本文基于一个 TypeScript Agent 框架的实际开发经验,介绍如何为 AI Agent 设计和实现一套多层次记忆系统。我们将从认知科学中的人类记忆模型出发,逐步映射到工程实现,最终构建出包含工作记忆、情景记忆和语义记忆的完整方案。
一、为什么 Agent 需要记忆
当前的大语言模型虽然强大,但设计上是无状态的。每一次 API 调用都是一次独立的计算,模型本身不会自动"记住"上一次对话的内容。
这带来一个很直观的问题:
erlang
用户:我叫张三,正在学习 Python
Agent:很好!Python 是一门很棒的语言...
用户:你还记得我叫什么吗?
Agent:抱歉,我不知道您的名字...这不是模型"笨",而是它根本没有存储上一轮对话的机制。要让 Agent 在连续对话中表现得像一个真正的助手,我们需要在框架层面为它补上记忆这个能力。
记忆系统要解决两个核心问题:
- 对话遗忘------Agent 无法记住之前的交互内容,导致上下文丢失、个性化缺失
- 知识局限------模型的知识来自训练数据,有时间截止点,无法获取最新或专业领域的信息
二、从人类记忆到系统设计
在动手写代码之前,我们先从认知科学中找灵感。
人类记忆的分层结构
认知心理学研究表明,人类记忆是一个多层级系统:
- 工作记忆 :容量有限(7±2 个项目),持续 15-30 秒,负责当前任务的信息处理。比如你正在心算
23 × 17时,临时记住的中间结果。 - 长期记忆 :容量几乎无限,可持续终生,又分为两类:
- 情景记忆:具体的个人经历和事件,比如"昨天的会议讨论了什么"
- 语义记忆:抽象的知识和概念,比如"巴黎是法国首都"
映射到 Agent 记忆
我们把这个分层结构直接映射到 Agent 的记忆系统:
| 人类记忆 | Agent 记忆 | 存什么 | 生命周期 |
|---|---|---|---|
| 工作记忆 | WorkingMemory | 当前会话的临时上下文 | 会话结束即清理 |
