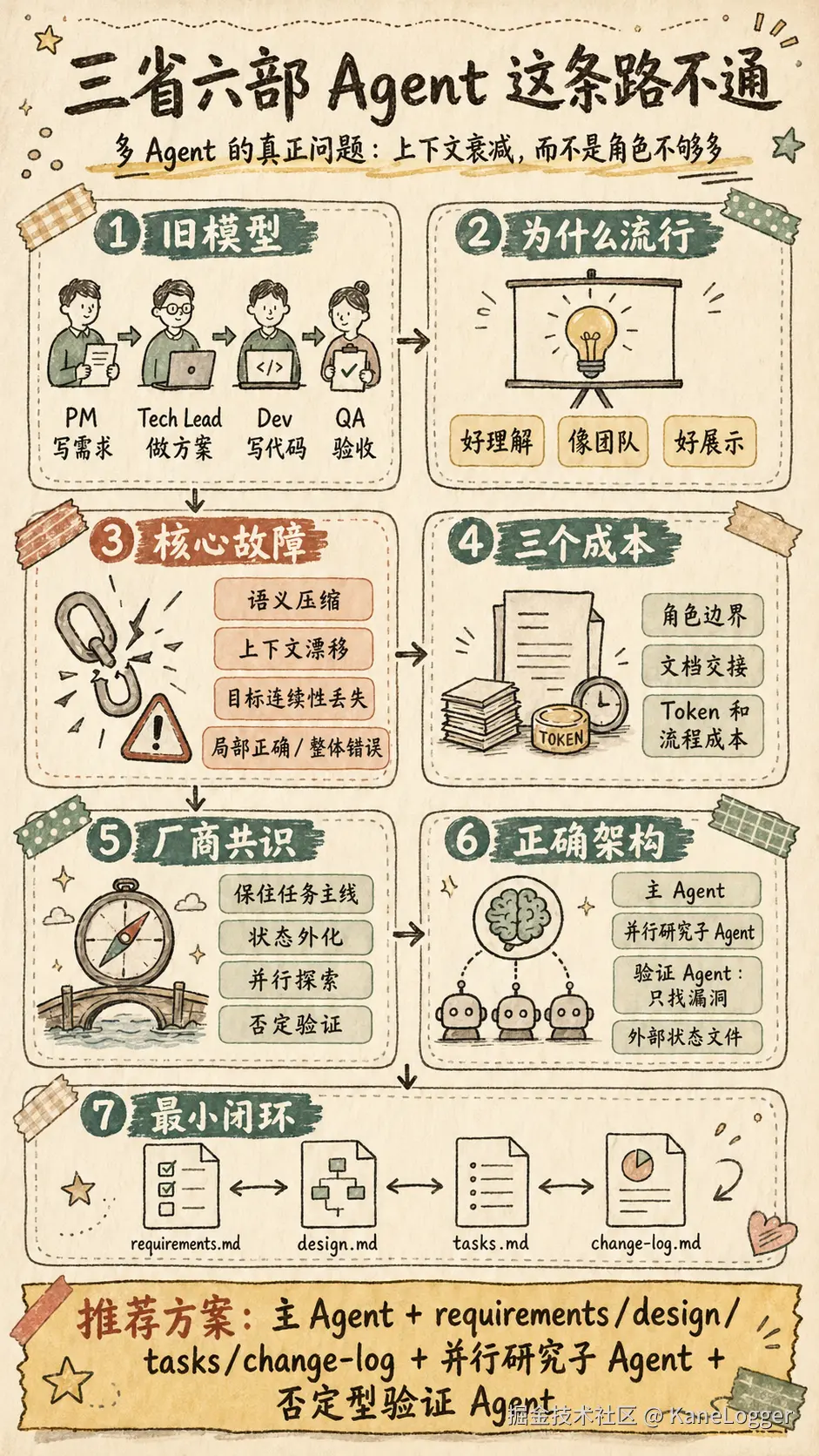
什么是三省六部?
它指的是直接把人类组织的分工逻辑迁移到 Agent 系统。之前团队的工作分工:
- PM / 产品经理:写需求
- Tech Lead / 架构师:做技术方案
- Dev / 工程师:写代码
- QA / 测试:验收测试 然后把需求交给AI,工作像公司流程一样在 Agents 之间流转。
三省六部为什么会流行?
