大家好,我是孟健。
这几天我最大的感受:多 Agent 协作真正难的,不是让它们动起来,是让任务别丢。
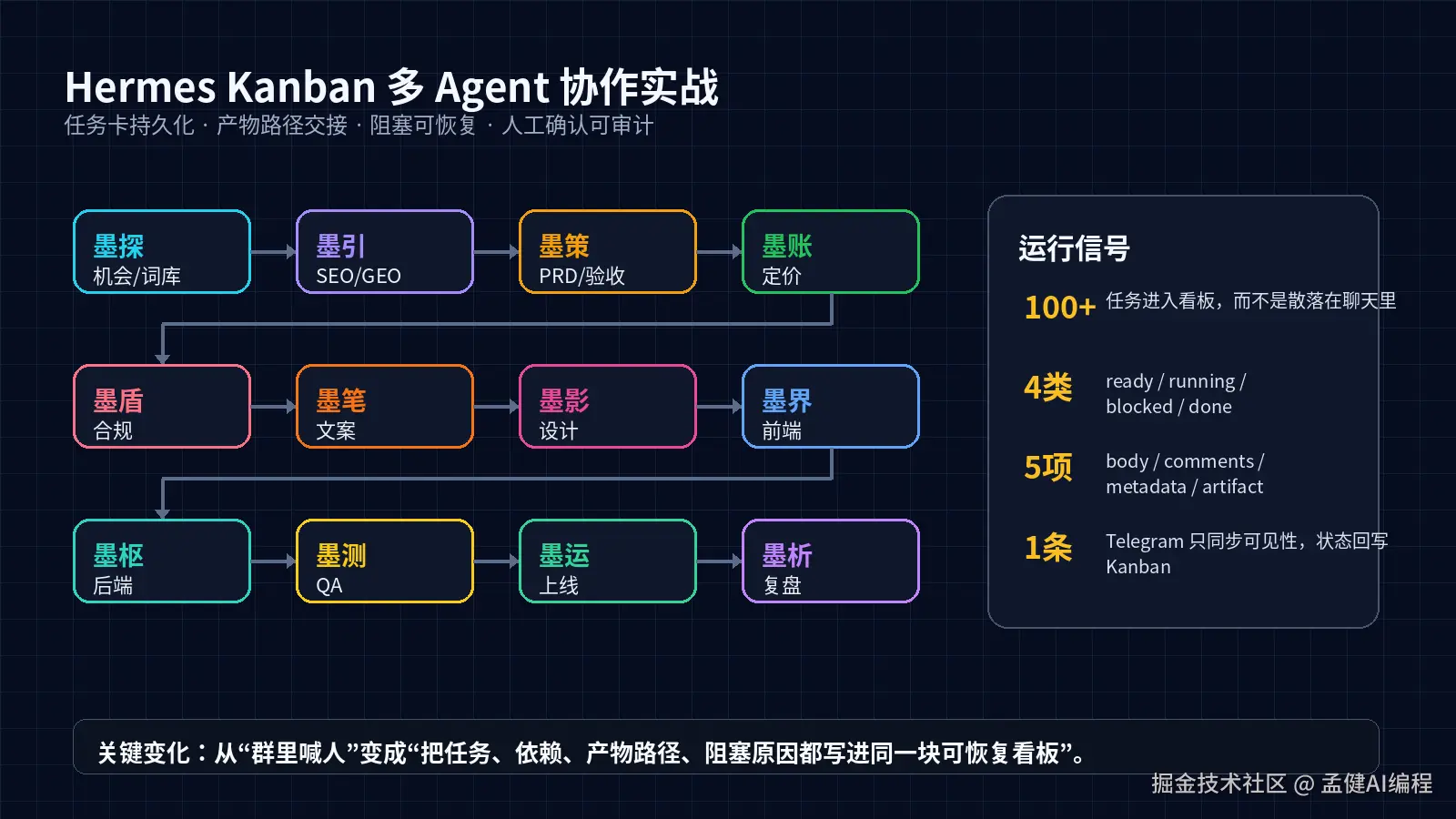
我最近在跑一条做站流水线。
从市场调研、关键词规划、PRD、定价、合规、文案、设计、前后端开发、QA,到上线冷启动,中间要经过一串 Agent 接力。
一开始我也用过最朴素的方式:在聊天窗口里派活,在群里 @ 人,让一个 Agent 做完后喊下一个 Agent。
很快就扛不住了。
聊天窗口适合沟通,不适合做任务系统。上下文一长,谁做了什么、产物在哪、哪里卡住、下一步谁接,经常要重新翻。
后来我把这条流程搬进 Hermes Kanban,才觉得多 Agent 协作终于像一套工程系统了。
Agent 可以忘。聊天可以断。任务卡不能丢。

01 delegate_task 解决不了长链路
delegate_task 很好用。
你把一个任务丢给子 Agent,父 Agent 等它执行完,再拿结果继续。它更像一次 RPC 调用。
短任务很适合:查资料、跑测试、写一个小模块、做一次独立 code review。
问题出在长链路任务。
比如做站。
设计 Agent 做完一版,产品 Agent 要验收。验收通过,前端 Agent 再实现。实现后,QA Agent 要回归。QA 发现问题,又要开修复任务。中间还可能插入人工确认、外部发布、凭据补充、合规判断。
这类任务不是一个"问答回合"。
它有状态,有依赖,有产物,有阻塞,有恢复。
如果还靠聊天接力,就会出现几个问题:
第一,父进程要等。任务时间一长,整个链路被挂住。
第二,状态不可见。你不知道它是真在跑、卡住了,还是已经崩了。
第三,恢复成本高。某个 Agent 中途断掉,下一次接起来要重新拼上下文。
第四,人工节点很别扭。比如"这个设计要不要过""这个站能不能发外部渠道",这些都不能让 Agent 自己越权处理。
Hermes Kanban 的思路完全不同。
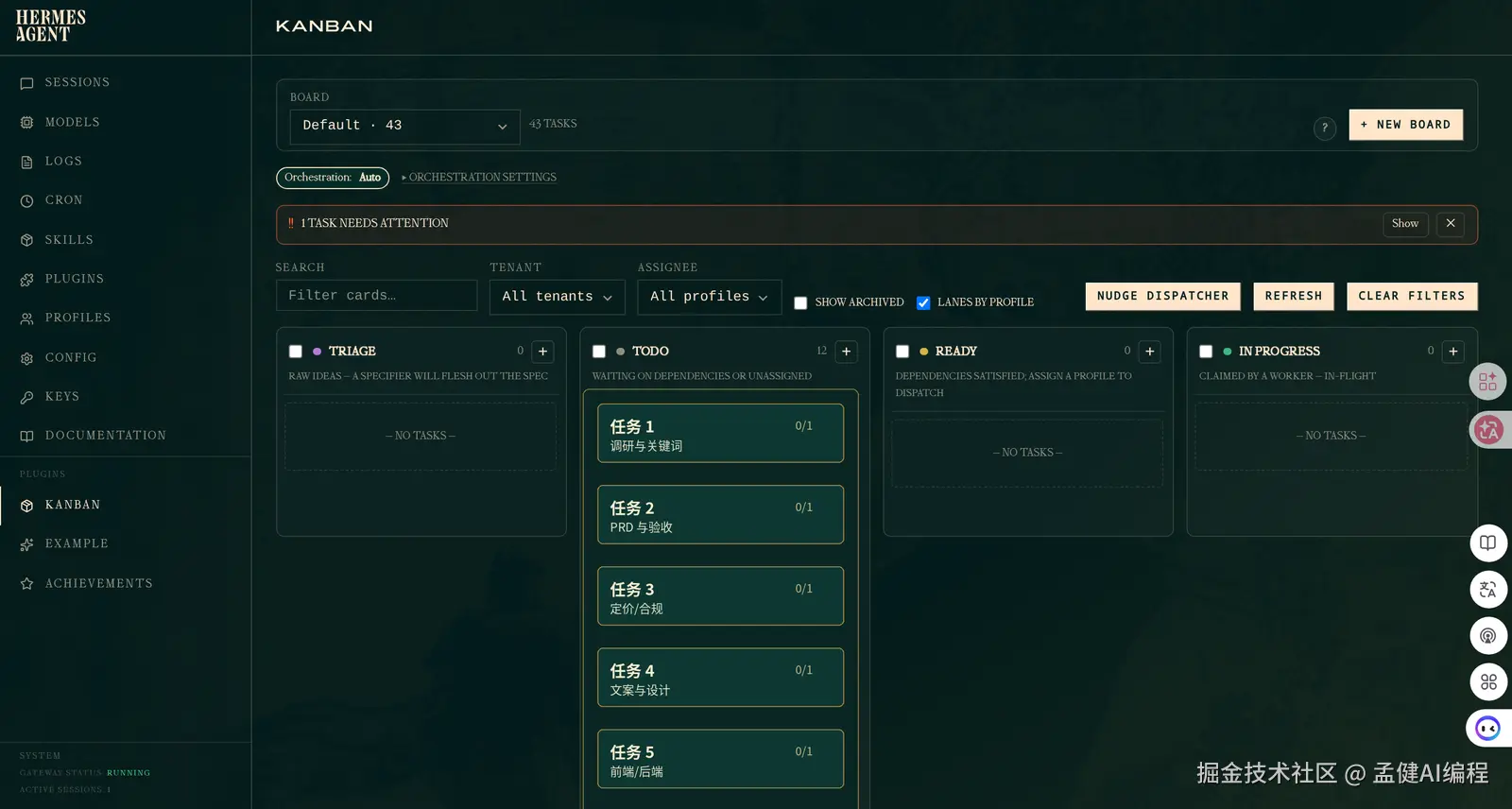
任务不是一次函数调用。任务是看板里一张持久化卡片。
卡片里有任务描述、owner、lane、状态、评论、metadata、产物路径、阻塞原因。Agent 接任务、执行、写结果、创建下一张卡。整个过程不依赖某个聊天窗口活着。
多 Agent 协作要跑起来,先得把任务从对话里拿出来。
