abstrace
推测解码被广泛用于降低大语言模型(LLM)推理延迟,其核心是利用能够处理多样化用户任务的小型草稿模型。然而,新兴的 AI 应用(如基于 LLM 的智能体)呈现出独特的工作负载特征:与多样化的独立请求不同,智能体框架通常会提交高度重复的推理请求,例如执行相似子任务的多智能体流水线,或反复迭代优化输出的自我精炼循环。这些工作负载产生了长而高度可预测的 token 序列,而现有的推测解码方法无法有效利用这一特性。
为填补这一空白,我们提出 SuffixDecoding------一种新颖的方法,利用高效的后缀树对来自提示词和历史输出的长 token 序列进行缓存。通过在接受率高时自适应地推测更多 token、接受率低时推测更少 token,SuffixDecoding 能够在机会充分时充分利用长推测的优势,并在机会有限时节省计算资源。在智能体基准测试(包括 SWE-Bench 和 Text-to-SQL)上的评估表明,SuffixDecoding 实现了高达 5.3 倍的加速,超越了当前最先进的方法------比 EAGLE-2/3 等基于模型的方法快 2.8 倍,比 Token Recycling 等无模型方法快 1.9 倍。SuffixDecoding 已在 https://github.com/snowflakedb/ArcticInference 开源。
1 introduction
大语言模型(LLM)是智能体 AI 应用的基础,涵盖自动化编程助手、多智能体工作流以及检索系统等场景。与基础聊天机器人不同,这类工作负载会发出高度重复且可预测的推理请求。例如,多智能体系统会反复执行相似的任务,而推理循环则会反复生成相似的 token 序列。尽管存在这种可预测的重复性,现有方法仍未能充分利用这些规律性模式,导致推理延迟依然是一大瓶颈。
推测解码是目前缓解推理延迟最流行的策略之一。LLM 每次前向传播只能生成一个 token,但却可以同时验证多个 token。利用这一特性,推测解码方法使用小型"草稿"模型或额外的解码头来预测多个候选 token,再由主模型并行验证。
为了高效处理智能体应用中普遍存在的长序列重复,推测解码方法必须满足两个关键要求。第一,需要以极低的开销快速生成草稿 token,从而最大限度地利用长推测序列带来的收益。第二,必须具备自适应能力------仅在接受率高时生成更多草稿 token,在接受率低时生成更少,以防止验证过程本身成为新的瓶颈。
然而,现有的推测解码方法在同时满足这两项要求方面存在明显不足。基于模型的方法【Model-based methods】在推测长序列时会消耗大量 GPU 时间,还可能引发内存竞争和内核级切换,需要精心管理。相反,现有的无模型方法【model-free approaches】(如提示词查找解码。prompt-lookup decoding, PLD)虽然开销低、生成速度快,但通常缺乏自适应能力。这些方法无论接受率高低都推测固定数量的 token,导致大量计算资源被浪费在验证冗长且不太可能被接受的草稿序列上。
为解决上述局限,我们提出 SuffixDecoding------一种专为重复性智能体工作负载设计的无模型推测解码方法。SuffixDecoding 利用高效的后缀树【suffix trees】对来自提示词和历史输出的长 token 序列进行缓存。树中每个节点代表一个 token,路径编码历史观测到的子序列,从而支持快速模式匹配【rapid pattern matching】,基于历史出现规律识别可能的续写内容。草稿 token 的生成速度极快(约每 token 20 微秒),且完全不产生 GPU 开销。
