一、知识图谱概念描述
知识图谱(Knowledge Graph)是一种将离散知识以实体和关系形式组织成可计算语义网络的知识表示方法。
核心特征包括:
- 知识关联化:将分散的数据通过语义关系连接,形成网状结构,揭示隐含联系。
- 语义显式化:以明确的语义约束表达知识含义,减少歧义,提升可解释性。
- 结构可计算:以图结构存储,支持高效查询、推理与计算。
- 知识可演化:支持持续更新与扩展,适应知识随时间变化的需求。
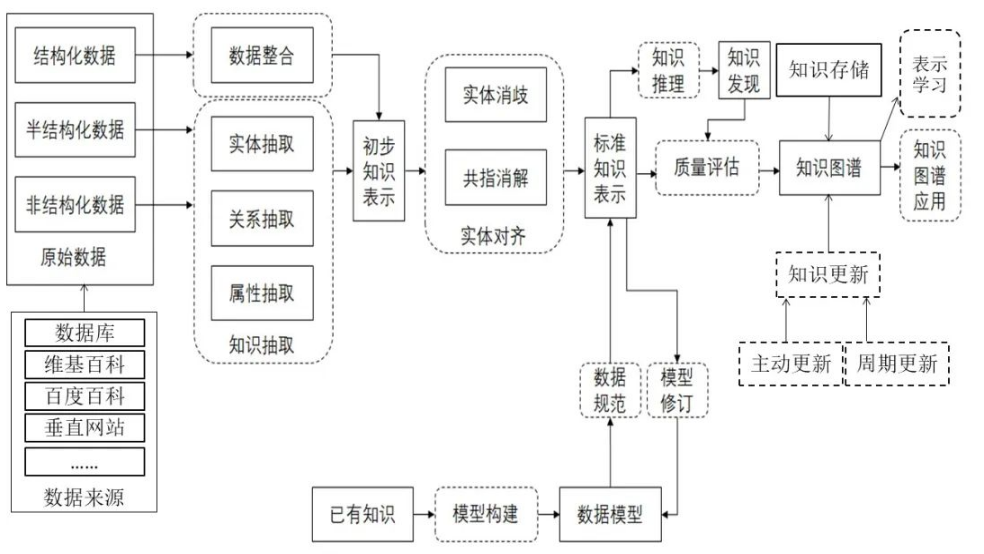
知识图谱相关技术包括知识图谱构建、存储、更新与应用。下图展示了一个知识图谱构建与应用的完整流程框架,涵盖了从原始数据获取到知识图谱生成、更新和应用的全过程。是知识图谱从数据源到实际应用的完整生命周期,主要分为以下几个阶段:
- 数据来源与预处理:数据来源包括数据库、维基百科、百度百科、垂直网站等,涵盖结构化、半结构化和非结构化数据。原始数据经过数据整合后进入知识抽取阶段。
- 知识抽取 :是构建知识图谱的核心步骤之一,主要包括:
实体抽取:识别文本中的关键实体(如人名、地点、组织等)。
关系抽取:提取实体之间的语义关系(如"张三是北京大学的教授")。
属性抽取:获取实体的属性信息(如"张三的出生年份是1980年")。 这些过程统称为"知识抽取",输出为初步知识表示。 - 知识融合与标准化 :为了消除歧义和冗余,需要进行以下处理:
实体消歧:解决同一实体在不同来源中被不同命名的问题(如"马云"和"Jack Ma")。
共指消解:识别指向同一实体的不同表达(如"他"指代"马云")。
实体对齐:跨数据源匹配相同实体。 这些操作最终形成统一的标准知识表示。 - 知识本体建模与规范:基于已有知识和领域经验,进行模型构建,定义知识图谱的数据模型(如本体或schema)。同时通过数据规范和模型修订来优化知识表示的一致性和可扩展性。
- 知识推理与发现:利用逻辑规则或机器学习方法进行知识推理,推导出隐含的知识(例如:若A是B的父亲,B是C的父亲,则A是C的祖父)。进行知识发现,挖掘潜在模式或关联。
- 知识存储与质量评估:将整理后的知识以图结构形式存储为知识图谱。通过质量评估确保知识的准确性、完整性与一致性。
- 知识图谱的应用 :知识图谱可用于多种下游任务,如:
搜索引擎优化(语义搜索)、推荐系统、智能问答、决策支持系统、同时支持表示学习(如图神经网络),提升机器理解能力。 - 知识更新机制 :知识图谱并非静态,需持续维护。包括基于新数据或事件触发的主动更新与定期批量的周期更新等。更新后的知识反馈回"标准知识表示",实现闭环迭代。
二、 知识图谱本体设计
2.1 知识图谱本体概述
1980年,本体论(Ontology)哲学概念"本体"被引入到人工智能领域用来刻画知识。本体是共享概念模型的明确的形式化规范说明,该定义体现了本体的四层含义:
- 概念模型:本体对事物的描述形成了一组组的概念。
- 明确:本体中术语、属性和定理都有明确定义,不是模棱两可的。
- 形式化:本体能够被计算机刻度,能够被计算机所处理。
- 共享:所体现的知识都是被大家认可的,是该领域公认术语集合。
本体是实体存在形式的描述,往往表述为一组概念定义和概念之间的层级关系,本体框架形成树状结构,通常被用来为知识图谱定义Schema。
2.2 schema构建方法
2.2.1 基于通用领域与特定领域
对于通用领域知识图谱,通常只需要宽泛的定义 schema 或者直接使用 openkg 等开发知识图谱的结构,甚至采用"无 schema"模式,直接将数据结构化为 SPO 的三元组结构即可。
特定领域的应用,对知识的精确性要求较高。因此需要构建领域数据的 Schema 模式,包括定义数据的概念、类别、关联、属性约束等。
2.2.2 基于构建顺序
"自顶向下"的方法适用于对领域知识体系已有深刻的洞察和全面了解的情况。
"自底向上"则是反向的认知路径。在已有大量数据表、文本时,先基于业务,定义具体的概念及其属性、关系。再对拥有高重叠属性/关系的概念进行聚类,抽象出共同的 super-concept。
2.2.3 七步法
斯坦福大学医学院开发的七步法,主要用于领域本体的构建:
① 第一步 确定本体的领域和范围
首先应该定义本体的领域和范围,即回答下列的基本问题:
本体覆盖的领域是什么?
要用这个本体来干什么?
本体中的信息应该为何种类型的问题提供答案?
谁将来使用并维护本体?
在确定了本体的基本范围后,一种确定本体具体范围的方法是,列出一系列本体应该能够回答的问题,这些问题被称为 competency questions,其专注于本体所涉及的领域,但也不用过于具体,将用这些问题来对已完成的本体进行测试,观察其是否能提供足够的信息。
② 第二步 考虑重用现有的本体
在从头开始构建本体之前,最好先调研是否有相关的本体已经被构建出来了。可以基于这些本体进行进一步的改进和扩展。当前大部分本体都以电子形式提供,能够直接导入,可以方便地进行扩展。
③ 第三步 列举本体中的重要术语
写下我们想要展示的所有术语的列表。一开始不需要考虑术语之间的关系或概念重叠等问题,先保证列表的全面性。
接下来的两步是开发类层次结构以及定义概念属性。这两步是本体设计中最重要的步骤,也是联系紧密的两步,我们通常先在层次结构中创建一些概念,然后描述这些概念的属性。
④ 第四步 定义类及其层次结构
定义类及其层次结构通常有以下几种方法:
自顶向下的方法:先定义领域中最宽泛的概念,然后进行细化
自底向上的方法:先定义领域中最具体的概念,然后进行归纳
混合方法:将上述两种方法结合起来
上述三种方法没有优劣之分,取决于开发者对于领域的视角。不论使用哪种方法,都需要先定义类,再定义层次结构。先从第三步中的列表中选取能描述对象独特性的术语作为类,然后将这些类按层次结构组织。
⑤ 第五步 定义类的属性
仅仅靠类无法提供足够的信息,还需要定义类的属性来进一步描述类。
从第三步的列表中选择了术语来构建类后,大部分剩余的术语都将是类的属性。一般来说,属性可以分为以下几种:
内在属性:如酒的味道
外在属性:如酒的名称、地域
部件:针对结构化的对象,可以是物理或抽象的部件
关系:与其他个体之间的关系(注意和类层次结构区分)
所有的子类都会继承其父类的属性,属性应该被放置到最宽泛的类中(即越靠近顶层越好)。
⑥ 第六步 定义属性的限制
类的属性有着许多限制(facets),如值的类型、允许的值、值的数量等。下面将介绍一些常见的 facets:
(1)属性基数:
定义一个属性可以有多少个值。有些本体只区分单数或复数的基数,有些本体则进一步定义基数最大和最小值;
(2)属性值类型:
描述一个属性的值的类型,常见的类型有:
- String 类型
- Number 类型
- Boolean 类型
- Enumerated 类型
- Instance 类型
(3)属性的领域和范围
对于 Instance 类型的属性,其允许的类的列表被称为属性的范围(range),而一个属性所属的类被称为该属性的领域(domain)。领域一般不需要单独指定,在设置属性时通常默认被设置的类为该属性的领域。
决定一个属性的领域和范围的法则是类似的:尽量保持类的宽泛性,但不要过于宽泛。
⑦ 第七步 创造实例
最后一步是创造类的具体实例,步骤如下:
选择一个类、创造该类的实例、填充属性值
三、 知识抽取技术
3.1 知识抽取概述
知识抽取是构建大规模知识图谱的重要环节,是对知识本体建模定义的知识要素进行实例化的过程。知识抽取依据领域知识表示实现从多源异构、多规模数据中获取知识,为后续知识融合、知识推理等提供知识支撑。
知识抽取技术由知识工程的相关任务演变而来。知识工程诞生以后,经过繁荣发展,不断产生了新的知识表示语言和方法。传统知识工程通常是自上而下实现的,需要依赖专家表达、获取和运用知识。由于人工构建的知识库规模和知识覆盖面有限,以及专家对知识的认知很难完全统一,专家知识也具有高度不确定型、不精确性;导致很难用统一的符号精确刻画专家知识。