| 情景记忆 | EpisodicMemory | 具体的交互事件和经历 | 长期保存 |
| 语义记忆 | SemanticMemory | 抽象的知识、概念和规则 | 长期保存 |
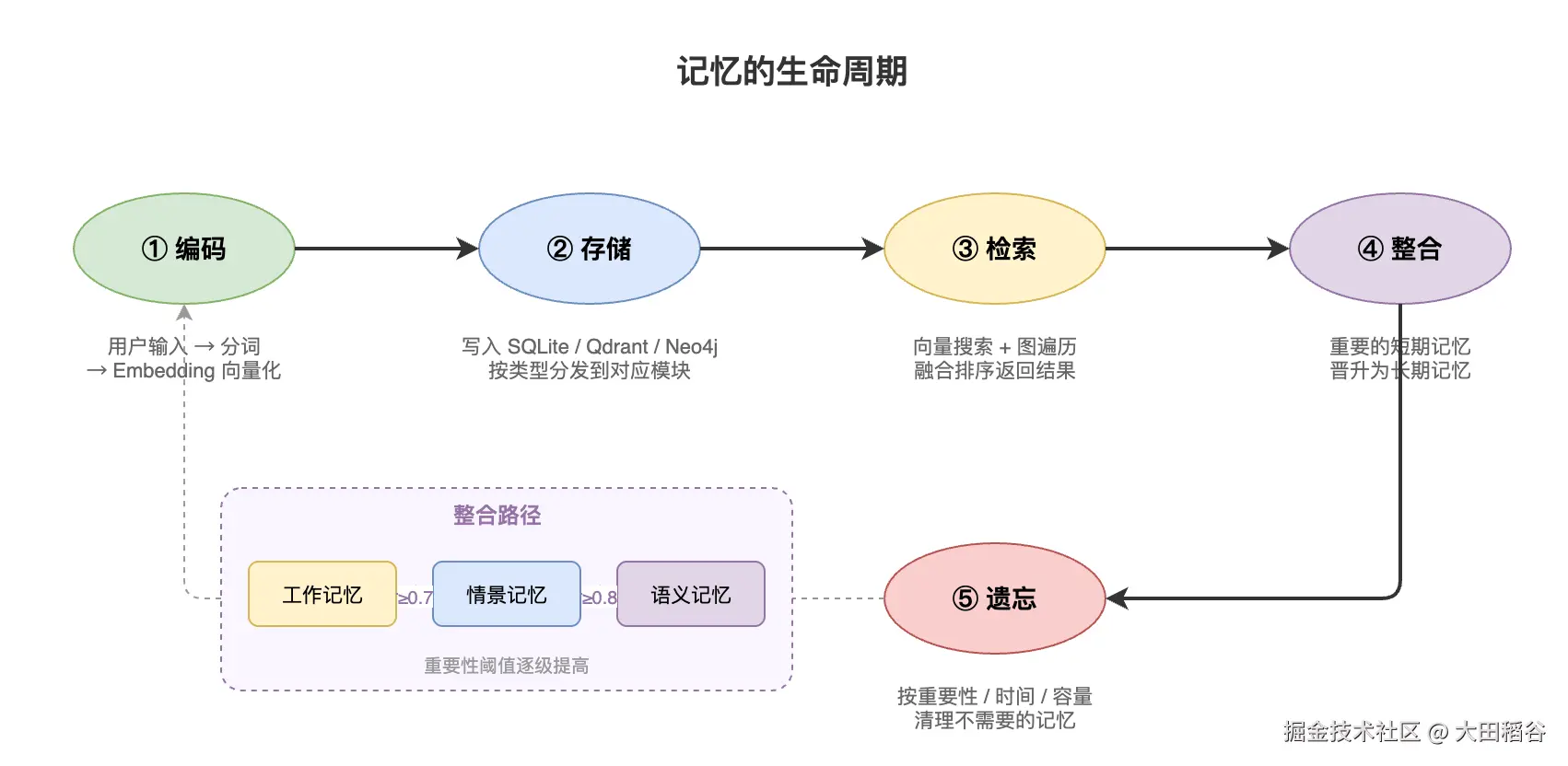
记忆的生命周期
和人类一样,Agent 的记忆也有完整的生命周期:
- 编码------将用户输入转换为可存储的形式(文本 → 向量)
- 存储------写入对应的记忆模块
- 检索------根据查询从记忆中提取相关信息
- 整合------将重要的短期记忆提升为长期记忆
- 遗忘------删除不重要或过时的信息,避免无限膨胀
三、整体架构设计
基于上述认知模型,我们设计了一个四层架构:
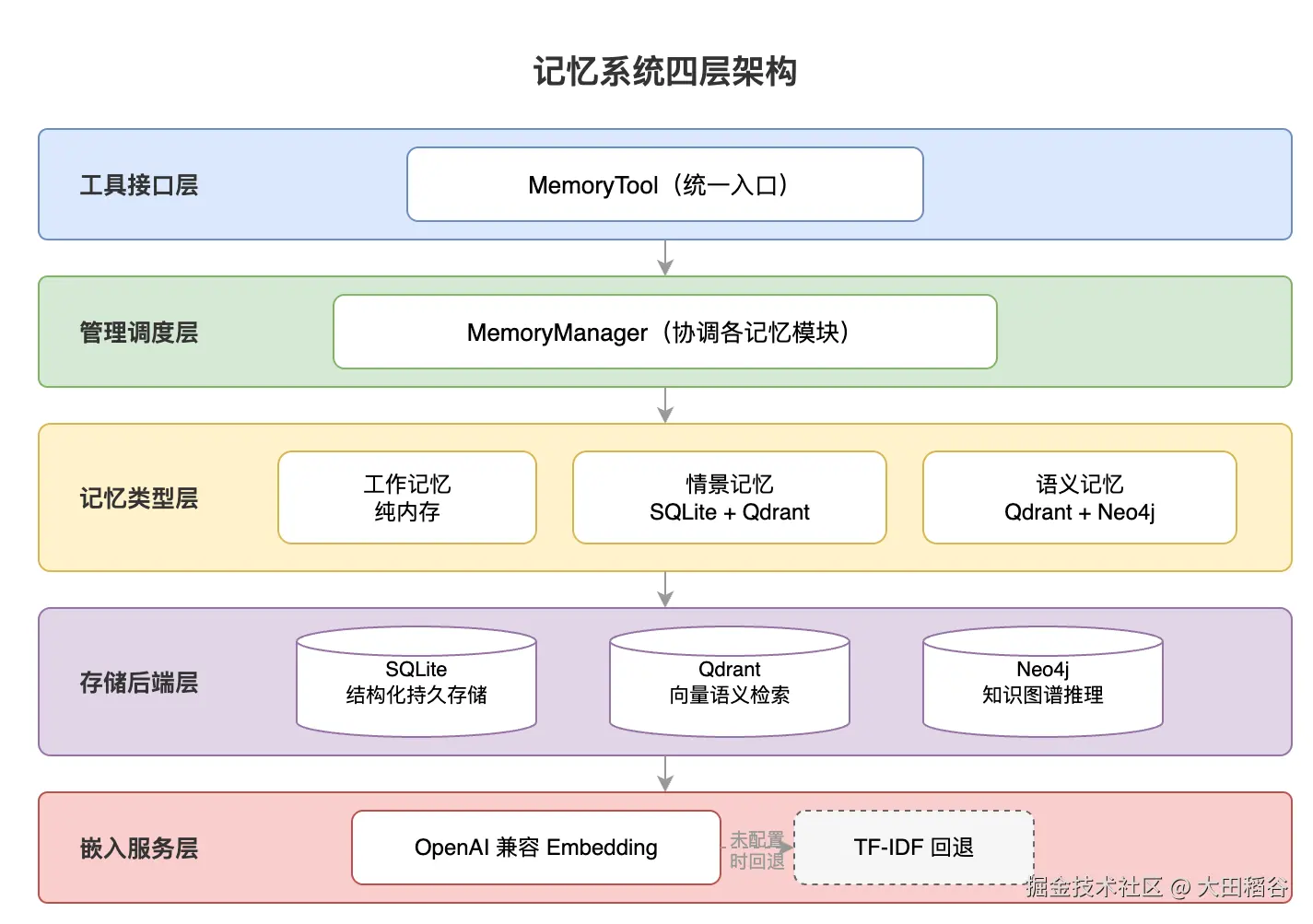
三个数据库的分工
一个自然的问题是:为什么需要三个数据库?因为它们各解决一个不同维度的问题。
SQLite 是"档案柜"。存储每条记忆的完整内容和元数据(id、内容、重要性、时间戳、会话信息等)。它擅长结构化查询------"列出最近 7 天重要性大于 0.8 的所有记忆"这类需求,SQLite 一条 SQL 就能搞定。
 Qdrant 是"语义索引"。存储记忆内容的向量表示,通过余弦相似度实现语义检索。当用户搜"编程语言"时,即使记忆里写的是"Python 是一种解释型语言",Qdrant 也能通过向量相似度匹配到它。这是纯文本匹配做不到的。
Qdrant 是"语义索引"。存储记忆内容的向量表示,通过余弦相似度实现语义检索。当用户搜"编程语言"时,即使记忆里写的是"Python 是一种解释型语言",Qdrant 也能通过向量相似度匹配到它。这是纯文本匹配做不到的。
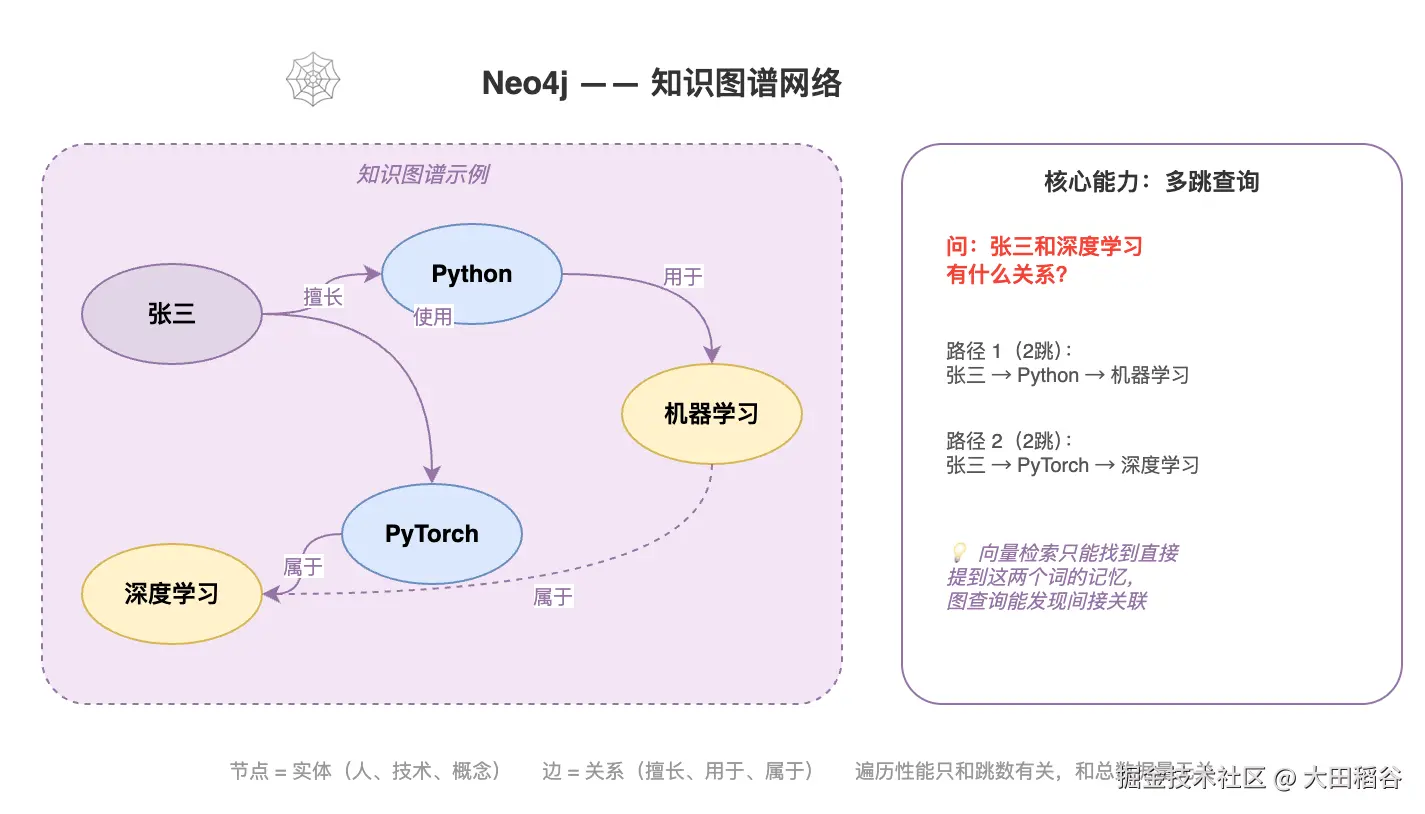
 Neo4j 是"知识网络"。存储从记忆中提取的实体和关系,形成知识图谱。它的独特价值在于发现间接关联 ------假设记忆 A 说"张三擅长 Python",记忆 B 说"Python 常用于机器学习",Neo4j 能沿着
