本文适合谁: 正在使用 Claude / GPT 做日常开发工作、但苦于每次新开会话都要"重新介绍自己"的工程师;以及想把 AI 助手从"一次性工具"升级为"长效分身"的技术探索者。
0. 先看结论:你现在的 AI 工作流有多浪费?
假设你每天用 Claude 辅助编码,每个新会话的前 5 轮对话平均要花 800 token 来重复说明:
- 你的技术栈("我用 FastAPI + PostgreSQL,代码风格遵循 Google Python Style Guide")
- 业务上下文("这个项目是一个多租户 SaaS,权限模型基于 RBAC")
- 工作流偏好("给我代码之前先给 pseudocode,回复用中文")
按 Claude Sonnet 的定价,这 800 token 每天消耗约 ¥0.05------看起来不多,但背后是你花在"复读"上的 3-5 分钟,日积月累是真实的认知损耗。
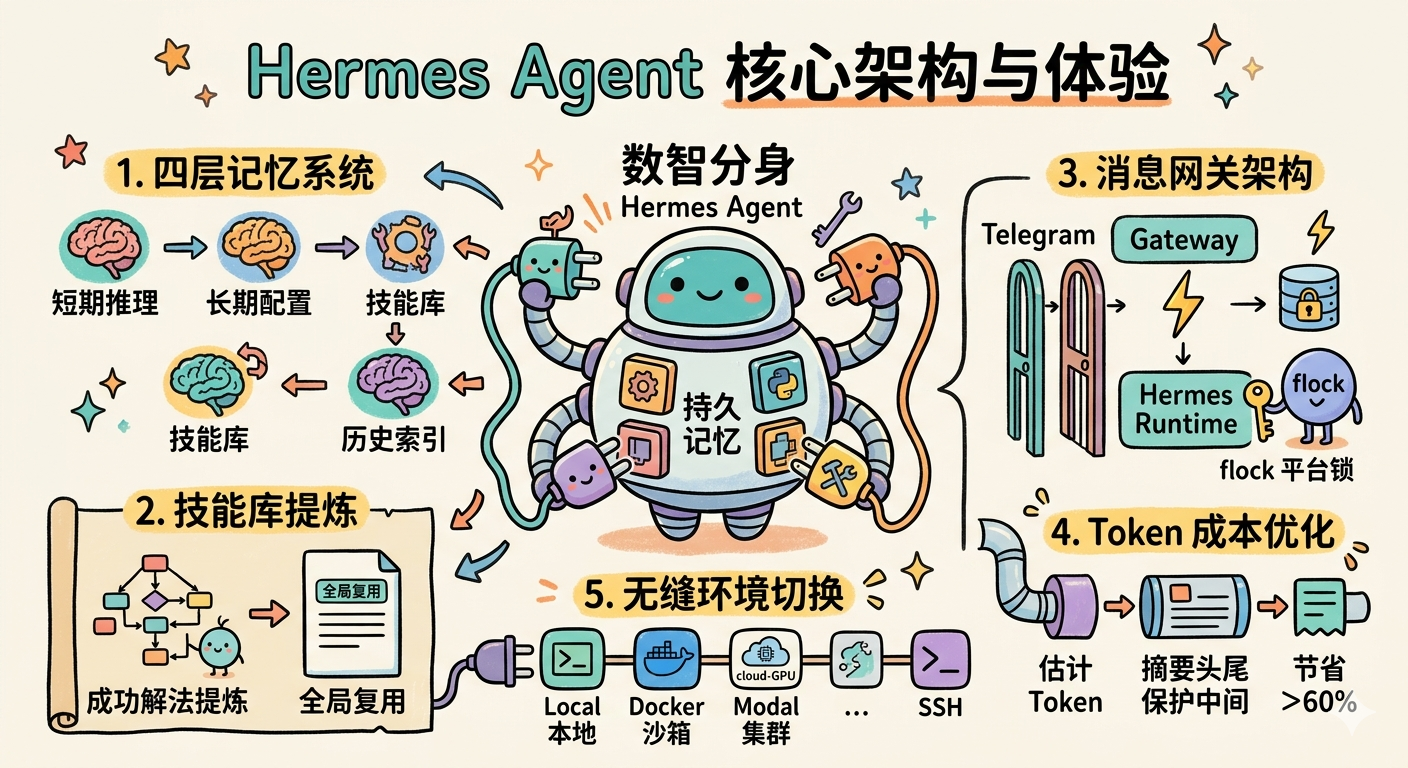
Hermes Agent 要解决的,正是这种"AI 上下文税"。它不是一个 ChatGPT Wrapper,而是一个具备持久记忆、跨平台一致性、自进化技能库的 Agent 运行时。
本文将带你从架构原理到实战落地,完整理解 Hermes 的设计哲学与使用方法。
1. 系统全景:在深入细节之前,先建立全局观
在拆解各个模块之前,先看清楚整个系统的边界和数据流向:
⚙️ 执行层(Environment)
💾 记忆层(Memory System)
🧠 核心层(AIAgent Runtime)
📥 输入层(Gateway)
Telegram
Discord
Slack
CLI / hermes chat
Gateway 消息路由
AIAgent.run_conversation
PromptBuilder
ContextCompressor
Claude API
短期记忆\nContext Window
长期记忆\nMEMORY.md / USER.md
技能库\nskills/*.md
历史索引\nSQLite FTS5
Local
Docker 沙箱
SSH 远程
Modal Serverless
核心设计哲学:Experience gained once, reused globally(经验一次获得,全局复用)。 无论你在 CLI 还是 Telegram 中与 Hermes 对话,它访问的是同一套记忆和技能,消息通道只是输入形式不同。
2. 消息网关架构:让 Telegram 成为你的 AI 指令部
为什么弃用重型中间件?
与许多依赖庞大消息队列(如 RabbitMQ/Redis)的 Agent 不同,Hermes 坚持极致的轻量化。它的选型是 SQLite + WAL(Write-Ahead Logging)模式:
| 对比维度 | RabbitMQ/Redis 方案 | Hermes SQLite+WAL |
|---|---|---|
| 部署复杂度 | 需要独立服务进程 | 零配置,单文件 |
| 断电数据安全 | 依赖 AOF/镜像配置 | WAL 天然原子性 |
| 移植成本 | 数据导出迁移 | 复制单个 .db 文件 |
| 并发写入 | 高(但资源消耗大) | 中高(WAL 支持并发读) |
WAL 模式让 Gateway 多平台并发写入时不会产生互斥锁死,配合 BEGIN IMMEDIATE + 随机退避重试(20-150ms Jitter,最多 15 次),在多平台并发场景下依然稳定。
多平台适配器架构
BasePlatformAdapter
+connect()
+send_message()
+receive_message()