知识图谱为摆脱传统知识工程的困境将知识获取的内容限定于界面比较清晰的任务,同时强调依靠大数据来自动化地获取知识,注重知识的规模。知识抽取主要包括以下几个核心子任务。
- 命名实体识别(Name Entity Recongnition, NER)
- 关系抽取(Relation Extraction, RE)
- 事件抽取(Event Extraction, EE)
3.2 命名实体识别
从文本中检测出命名实体,并将其分类到预定义的类别中,例如人物、组织、地点、时间等。命名实体识别通常是知识抽取中其他任务的基础。
例如,给定一段新闻报道中的句子"北京时间10月25日,骑士后来居上,在主场以 119:112击退公牛"。实体抽取旨在获取如图4-2所示的结果。例句中的"北京""10月25日"分别为地点和时间类型的实体,而"骑士"和"公牛"均为组织实体。
实体抽取问题的研究开展得比较早,该领域也积累了大量的方法。总体上,可以将已有的方法分为基于规则的方法、基于统计模型的方法和基于深度学习的方法。
3.2.1 基于规则的方法
早期主要采用人工编写规则的方式进行实体抽取,如正则匹配。一般由具有一定领域知识的专家手工构建。然后,将规则与文本字符串进行匹配,识别命名实体。这种实体抽取方式在小数据集上可以达到很高的准确率和召回率, 但随着数据集的增大,规则集的构建周期变长,并且移植性较差。
3.2.2 基于统计模型的方法
此类方法将命名实体识别作为序列标注问题处理。序列标注,是指对满足序列结构的数据进行分类,属于特殊的分类问题。具有序列结构的数据在空间或时间维度上前后存在依赖的关系,文本类型数据具有非常典型的序列结构,因此很多文本分析问题转化为序列标注问题处理。基于统计模型构建命名实体识别方法主要涉及训练语料标注、特征定义和模型训练三个阶段。
(一)训练语料标注
为了构建统计模型的训练语料,需要设计标注方案给出标注的定义方式, 对训练文本语料进行人工标注。其中比较流行的"BIO"标注方案是这样表示的:B,即Begin,表示开始;I,即Intermediate,表示中间;O,即Other,表示其它,用于标注无关字符。
(二)特征定义
在训练模型之前,统计模型需要计算每个词的一 组特征作为模型的输入。这些特征具体包括单词级别特征、词典特征和文档级特征等。单词级别特征包括是否首字母大写、是否以句点结尾、 是否包含数字、词性、词的 n-gram 等。词典特征依赖外部词典定义, 例如预定义的词表、地名列表等。文档级特征基于整个语料文档集计算,例如文档集中的词频、同现词等。
(三)模型训练
常用机器学习模型:
1、隐马尔可夫模型(Hidden Markov Model,HMM)
隐马尔可夫模型是可用于标注问题的统计学模型,描述由隐藏的马尔科夫链随机生成观测序列的过程,属于生成模型。
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐藏的马尔科夫链随机生成的状态的序列称为状态序列(state sequence);每个状态生成一个观测,而由此产生的观测的随机序列称为观测序列(observation sequence)。序列的每一个位置又可以看作是一个时刻。
状态转移该概率矩阵A与初始状态概率向量π确定了隐藏的马尔科夫链,生成不可观测的状态序列。观测概率矩阵B确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。
隐马尔可夫模型做了两个基本假设:
(1)齐次马尔可夫性假设
(2)观测独立性假设
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态的序列,再由各个状态随机生成一个观测而产生观测的序列的过程。
2、条件随机场模型(Conditional Random Fields, CRF)
条件随机场是给定一组输入随机变量条件下,另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔可夫随机场。线性链条件随机场,是输入序列对输出序列预测的判别模型,形式为对数线性模型,其学习方法通常是极大似然估计或正则化的极大似然估计。
3.2.3 基于深度学习的方法
与传统统计模型类似,基于深度学习的方法也将命名实体识别作为序列标注问题处理;但在特征定义阶段存在不同,深度学习方法直接以文本中词的向量为输入,通过神经网络实现端到端的命名实体识别,不再依赖人工定义的特征。
常用深度学习模型:
CNN
卷积网络通过对局部的卷积运算,学习到具备空间信息的局部模式。通过多次卷积,就能学习到越来越复杂和抽象的视觉概念。
卷积神经网络主要由这几类层构成:输入层、卷积层,ReLU层、池化(Pooling)层和全连接层。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络。在实际应用中往往将卷积层与ReLU层共同称之为卷积层,卷积层经过卷积操作也是要经过激活函数的。
RNN
循环神经网络(Recurrent Neural Network, RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息。
引入注意力的神经网络
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。那么通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。
DNN+CRF
一个 RNN 的示意图如下所示,
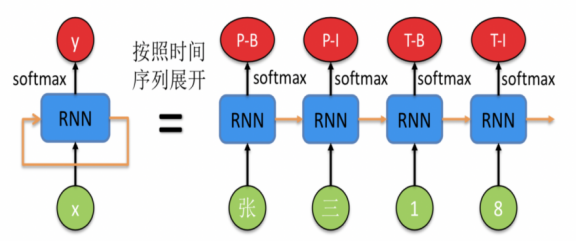
左边是原始的 RNN,可以看到绿色的点代码输入 x,红色的点代表输出 y,中间的蓝色是 RNN 模型部分。橙色的箭头由自身指向自身,表示 RNN 的输入来自于上时刻的输出,这也是为什么名字中带有循环(Recurrent)这个词。
右边是按照时间序列展开的示意图,注意到蓝色的 RNN 模块是同一个,只不过在不同的时刻复用了。这时候能够清晰地表示序列标注模型的输入输出。
GRU为了解决长期记忆和反向传播中梯度问题而提出来的,和LSTM一样能够有效对长序列建模,且GRU训练效率更高。
使用GRU可以解决长句子的问题。
条件随机场CRF(Conditional Random Fields)
长句子的问题解决了,序列标注任务的另外一个问题也亟待解决,即标签之间的依赖性。举个例子,我们预测的标签一般不会出现 P-B,T-I 并列的情况,因为这样的标签不合理,也无法解析。无论是 RNN 还是 LSTM 都只能尽量不出现,却无法从原理上避免这个问题。下面要提到的条件随机场(CRF,Conditional Random Field)却很好的解决了这个问题。
条件随机场这个模型属于概率图模型中的无向图模型,这里我们不做展开,只直观解释下该模型背后考量的思想。一个经典的链式 CRF 如下图所示,
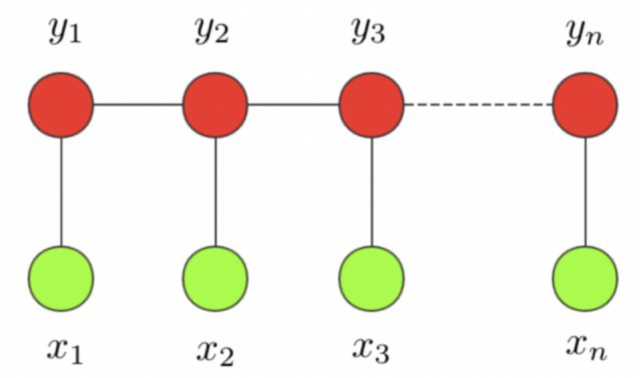
CRF 本质是一个无向图,其中绿色点表示输入,红色点表示输出。点与点之间的边可以分成两类,一类是 x与 y之间的连线,表示其相关性;另一类是相邻时刻的 y之间的相关性。也就是说,在预测某时刻 y 时,同时要考虑相邻的标签解决。当 CRF 模型收敛时,就会学到类似 P-B 和 T-I 作为相邻标签的概率非常低。
3.3 关系抽取
从文本中识别出抽取实体及实体之间的关系。关系抽取与实体抽取密切相关,一般在识别出文本中的实体后,再抽取实体之间可能存在的关系。关系抽取方法可分为基于模板的方法、基于监督学习的方法和基于弱监督学习的方法。
3.3.1 基于模板的关系抽取方法
早期的实体关系抽取方法大多基于模板匹配实现。该类方法基于语言学知识结合语料的特定,由领域专家手工编写模板,从文本中匹配具有特定关系的实体。在小规模、限定领域的实体关系抽取问题上,基于模板的方法能够取得较好的效果。
例句:徐峥老婆陶虹晒新写真
模板:X老婆Y ......