在每个推理步骤中,SuffixDecoding 根据模式匹配的长度自适应地调整草稿 token 的数量,并利用后缀树中记录的频率统计信息对候选推测序列进行评分与筛选。更长的模式匹配意味着可以自信地推测更长的 token 序列,从而最大化在智能体工作负载上的效果;而较短的模式匹配则触发保守推测,以避免计算浪费。
此外,SuffixDecoding 可以与现有的基于模型的推测解码方法无缝集成。这种灵活性催生了一种混合方案:对重复性强、可预测的智能体工作负载采用基于后缀树的推测,对开放式对话任务则发挥基于模型的推测方法的优势,从而兼顾两者之长。
我们在两个实际的智能体工作负载上对 SuffixDecoding 进行评估:SWE-Bench(一个基于 LLM 的软件工程基准测试)以及 AgenticSQL(一个用于 SQL 生成的专有多智能体流水线应用)。我们借助 Spec-Bench 与当前最先进的基于模型和无模型推测解码方法进行对比,结果表明 SuffixDecoding 的解码速度比 EAGLE-2/3 最高快 2.8 倍,比 Token Recycling 最高快 1.9 倍。
针对 SWE-Bench,我们还测量了全面的端到端任务完成时间------涵盖提示词预填充、token 生成以及外部动作的执行------结果表明推测解码带来的端到端加速最高可达 4.5 倍。
上述结果表明,SuffixDecoding 能够大幅降低真实智能体应用的推理延迟,有效解决了实际推理场景中的关键性能瓶颈。
2 Background and Related Work
LLM 推理分为两个阶段:给定提示词 xprompt = (x1, x2, . . . , xm),LLM 首先并行处理提示词(预填充阶段),然后逐步顺序生成新 token(解码阶段),每个 token 均以先前生成的 token 为条件:
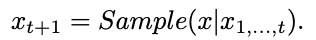
在贪心采样中,每次迭代选择概率最高的 token,直至满足停止条件。由于每个 token 都依赖于前序输出,生成过程天然是串行的,每生成一个 token 就需要一次独立的前向传播,这限制了吞吐量,也造成了并行硬件加速器的利用率不足。
推测解码。 推测解码通过使用轻量级模型快速生成多个候选 token 来加速推理,这些候选 token 随后由主 LLM 并行验证。该方法的基本流程包含两个核心步骤:
-
推测:一个较小的"草稿"模型基于已有的 token 前缀
,快速生成推测 token 序列
-
验证:主 LLM 并行验证草稿 token,接受直至第一个不一致处之前的所有 token,并丢弃其余部分。
这一机制将计算重心从串行生成转移到了并行验证。然而,草稿模型仍然需要消耗计算资源,并增加了系统编排的复杂性。基于模型的方法包括 Medusa、SpecInfer(提出了基于树的推测机制)、多 token 预测以及块并行解码等。
近期的无模型方法包括提示词查找解码(PLD)、Token Recycling、LLMA 以及 ANPD 等。这些方法依赖少量参考文本,且缺乏自适应推测能力。SuffixDecoding 专为具有长重复序列的智能体应用场景而设计,在这一方面具有独特优势。
智能体 AI 算法Agentic AI Algorithms.。 智能体应用将任务组织为多次 LLM 调用,从而产生大量重复的长 token 序列。自洽采样Self-consistency samples从同一提示词出发采样多条推理路径,这些路径共享相似的思维链步骤。自我精炼通过迭代修正错误,每次仅修改少量内容,同时保留周围的上下文。多智能体工作流使用功能专一的专业化智能体,因而产生高度重复的输出。这些模式为利用长重复序列提供了可乘之机。
