目录
[1. 进程独立性](#1. 进程独立性)
[2. 进程间通信目的](#2. 进程间通信目的)
[二、IPC 体系](#二、IPC 体系)
[1. IPC 发展历程](#1. IPC 发展历程)
[2. IPC 主要分类](#2. IPC 主要分类)
[1. 什么是管道](#1. 什么是管道)
[1. pipe 系统调用](#1. pipe 系统调用)
[2. fork 共享管道原理](#2. fork 共享管道原理)
[3. 文件描述符视角](#3. 文件描述符视角)
[4. 内核视角](#4. 内核视角)
[1. 样例代码](#1. 样例代码)
[1. 读规则](#1. 读规则)
[2. 写规则](#2. 写规则)
一、为什么需要IPC
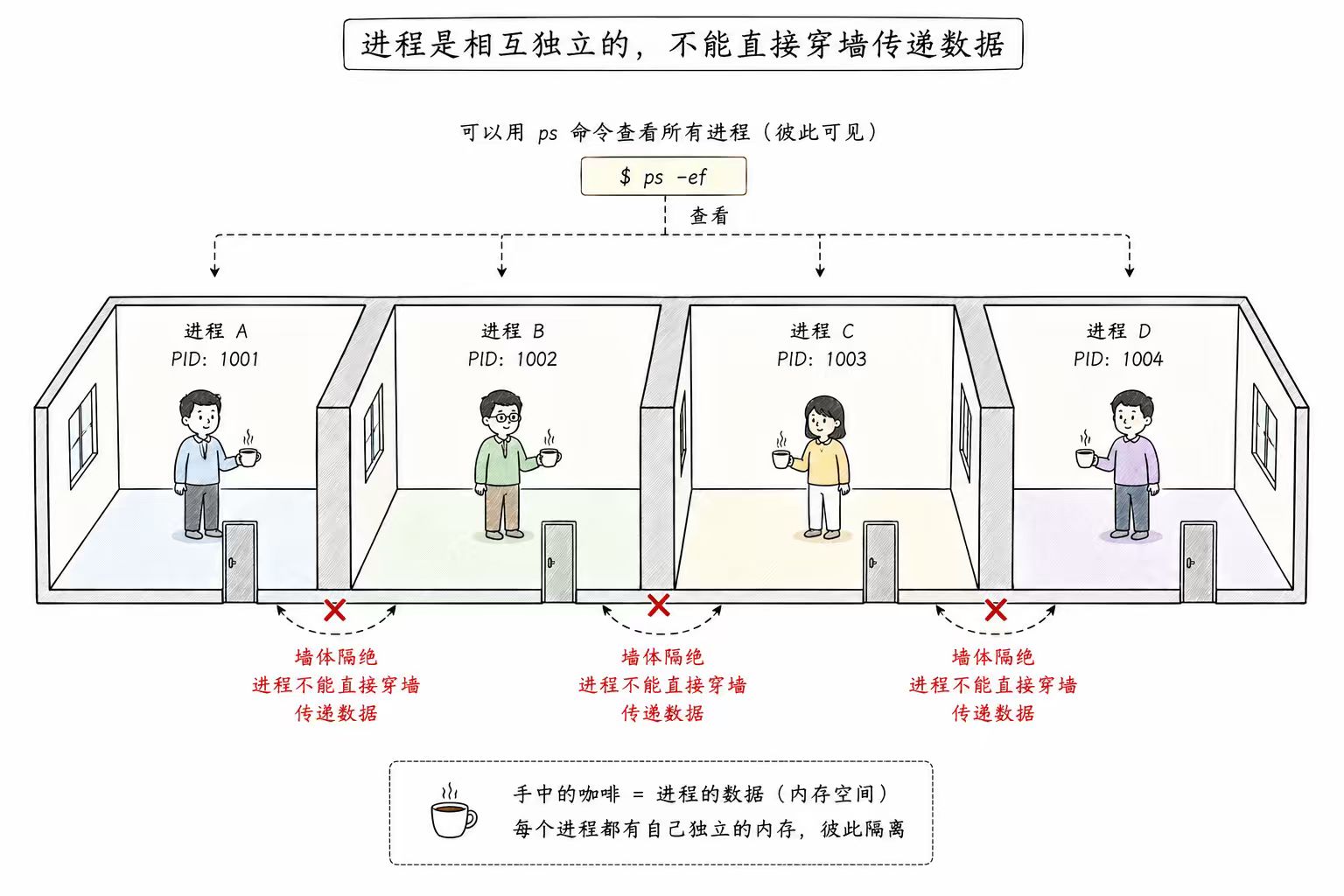
在深入探讨复杂的系统调用之前,我们必须首先明确一个基本概念:现代操作系统中,进程默认都具有隔离性 ,这种隔离性是操作系统强制实现的安全特性
1. 进程独立性
在 Linux 中,每个进程都运行在自己的虚拟地址空间中。由于虚拟内存管理机制的存在,进程 A 无法直接访问进程 B 的内存地址
-
保护机制: 这种独立性是操作系统的核心特性。当进程A崩溃或发生指针错误时,不会意外破坏进程B的数据,从而确保了系统的安全性和稳定性
-
副作用: 进程间的物理隔离导致了逻辑上的数据孤立。假设在进程 A 中定义了一个全局变量 int count = 10,这个变量对进程 B 而言是完全不可见的
我们可以把每个进程想象成一间一间独立办公室,大家能互相看见(通过 ps 命令),但如果你想把手里的咖啡(数据)递给隔壁同事,直接穿墙是不可能的
2. 进程间通信目的
既然隔离是为了安全,那为什么我们又要费尽心思打破这种隔离呢?关键原因在于:
-
数据传输: 最基本的需求。一个进程需要将其处理后的结果发送给另一个进程进行后续处理(比如 ls | grep)