利用上述模板在例句文本中进行匹配,可以获得新的具有"夫妻"关系的实体。该方法的优点是构建简单、可以快速在小规模数据集上实现;缺点是规模较大时手工构建模板需要耗费领域专家大量的时间、可移植性较差、手工构建的模板数量有限模板覆盖的范围不够、召回率普遍不高。
3.3.2 基于监督学习的关系抽取方法
利用监督学习的方法进行关系抽取的一般步骤包括:
预定义关系的类型;解码设计;人工标注数据;选择分类模型;基于标注数据训练模型;模型评估。
(一)关系抽取模型的解码设计
1.Novel-Tagging标注方案
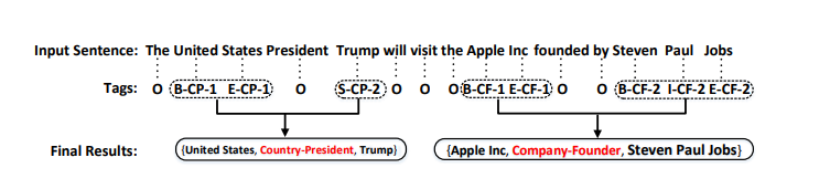
Novel-Tagging标注方案使用"BIES"(开始、内部、结束、单个)符号来表示单词在实体中的位置信息。每个单词都有一个标签,有助于提取结果。标记"O"表示"其他"标记。除了"O"之外,其他标记由三部分组成:单词在实体中的位置、关系类型和关系角色。关系类型信息是从预定义的一组关系中获得的,下图中的CP、CF即表示关系类型;关系角色信息由数字"1"和"2"表示。提取的结果由三元组表示:(Entity1,RelationType,Entity2)。"1"表示单词属于三元组中的第一个实体即头实体,而"2"属于关系类型后面的第二个实体即尾实体。
2.Novel Cascade标注方案
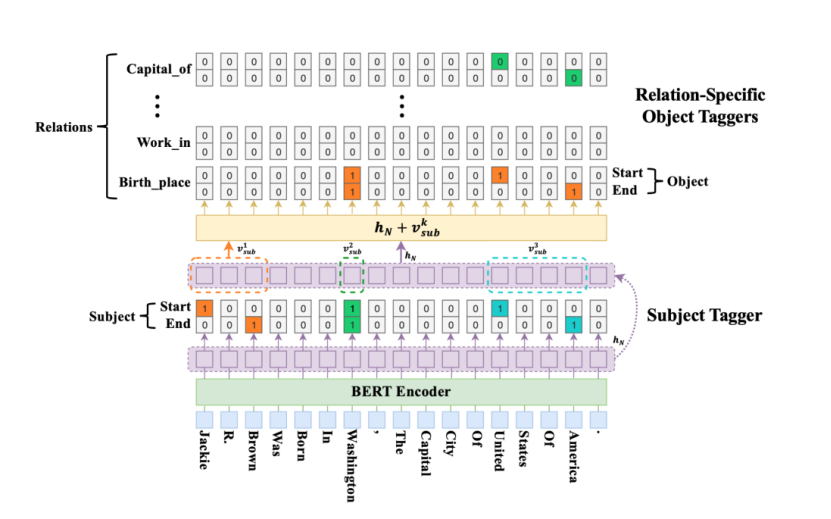
基本思想是在两层级联步骤中提取三元组。首先,从输入句子中识别头实体。然后,对于每一个候选实体,检查所有可能的关系,判断一个关系是否可以将句子中的尾实体与该头实体相关联。对应于这两个步骤,级联解码器由两个模块组成,如下图所示:subject tagger和一组relation-specific object taggers。
subject tagger下层标记模块设计用于识别输入句子中的所有可能头实体;采用两个相同的二进制分类器,通过为每个token分配一个二进制标记(0、1)来分别识别实体的开始和结束位置,该标记表示当前token是否对应于实体的开始或结束位置。对于多个实体检测,采用最近开始-结束对匹配原则,根据开始和结束位置标记器的结果来确定实体的跨度。如下图所示,距离第一个开始标记"Jackie"最近的结束标记是"Brown",因此第一个实体跨度的检测结果将是"Jackie R.Brown"。注意,为了将结束标记与开始标记匹配,将不考虑在给定标记位置之前的标记。
relation-specific object taggers上层标记模块同时识别尾实体以及与subject tagger获得的头实体相关的关系。它由一组特定于关系的尾实体标签组成,其结构与下层模块中的subject tagger相同,适用于所有可能的关系。
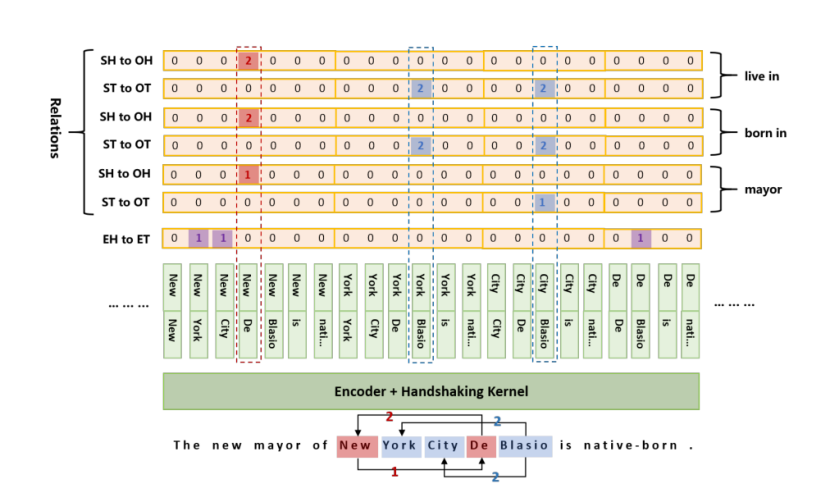
3.TPLinker标注方案
如下图所示SH是主语头部的缩写,OH是宾语头部的缩写,ST是主语尾部的缩写,OT是宾语尾部的缩写。通过解码,可以提取出5个三元组: (New York,mayor, De Blasio), (De Blasio, born in, New York), (De Blasio, born in, New York City), (De Blasio, live in, New York),(De Blasio, live in, New YorkCity)
(二)基于深度学习的关系抽取模型
基于深度学习的关系抽取模型主要包括流水线方法和联合抽取方法两大类。
流水线方法将识别实体和关系抽取作为两个分离的过程进行处理,两者不会相互影响;关系抽取在实体抽取结果的基础上进行,因此关系抽取的结果也依赖于实体抽取的结果。
联合抽取方法将实体抽取和关系抽取相结合,在统一的模型中共同优化;可以避免流水线方法中的错误积累问题。
2.3.3.3 基于弱监督学习的关系抽取方法
基于监督学习的方式特别是深度学习的方式,需要依赖大量的训练数据。当训练语料不足时,弱监督学习可以只利用少量的标注数据进行模型学习。基于弱监督学习的关系抽取方法主要包括远程监督方法和Bootstrapping方法。
(一)远程监督方法
(二)Bootstrapping方法
3.4 事件抽取
事件抽取需要从一段文本中抽取出预定义的事件触发词和事件要素。在实际使用的过程当中,我们可以把除了关系以外的所有复杂信息全部拆解成关系抽取来解决事件抽取问题。
事件抽取是信息抽取的难点问题;
事件抽取依赖实体抽取和关系抽取;
目前对事件还没有统一的定义,在不同领域针对不同应用不同人对事件有不同的描述。
3.4.1信息抽取中事件的定义
事件:是发生在某个特定的时间段、某个特定的地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事件或者状态的改变。(与事理图谱定义的事件一致)
事件类型: 不同动作或者状态的改变代表不同类型的事件;
事件元素: 同一类型的事件中不同的时间、地点、元素代表了不同的时间实例;
3.4.2事件抽取包含的子任务
识别事件触发词及事件类型;抽取事件元素的同时判断其角色;抽取出描述事件的词组或句子;事件属性标注;事件共指消解
3.4.3事件抽取方法
事件抽取已有方法可分为两大类:流水线方法、联合抽取方法。
(1)事件抽取流水线方法
流水线方法将事件抽取任务分解为一系列基于分类的子任务,包括事件识别、元素抽取、属性分类和可报告性判别;每个任务由一个机器学习分类器负责实施。一个基本的事件抽取流水线需要的分类器包括:
事件触发词分类器。判断词汇是否为事件触发词,并基于触发词信息对事件类别进行分类
元素分类器。判断词组是否为事件的元素。
元素角色分类器。判定时间元素的角色类别。
属性分类器。判定事件的属性。
可报告性分类器。判定是否存在值得报告的事件实例。
(2)事件的联合抽取方法
事件抽取流水线方法各阶段的误差累积起来会影响最终的性能。在联合方法中,事件的所有相关信息会通过一个模型同时抽取出来。
具有代表性的一个联合建模方法是QiLi等人在ACL2013论文中提出的模型。该模型将事件触发词、元素抽取的局部特征和捕获任务之间关联的结构特征结合进行事件抽取。
3.4.4 通用信息抽取
信息抽取任务具有不同子任务(如实体识别、关系抽取等)和特定的需求;目前大多数信息抽取方法都是面向特定任务的,这导致神对不同的信息抽取子任务需要专用的体系结构和独立的模型。为了解决信息抽取系统的快速体系结构开发、有效的知识共享和快速跨领域适应,通用信息抽取模型(Universal Information Extraction, UIE)应运而生。
UIE算法主要分为三个阶段:计算阶段、解析阶段、推理阶段。
- 计算阶段:根据给定的输入内容,按照预设的数据结构分析数据,计算出所需要的结果。
- 解析阶段:UIE按照语句特征,例如实体、关系、事件等进行解析,从而抽取出相应的实体和关系。
- 推理阶段:根据前面两个极端的信息抽取,通过推理技术获取更加精细的信息。
四、知识融合技术
在实际的知识图谱应用中,本体异构造成了大量的信息交互问题。解决本体异构、消除应用系统间的互操作障碍是很多知识图谱应用面临的关键问题之一。另外知识图谱中的大量实例也存在异构问题,同名实例可能指代不同的实体,不同名实例可能指代同一个实体,大量的共指问题会给知识图谱的应用造成负面影响。知识图谱应用还需要解决实例层的异构问题。