因为它方便人去理解,满足了人类对AI系统可解释性的渴望;也满足了管理层对"AI像团队一样工作"的想象;还好展示,用流程图画出来,有部门、有箭头、有交接,非常直观。 更深层的原因是:大多数采用这个模式的团队,并没有真正面对过"上下文在多Agent间传递时的损耗"这个问题。他们的任务可能不够复杂,或者问题被其他因素掩盖了。等到任务复杂度上来,系统开始出现诡异的"局部正确,整体错误"时,问题才会暴露。
我之前一段时间也觉得 opencode + oh-my-opencode/OMO 配合 A2A 协议这套组合是现阶段的最佳实践,A2A 解决的是 Agent 间通信协议,不解决语义压缩、上下文漂移和目标连续性。 但是在执行一些复杂的任务过程中,碰到了上下文截断/污染的问题,再之后深入去了解之后才知道存在会制造假边界、切断上下文、浪费 token这些问题。而现在现有的 A2A 协议等技术手段还不能解决信息压缩造成的损失问题,信息压缩的次数和信息漂移的程度是正相关。 回头研究主流模型厂商的 coding agent 架构,是主 Agent 持有完整意图,显式状态承接长期记忆,子 Agent 只负责并行探索和对抗验证。
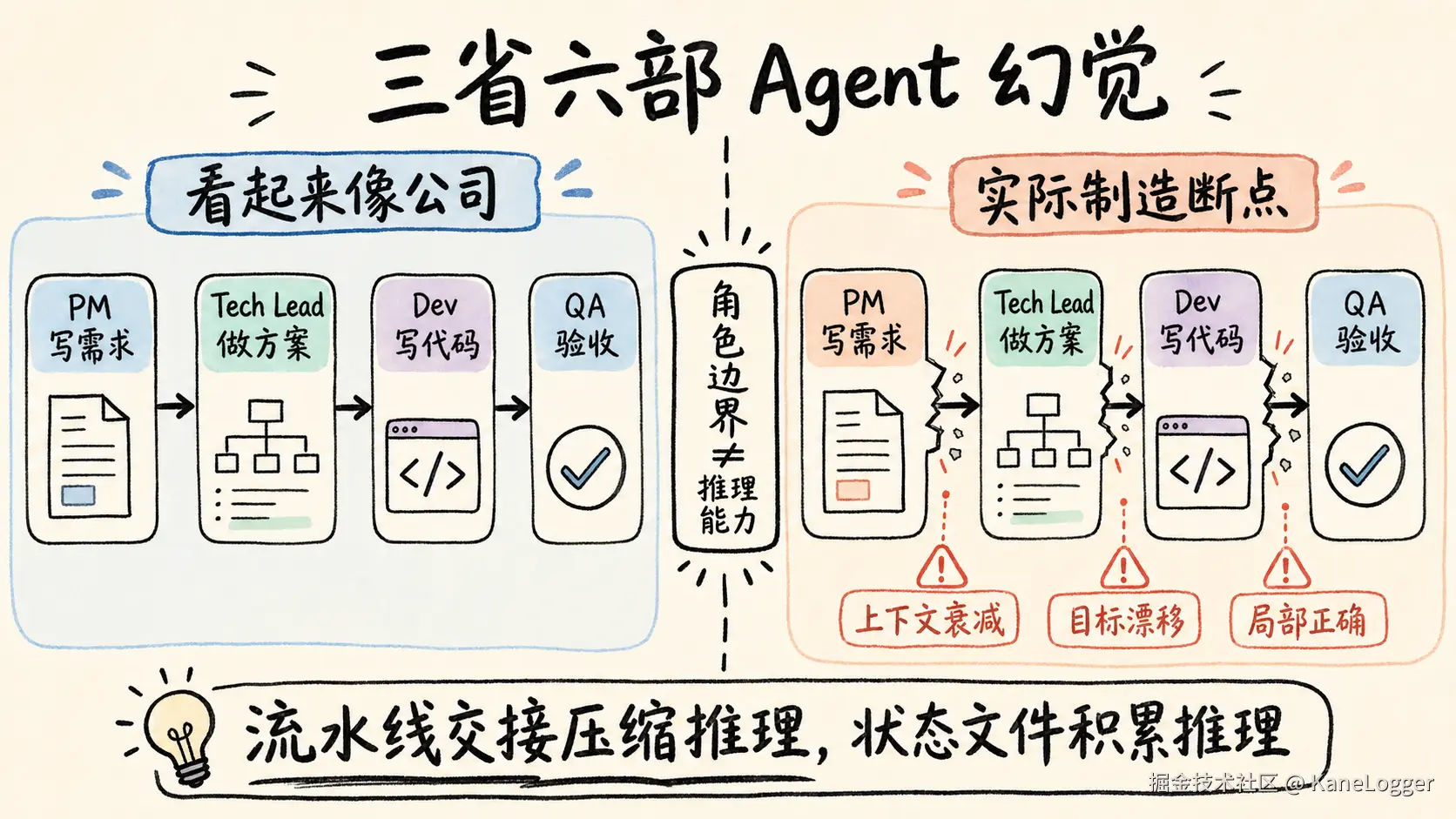
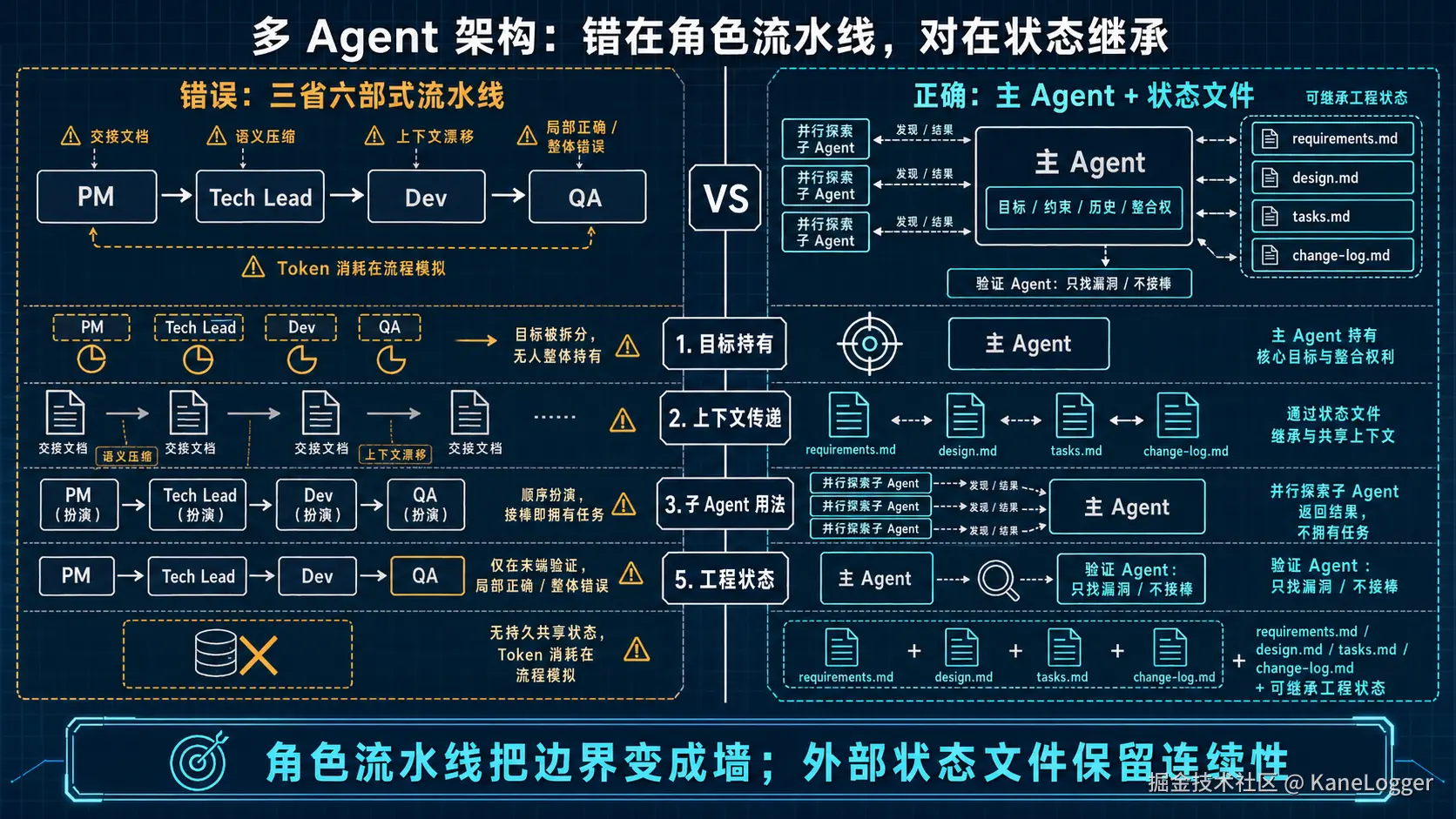
为什么多Role-Agent架构在工程上站不住?