-
资源共享: 多个进程需要访问同一块数据
-
通知事件: 一个进程需要告诉另一个进程发生了什么(例如子进程退出时通知父进程)
-
进程控制: 有些进程(如调试器)需要完全控制另一个进程的执行状态,或者需要实时监控其行为
进程彼此相互隔离、独立运行,而 IPC(Inter-Process Communication,进程间通信) 机制,能够打破进程的隔离限制,提供数据传输与交互渠道,实现不同进程间的数据共享与业务协作
二、IPC 体系
在 Linux 系统中,进程间通信(IPC)并非单一的技术实现,而是随着 Unix / Linux 操作系统的演进,由不同的标准共同构建的体系
1. IPC 发展历程
Linux 继承了 Unix 的通信机制,其 IPC 的发展主要经历了以下三个阶段:
-
早期 Unix 通信: 最早期的通信方式包括管道 、命名管道以及信号。这些机制主要用于简单的进程协同,功能相对有限
-
System V IPC: 20 世纪 80 年代,由 AT&T 发布的 System V Release 4 (SVR4) 引入了一套成体系的 IPC 方案,包括 System V 消息队列 、System V 共享内存 和 System V 信号量。其特点是自成体系,拥有独立的标识符和权限管理,至今仍被广泛应用
-
POSIX IPC: 随着 IEEE 对 POSIX 标准的制定,为了提供更统一、更易用的接口,引入了 POSIX IPC(包括消息队列、共享内存和信号量)。相比 System V,POSIX IPC 的接口设计更为现代,在实时性和可移植性上更具优势
2. IPC 主要分类
根据通信的功能和实现机制,可以将 IPC 分为以下三大类别:
(1)管道
管道是 Unix 操作系统中最古老、最基础的 IPC 形式。其核心特征是基于字节流的单向传输
-