Neo4j 是"知识网络"。存储从记忆中提取的实体和关系,形成知识图谱。它的独特价值在于发现间接关联 ------假设记忆 A 说"张三擅长 Python",记忆 B 说"Python 常用于机器学习",Neo4j 能沿着 张三 → Python → 机器学习 的路径,发现张三和机器学习之间的隐含关系。
 三者的协作关系:
三者的协作关系:
scss
存储时:文本 → SQLite(完整存档) + Embedding→Qdrant(向量索引) + 实体提取→Neo4j(知识图谱)
检索时:查询 → Qdrant(语义匹配) ∥ Neo4j(关系推理) → 融合排序 → SQLite(读完整内容) → 返回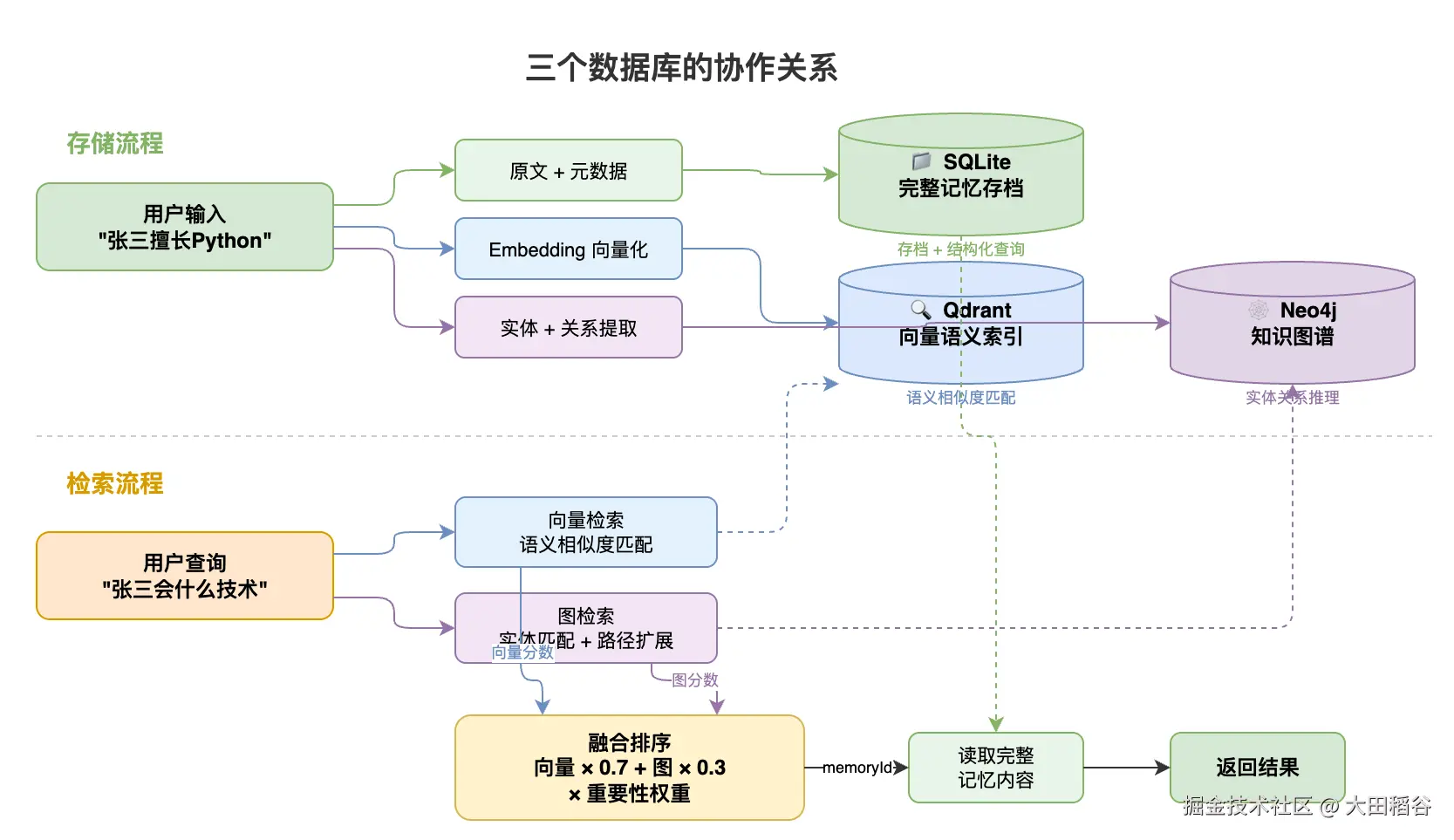
降级设计
并非所有用户都会部署 Qdrant 和 Neo4j。我们的设计原则是:外部数据库是增强,不是必需。
- Qdrant 未配置 → 回退到本地 TF-IDF 向量化 + 余弦相似度
- Neo4j 未配置 → 回退到关键词匹配
- SQLite 始终可用(零配置,文件数据库)
这样保证框架在任何环境下都能运行,只是检索质量有差异。
记忆封装为工具
一个重要的设计决策:记忆能力被封装为标准的 Tool,而不是创建新的 Agent 子类。这意味着任何 Agent(SimpleAgent、ReActAgent)都可以通过注册 MemoryTool 获得记忆能力,不需要修改 Agent 本身的代码。
四、三种记忆类型的实现
4.1 工作记忆------当前会话的临时便签
工作记忆是最轻量的一层,模拟人类在处理当前任务时的短期记忆。
核心特点:
- 纯内存存储,不依赖任何外部数据库
- 容量限制(默认 50 条),超出时移除最不重要的
- TTL 自动过期(默认 60 分钟),会话结束后自动清理
检索策略:采用 TF-IDF 向量化 + 关键词匹配的混合方式。TF-IDF 负责语义层面的相似度计算,关键词匹配作为补充确保精确命中。