知识融合是解决知识图谱异构问题的有效途径。解决知识融合问题首先需要分析造成本体异构和实例异构的原因;还需要明确融合针对的具体对象。知识融合的核心在于映射的生成。知识融合旨在合并知识图谱,它可以起到数据清洗和数据集成的作用。
知识异构的原因分析:
造成知识异构的原因之一是语言层面的不匹配。在知识工程发展的不同阶段曾出现郭多种流行的本体语言,然而不同的语言大多存在不兼容问题,这导致不同时期构建的知识图谱在本体层面存在难以交互的挑战,由此产生了本体的异构性。
一般来说本体语言层次的不匹配可分为原语异构、语法异构、逻辑异构和表达能力异构四类。

模型层面存在的不匹配性也会导致知识的异构性。模型层面的不匹配和具体采用的本体语言无关,具体包含解释不匹配和概念化不匹配两种类型。
解释不匹配主要是由于不同的本体对于相同的术语采用了完全不同的定义。
利用对于同样的实例"汽车",一类本体采用词汇"Auto",而另一中类型的本体采用"Car",这导致了解释的不匹配性。
概念化的不匹配主要是由于本体在领域层次的抽象建模的不同。例如,在对动物知识进行建模时,一类建模专家将"动物"划分为"食草动物"和"食肉动物";而其他一些专家可能会将"动物"分类为"无脊椎动物"和"脊椎动物",这也导致了概念化的不匹配。
五、知识图谱存储技术
5.1 知识图谱存储概述
知识图谱的存储是将知识图谱中的知识数据存储在数据库当中以便于后续的应用查询。知识图谱的底层数据抽象模型从分类上,可以认为是图(Graph)由节点、边等元素构成;但在具体的实现细节上又有一些差异。首先来介绍知识图谱中知识数据的组织形式,即数据模型。
5.2 数据模型
5.2.1 RDF模型
RDF(Resource Description Framework,资源描述框架)是W3C标准化组织制定并推广的主要在语义网领域使用的一项标准化数据模型。RDF的主要结构由主谓宾的三元组形式组成,分别表示主语和宾语两个实体,以及两个实体之间的关系。
- 主语(Subject):是一个实体,用URI或空白节点表示。
- 宾语(Object):是一个实体,用URI或空白节点或字面量表示。
- 谓语(Predicate):表示主语和宾语之间的关系,用URI表示。
其中URI(Uniform Resource Identifier,统一资源标识符)是一个用于标识某一互联网资源名称的字符串。该种标识允许用户对任何(包括本地和互联网)的资源通过特定的协议进行交互操作。资源就是一个对象,每一个资源都有一个URI,一种唯一的标识符。使用 URI 是 RDF背后的一个关键设计方案。它允许全球唯一的命名方案的存在。 使用这种机制能够大幅缓解迄今为止困扰分布式数据表示的一词多义问题。
5.2.2 属性图模型
属性图是当下流行的图数据库Neo4j实现的图结构表示模型。属性图的有点是表达方式非常灵活,在查询计算方面具有较大优势;但属性图缺乏工业标准规范的支持,不关注更深层的语义表达,也不支持符号逻辑推理。
属性图内置了对节点和边进行属性描述的能力。属性图是由顶点(Vertex)、边(Edge)、标签(Label)、关系类型和属性(Property)组成的有向图。顶点也称为节点(Node),边也称为关系(Relationship)。
5.3 存储结构
5.3.1 关系数据库存储
(一)基于三元组表的图谱存储
三元组表(triple table)是将知识图谱存储到关系数据库的最简单、最直接的办法。利用关系数据库,只建一张包含(Subject, Predicate, Object)三列的表,然后把所有的三元组存入其中。典型数据库代表有RDF图数据库系统 3store。
(二)基于水平表的图谱存储
水平表(horizontal table)相当于知识图谱的邻接表。水平表的每行记录存储知识图谱中的一个终于的所有谓语和宾语。水平表的列数是知识图谱中不同谓语的数量,行数是知识图谱中不同主语的数量。典型数据库代表有RDF 图数据库系统 DLDB。
(三)基于属性表的图谱存储
属性表(property table)存储方案是对水平表的细分,将同类主语存到一个表中,解决了表中列数目过多的问题。典型数据库代表有RDF 图数据库 Jena。
(四)基于垂直划分表的图谱存储
垂直划分(vertical partitioning)存储方案,为每种谓语建立一张两列的表(subject,object),表中存放知识图谱中由该谓语连接的主语和宾 语,表的总数量即知识图谱中不同谓语的数量。典型数据库代表有RDF 图数据库SW-Store。
5.3.2 原生图数据库存储
在关系数据库中,属性是从属于某个表的,而实体关系又被隐藏在外键定义中。在图模型中,关系是显示描述和定义的,属性也可以单独定义,这将极大增强数据建模的灵活性。
以Neo4J背后的实现来介绍原生图数据库的物理存储实现,Neo4j最核心的实现是两个文件------节点存储文件和关系边存储文件,同过设计这两个文件的物理结构,对图查询进行了全方位的优化。
知识图谱中的节点存储于独立的"节点存储文件"。每个节点存储空间固定,节点从头至尾依次存储该节点的inUse信息、第一个关系边的ID、第一个属性边ID、第一个LabelID。这些ID都类似于指针便于从该节点出发来快速索引。
知识图谱中的关系或边存储于独立的"关系边存储文件"。关系边的存储空间也固定。从头至尾的字节区段依次代表关系边的inUse信息、头节点ID、尾节点ID、关系边类型ID、头尾节点上一个关系边ID、下一个关系边ID。
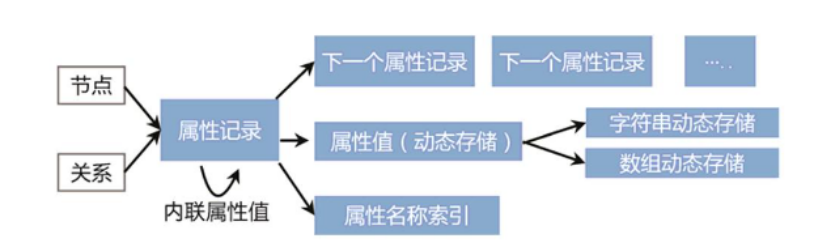
图数据库中存在大量属性,属性的检索与图遍历的计算是分开的。节点和关系边的存储记录都包含指向它们的第一个属性ID的指针,属性记录也是固定大小,便于通过ID计算活得存储位置。每个属性记录包含多个属性快,以及属性链中下一个属性的ID。每个属性记录包含属性类型以及索引文件,属性索引文件存储属性名称。对于每一个属性值,记录包含一个只想动态存储记录的指针或内联值。
5.4 存储方式的对比
RDF数据模型历史悠久,规则严谨,功能也比较完善;但是RDF对于实现不是非常友好,较为冗余烦琐,限制很多,比较难调优。
属性图模型出现的比较晚,应用起来更加灵活,比较容易映射到和现有的存储系统中。
两种模型并不是完全对立的,甚至可以相互转化。如果把边设置成一个独立的点,比如用一个点来表示两个实体之间的关联关系,将边上的属性设置到这个点上,就可以把属性图模型映射成语义相近的RDF模型。
5.5 图数据库性能对比与排名
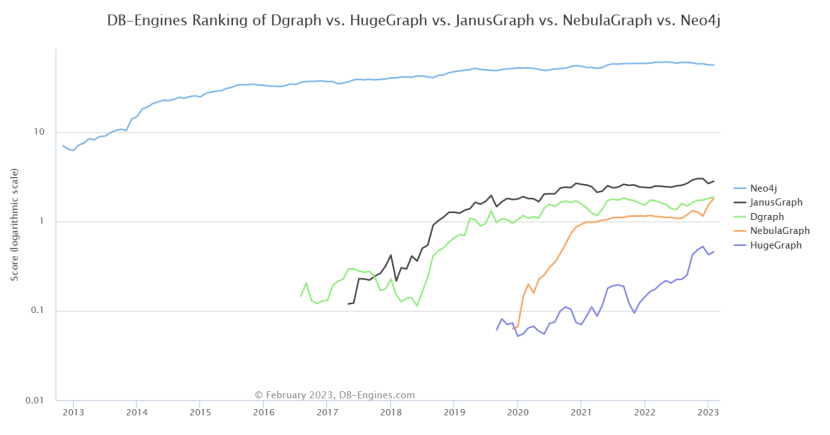
5.5.1 DB-Engines的数据库排名介绍
DB-Engines的数据库排名是根据当前数据库的流行程度进行排名。具体有如下几个维度。
1、数据库系统在网络上被提及的次数。
2、对该数据库感兴趣程度。
3、专业技术讨论中提到该数据库的次数。
4、招聘描述中提及该数据库的次数。
5、专业网站中使用的频率。
6、社交平台的相关度。
5.5.2 RDF图数据库及排名
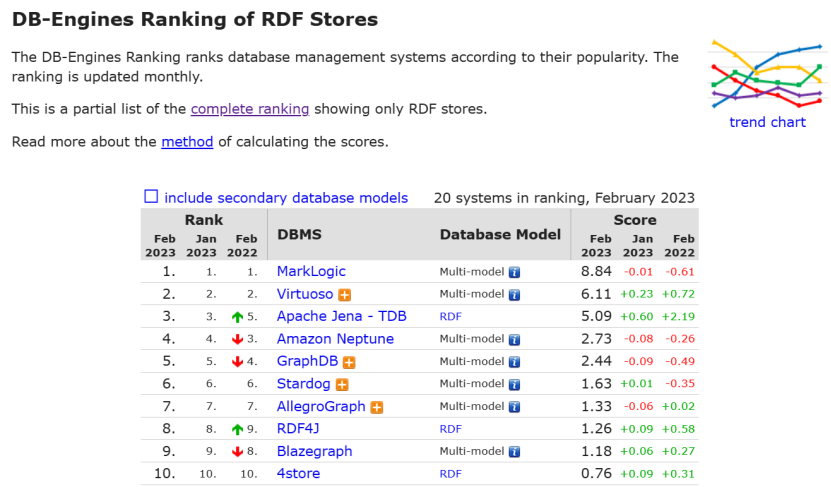