匿名管道: 仅限于具有亲缘关系(如父子进程)的进程间通信。它没有文件系统路径,随进程的创建而产生,随进程的终止而销毁
-
命名管道: 克服了匿名管道只能在亲缘进程间通信的限制。它在文件系统中拥有一个路径名,允许无亲缘关系的进程通过打开该文件进行通信
(2)System V IPC
System V IPC 是由 AT&T System V 操作系统引入的通信机制。在 Linux 内核中,它拥有一套独立的资源管理方式
-
System V 消息队列: 允许进程以消息块为单位发送数据,支持按类型过滤读取
-
System V 共享内存: 允许不同进程映射同一块物理内存。这是最快的 IPC 方式
-
System V 信号量: 主要用于进程间的同步与互斥
(3)POSIX IPC
POSIX IPC 是 IEEE 为了统一 Unix 环境下的编程接口而制定的标准。相比 System V,其接口设计更加规范,且大多通过文件描述符进行操作,符合Linux 一切皆文件的思想
-
POSIX 消息队列: 提供属性设置及优先级控制
-
POSIX 共享内存: 通过 shm_open 创建,利用 mmap 进行内存映射,接口更加简洁
-
POSIX 信号量: 分为有名信号量和无名信号量,支持多线程与多进程场景
在分布式系统中,套接字(Socket) 也是一种重要的 IPC 机制,它不仅支持同主机下的跨进程通信,还支持跨网络的远程进程通信
三、管道
在 Linux 系统编程中,管道(Pipe) 是最基础且最常用的通信机制。它允许将一个进程的标准输出(Stdout)直接连接到另一个进程的标准输入(Stdin),从而实现数据的流式传输
1. 什么是管道
从多个维度理解,管道的定义与本质如下:
(1) 基本定义
管道是指将一个进程连接到另一个进程的一个数据流。在逻辑上,它可以被看作是将数据从 A 进程的输出端传给 B 进程输入端的通道
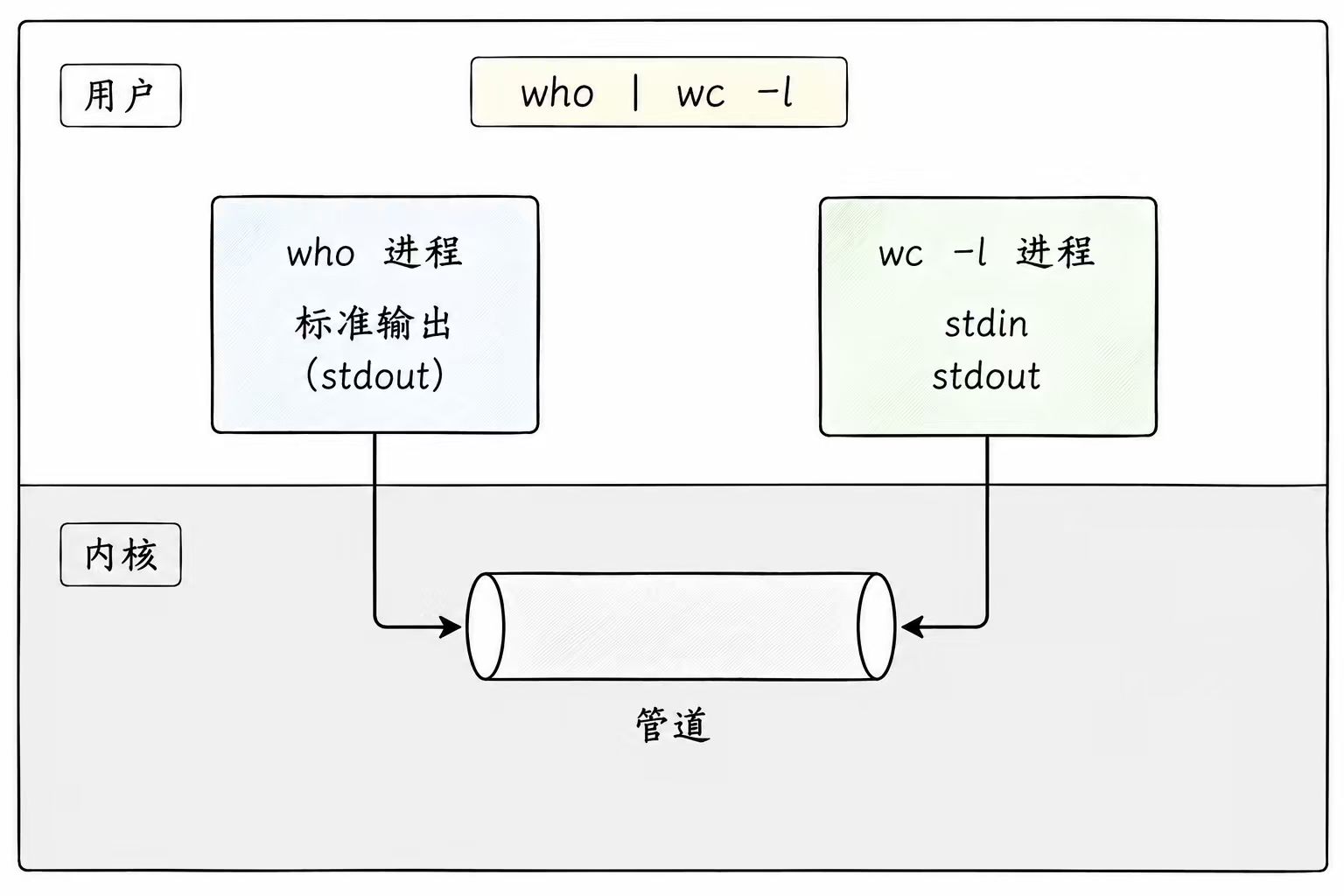