评分公式:
scss
最终得分 = (TF-IDF相似度 × 0.7 + 关键词匹配 × 0.3) × 时间衰减 × 重要性权重其中时间衰减使用指数衰减模型,24 小时内保持高分,之后逐渐降低。重要性权重的范围是 [0.8, 1.2],避免重要性过度影响排序。
容量管理的关键代码逻辑:
ts
add(item: MemoryItem): string {
this._expireOldMemories(); // 先清理过期的
if (this.memories.length >= this.config.workingMemoryCapacity) {
this._removeLowestPriority(); // 再淘汰最不重要的
}
this.memories.push(item);
this.vectorizer.addDocument(tokenize(item.content)); // 更新 TF-IDF 语料库
return item.id;
}工作记忆的设计哲学是"快进快出"------快速写入、快速检索、自动清理,不给系统增加持久化负担。
4.2 情景记忆------交互事件的时间线
情景记忆负责长期存储具体的交互事件,比如"用户在 3 月 15 日完成了第一个 Python 项目"。
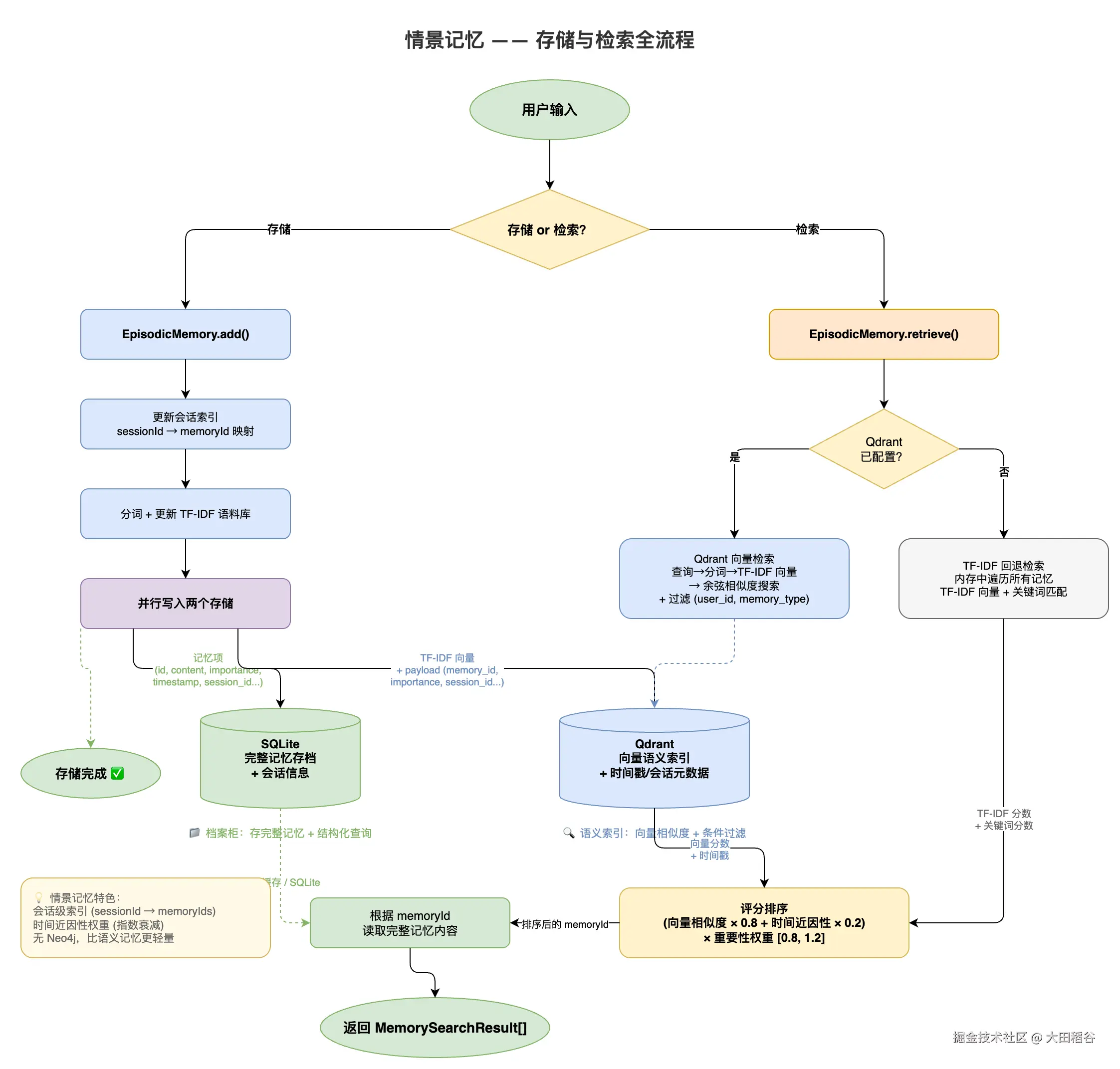 存储架构:SQLite + Qdrant 双写。SQLite 存完整记忆项,Qdrant 存向量索引。
存储架构:SQLite + Qdrant 双写。SQLite 存完整记忆项,Qdrant 存向量索引。
会话级索引 :情景记忆维护了一个 sessionId → memoryIds 的映射,可以快速回溯某次会话的所有交互。这对于"回顾上次对话"这类需求很有用。
