测头①(大目标)
│
上采样 ×2 = 26×26 + concat(26×26浅层特征)
│
26×26特征图 ──────────────────────────── 检测头②(中目标)
│
上采样 ×2 = 52×52 + concat(52×52浅层特征)
│
52×52特征图 ──────────────────────────── 检测头③(小目标)
图2:YOLOv3 三尺度检测结构,融合不同层的特征信息
3.3 先验框分配策略
YOLOv3 通过 K-Means 聚类在 COCO 数据集上得到 9 种先验框,按尺寸分为三组分配给三个检测尺度:
| 检测尺度 | 先验框尺寸 | 适合检测目标 |
|---|---|---|
| 13×13(感受野最大) | (116×90), (156×198), (373×326) | 大目标 |
| 26×26(中等感受野) | (30×61), (62×45), (59×119) | 中等目标 |
| 52×52(感受野最小) | (10×13), (16×30), (33×23) | 小目标 |
规律:大感受野对应大先验框,小感受野对应小先验框,感受野与先验框尺寸需要匹配。
四、YOLOv3 输出格式解析
每个检测头的输出张量形状为:
N×N×3×(5+C)N \times N \times 3 \\times (5 + C)N×N×3×(5+C)
其中:
- N×NN \times NN×N:特征图分辨率;
- 333:每个格子对应 3 个先验框;
- 555:x,y,w,h,objectnessx, y, w, h, \\text{objectness}x,y,w,h,objectness;
- CCC:类别数(COCO 为 80,VOC 为 20)。
以 COCO 数据集为例:
- 13×13×255(255 = 3×85 = 3×(5+80))
- 26×26×255
- 52×52×255
五、分类器改进:Logistic 替代 Softmax
5.1 Softmax 的局限性
Softmax 将所有类别的概率归一化,假设类别互斥(即一个目标只能属于一个类别)。但现实场景中存在类别重叠:
示例:一只猫,既是"猫"也是"动物",这两个标签同时成立。
Softmax 无法处理这类多标签(Multi-label)情况。
5.2 独立 Logistic 分类器
YOLOv3 为每个类别独立使用 Sigmoid(Logistic)函数:
P(classi)=σ(zi)=11+e−ziP(\text{class}_i) = \sigma(z_i) = \frac{1}{1 + e^{-z_i}}P(classi)=σ(zi)=1+e−zi1
每个类别的预测相互独立,通过设置阈值(如 0.5)判断目标是否属于该类别,天然支持多标签分类。
对比示例:
| 图像 | Softmax 输出 | Logistic 输出 |
|---|---|---|
| 猫 | 猫:0.9, 狗:0.08, 动物:0.02 | 猫:0.8, 狗:0.3, 动物:0.7 |
| 预测结果 | 只预测"猫" | 预测"猫"和"动物"(均>0.5) |
六、LabelMe 数据标注工具实战
在自定义数据集训练 YOLOv3 之前,需要对数据进行标注。本节介绍使用 LabelMe 完成完整的标注与训练流程。
6.1 常用数据标注工具对比
| 工具 | 特点 | 支持标注类型 |
|---|---|---|
| LabelImg | 轻量快速,专注目标检测 | 2D 矩形框 |
| LabelMe | 功能全面,MIT 开源 | 多边形、矩形、圆、线、点 |
| CVAT | 企业级,支持视频 | 多边形、骨架、分割等 |