+_acquire_platform_lock()
TelegramAdapter
+webhook_handler()
+polling_loop()
DiscordAdapter
SlackAdapter
每个适配器在 connect() 时会获取平台级文件锁(fcntl.flock),锁文件存放在 ~/.hermes/gateway_<platform>.lock。即使进程崩溃,内核也会自动释放锁,防止多实例竞争同一个 bot token。
单条消息完整生命周期
StreamConsumer AIAgent SessionStore(SQLite) SessionContext TelegramAdapter Telegram 用户 StreamConsumer AIAgent SessionStore(SQLite) SessionContext TelegramAdapter Telegram 用户 发送消息 1 webhook / polling 事件 2 _acquire_platform_lock() fcntl.flock LOCK_EX|LOCK_NB 3 构造 MessageEvent 4 get_or_create_session(session_key) 5 conversation_history 6 run_conversation(user_message) 7 stream_delta_callback(token) 8 缓冲后分批发送(避免频繁 API 调用) 9 editMessageText / sendMessage 10 用户收到流式回复 11
🛠️ 实战:10 分钟接入 Telegram Bot
Step 1:获取 Bot Token
前往 @BotFather,发送 /newbot,按提示创建并复制 token。
Step 2:配置 Hermes
yaml
# ~/.hermes/config.yaml
platforms:
telegram:
enabled: true
bot_token: "YOUR_BOT_TOKEN_HERE"
# 可选:限制只响应特定用户
allowed_user_ids:
- 123456789
agent:
model: "claude-sonnet-4-20250514"
environment: "local" # 或 "docker" 实现沙箱隔离Step 3:启动 Gateway
bash
# 前台运行(调试用)
hermes gateway run
# 作为 systemd 服务静默运行(生产推荐)
hermes gateway install --service
systemctl --user start hermes-gateway
systemctl --user enable hermes-gateway # 开机自启Step 4:验证
在 Telegram 中给你的 bot 发送 你好,告诉我你现在的系统时间,如果 Hermes 正确响应并执行了 terminal_tool,配置成功。
💡 通勤场景: 你在地铁上通过 Telegram 发送 "帮我跑一下项目的 pytest,把失败的用例整理成 Markdown 表格",Hermes 在远端服务器上执行,结果推送回你的手机。全程你不需要开电脑。
3. 多层记忆系统:Agent 的"大脑"解构
Hermes 能做到"越用越懂你",靠的是严密的多层记忆架构。理解这个架构,是高效使用 Hermes 的关键。
3.1 四层记忆总览
L4:历史索引(情节性记忆)
SQLite FTS5\n全文检索\n前缀·短语·布尔运算
L3:技能库(程序性记忆)
skills/*.md\n成功解法的结构化提炼\n可全局复用