向量生成 :这里涉及到 Embedding 的选择。我们的策略是优先使用外部 Embedding 模型(通过 OpenAI 兼容端点接入,在 .env 中配置 EMBED_API_KEY、EMBED_BASE_URL、EMBED_MODEL_NAME),未配置时回退到本地 TF-IDF。外部模型能理解语义(搜"代码开发"能匹配到"Python 编程"),TF-IDF 只能做字面匹配,但胜在零依赖。
存储流程:
ts
add(item: MemoryItem): string {
// 1. 更新会话索引
this.sessions.get(sessionId).push(item.id);
// 2. 持久化到 SQLite(同步,立即完成)
this.docStore.save(item, this.userId);
// 3. 更新内存缓存和 TF-IDF 语料库
this.memoryCache.set(item.id, item);
this.vectorizer.addDocument(tokenize(item.content));
// 4. 异步写入 Qdrant(不阻塞主流程)
this._embedAndStore(item, sessionId).catch(console.warn);
return item.id;
}注意第 4 步是异步的------向量生成和 Qdrant 写入不阻塞 add() 的返回。这是因为 Embedding API 调用有网络延迟,而 SQLite 已经保证了数据不丢失。
检索流程的评分公式:
scss
最终得分 = (向量相似度 × 0.8 + 时间近因性 × 0.2) × 重要性权重为什么时间近因性占 0.2?因为情景记忆的本质是"事件",最近发生的事件通常更相关。但权重不能太高,否则会压过语义相关性------用户问"我之前学过什么"时,语义匹配比时间顺序更重要。
4.3 语义记忆------知识的关系网络
语义记忆是最复杂的一层,存储抽象的概念、规则和知识,并支持关联推理。
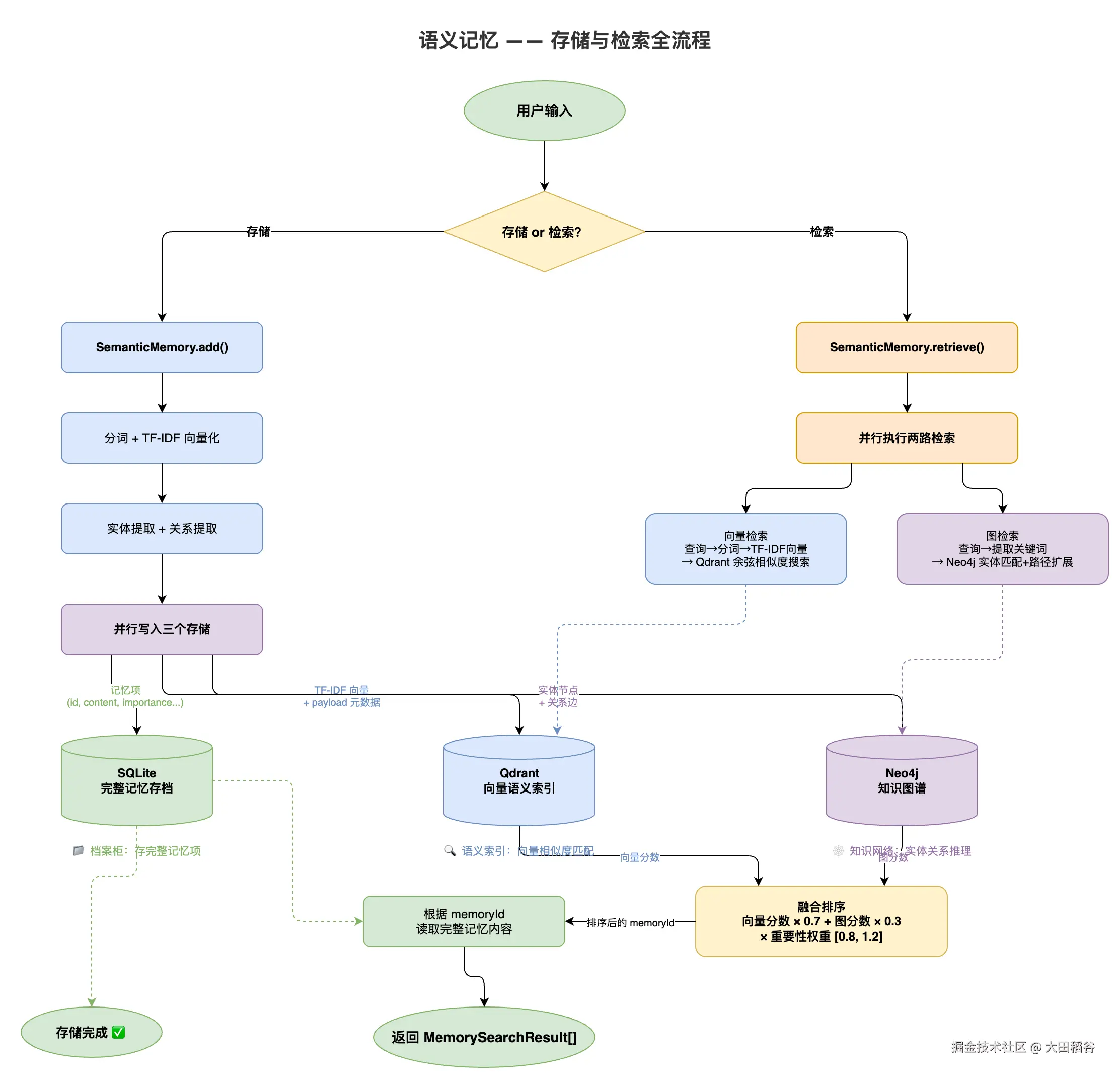 存储架构:Qdrant + Neo4j 双路。Qdrant 负责向量语义检索,Neo4j 负责知识图谱推理。