(2) 本质:内核缓冲区
管道在内核层面的实现并非物理文件,而是内核维护的一块缓冲区
-
当进程 A 向管道写入数据时,实际上是将数据拷贝到这块内核缓冲区中
-
当进程 B 从管道读取数据时,实际上是从这块缓冲区中提取数据
-
这块缓冲区的大小通常是有限的(在现代 Linux 内核中通常为 64KB,但会根据系统配置动态调整)
(3) 特殊的文件类型
虽然管道本质上是内核缓冲区,但 Linux 通过一切皆文件 哲学,将其抽象为一种特殊的文件
-
非持久性: 与普通文件不同,管道的数据仅存储在内存中,不会刷新到磁盘
-
接口统一: 开发者可以使用标准的 read()、write() 和 close() 等系统调用来操作管道
-
索引方式: 在进程中,管道通过文件描述符进行引用
管道具有半双工通信的特点,即在同一时刻,数据只能在一个方向上流动。如果需要实现双向通信,通常需要建立两个方向相反的管道
四、匿名管道
匿名管道是 Linux 进程间通信最传统的方式。它没有具体的路径名,通常在内核中申请一块缓冲区,并仅限于具有亲缘关系的进程(如父子进程、兄弟进程)之间使用
1. pipe 系统调用
在 Linux 中,创建匿名管道是通过 pipe 系统调用完成的
cpp
#include <unistd.h>
功能:创建一个无名管道。
原型:int pipe(int fd[2]);
参数:
fd:文件描述符数组。这是一个输出型参数,由内核填充。
其中 fd[0] 表示读端(read end),fd[1] 表示写端(write end)
返回值:成功返回 0;失败返回错误代码(如 -1,并设置 errno)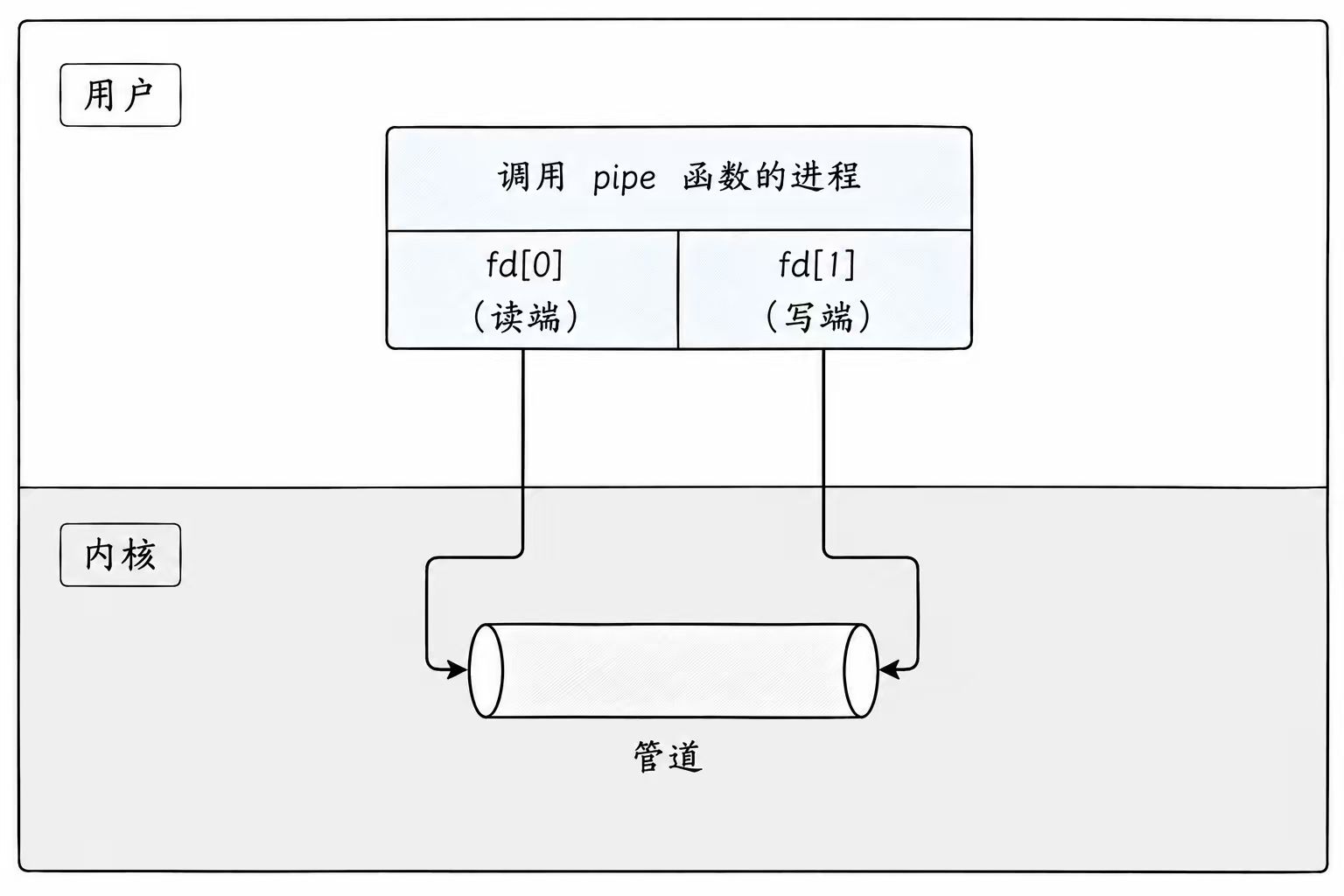
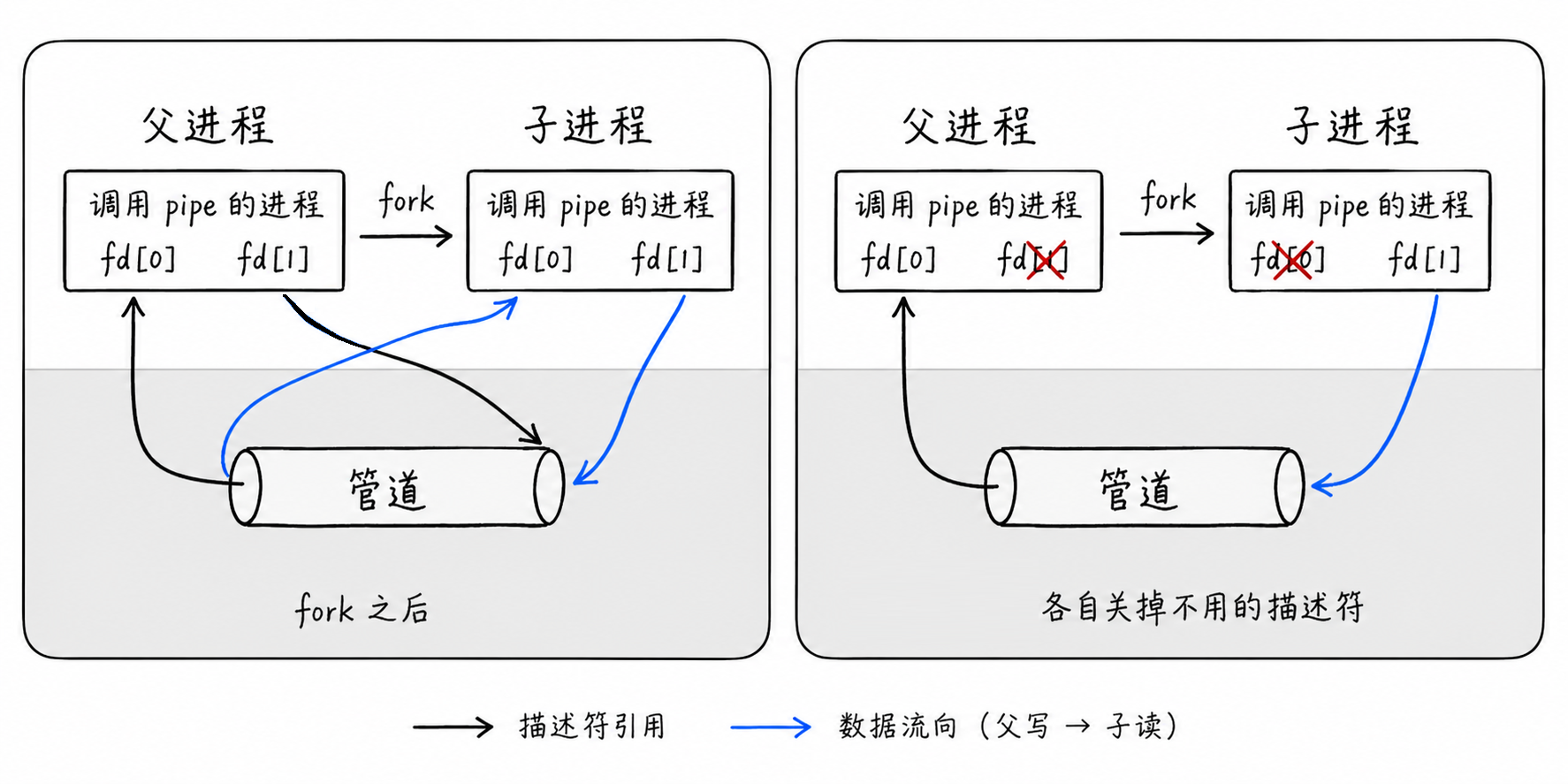
2. fork 共享管道原理
pipe 调用通常与 fork 系统调用配合使用。其核心逻辑如下:
-
父进程创建管道:调用 pipe(fd),在内核中开辟一块缓冲区,并在父进程的文件描述符表中占用两个位置(fd0 和 fd1)
-
创建子进程:父进程调用 fork()。根据进程创建机制,子进程会继承父进程的文件描述符表
-
共享内存缓冲区:此时,父子进程的 fd0 和 fd1 指向内核中同一个管道缓冲区
-
确立通信方向:为了实现单向通信,通常需要关闭不必要的描述符。例如,若要求父进程写、子进程读:
-
父进程关闭 fd0(读端)
-
子进程关闭 fd1(写端)
-
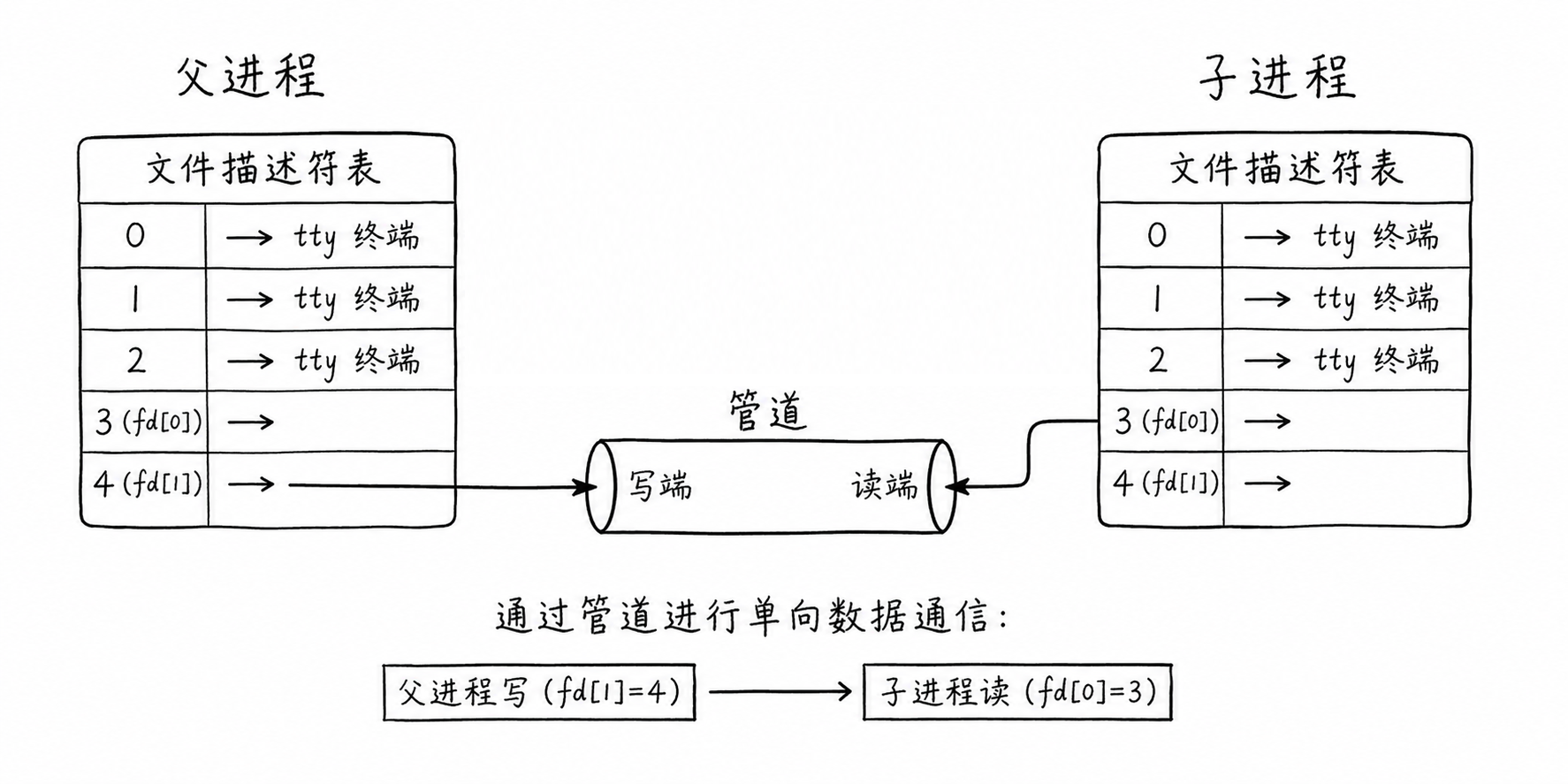
3. 文件描述符视角
(1) files_struct 拷贝
在 Linux 内核中,每个进程由 task_struct 结构体表示,其中包含一个指向 files_struct 的指针,该结构体维护着进程所有打开的文件描述符表
当父进程调用 fork() 时,内核会为子进程创建一份父进程 task_struct 的副本。对于文件描述符表,子进程会完整拷贝父进程的 files_struct。这意味着:
-
子进程拥有与父进程完全相同的文件描述符编号
-
这种拷贝本质上是指针数组的复制 ,父子进程中相同下标的 FD 指向的是内核中同一个
struct file 对象
(2) 共享 file 对象与引用计数
由于父子进程的 FD 指向同一个 struct file 对象,而该对象又直接关联着内核中的管道缓冲区,因此:
-
父进程向 fd1 写入数据,实质上是通过其 file 对象操作内核缓冲区;子进程通过其 fd0 访问同一个 file 对象,从而能读到相同的数据
-
每个 file 对象内部维护着一个引用计数。当 fork 发生后,管道读端和写端对应的 file 对象引用计数均会加 1。这也是为什么建议父子进程各自关闭不用的 FD------只有当所有指向该管道端的描述符都关闭,引用计数归零时,内核才会真正释放该管道资源