LLM 智能体加速方法** Methods for Accelerating LLM Agents.**。 近期研究致力于降低智能体应用的推理延迟。ALTO 通过流水线化和任务调度来优化多智能体工作流。Dynasor 通过提前终止低概率推理路径来减少无效计算。SuffixDecoding 采用与上述方法正交的推测解码思路,可与它们结合使用。
3 SuffixDecoding
SuffixDecoding 的目标是实现对长序列的快速、自适应推测解码,尤其适用于智能体应用场景------在这类场景中,重复的推理调用往往包含高度可预测且相互重叠的 token 序列。在这种环境下,大段的输出内容可以从历史请求和当前进行中的请求中准确预测。
为充分利用这些机会,SuffixDecoding 必须应对两项关键挑战。第一,必须支持快速生成推测序列------包括长续写序列------而不依赖草稿模型或代价高昂的逐 token 预测。第二,必须能够自适应当前的预测上下文:仅在长续写序列很可能被接受时才大胆推测,在不确定时则推测较短的序列,以避免浪费验证所需的计算资源。
为支持快速推测,SuffixDecoding 在当前请求和历史请求的 token 上构建后缀树【a suffix tree】,并利用后缀树生成推测 token。树的根节点代表树中存储的任意 token 序列的某个后缀的起始位置,每个节点的子节点代表从该节点出发的一个可能的后续 token,从根节点到任意节点的路径则代表一个唯一的子序列。
对于每个请求,我们从以下两个来源推测 token 序列:(1)该请求自身的提示词和输出;(2)历史请求的输出。这样做能够捕获许多智能体算法中输出 token 重复的根本来源,包括自洽采样、自我精炼以及多智能体流水线等。
SuffixDecoding 利用后缀树执行快速模式匹配,以找到 token 序列的可能续写。假设当前进行中的推理请求的提示词和输出 token 序列为 。取其长度为 p 的后缀
,将其称为模式序列。我们从根节点出发遍历后缀树,每一步选取对应 token
的子节点。若该子节点不存在,则说明未找到匹配模式,SuffixDecoding 回退至标准的非推测解码模式。
否则,经过 p 步之后,我们到达一个节点,其所有下行路径即为该模式序列的可能续写。尽管上述过程能够快速找到一组(可能数量庞大的)候选序列,但在推测解码中验证所有候选序列的代价可能过于高昂。
为此,SuffixDecoding 通过贪心扩展和评分流程构建一棵规模更小、可信度更高的推测树,并将这棵精简的推测树用于基于树的推测验证。SuffixDecoding 的整体流程如图 1 所示,本节后续部分将对其进行详细阐述。
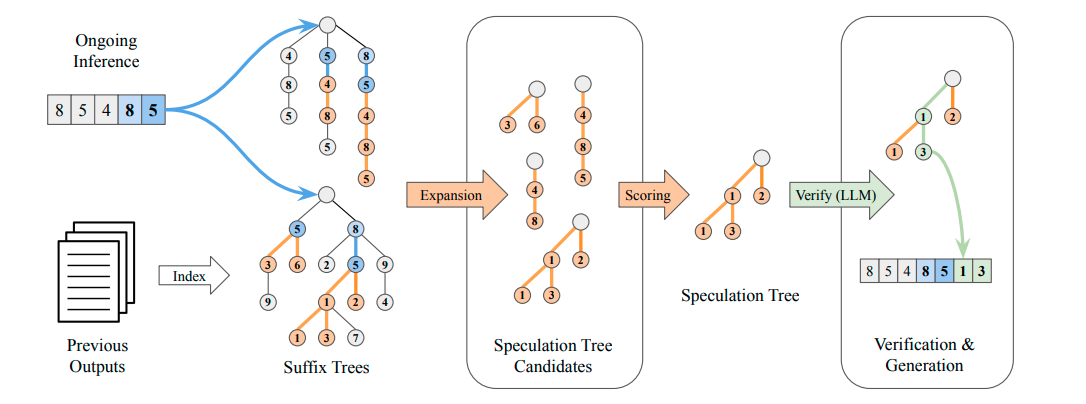
图 1:SuffixDecoding 算法概览。两棵后缀树分别追踪当前进行中的推理(左上)和历史输出(左下)。SuffixDecoding 利用这两棵后缀树,基于最近生成的 token 查找匹配的历史模式。随后,通过依据频率统计信息对候选续写进行评分,选出最可能的续写序列,从而构建推测树(中)。最终,最优候选序列由 LLM 在单次前向传播中完成验证(右),被接受的 token(以绿色标注)将被添加至输出,并用于下一轮推测。
Suffix Tree Construction. **后缀树的构建。**在在线推理服务中构建并持续更新后缀树,需要经历两个阶段。第一,历史推理输出可以通过一次性离线处理步骤添加到树中(例如从历史日志中读取),也可以在推理服务运行期间,于每个推理请求完成后在线添加。第二,当前进行中的提示词和输出 token 则在收到新请求及每生成一个新 token 时实时在线添加。