存储架构:Qdrant + Neo4j 双路。Qdrant 负责向量语义检索,Neo4j 负责知识图谱推理。
实体和关系的自动提取:当一条语义记忆被添加时,系统会自动从文本中提取实体和关系。当前采用基于规则的轻量实现------英文匹配首字母大写的词(如 "Python"、"React"),中文匹配"是一种/属于/使用"等句式中的关键词。同一句话中出现的实体之间建立共现关系。
举个例子,添加记忆"张三擅长 Python,Python 常用于机器学习"后,Neo4j 中会形成:
scss
(张三) --RELATED_TO--> (Python) --RELATED_TO--> (机器学习)图检索的独特价值 :当用户问"张三和深度学习有什么关系"时,向量检索可能只找到直接提到这两个词的记忆。但如果后来又添加了"PyTorch 是深度学习框架"和"张三在用 PyTorch",Neo4j 能沿路径 张三 → PyTorch → 深度学习 发现这个间接关联。这是纯向量检索做不到的。
并行双路检索:
ts
async retrieve(query: string, limit = 5): Promise<MemorySearchResult[]> {
// 向量检索和图检索并行执行
const [vectorResults, graphResults] = await Promise.all([
this._vectorSearch(query, limit * 2),
this._graphSearch(query, limit * 2),
]);
// 融合排序
return this._combineAndRank(vectorResults, graphResults, query, limit);
}融合排序的评分公式:
scss