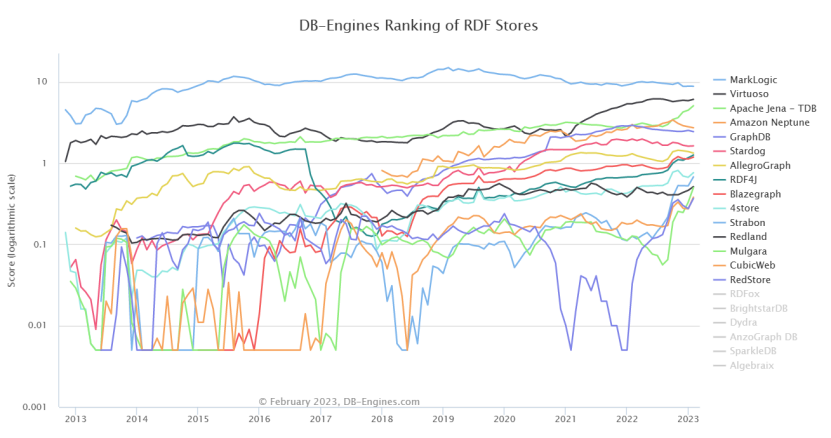
5.5.3属性图数据库及排名
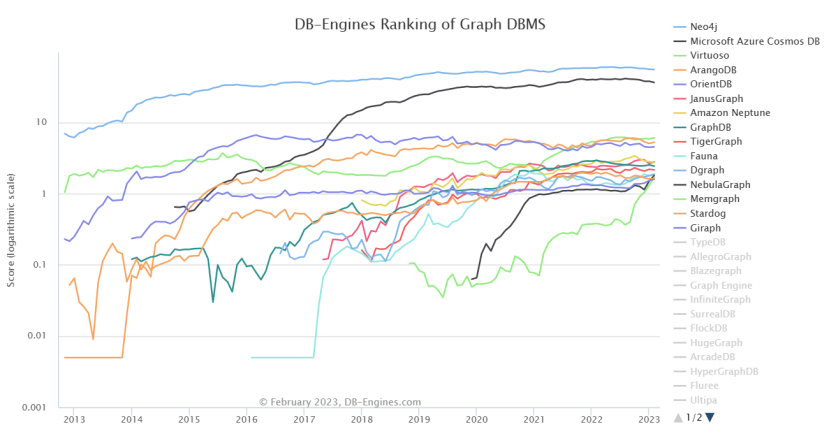
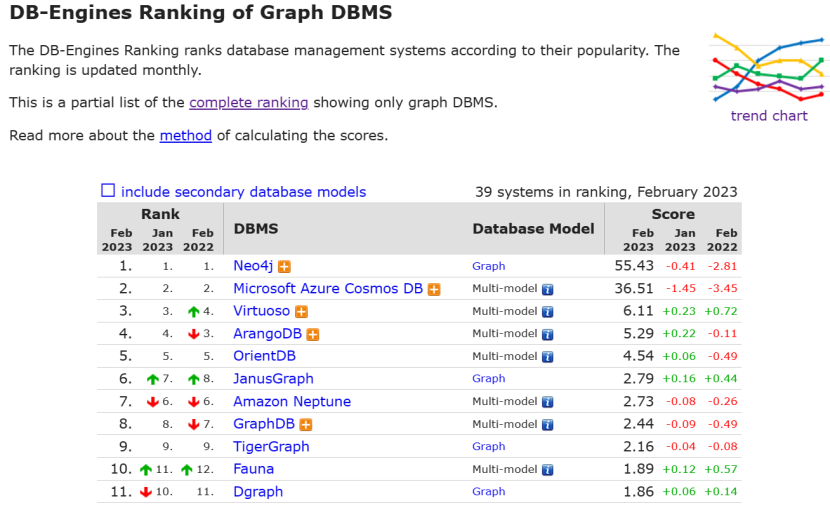
5.5.4属性图数据库对比
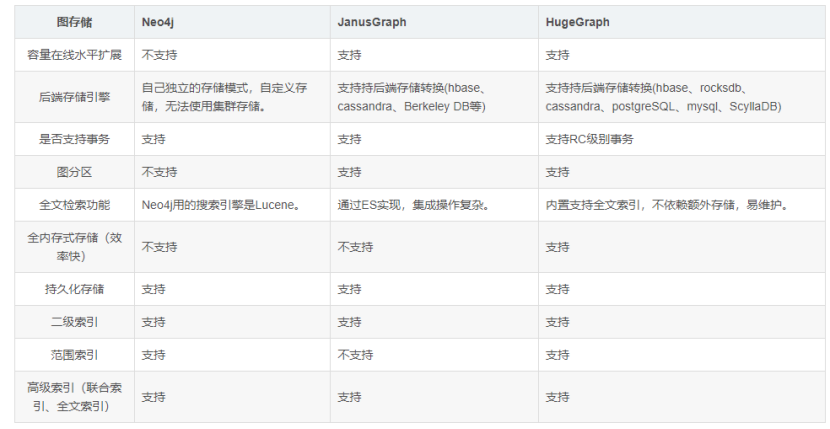
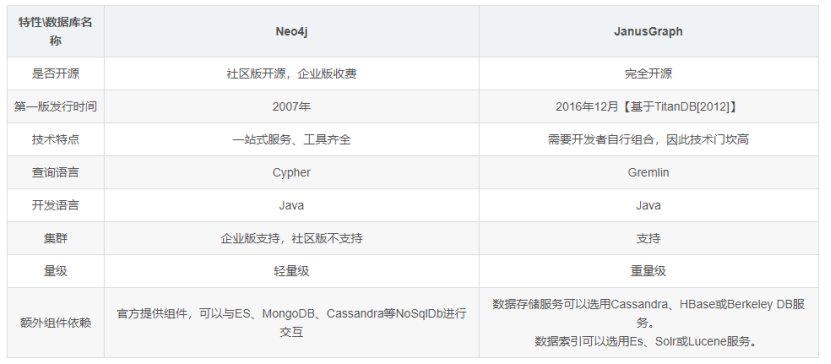
这里主要对HugeGraph、JanusGraph、Neo4j 三种图数据库在功能和性能方面进行的分析对比。
(1)从性能的方面考虑(涉及到数据量大小、是否为集群等因素)
1、Neo4j:单机性能明显,企业版是集群模式(非分布式)
2、hugegraph:单机性能(rocksdb后端)和neo4j相近甚至较好;同时还可以通过配置存储引擎,适用集群存储可支持大数据超千亿级以上(性能相对单机会有所降低)。
3、 JanusGraph:开源的分布式图数据库,单机性能较差。但是分布式可支持大数据超千亿级以上,和apache下的spark、hbase等结合度高
(2)从功能的完备度、易用性等方面考虑
1、Neo4j:功能比较齐全,但是功能都比较独立。和别的存储引擎耦合性低,不能相互组合使用。有可视化操作系统,简单功能可以实现。支持灾备,支持事务锁等。
2、huegraph:功能支持健最齐全,导入组件支持各种数据源。可视化操作组件 hubble 支持功能齐全,存储后端引擎支持宽泛,能和相关的数据库搭配使用,更适合刚上手的用户。整体上常用算法都进行封装过,易用性强。有HA组件支持灾备,事务方面的支持较弱
3、JanusGraph:功能方面支持(不支持可视化界面、HA灾备)其他相关功能都具备。整体上各功能使用没有hugegraph便捷易用。
六、 知识图谱可视化技术
6.1 可视化概述
信息可视化是利用可视化技术方式展示信息结构、挖掘隐含在大量数据中的信息和知识,其基本目的是在大量数据中发现新的见解、增强认知。
知识可视化主要是利用可视化技术来丰富知识表示方式,促进知识在发送者和接收者之间的传播。
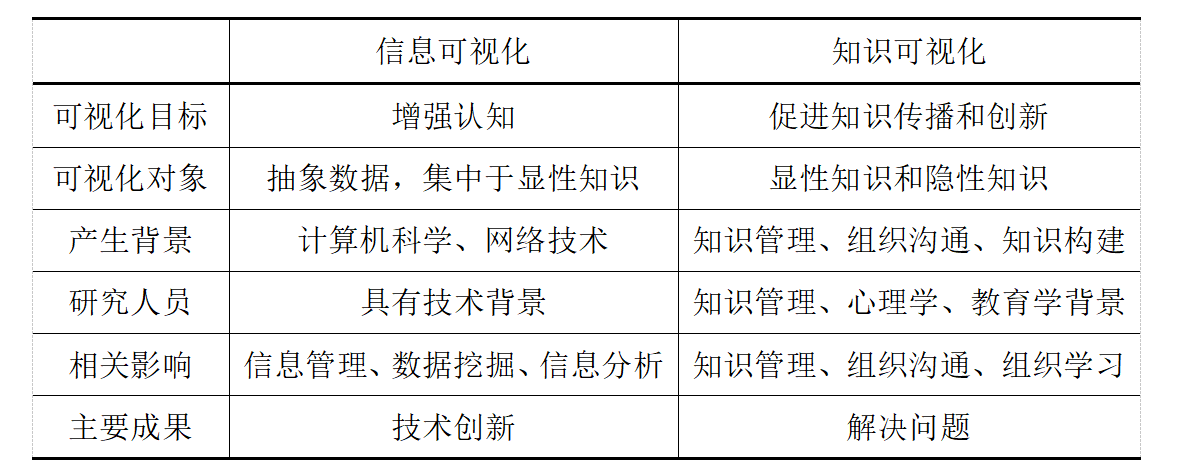
知识图谱的运转过程通常是由数据模型完成,用户可见的只是计算后的结果,其数据的可视化也仅停留在对结果的可读性展示上。但图谱之间的关系、数据计算的过程,也具备分析价值和潜在的机会信息。将知识图谱转化为可视化信息图,能帮助用户更好的理解和利用数据及其关系传统的信息可视化-侧重在数据结果的展示和筛选,较少涉及数据关系的干预。知识图谱的可视化-侧重在数据关系构建和处理过程的可视化。
6.2 知识可视化的优势
1、在沟通过程中,利用可视化表示知识协调不同的参与者,属于社会优势,
2、利用可视化识别模式、观点、趋势,以吸引并保持参与者的注意力属于认知优势
3、提高记忆的程度,因为人们易于用图像思考属于认知优势
4、可以激励、刺激观察者,属于感情优势
5、可以改善小组间详细阐述知识的效果,属于认知优势
6、通过嵌入情境知识、展示对象之间的关系,可以促进新见解的产生,属于认知优势
6.3 知识可视化技术的应用
6.3.1 专家系统中可视化技术应用
在建造基于知识的系统时,一个十分关键问题就是充分获取领域专家的知识。隐形知识获取时,基于案例库、下波纹规则,利用推理的方法,通过描绘专家的认知地图获取专家的隐性知识。具体过程时将专家解决问题的思维过程用图形表示出来,从中提取解决问题的方法,同时,将问题发生的情境和条件等一起存入知识库。
6.3.2 群体决策中可视化技术应用
群体决策是通过沟通交流,由群体参与讨论,共同做出决策的过程,群体决策能够充分调动参与成员的积极性,让他们提供更多的观点和意见,获取更多的备选方案。群体决策过程中会产生大量知识和信息,例如,观点的提出者,观点的内容,观点的数量,观点提出的出发点,观点的支持度,观点与观点之间的关系,观点的可行性,方案形成的过程等。将可视化技术应用到群体决策过程中,可以有效组织这些知识和信息,让参与成员更易把握复杂问题和特征以及其他成员的观点和意见,让不易描述和表达的隐含结构表达出来,让参与成员进行发散性思维、联想出更多的观点和意见,同时可以减少甚至消除参与成语之间的误解与分歧,让参与成员对各种备选方案做出更为正确的判断,提高群体决策的质量。
6.4 知识图谱可视化工具
6.4.1 可视化基本技术
知识图谱的可视化经过是一个逐步演进的过程,经过了几个阶段的技术引入,包括SVG、Canvas2D、WebGL、WebGL2等,目前的技术主要以2D为主。
1、可缩放矢量图形(Scalable Vector Graphics,SVG),是一种用于描述二维的矢量图形,基于XML的标记语言。作为一个基于文本的开放网络标准,SVG能够优雅而简洁地渲染不同大小的图形,并和CSS,DOM,JavaScript等其他网络标准无缝衔接操作非常方便。其中D3.js开创了使用SVG绘制知识图谱网络图的先河,为开源社区提供了早期知识图谱可视化的技术库资源。在小数据量的情况下,SVG的方案通常内存占用会更小,做缩放、平移等操作的时候往往帧率也更高。从交互优势上,看由于SVG是基于HTML的DOM,能快速应用浏览器底层的鼠标事件、CSS样式、CSS3动画等,在交互、局部重绘制上有很多便利。
2、Canvas是HTML5提供的一种新的标签,它定义了一个矩形区域的画布,通过Javascript可以再画布上绘制各种图形,拥有多种绘制路径、矩形、圆形、字符以及添加图像的方法,为区别WebGL这里的Canvas主要是指Canvas2D。Canvas比SVG在渲染绘制性能上有优势,特别是在绘制对象数量比较多的情况,但另一个方面是在大尺寸画布的绘制上性能有优势。
3、 WebGL(Web图形库)是一个JavaScript API,可在任何兼容的Web浏览器中渲染高性能的交互式3D和2D图形,而无需使用插件。WebGL通过引入一个与OpenGL ES 2.0非常一致的API来做到这一点,该API可以在HTML5的Canvas元素中使用。
4、WebGL2是WebGL的一个主要更新。它基于OpenGL ES 3.0,新一些功能特性,在性能上也有较大提升,但受限于OpenGL引擎技术相对WebGPU落后。WebGPU是基于Vulkan、Metal和Direct3D 12设计上更好的反映了GPU硬件技术这些年新的发展,能提供更好的性能,支持多线程,采用了偏面向对象的编程风格,WebGPU目前能支持的设备还比较少,相关的生态还在发展阶段,但这个是未来的趋势。
6.4.2 知识图谱可视化工具
在上面描述的一些可视化基本技术等在知识图谱的可视化逐步演进的过程中有一些较为经典的开源项目如下:
-
1、D3.js项目
D3是一款可视化Javascript库,提供了可视化的的基础能力:如图形、色彩、比例尺、布局算法、定时器、缩放、动画已经操作交互等。D3.js 是一个比较基础的库,只对一些基本算法进行了封装,使用非常灵活,可以实现丰富的定制化效果;
-
2、Sigma.js项目
Sigma.js相较D3.js是专门为图谱渲染编写的Javascript库,期主要特点是对图谱渲染做了一些优化努力,包括使用Canvas技术来渲染图谱,所以能处理上千节点的图谱渲染。