02 我怎么把做站流水线搬进 Kanban
我的做法很简单:Kanban 做事实源,Telegram 只做可见性。
看板里有不同 lane。
每个 Agent 只看自己 lane 里的 ready 任务。比如调研 Agent 看 research,PRD Agent 看 product,设计 Agent 看 design,前端 Agent 看 frontend,QA Agent 看 qa。
任务开始执行后,状态变成 running。
做完以后,必须 complete,并写清楚:
- 交付物在哪里
- 关键结论是什么
- 下一棒是谁
- 有没有风险
- 有没有需要人工确认的点
如果做不下去,就 block。
block 不是失败。block 的意思是:我已经做到当前边界,继续往下需要外部条件。
比如缺凭据,缺确认,缺上游产物,或者发现需求冲突。
这比一直 running 强太多。一直 running 你不知道它是在工作,还是已经死了。blocked 至少把问题暴露出来。
Hermes 的 worker lane 机制也很关键。
Agent 启动后,会拿到当前任务、看板 slug、工作目录等上下文。它知道自己接的是哪张卡,属于哪块板,产物应该写到哪里。
这里有个细节:看板名是 board slug,不是某个本机数据库路径。
这个设计很重要。因为多 Agent 协作最怕"靠嘴传上下文"。一旦要靠聊天告诉它"你去读哪个文件""你接哪个任务""你现在是什么身份",链路就会变脆。
我现在要求所有 Agent 完成任务时,都必须把产物路径写回卡片。
不要只说"完成了"。
下一棒 Agent 不需要猜。它打开任务卡,看到上游文件,直接读取,继续执行。
状态消息会过期,产物路径不会。
03 一条真实任务链
这次写文章前,我专门翻了几个小墨系列 Agent 的历史 session。
最有代表性的是一次地图类工具站的视觉返工。
起点是用户反馈:实站效果和设计预期差距很大。
以前这种事很容易变成一句模糊指令:"设计再优化一下。"
这次我没有这么做。
我在看板里建了一张设计返工卡,要求设计 Agent 先做四件事:
- 看实站效果
- 对照原设计真源
- 列出 fidelity gap
- 交付可执行的前端 patch 清单
设计 Agent 执行过程中遇到一个外部工具失败。它没有把失败吞掉,而是在任务评论里写清楚:工具尝试失败,改用 fallback 方案继续。