(3) 最终的共享路径
从进程空间到内核硬件(内存)的映射路径如下:
父进程 FD -> 内核 struct file -> 管道缓冲区 <- 内核 struct file <- 子进程 FD
这是匿名管道只能用于有亲缘关系进程通信的原因:没有血缘关系的进程无法通过 fork 获取指向同一个内核管道对象的 FD
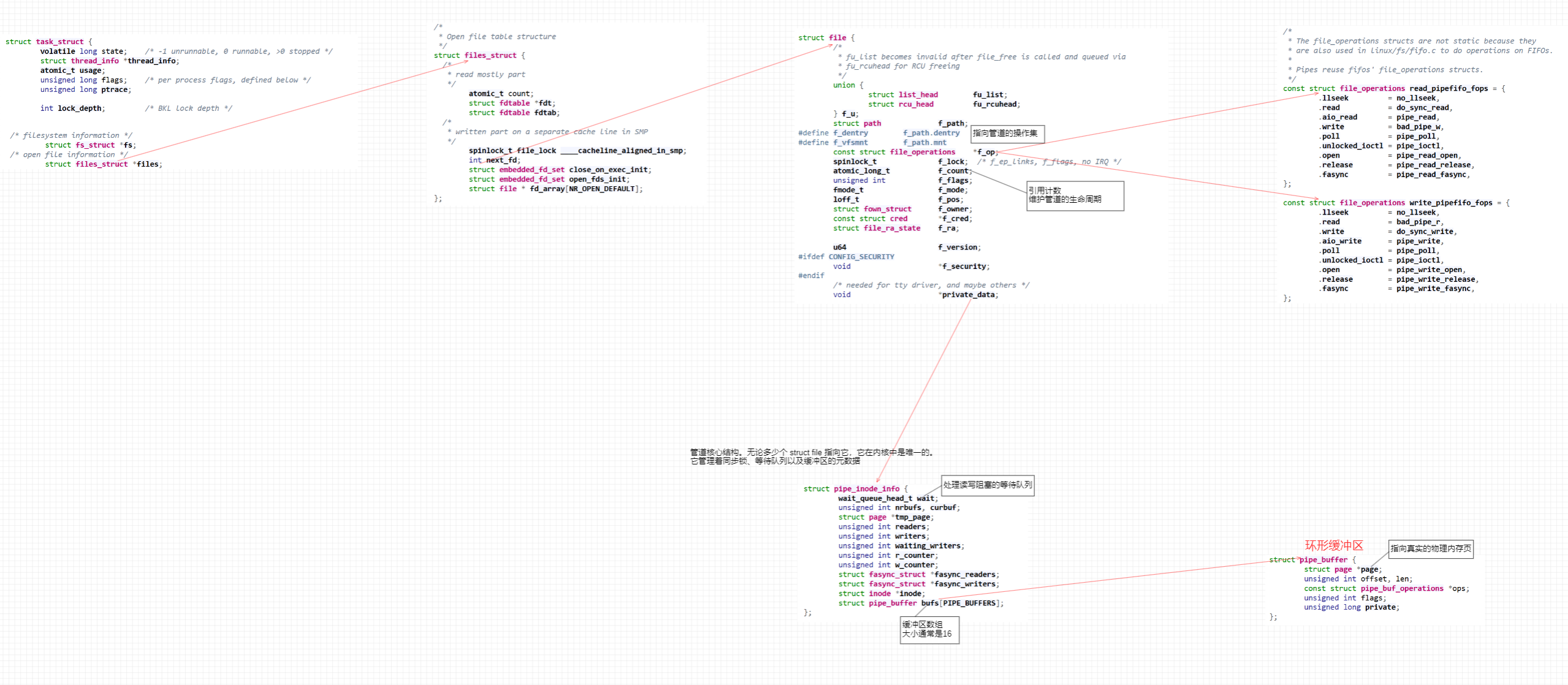
4. 内核视角
在内核空间中,匿名管道的实现依赖于一个特殊的临时文件系统
-
缓冲区实现:内核分配一页或多页(通常是 64KB)作为环形缓冲区
-
同步机制:内核通过等待队列管理读写进程。如果缓冲区为空,读取进程会被阻塞;如果缓冲区已满,写入进程会被阻塞
-
引用计数:内核通过文件引用计数来维护管道的生命周期。只有当所有指向该管道的文件描述符都被关闭时,内核才会释放对应的缓冲区
匿名管道架构图
五、管道通信实战
通过前面的理论铺垫,我们已经知道匿名管道的建立依赖于 pipe() 创建描述符和 fork() 继承描述符。下面通过一个经典的父写子读案例,演示如何实现这一过程
1. 样例代码
在这个实战样例中,我们将遵循规范:父进程关闭读端 fd0,子进程关闭写端 fd1,以构建一个单向的数据传输通道
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
int main() {
// 1. 创建管道
int pipefd[2];
if (pipe(pipefd) == -1) return -1;
// 2. 创建子进程
pid_t id = fork();
if (id == 0) {
// 子进程:负责读取
// 3. 关闭子进程不使用的写端
close(pipefd[1]);
char buffer[1024];