最终得分 = (向量分数 × 0.7 + 图分数 × 0.3) × 重要性权重向量检索权重更高(0.7),因为语义相似度是主要的相关性信号。图检索作为补充(0.3),负责发现向量检索遗漏的间接关联。两路都命中的记忆会排在最前面。
五、记忆的生命周期管理
记忆不能只增不减,否则系统会无限膨胀,检索质量也会下降。MemoryManager 提供了遗忘和整合两个机制。
遗忘
支持三种策略,模拟人类大脑的选择性遗忘:
- 基于重要性:删除重要性低于阈值的记忆(比如清理所有重要性 < 0.2 的)
- 基于时间:删除超过指定天数的记忆(比如清理 30 天前的)
- 基于容量:当存储接近上限时,删除最不重要的记忆
工作记忆有自己的 TTL 机制自动清理,遗忘策略主要作用于情景记忆和语义记忆。
整合
整合模拟的是人类大脑将短期记忆固化为长期记忆的过程。比如,一条重要性超过 0.7 的工作记忆,可以被"晋升"为情景记忆,从而获得持久化存储:
ts
consolidateMemories(
fromType = MemoryType.Working,
toType = MemoryType.Episodic,
importanceThreshold = 0.7
): number {
const items = sourceMemory.getAll();
for (const item of items) {
if (item.importance >= importanceThreshold) {
targetMemory.add(newItem); // 添加到目标记忆
sourceMemory.remove(item.id); // 从源记忆移除
}
}
}整合链路是 工作记忆 → 情景记忆 → 语义记忆,重要性阈值逐级提高,确保只有真正重要的信息才会被长期保存。
MemoryTool 的统一接口
所有记忆操作通过一个 action 参数分发:
ts
memoryTool.run({ action: 'add', content: '...', memory_type: 'semantic', importance: 0.8 });