把 Agent 命名为产品经理、架构师、工程师、测试,不能让系统更专业,只会引入三个成本:
角色边界让模型少思考
人类组织需要分工,是因为人有注意力上限、专业壁垒和沟通成本。LLM 不同,同一个模型可以写需求、读代码、做架构、补测试;它缺的是完整上下文、稳定目标和足够深的推理预算。 把模型锁进 PM、Tech Lead、Dev、QA 角色,会把原本连续的判断拆碎。
- 测试角色看到架构问题,会被角色设定诱导成沉默;
- 实现角色发现需求漏洞,也会被流水线诱导成照单执行。
- 最有价值的判断常常出现在边界上。角色流水线把边界变成墙。
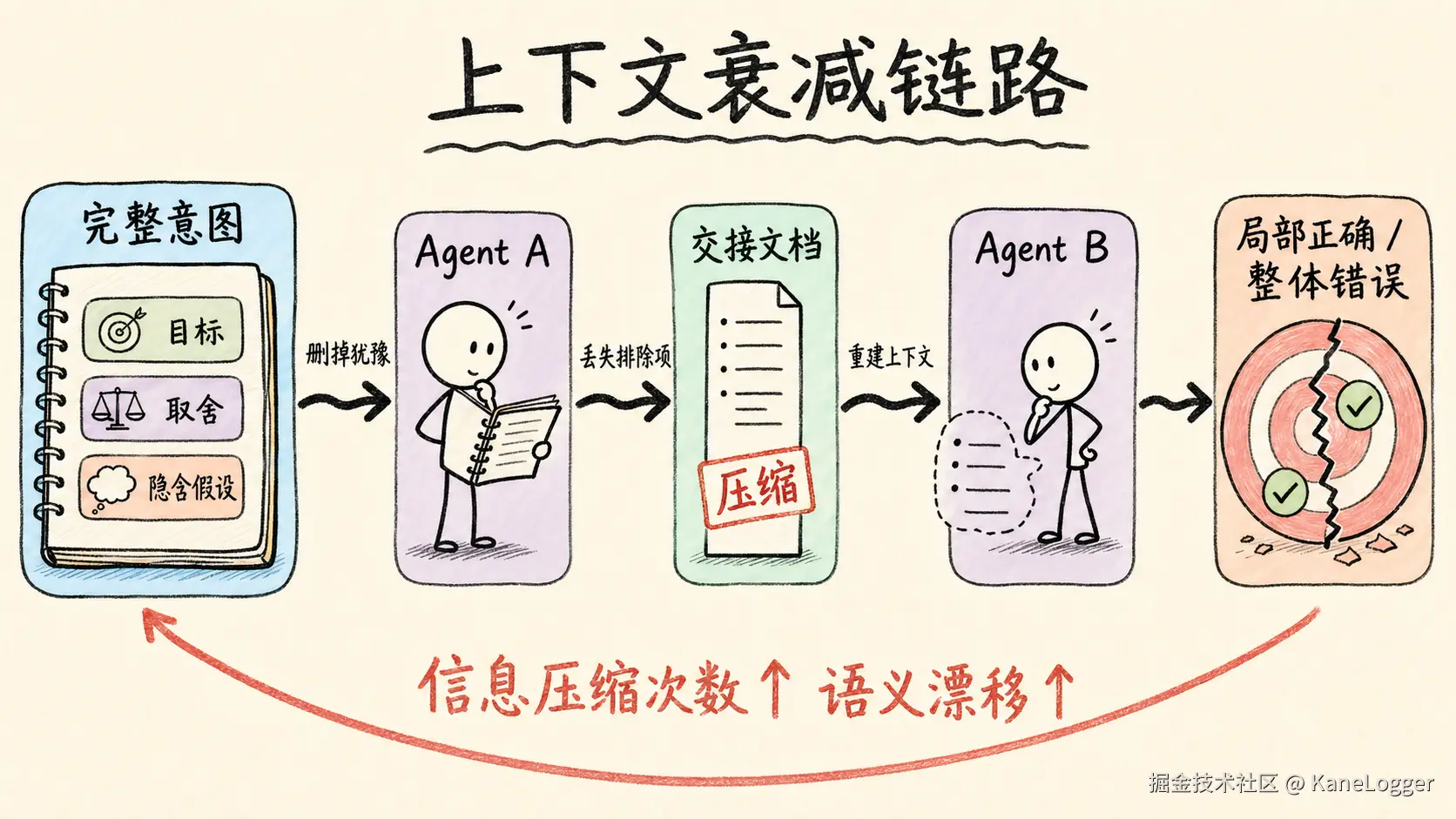
文档交接让上下文衰减
在三省六部工作流里,A 写文档交给 B。B 拿到的是压缩后的结论,缺少生成结论时的犹豫、取舍、排除项和隐含假设。每一次交接都在重建上下文。
Token 和流程成本
流程越长,漂移越隐蔽:每个节点都局部合理,整体目标逐步偏离,局部最优不代表整体最优。 外部状态文件的逻辑完全不同。progress、spec、runbook、git history 记录的是同一条任务主线的增量历史。下一个 session 读取的是完整工程现场,相当于下一个自己接着做。 大量 token 被消耗在"交接文件""角色说明""流程模拟"上,而没有用于真正推理。系统看起来像一个公司在协作,实际是把 token 消耗在模拟组织行为上。