| RectLabel | macOS 专用,支持 YOLO 导出 | 矩形框 |
| VOTT | 微软出品,支持半自动标注 | 矩形框 |
6.2 安装 LabelMe
bash
# 方法一:pip 安装(推荐)
pip install labelme
pip install pyqt5
pip install pillow
# 方法二:从源码安装
git clone https://github.com/wkentaro/labelme.git
cd labelme
pip install -e .安装完成后,在命令行输入以下命令启动:
bash
labelme
图3:LabelMe 标注工具界面,支持多种标注类型
6.3 使用 LabelMe 进行标注
基本操作流程:
- 打开文件夹 :
File → Open Dir,选择待标注图像所在文件夹; - 新建多边形/矩形 :点击
Edit → Create Polygons或Create Rectangle; - 绘制标注框:在图像上拖拽绘制框,松开鼠标后输入类别标签;
- 保存标注 :
Ctrl+S保存,默认生成与图像同名的.json文件。
LabelMe JSON 格式示例:
json
{
"version": "5.0.1",
"flags": {},
"shapes": [
{
"label": "cat",
"points": [[100, 150], [300, 150], [300, 400], [100, 400]],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
}
],
"imagePath": "cat.jpg",
"imageHeight": 600,
"imageWidth": 800
}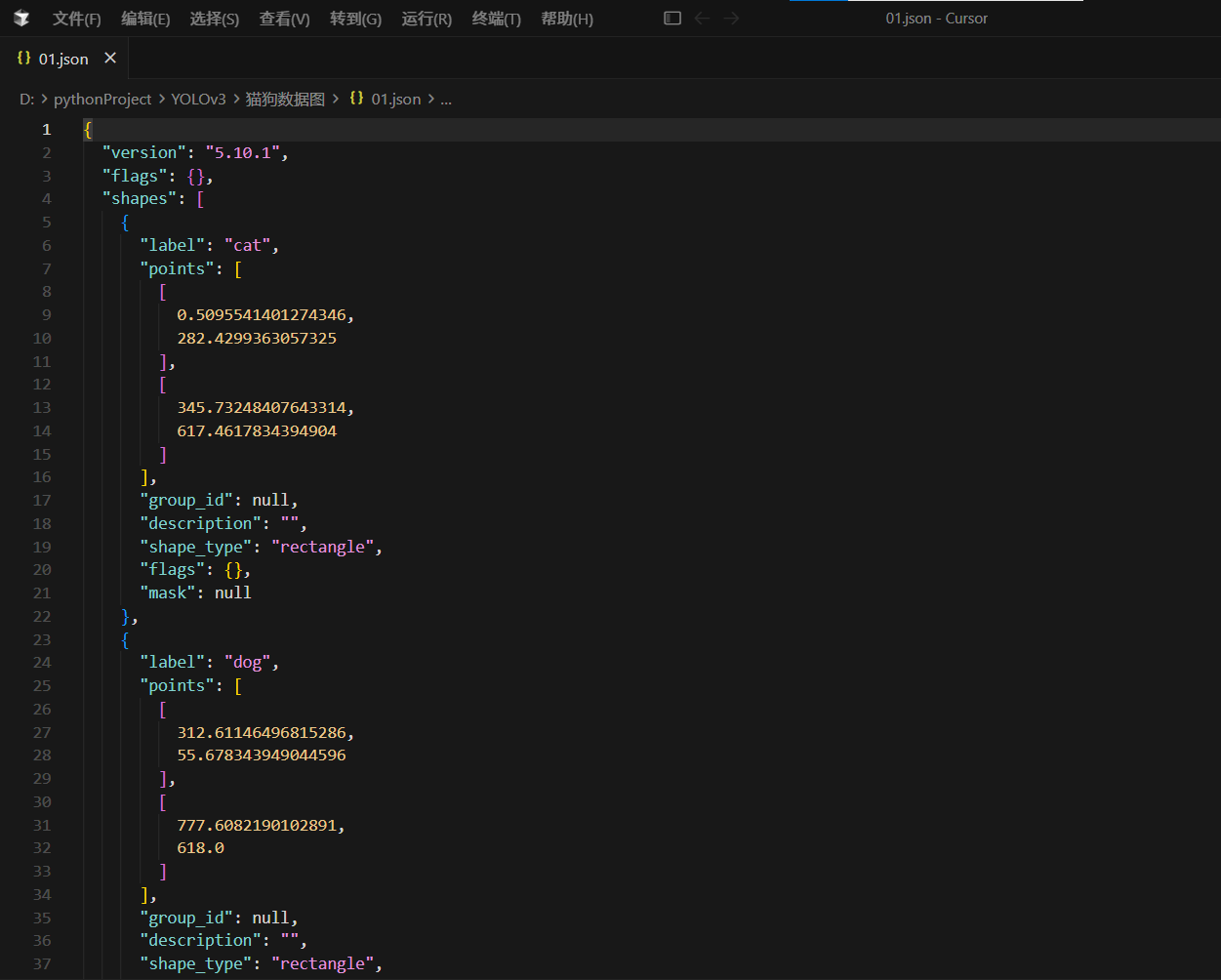
图4:使用 LabelMe 对图像中的目标进行矩形框标注
6.4 JSON 格式转换为 YOLO 格式
LabelMe 默认输出 JSON 格式,需转换为 YOLO 训练所需的 .txt 格式。
YOLO 格式规范(每行一个目标):
<class_id> <x_center> <y_center> <width> <height>所有坐标值均为相对图像尺寸的归一化值(0~1)。
转换脚本 (位于 utils/ 文件夹):
python
import json
import os
from pathlib import Path
def labelme_json_to_yolo(json_path, label_map, output_dir):
"""
将 LabelMe JSON 标注转换为 YOLO txt 格式
Args:
json_path: LabelMe 生成的 JSON 文件路径
label_map: 类别名到 ID 的映射字典,如 {'cat': 0, 'dog': 1}
output_dir: YOLO txt 文件输出目录
"""
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
img_w = data['imageWidth']
img_h = data['imageHeight']
yolo_lines = []
for shape in data['shapes']:
label = shape['label']
if label not in label_map:
continue
class_id = label_map[label]
points = shape['points']
# 获取矩形框的最小外接矩形
xs = [p[0] for p in points]