这个细节很重要。
后面接手的人不需要猜"为什么交付格式和预期不一样"。原因已经写在卡片里。
设计完成后,产品验收 Agent 接棒。
它不是凭感觉说"可以"。它读取设计包、核对验收标准,然后给出明确结论:是否允许进入前端实现。
通过后,它创建下一张前端任务卡。
前端 Agent 拿到的不是一句"你实现一下"。
它拿到的是:设计交付物、验收结论、实现边界、不得额外发挥的要求。
这句话非常关键。
很多多 Agent 协作会失控,就是因为每个 Agent 都想"顺手优化"。设计想改产品,前端想改设计,QA 想改需求。最后看起来大家都很主动,实际产物越来越偏。
我的规则是:
当前 Agent 只执行当前合同。发现问题可以开卡,不能偷偷改方向。
前端实现后,QA Agent 接棒。
QA 没有只回一句"有问题"。它把问题按严重程度写成报告,并创建修复卡。修复卡再回到前端 lane。修完后,QA 再回归。
这一整条链路里,人类只在关键节点介入:确认方向、解锁外部动作、判断是否发布。
其他动作都在 Kanban 上流转。

这就是我现在觉得 Kanban 必须存在的原因。
如果只看聊天记录,你会看到一堆"完成了""已修复""继续"。
如果看 Kanban,你能看到任务链本身:谁创建了卡,谁接手,谁阻塞,谁产出,谁验收,谁把下一张卡推出来。
真正的协作痕迹,不在热闹的聊天里,在冷静的状态机里。
04 worker lanes 解决的是"谁来执行"
Hermes 官方文档里有一个页面专门讲 worker lanes。
我以前对这个概念没那么敏感。真正跑起做站流水线后,才发现它是多 Agent 协作的关键抽象。
lane 不是简单的列名。
lane 代表一类可执行任务的角色、启动方式、生命周期边界和完成约定。
比如设计 lane 里的任务,就应该由设计 Agent 接。QA lane 里的任务,就应该由 QA Agent 接。前端 lane 的任务,不能因为某个 Agent"看到了"就随手做。
这让协作从"谁在线谁接"变成"谁适合谁接"。

这也是为什么我现在不喜欢纯群聊派活。
群聊派活靠人记。
Kanban lane 靠系统路由。
前者看起来灵活,后者更适合长期运行。
05 我从小墨历史 session 里看到的协作规则
这次复盘几个 Agent 的历史 session,我更确定了四条规则。
第一,看板是事实源。