memoryTool.run({ action: 'search', query: '...', limit: 5 });
memoryTool.run({ action: 'forget', strategy: 'importance_based', threshold: 0.2 });
memoryTool.run({ action: 'consolidate', from_type: 'working', to_type: 'episodic' });这种设计让 Agent 通过 Function Calling 就能自主管理自己的记忆------决定什么值得记住、什么时候回忆、什么应该遗忘。
六、总结与展望
回顾整个实现,我们完成了从认知科学理论到工程代码的映射:
| 认知科学概念 | 工程实现 |
|---|---|
| 工作记忆的容量限制 | 内存数组 + 容量上限 + TTL |
| 情景记忆的时间序列 | SQLite 持久化 + 会话索引 + 时间衰减评分 |
| 语义记忆的关联网络 | Neo4j 知识图谱 + 实体关系提取 |
| 记忆编码 | Embedding 向量化 |
| 记忆检索 | 向量相似度 + 图遍历 + 融合排序 |
| 记忆固化 | 工作→情景→语义的整合机制 |
| 选择性遗忘 | 三种遗忘策略 |
当前实现还有一些可以改进的方向:
- 实体提取精度:当前基于规则的提取比较粗糙,可以替换为 NLP 模型(如 spaCy 或 LLM 辅助提取)
- 感知记忆:教程中提到的多模态记忆(图像、音频)尚未实现
- RAG 集成:记忆系统可以和 RAG(检索增强生成)结合,将外部知识库的检索结果自动存入语义记忆
- 多用户隔离:当前通过 userId 做基本隔离,生产环境需要更完善的数据隔离方案
记忆系统的核心价值在于让 Agent 从"无状态的问答机器"进化为"有记忆的智能助手"。当 Agent 能记住用户的偏好、学习历程和知识背景时,它提供的服务质量会有质的提升。