ys = [p[1] for p in points]
x_min, x_max = min(xs), max(xs)
y_min, y_max = min(ys), max(ys)
# 转换为 YOLO 格式(归一化)
x_center = (x_min + x_max) / 2 / img_w
y_center = (y_min + y_max) / 2 / img_h
width = (x_max - x_min) / img_w
height = (y_max - y_min) / img_h
yolo_lines.append(f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
# 写入输出文件
output_path = Path(output_dir) / (Path(json_path).stem + '.txt')
with open(output_path, 'w') as f:
f.write('\n'.join(yolo_lines))
print(f"Converted: {json_path} → {output_path}")
# 使用示例
label_map = {'cat': 0, 'dog': 1, 'person': 2}
json_folder = 'data/raw_labels/' # LabelMe 生成的 JSON 文件夹
output_dir = 'data/custom/labels/' # YOLO 格式输出目录
os.makedirs(output_dir, exist_ok=True)
for json_file in Path(json_folder).glob('*.json'):
labelme_json_to_yolo(str(json_file), label_map, output_dir)
图5:JSON 标签格式转换为 YOLO 所需的 txt 格式
6.5 配置模型文件
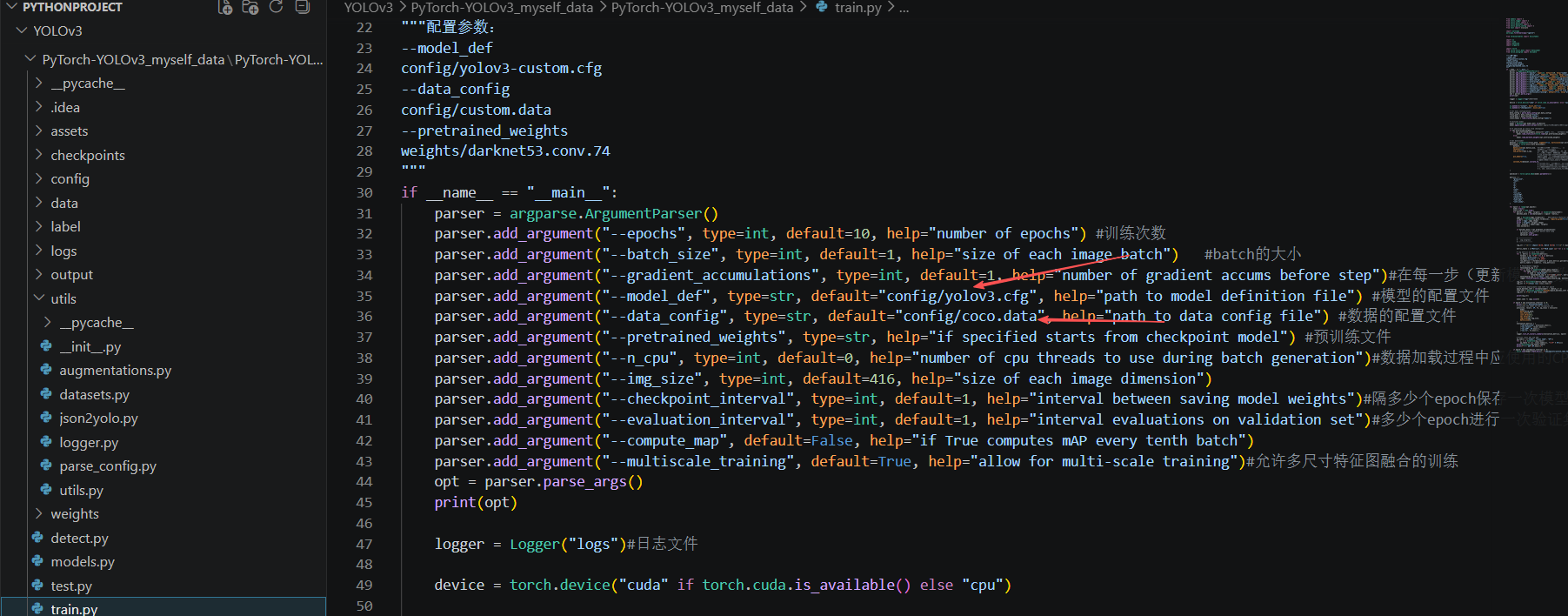
可以根据训练模型中对应的config和data去查看改成类似的形式。
第一步:生成自定义模型配置文件
使用官方提供的脚本生成适配自定义类别数的配置文件(需安装 Git):
bash
# 在项目目录下右键 → Git Bash Here
# 2 代表自定义数据集的类别数(根据实际情况修改)
bash create_custom_model.sh 2⚠️ 注意 :每次运行前先删除旧的
yolov3-custom.cfg文件,否则内容会追加到末尾导致配置错误。
第二步:修改类别名称文件
编辑 data/custom/classes.names,每行一个类别名称,顺序需与标注时一致:
text
cat
dog
person第三步:配置数据路径文件
编辑 data/custom/custom.data:
ini
classes = 2
train = data/custom/train.txt
valid = data/custom/val.txt
names = data/custom/classes.names
backup = checkpoints/train.txt 和 val.txt 中写入对应图像的绝对路径,每行一条:
/path/to/dataset/images/img001.jpg
/path/to/dataset/images/img002.jpg
...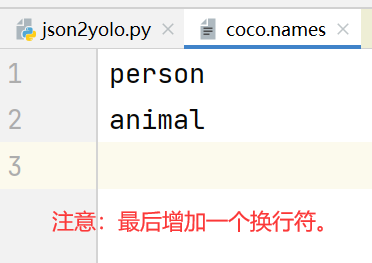
图6:数据配置文件结构与路径设置
6.6 训练与测试
训练命令:
python
# train.py 关键参数
python train.py \