关键差异很简单:流水线交接压缩推理;状态文件积累推理。前者制造断点,后者保留连续性
厂商是怎么设计的
Anthropic、OpenAI、Google 关注的是任务上下文如何持续、状态如何继承、推理如何避免漂移。主要集中在:
- 哪些信息必须由同一条推理链持续持有
- 哪些问题可以并行探索
- 哪些状态必须写进外部文件
- 哪些结果需要被独立验证
共同点:保住任务主线,扩大独立搜索,把关键状态写到外部,给验证者明确的否定职责。
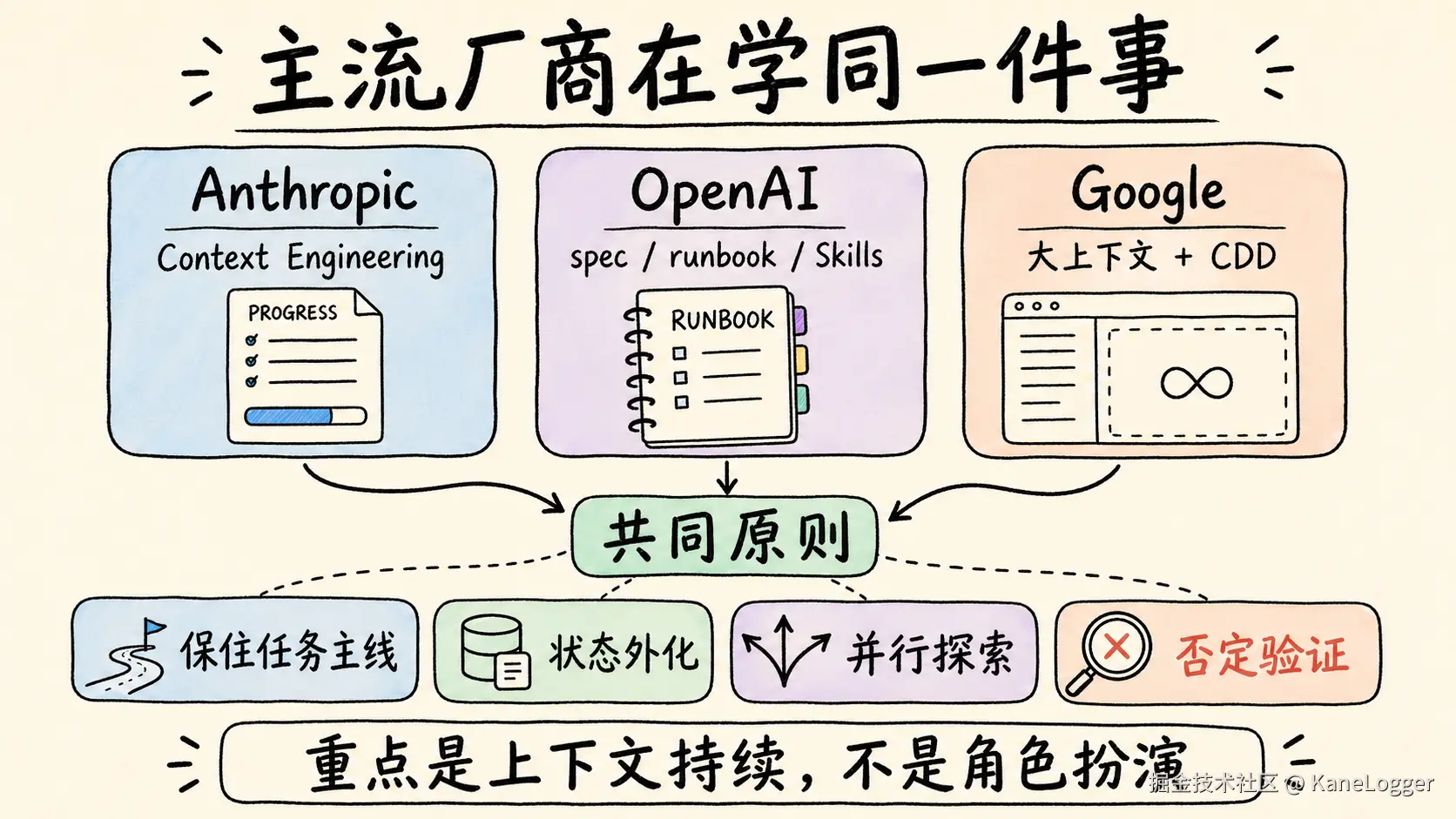
Anthropic
方向是 Context Engineering:
- 用 progress 文件、git history、initializer/runbook 保住跨 session 状态;
- Research 系统采用 orchestrator-worker,由主 agent 分解任务,子 agent 并行探索
- 再回流给主 agent 综合。
OpenAI
方向是 spec、runbook、compaction、Skills:
- 先冻结目标,再把操作规程和可复用能力挂进执行环境。