ssize_t s = read(pipefd[0], buffer, sizeof(buffer) - 1);
read(piped[0], buffer, sizeof(buffer) - 1);
printf("child: %s", buffer);
close(pipefd[0]);
exit(0);
}
// 父进程:负责写入
// 3. 关闭父进程不使用的读端
close(pipefd[0]);
const char* msg = "Hello Child\n";
int count = 5;
while (count--) {
write(pipefd[1], msg, strlen(msg));
sleep(1); // 每秒写入一次
}
// 4. 通信结束,关闭写端
close(pipefd[1]);
// 等待子进程退出
waitpid(id, NULL, 0);
return 0;
}-
单向通道的确立 :在 fork() 之后,父子进程都拥有 pipefd0 和 pipefd1。虽然不关闭不用的端也能通信,但规范操作是必须关闭。这不仅是为了节省文件描述符资源,更是为了触发管道的特定读写规则
-
read 的阻塞特性 : 在代码中,如果父进程没有写入,子进程的 read 调用会默认进入阻塞状态,等待内核缓冲区中有数据到来
六、管道读写规则
管道通信并非简单的数据读写,内核针对不同的资源状态(空、满、关闭)以及并发安全性,制定了一套严格的读写规则。理解这些规则是编写健壮的 IPC 代码的前提
1. 读规则
当进程尝试从管道读取数据时,其行为取决于管道当前的缓冲区状态以及是否设置了非阻塞标志(O_NONBLOCK):
-
缓冲区为空时:
-
默认状态(阻塞): read 调用会阻塞,进程挂起,直到管道中被写入数据
-
**非阻塞状态:**read 立即返回 -1,并设置 errno 为 EAGAIN。
-
-
写端连接状态:
-