--model_def config/yolov3-custom.cfg \ # 模型配置文件
--data_config config/custom.data \ # 数据配置文件
--pretrained_weights weights/darknet53.conv.74 # 预训练权重(迁移学习)测试/推理命令:
python
python detect.py \
--image_folder data/samples/ \ # 测试图像文件夹
--model_def config/yolov3-custom.cfg \ # 模型配置
--checkpoint_model checkpoints/yolov3_ckpt_100.pth \ # 训练好的权重
--class_path data/custom/classes.names # 类别名称文件6.7 完整工作流程图
原始图像
↓
LabelMe 标注(生成 JSON)
↓
json_to_yolo 格式转换(生成 txt)
↓
配置 classes.names / custom.data / train.txt / val.txt
↓
bash create_custom_model.sh <类别数>(生成 yolov3-custom.cfg)
↓
python train.py --model_def ... --data_config ... --pretrained_weights ...
↓
python detect.py --image_folder ... --checkpoint_model ...
↓
检测结果输出七、YOLOv3 性能分析
7.1 与其他算法的对比(COCO 数据集)
| 算法 | mAP@50 | FPS | 特点 |
|---|---|---|---|
| YOLOv2 | 48.1 | 40 | 速度快,精度一般 |
| YOLOv3 | 57.9 | 20 | 精度大幅提升,速度适中 |
| SSD512 | 48.9 | 19 | 精度与 YOLOv3 相近 |
| RetinaNet | 61.1 | 5 | 精度高,速度慢 |
| Faster R-CNN | 55.7 | 7 | 精度高,速度慢 |
7.2 YOLOv3 的局限性
- 对密集小目标检测仍有不足;
- 训练速度较慢(相比 v2 网络更深);
- 没有充分利用注意力机制等现代技巧。
这些问题将在 YOLOv4 中进一步解决。
八、小结
本文详细介绍了:
- YOLOv3 的三大核心改进:Darknet-53 骨干、三尺度检测头、独立 Logistic 分类器;
- 9 种先验框的分配策略:大感受野对应大框,小感受野对应小框;
- 完整的自定义数据集训练流程:从 LabelMe 标注到 YOLO 格式转换再到模型训练。
掌握这套流程后,可以快速将 YOLOv3 应用到任何自定义目标检测任务中。下一篇将介绍 YOLOv4,它在 YOLOv3 基础上引入了更多先进技术,进一步突破了速度与精度的平衡极限。
参考资源
- Redmon, J., & Farhadi, A. "Yolov3: An incremental improvement." arXiv 2018.
- LabelMe 官方仓库:https://github.com/wkentaro/labelme
- COCO 数据集介绍:https://blog.csdn.net/qq_44554428/article/details/122597358
分类器;
- 9 种先验框的分配策略:大感受野对应大框,小感受野对应小框;
- 完整的自定义数据集训练流程:从 LabelMe 标注到 YOLO 格式转换再到模型训练。