任务上下文、中间决策、产物路径,必须写在卡片里。聊天可以同步进展,但不能承担事实源。
这点非常反直觉。
人类习惯在群里看进度,觉得群消息就是记录。但 Agent 不一定读群。下一棒真正会读的是任务卡、metadata、handoff 文件。
所以我现在给所有做站 Agent 的规则都是:群里可以发 START / DONE / BLOCKED,但最终状态必须回写 Kanban。
第二,block 是安全阀。
很多人会把 blocked 当成坏状态。
我现在反而希望 Agent 该 block 就 block。
缺权限、缺确认、缺输入、外部发布有风险,就停下来,把原因写清楚。
最危险的不是 block。
最危险的是 Agent 为了显得能干,绕过确认,自己往下做。
第三,产物路径比自然语言总结重要。
"我已经完成设计优化"没有意义。
有意义的是:设计包在哪、验收报告在哪、patch 清单在哪、截图在哪、测试报告在哪。
Agent 的自然语言总结经常会变形。文件不会。
第四,下一棒必须由上游产物驱动。
不是让前端 Agent 重新理解一遍需求,也不是让 QA Agent 重新猜业务目标。
上游交付什么,下游就基于什么执行。
如果下游发现上游有问题,开新卡,回到对应 lane。
这样链路才不会变成一团麻。
06 我现在对多 Agent 协作的判断
别急着同时启动 20 个 Agent。
先把任务系统搭好。
多 Agent 协作的核心,不是"更多模型同时干活"。
核心是:
- 任务能不能持久化
- 状态能不能恢复
- 上下文能不能无损交接
- 阻塞能不能暴露
- 人工确认能不能留下记录
- 产物能不能被下一棒直接使用
Hermes Kanban 给我的价值,就是把这些东西变成了工程约束。
Agent 可以独立跑。
任务可以被追踪。
中间状态可以被审计。
某个 Agent 崩了,卡片还在。某段聊天断了,流程还能继续。
这才是多 Agent 协作真正需要的底座。
我现在越来越相信一件事:
多 Agent 协作的上限,不取决于 Agent 数量,取决于任务管理精度。
工具就在那儿。
用不用,是你的事。
👋 我是孟健,前腾讯 T11 / 前字节技术 Leader,现在全职做 AI 编程。
🔥 更多 AI 编程实战:
- GitHub:@mengjian-github
- 专栏:AI编程实战
觉得有用?点赞+收藏 就是最大支持 🙏