- Skills 是操作规范和工具包,角色标签在这里没有工程价值。
方向是大上下文与 Context-driven Development:
- 把项目意图放进持久化 spec 和 plan
- 用长上下文和推理签名缓解漂移。
感慨一下
人有康威定律,Agent也有自己的"康威定律"。 人类分工是为了解决注意力、专业壁垒和沟通协调的问题,虚拟公司式多 Agent 的核心问题是:它用组织分工替代了推理连续性。 维护型项目真正需要的,是主线 Agent、外部状态文件和否定型验证。
和厂商学能学到什么?
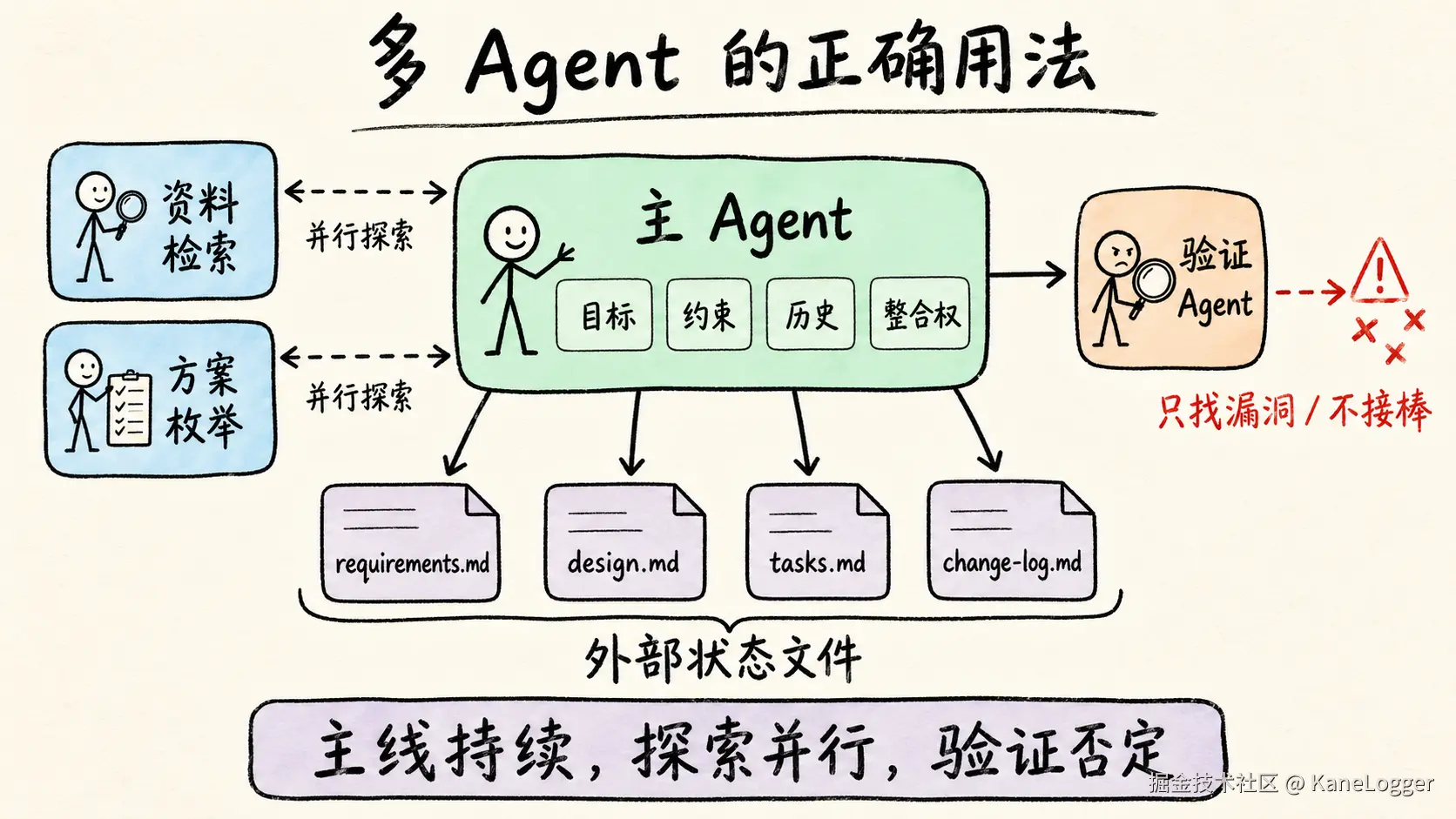
- 连续推理交给单一主线。主 Agent 持有目标、约束、历史和最终整合权。
- 独立问题交给并行子 Agent。竞品调研、资料检索、方案枚举适合拆出去;强依赖同一上下文的设计和实现适合留在主线。
- 长期任务必须外化状态。一份有效状态文件至少包含:任务目标、已完成步骤、当前状态、已知坑。目标保持稳定,历史追加,当前状态覆盖,坑位持续沉淀。
- 验证 Agent 只负责否定。它要找漏洞、反例、遗漏和风险;它不接棒继续做。
- 工具和规程决定能力。bash、文件读写、搜索、测试、spec、runbook、skill,比 PM/QA 这种标签更重要。