在实践中,我们发现维护两棵独立的后缀树更为便利:一棵全局树用于存储历史生成的输出,另一棵独立的每请求树用于存储当前进行中的推理请求内容。这一设计规避了多个并发请求同步更新同一棵后缀树所带来的复杂性和额外开销。全局树可在离线状态下以 O(n) 时间复杂度完成构建,而每请求树则可在线高效地构建和更新。
尽管后缀树的空间复杂度为 O(n),内存利用率较高,但当历史输出数量庞大时,全局树仍可能占用相当大的空间。然而,后缀树仅需占用 CPU 内存,而在 LLM 服务场景中,CPU 内存通常十分充裕且利用率偏低。例如,常用于 LLM 服务的 AWS p5.48xlarge 实例配备了 2TB 主内存,足以轻松支撑一棵覆盖数百万条历史输出、数十亿 token 的后缀树。在典型的服务器配置下,SuffixDecoding 大约可缓存一个月的生成 token 量,之后才需要触发缓存淘汰机制。
Speculation Tree Expansion. 推测树的扩展。 给定当前推理 的模式序列
,SuffixDecoding 能够在全局后缀树或每请求后缀树中快速定位节点
,该节点的所有下行路径即为该模式序列的可能续写。为了筛选出一棵规模更小、可信度更高、更适合推测验证的子树,我们从单个节点
出发,每次扩展一个叶节点,以贪心方式逐步生长出一棵子树。
具体而言,我们定义如下:
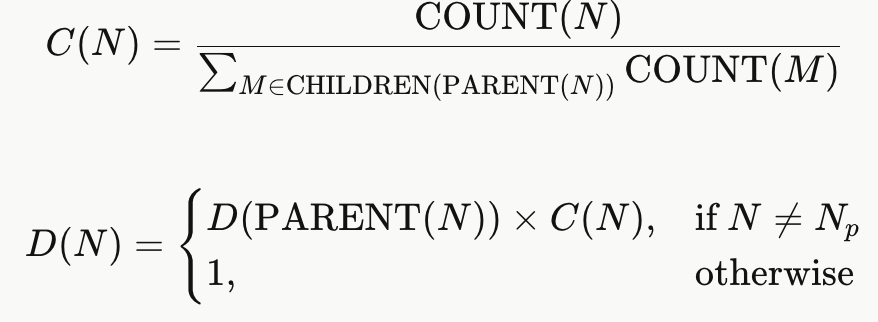
其中,COUNT(N) 是节点 N 在参考语料库中出现的次数,可在构建后缀树时计算得出。从推测子树中的单个节点 出发,我们遍历所有叶节点的全部子节点,并将 D(N) 值最高的节点 N 加入子树。重复上述过程,直到子树的规模达到预设的上限 MAX_SPEC 为止。
直觉上,C(N) 估计了在子序列 TOKEN(), . . . , TOKEN(PARENT(N)) 之后,下一个被观测到的 token 为 TOKEN(N) 的概率;而 D(N) 则在假设输出 token 遵循历史规律的前提下,估计了 TOKEN(N) 最终被推测树验证所接受的概率。因此,SuffixDecoding 通过贪心地添加最可能在验证阶段被接受的叶节点来构建推测树。
Algorithm 1 Speculation Tree Generation 算法 1:推测树生成

Adaptive Speculation Lengths. **自适应推测长度。**上述流程使 SuffixDecoding 能够基于经验概率估计缓存并快速推测长 token 序列,但与此同时,还需要一种机制来自适应地控制推测的 token 数量。SuffixDecoding 通过动态调整 MAX_SPEC 来实现这一目标。MAX_SPEC 值较小时,推测所选的 token 数量更少但可信度更高;值较大时,所选 token 数量更多但可信度相对较低。若 MAX_SPEC 过小,推测带来的加速效果将受到限制;若过大,则可能浪费大量计算资源用于验证不太可能被接受的 token。
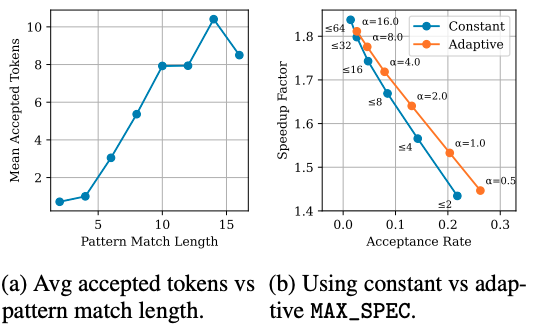
Figure 2: (a) the mean number of accepted tokens increases with the length of the pattern match, which motivates MAX_SPEC = αp. (b) shows that this choice achieves a better trade-off between acceptance rate and speculative speedup.