所有写端关闭: 如果指向管道写端的所有文件描述符都已关闭,且缓冲区内无剩余数据,read 将返回 0,表示读取到文件末尾(EOF)
-
仍有写端开启: 即使当前缓冲区没有数据,只要写端 FD 引用计数不为 0,读进程就会持续等待
-
2. 写规则
写入规则同样受到缓冲区空间及读端状态的影响:
-
缓冲区已满时:
-
默认状态(阻塞): write 调用会阻塞,直到读进程取走数据腾出空间
-
非阻塞状态: write 立即返回 -1,并设置 errno 为 EAGAIN
-
-
读端连接状态:
- 所有读端关闭: 如果指向管道读端的所有文件描述符都已关闭,此时执行 write 操作被视为非法。内核会向写进程发送 SIGPIPE信号,这通常会导致写进程异常退出
-
原子性:
-
当写入数据量 <= PIPE_BUF 时,Linux 保证操作的原子性。这意味着多个进程同时向管道写数据时,数据不会交织,要么全部写入,要么都不写
-
当写入数据量 > PIPE_BUF 时,Linux 不再保证原子性。数据可能会与其它进程的写入数据重叠交织
-
注: 在 Linux 系统中,PIPE_BUF的值通常为 4096 字节
七、管道特点总结
综上所述,管道本质上是一种基于内核缓冲区实现的文件式通信机制。通过 fork 之后父子进程共享文件描述符表中的 file 对象,双方得以访问同一份管道缓冲区,从而完成数据传输
作为最早出现的 IPC 机制之一,匿名管道具有实现简单、使用方便等优点,非常适合具有亲缘关系的进程之间进行单向通信。但与此同时,它也存在明显局限:只能用于父子等亲缘进程之间,生命周期依赖进程本身,并且默认仅支持半双工通信
也正因如此,Linux 后续又逐步发展出了命名管道、共享内存、消息队列等更灵活的通信机制,以满足不同场景下的进程协作需求
在下一篇中,我们将进一步学习命名管道,并基于管道通信机制尝试实现一个简易的进程池,从理解通信真正迈向利用通信组织多个进程协同工作