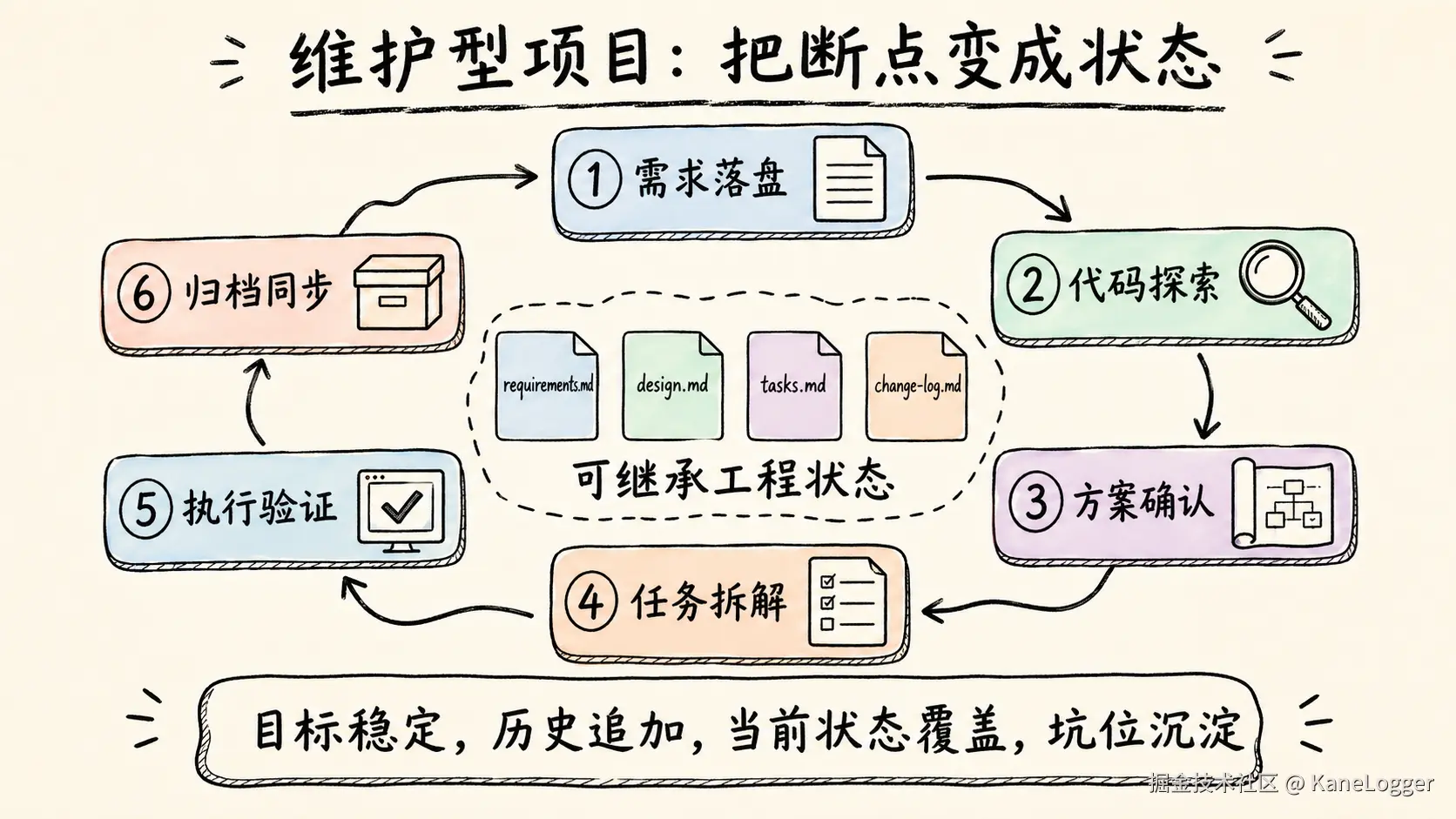
维护型项目的正确工作流
维护型项目是在活系统上动手术。第一步是把 AI 接到真实工程现场:原始需求、现有代码、历史决策、项目规范、已知坑和验收标准。
正确流程可以压成六步:
- 需求落盘:先把原始需求写成
requirements.md,包含目标、边界、非目标、验收标准和相关链接。需求必须稳定,否则后面的推理都会漂。 - 代码探索:让 AI 先读现有实现、目录结构、接口契约、测试和历史文档,再提出澄清问题。没有完成探索之前,不进入实现。
- 方案确认:AI 输出
design.md或修改计划,写清为什么改、改哪些文件、有哪些方案、推荐哪一种、风险是什么。人只在这里做关键决策。 - 任务拆解:把方案拆成
tasks.md,每个任务都要有文件路径、变更点和验证方式。任务数量要受控,复杂需求宁愿拆小,也不要让一个超长计划吞掉上下文。 - 执行验证:AI 按计划实现,过程中持续更新
progress.md或change-log.md,记录已完成步骤、当前状态、踩坑、回滚点和未解决问题。验证 Agent 只负责找错,不能接棒继续写。 - 归档同步:需求完成后,把规范增量、关键决策、测试结果和踩坑记录合并回项目活文档。否则文档会重新变成沉睡 Wiki,下一个 session 还是要从头考古。
本质是用工具链把每个断点都变成可继承的工程状态。
最小闭环可以固定四类文件:
requirements.md:目标、边界、验收标准、非目标。design.md:方案选择、文件影响面、风险和人工决策。tasks.md:可执行任务、路径、验证标准。change-log.md:计划变更、执行进度、踩坑记录、当前状态。
小修小改可以只保留 requirements.md + change-log.md。
复杂功能、重构、跨模块改动必须走完整的 requirements -> design -> tasks -> execute -> verify -> archive 流程。
判断标准很简单:只要 AI 需要理解历史上下文才能不误伤系统,就不要直接让它写代码。
最终判断
三省六部让 AI 系统看起来像公司,工程收益很低。
多 Agent 架构真正需要的是一个能持续记住目标的主线、一组可并行探索的子任务、一套可继承的外部状态,以及一个专门找错的验证者。
推荐方案:主 Agent + requirements/design/tasks/change-log + 并行研究子 Agent + 否定型验证 Agent。
先把需求、方案、任务、变更日志标准化,这比增加更多角色 Agent 更有效。