为指导 MAX_SPEC 的自适应设置,我们观察到:在实践中,被接受的 token 数量通常随模式序列长度 p 的增加而增多(图 2a)。为此,我们将 MAX_SPEC 自适应地定义为:
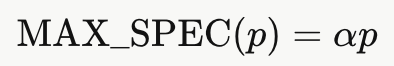
其中 α 为用户自定义的最大推测因子。图 2b 表明,根据模式长度自适应地设置 MAX_SPEC,能够在接受率与推测加速比之间取得更优的权衡。在实践中,我们发现对于智能体应用,α ∈ 1, 4 的取值范围表现良好。
Speculation Tree Scoring. **推测树评分。**至此,我们已经讨论了如何在给定后缀树和模式长度 p 的情况下获得一棵推测树。然而,SuffixDecoding 维护着两棵后缀树------全局后缀树【the global suffix tree】和每请求后缀树【the per-request suffix tree】,每棵树都对应多种 p 的取值选择。为了最终得到一棵推测树,我们针对全局后缀树和每请求后缀树,在一定范围的 p 值下分别构建推测树。随后,依据如下评分函数从中选出唯一一棵推测树:
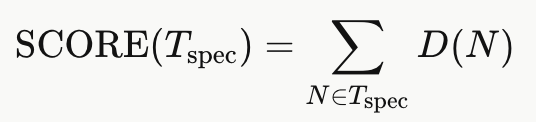
直觉上,若 D(N) 估计的是推测树 Tspec 中节点 N 被接受的概率,则 SCORE(Tspec) 估计的便是期望被接受的 token 总数。SuffixDecoding 随后选取 SCORE 最高的 Tspec 作为最终待验证的推测树。从推测树扩展到评分的端到端候选生成流程详见算法 1。
Hybrid Suffix Speculative Decoding. **混合后缀推测解码。**最后,我们发现 SCORE(Tspec) 可用于动态决策:究竟采用 SuffixDecoding,还是回退至基于模型的推测方法。这对于工作负载混合了智能体任务和更多样化应用的实际场景尤为有用。
具体而言,在每次解码迭代中,我们始终优先使用 SuffixDecoding 进行推测。若 SCORE(Tspec) > τ(其中 τ 为可配置的阈值),则采用 SuffixDecoding 生成的草稿 token。否则,回退至备用推测方法,例如 EAGLE-3。
作为实践指导,我们发现对于混合工作负载,将 τ 设置为接近回退推测器的平均接受 token 数效果最佳;而对于高度重复的智能体任务,单独使用 SuffixDecoding(τ = 0)则是最优选择。附录 B.1 提供了 τ 在不同工作负载类型下的详细敏感性分析。对于批量服务场景,SuffixDecoding 可与现有的批次级推测控制方法集成使用(详见附录 C)。