-
3、Cytoscape.js项目
Cytoscape.js主要专注在图论算法上,Cytoscape.js图布局上上做了很多研究,在提供了大量的实践示例对不同布局的同时Cytoscape.js也提供了手势等交互控制。
-
4、vis.js项目
是一个动态的、基于浏览器的可视化库,可处理大量的动态数据并能与这些数据进行交互操作。该项目包含 DataSet、Timeline, 和 Graph(2d和3d),基本图表如折线图、柱状图等的使用不如同为基于Canvas的echarts图表种类多而全,echarts也相对更美观易用,但是vis.js有多种的3D图表,如果需要展示3D效果可以使用vis.js。vis.js是基于Canvas的,其中有一些做好的示例效果非常不错,在应用场景上可根据需求选择相对合适的一个。vis.js的时间轴很不错,需要时间轴的组件或者展示,可以用vis.js来做。
-
5、Echarts项目
ECharts是一个基于 JavaScript 的开源可视化图表库,做简单展示比较方便易于实现,但扩展性较差。
6.5 知识图谱可视化场景需求分析
·图查询应用:以图数据库为主的图谱可视化工具,提供图数据的编辑、子图探索、顶点/边信息查询等交互操作。
·图分析应用:对业务场景中的关系类数据进行可视化展示,帮助业务人员快速了解链路故障、组件依赖等问题。
6.6 知识图谱可视化要点设计
6.6.1 布局策略
在不同类型的知识图谱中,因数据差异较大,对布局效果的要求也有所不同。能让业务数据有合适的布局来做可视化呈现,是一项比较大的技术挑战。下面展示几种基本的布局:
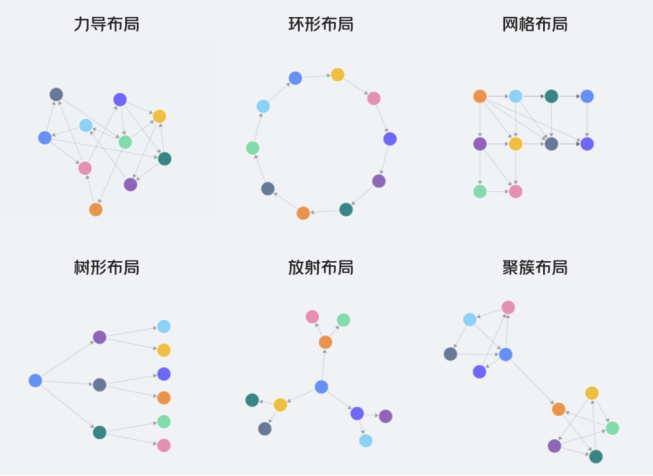
在很多业务场景中,用户更倾向于采用分层的方式来观察图谱数据,因为这样有利于理解和分析图谱数据,比如:根据用户探索路径分层、边关系聚合分层、业务属性归类分层、指定中心点路径分层等等,这些需求对图谱的样式和布局形式提出了更高的要求。
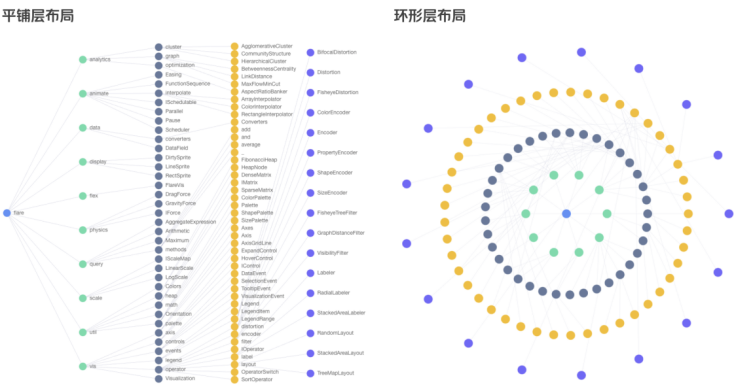
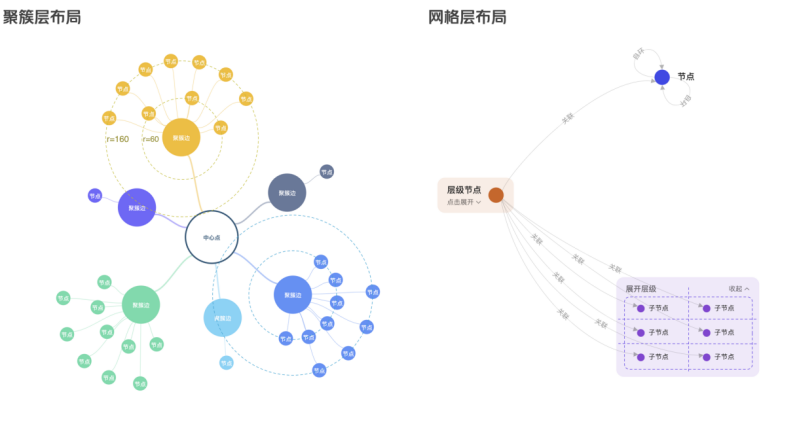
6.6.2 视觉降噪
在用户使用可视化应用时,文字/节点/边等元素内容混杂在一起,如果没有做好信息的表达和呈现,会直接影响到用户的使用体验和使用效率。经过分析,我们发现这是因为在可视化过程中产生的视觉噪声太多,而通过可视化带来的有效信息太少。下面将举例展示什么叫做视觉噪声:

在以上几张图中,虽然将知识图谱的数据呈现了出来,但是元素数量非常多,信息杂乱,给用户的观感是"眼花缭乱"。针对这类问题有几种特定的解决方案:
(1)文字处理
文字主要用在节点和边的描述上,虽然能提供非常重要的信息,但是节点过多文字会相互重叠,而重叠后的文字很难快速识别出来,造成很差的视觉体验。需要对文字进行遮挡检测,根据文字的层叠关系,将置于底部的文字透明度调低,这样即使多层文字重叠后,置于顶层的文字依然能被快速识别。
(2)边处理
知识图谱中存在包含大量出(入)边的中心节点,在对这些中心节点的边进行可视化展示时,往往会出现边与中心节点联结处(Nexus)重叠交错在一起的情况,进而影响视觉体验。通过多边散列排布,改变边线类型,并调整样式参数,将图谱中凌乱无序的边线进行优化。
6.6.3 交互功能
合适的图谱布局能更好地表达出数据的含义,通过视觉降噪可以进一步让图谱传递出更多的有效信息。但是用户依然需要通过交互找到自己关心的信息,一个图谱可视化工具是否好用,交互功能会起到非常重要的作用。下面介绍几种的基本交互功能:
- 画布操作:拖动、缩放、动态延展、布局变换、多节点圈选。
- 元素(节点和边)操作:样式配置、悬浮高亮、元素锁定、单击、双击、右键菜单、折叠/展开、节点拖动、边类型更改。
- 数据操作:节点的增删改查、边的增删改查、子图探索、数据合并、更新重载。
下面详细叙述其中的几个功能:
(一)路径锁定
通过选取不同的节点,自动计算出节点之间的合适路径,做锁定展现,方便观察两个或多个节点是如何关联起来的。
(二)聚焦展现
对于当前不关注的图谱区域,默认布局可以密集一些来节省画布空间,关注某个区域后,会对当前关注的一小块区域重新布局,让节点排布分散一些,方便查看文字的内容。无论可视化的节点与边的数量有多庞大,当深入到业务细节中的时候,使用者关注的节点数量其实不多,重点是把使用者关心的数据从大量数据中筛选出来,并且做好清晰地呈现表达。
七、 知识图谱推理应用技术
7.1 知识推理概述
推理可以用于属性补全、关系预测、错误检测、问句扩展和语义理解等。
推理指的是从已知事实来推断得出新的事实的过程。有很多钟实现推理的方法,较为常见的有演绎、归纳、溯因、类比。
与知识图谱有关系的推理任务:
1、基于描述逻辑的推理
描述逻辑关注的是描述客观世界的逻辑,也就是本体。
2、自然语言推理
既然人可以利用自然语言实现推理,也希望及机器能模仿人的语言实现自动推理。
3、视觉推理
给定一张图片,视觉推理不仅要求识别其中的物体,还需要分析他们之间的位置关系、实现路径搜索、比较属性大小和计数等。
4、表示与推理
计算机领域的推理实现,其本质都是找到一种合适的表示方法,一方面这种表示能方便而且准确地刻画客观世界中的事物以及运行规律,另一方面这种表示又非常适合于机器处理和计算。
知识推理的作用
1、知识丰富:虽然知识图谱中包含大量的结构化知识,但是这些知识往往是不完备的,使用推理方法预测表示实体和实体之间关系的新的三元组称为链接预测任务。
2、知识清洗:知识图谱的构建过程远非完美,因此知识图谱中可能包含许多不正确的事实。
专家系统是人工智能领域中发展最为迅速、应用最为广泛的一个技术方向。专家系统主要处理的是行业专家或书本上的知识,正像在数据处理中数据是处理对象一样,所以专家系统又称知识处理学。其内容主要包括知识的获取、知识的表示及知识的运用和处理三大方面。绝大部分专家系统都是介绍如何在各行业内对特有需求进行分析与决策。所有这些领域内的需求都具有相同的抽象描述即一般需求的分析与决策。
符号推理与向量推理的比较
符号表示是一种显式的知识表示,一般需要人工来定义;向量表示主要是依靠大量训练语料,通过机器学习模型学习出来的表示。
符号表示的推理过程主要依靠符号匹配,更适合于需要精确推理的场景;
向量推理是通过向量或矩阵计算来完成,由于最终得到的是一个三元组事实的真实性得分,因此推理的结果也具有不确定性。
符号推理一般都是需要人工定义推理逻辑的,比如本体逻辑推理都需要人工定义公理;向量推理本身是利用向量计算完成的近似推理,不需要人工定义显式的规则逻辑。
符号推理过程本身是严格而且人可理解的,因此没有可解释的问题;向量推理虽然简单高效,但丢失了推理的过程,因此也就丢失了推理的可解释性。
7.2基于符号逻辑的知识推理
基于本体的推理
基于Datalog的知识图谱推理
基于产生式规则的推理
7.3 基于表示学习的知识推理
基于符号逻辑的演绎推理的主要缺点是对知识表示的逻辑机构要求比较高,不论是本体推理还是规则推理,都要求人工定义公理和规则才能完成推理,过于依赖人工限制了知识库的规模和应用能触达的范围。随着深度学习的深入发展,基于表示学习和知识图谱嵌入的推理方法得到了更多的重视。同时,既然知识图谱有图结构特点,图神经网络方法也非常自然地被应用到知识图谱的推理和挖掘分析中。
7.3.1 知识图谱表示
用某种语言对知识图谱进行建模,从而方便知识运算。
-
符号知识表示 :以符号逻辑为基础的知识表示方法。
特点:易于刻画显示、离散的知识。具有内生的可解释性。
不足:部分隐性知识不易符号化表示,故知识表示不完备失去鲁棒性推理难达应用。
-
向量知识表示 :基于向量方式表示知识。
特点:可以通过数值运算发现新事实和和新关系,有效发现更多隐性知识和潜在假设;通常作为一种类型的先验知识辅助输入很多深度神经网络模型中用来约束和监督神经网络训练过程。
流行的以三元组为基础的知识表示方法弱化了对强逻辑的要求;另外基于向量的知识图谱表示使得数据更易于在搜索、问答等应用的深度学习模型集成应用,因此基于向量的知识图谱表示越来越受重视。下面着重介绍知识图谱的向量表示方法。
7.3.2 知识图谱的向量表示
1、产生背景
基于离散符号的方法表示知识,不能在计算机中表达相应语义层面的信息,也不能语义计算;对于数据量较大的图谱,需要改进传统的表示方法。
在自然语言处理领域中,因为离散符号化的词语不能蕴含语义信息,所以将词映射到向量空间,这不仅有利于进行计算,在映射过程中也能使相关的向量蕴含一定的语义。知识图谱中的向量表示方法也在这里有所借鉴。
2、知识图谱的向量表示定义
知识图谱的向量表示:将知识图谱中包括实体和关系的内容映射到连续向量空间方法的研究领域。(也叫做知识图谱嵌入、知识图谱的表示学习、知识表示学习)
知识图谱嵌入方法的训练需要基于监督学习。在训练过程中可以学习到语义层信息。
3、知识图谱嵌入的优点:
- 提高应用时的计算效率
- 增加了下游应用设计的多样性
- 作为下游应用的与训练向量输入时包含一定信息
4、知识图谱嵌入的主要方法
知识图谱嵌入方法的分类:
- 基于转移距离,(TransE等模型)
- 基于语义匹配,(RESCAL等模型)
- 基于神经网络,(ConvE等模型)
- 基于图神经网络,(GNN模型)
- 考虑附加信息的模型,(PTransE等)
5、知识图谱嵌入与知识图谱推理
知识图谱推理:基于图谱中已有的事实或关系推断出位置的事实或关系;主要能够辅助推理出新的事实、新的关系、新的公理以及新的规则等。
知识图谱推理的任务 主要有:知识图谱补全、不一致性监测、查询扩展、知识图谱融合过程中的推理任务(实体对齐、关系对齐)、链接预测等。
基于归纳的知识图谱推理:主要通过对知识图谱已有信息的分析和挖掘进行推理的,最常用的信息为已有的三元组。按照推理要素不同可分为以下几类:
- 基于知识图谱嵌入的推理
- 基于图结构的推理
- 基于规则学习的推理
6、知识图谱嵌入的应用
在知识图谱嵌入的发展中,有很多相关应用一起发展起来,它们和知识图谱嵌入之间有着相辅相成的关系。
- 链接预测
- 三元组分类
- 实体对齐
- 问答系统
- 推荐系统
7.3.3 利用机器学习实现知识图谱归纳推理
1、本体嵌入
虽然基于图遍历的方法可解释性强可以直观地推理,但是在大规模知识图谱上会遇到性能瓶颈。基于表示学习的方法在大规模图谱中比较有优势,但可解释性不强,且在稀疏实体上由于无法充分学习到好的表示,效果较差。
2、基于规则学习的知识图谱推理
知识图谱嵌入主要考量的是三元组级别的知识,但知识图谱中的知识不止三元组。其中规律也是重要的知识结构。
可以换一个视角来看待知识图谱上实现推理的问题。本质上,知识图谱的关系推理的问题都可以转化为基于规则的推理。例如,可以利用一条规则,在已知(A hasWife C)和(C hasChild M)两条事实的前提下,推理得出(A isFatherOf B),但这需要人工定义很多规则。
(1)PRA
第一种思路是利用知识图谱的图结构特点来学习这类规则。例如比较经典的PRA的基本思想是将两个实体的路径作为特征来预测其间存在某种关系。
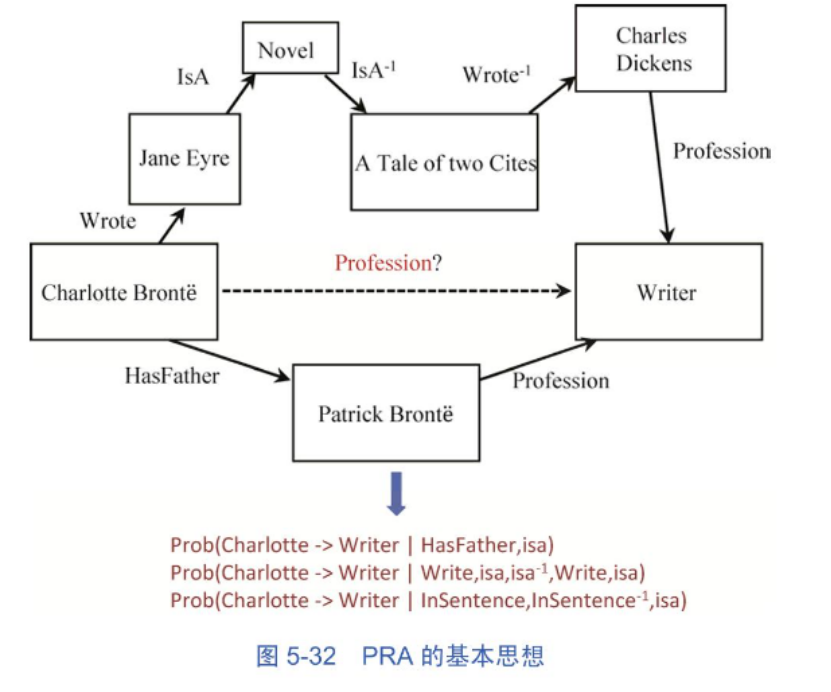
从实体Charlitte出发有一条路径是(Charlotte Bronte, hasFather Patrick),(Patrick, profession, Writer),可以近似地认为,如果Charlotte的父亲是作家,那么她自己也是作家的可能性就会大一些。
根据一个带有边类型的有向图,判断某结点对(s, t)之间是否存在给定关系,
需要计算这两个结点之间的一个分数(Score),如果分数高于某个阈值则认为这两个结点间具有关系Profession。在计算分数时,对于结点对(s, t)可以找出从s到t的所有连通路径p,对于每条路径计算出一个概率,然后加权求和,即可得到分数。权重是通过有监督学习方法线下计算出来的。对于一个关系r和有向图G其训练样例中需要给出一些节点对,标注出每个结点是否具有关系r,然后通过使用逻辑回归模型为每条路径类型计算出权重。这个模型将路径类型看作特征,通过模型训练为每一种路径类型学习一个权重。这是因为每条路径对于结果预测重要性程度不一样。另外还有一个问题是图中的每一条路径都可以作为关系推断的一条线索,可以穷举出从头节点出发到尾节点的所有路径,但是这个数量是随着路径长度呈指数级增长的。PRA采用随机游走的方法,从头尾两个结点出发,随机地采用部分路径以降低路径搜索的计算量。
PRA最终学习得出的是一组从头节点到尾节点的路径。这些路径被用来推断头尾结点之间未知的关系。
可以用规则学习的视角来看待PRA的学习结果。
规则表示方法:
规则通常由体部(Body)和头部(Head)两部分组成。其中的每一个原子对应一个谓词,谓词可以是一元谓词,如声明x是学生,也可以是二元谓词,如声明x、y是读者关系。PRA所学习出来的路径也可以描述为一条规则。
这种规则也称为路径规则或称为封闭式规则。这种规则的体部原子中的变量从头节点x开始,如r1(x, z1)沿着图谱中的路径r2(z1, z2),一直到rn(zn−1, y)其中y对应尾节点。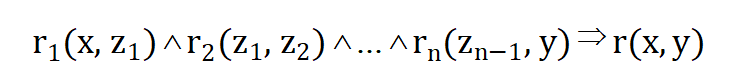
如果规则中的所有变量替换为具体的实体并保证每个实例化后的原子都存在于图谱中,这样规则的实例化后的结果称为规则的一个Grounding。因此,也可以用规则学习的方法来实现类似于PRA的推理。这类算法中比较传统的方法是AMIE。
(2)AMIE
关联规则挖掘(Association Rule Mining under Incomplete Evidence, AMIE)是一种基于规则学习的归纳推理方法。支持从不完备知识库中,挖掘闭式规则。
AMIE依次学习预测每种关系的规则。对于每种关系,从规则体为空的规则开始,通过三种操作扩展规则体部分,保留支持度大于阈值的候选(闭式)规则。
添加悬挂边:悬挂边是指边的一端是一个未出现过的变量,而另一端(变量或常量)是在规则中出现过的
添加实例边:实例边与悬挂边类似,边的一端也是在规则中出现过的变量或常量,但另一端是未出现过的常量,也就是知识库中的实体
添加闭合边 :闭合边则是连接两个已经存在于规则中的元素(变量或常量)的边。
规则学习的几个统计指标。
支持度(Support)指的是给定规则,用知识图谱中的实体对规则进行Grounding的总个数,即知识图谱中多少实例满足这条规则的定义。同时符合规则体和规则头的实例数目.
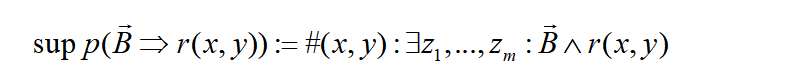
头覆盖度(Head Coverage)是用规则的Grounding数除以规则的头部关系r的所有三元组数,指的是满足规则定义的实例覆盖了多少头部关系的三元组。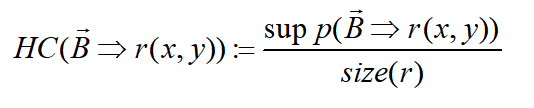
置信度(confidence)是用规则的Grounding数除以满足体部定义的实例数。满足体部定义的实例未必都会推导得出头部原子,因此,这个指标衡量了某个规则的可信程度。支持度除以仅符合规则体的实例数目。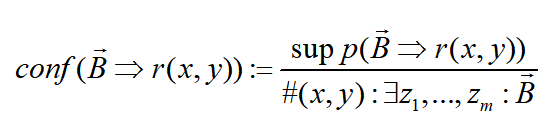
PCA置信度:传统的置信度定义基于封闭世界假设,即图谱中不存在的三元组都被视为错误的。知识图谱通常要求采用开放世界假设,即知识图谱中不存在的事实不一定是错误的。PCA置信度只将满足规则体部并且存在三元组的激励才计入分母,在一定程度上考虑了知识图谱本身的不完备性。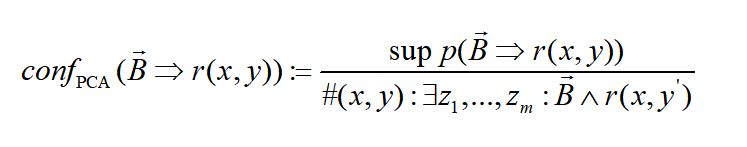
7.4 知识图谱实体处理相关任务
- 实体对齐(Entity Alignment):目标是在两个不同知识图谱之间,将相同的实体对应起来。
- 实体解析(Entity Resolution):有时候也叫共指消解(Coherence Resolution),句子中经常会有"他/她/它/这/那"等代词,实体解析负责验证句子中的两个mention是否指向同一个entity,通常是对重复节点的数据删除。
- 实体消歧(Entity Disambiguation):目标是找到句子里mention对应到知识库(KB,Knowledge Base. 如Wikipedia)或知识图谱(KB, Knowledge Graph)中的entity。实体消岐可以当做是实体链接任务的一部分,重点在于区分候选实体间的不同,并选出最佳匹配(Gold Entity),因此候选实体经常使用别名表(Alias Table),可以参考【github】中的思维导图和PPT。很多论文做的实际是Entity Disambiguation,但也把自己的标题起做Entity Linking。
- 实体链接(Entity Linking):在实体消岐基础上加一步实体检索(Entity Retrieval)来生成候选实体,便于应对人工Alias Table覆盖不全的问题。此外完整的步骤应该还包括对无对应entity的mention(NIL)进行处理。
- 知识融合(KG Alignment):知识融合,即合并两个知识图谱(本体),基本的问题都是研究怎样将来自多个来源的关于同一个实体或概念的描述信息融合起来。将多个知识库中的知识进行整合,形成一个知识库的过程,在这个过程中,主要关键技术包含指代消解、实体消歧、实体对齐。
八、 基于知识的对话系统
8.1 人机对话
对话领域是当前最热门的一个NLP的方向之一,无论在学术界还是在工业界。由此衍生出来的产品包括通用形态的苹果siri,微软小冰,小米的小爱同学等,以及各个行业领域的智能助手,智能客服等。 这些产品基本可以看成下一代人机自然语言交互的雏形。
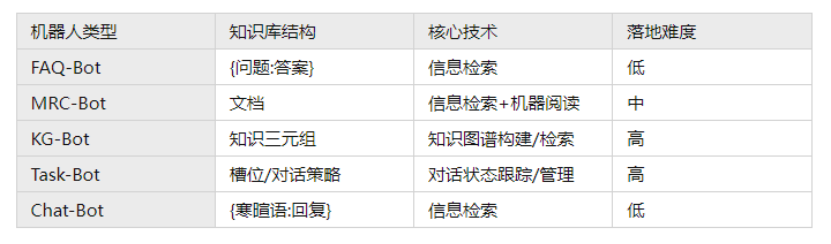
具体而言人机对话又可以拆分为以下几种形式:
(1) FAQ-Bot: 基于常见问答对的问答,也是运用最为广泛的智能问答技术,可以认为是最朴素的一种对话。抽象出来是一个信息检索的问题,给定用户的问题,在由{问答:答案}组成的知识库中检索相似的问题,最后将与用户相似问法问题的答案作为结果返回给用户。
(2) MRC-Bot: 基于机器阅读的智能问答,一般运用在开放域的问答中。给定用户的问题,具体分成召回和机器阅读两个阶段,先从知识库中检索出可能存在答案的文档,再针对文档做机器阅读确定答案。在实际落地中也很有前景,相比FAQ-Bot用户不需要耗费很大力气构建知识库,只需要上传产品文档即可。但是目前机器阅读的准确性还不够,效果不稳定,还不能直接将机器阅读的结果作为答案返回给用户。
(3)KG-Bot: 基于知识图谱的问答,一般用于解答属性型的问题,比如"北京的市长是谁"。给定用户的问题,需要先解析成知识图谱查询语句,再到知识图谱中检索答案。这种问答一般回答的准确率非常高,但是能回答的问题也非常局限,同时构建知识图谱非常耗费人力。
(4)Task-Bot: 任务型对话,是面向特定场景的多轮对话,比如"查天气","订机票"。"Task oriented dialogue"在学术和工业界都已经有了很深入的研究,分成pipeline和end-to-end两种思路。在实地落地过程中,难得是如何让用户自主的灵活配置一个任务型对话场景,训练语料可能只有一两条,如何训练出一个NER的槽位?
(5)Chat-Bot: 闲聊对话,一般用于提高机器人的趣味性,比如"你是谁?","你是机器人吗?"等。在学术上一般基于end-to-end的方案,可以支持多轮,但是回复结果不可控。所以在实际落地中还是会转换成FAQ-Bot,预先构建一个寒暄库,转换成检索的任务。
8.2 结合LLM模型的知识对话
8.3 KEQA
九、参考
0赵航. 知识图谱基础知识 2023.03
1陈华钧. 知识图谱导论M.电子工业出版社2021.02
2张伟,陈华钧,张亦弛. 工业级知识图谱------方法与实践M.电子工业出版社2021.08
3葛唯益,王振宇,王羽,陆辰,姜晓夏. 主流知识图谱存储系统实验对比J.指挥信息系统与技术,2019,10(5):28-33.
4知识图谱标准化白皮书(2019版)S.中国电子技术标准化研究院.2019
5张会平著.基于可视化技术的知识转化研究M.成都:电子科技大学出版社,2011
6Yucheng Wang, Bowen Yu1, Yueyang Zhang,Tingwen Liu, Hongsong Zhu, Limin Sun.2020.TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
7Zhepei Wei, Jianlin Su, Yue Wang, Yuan Tian, and Yi Chang. 2020. A novel cascade binary tagging framework for relational triple extraction. In Proceedings of ACL.
8Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao, Peng Zhou, and Bo Xu. 2017. Joint extraction of entities and relations based on a novel tagging scheme. In Proceedings of ACL.