L2:长期配置记忆(持久)
MEMORY.md\n硬性约束\n代码规范·业务背景
USER.md\n用户画像\n偏好·身份·习惯
L1:短期推理记忆(当下)
Context Window\n即时指令处理
| 层级 | 存储位置 | 写入时机 | 读取方式 |
|---|---|---|---|
| L1 短期推理 | Context Window(内存) | 每次对话 | 自动注入 |
| L2 长期配置 | ~/.hermes/memories/ |
Agent 主动更新 | 启动时快照 |
| L3 技能库 | ~/.hermes/skills/ |
手动或自动提取 | 系统提示词注入 |
| L4 历史索引 | ~/.hermes/hermes_state.db |
每轮对话结束 | session_search_tool |
3.2 记忆的三个生命周期阶段
ExternalProvider(Honcho等) BuiltinMemoryProvider MemoryManager AIAgent ExternalProvider(Honcho等) BuiltinMemoryProvider MemoryManager AIAgent 阶段 1 --- 会话初始化 阶段 2 --- 每次 LLM 调用前(prefetch) 阶段 3 --- Turn 结束后(sync) initialize(session_id) initialize(session_id) initialize(session_id) prefetch_all(user_message) prefetch(query) prefetch(query) builtin_context(MEMORY.md + USER.md 快照) external_context(Honcho 检索结果) 合并后的记忆上下文 注入到当前 user_message(非 system prompt!) sync_all(user_msg, assistant_msg) sync_turn(...) sync_turn(...) 原子写入 ~/.hermes/memories/ API 调用写入远程后端
关键设计细节: 动态记忆内容被注入到 用户消息 而非系统提示词。原因是 Anthropic 等厂商的前缀缓存(Prefix Cache)以系统提示词为 key------如果每轮修改系统提示词,缓存就会失效,成本倍增。把动态内容放入 user message,系统提示词保持稳定,缓存命中率最大化。
3.3 技能库(Procedural Memory):Hermes 最独特的能力
技能库是 Hermes 与普通 AI Wrapper 最本质的区别。 当 Agent 成功解决一个复杂问题后,可以通过 skill_manager_tool 将解法提炼为结构化的 SKILL.md,供后续所有会话复用。
一个标准 SKILL.md 的结构:
markdown
---
name: deploy-fastapi-to-modal
description: "将 FastAPI 应用部署到 Modal Serverless 平台的完整流程"
tags: [fastapi, modal, deployment, serverless]
success_rate: "3/3"
last_used: "2025-04-10"
---
## 前置条件
- modal Python 包已安装:`pip install modal`
- Modal token 已配置:`modal token new`
## 执行步骤
1. 创建 `modal_app.py`,使用 `@app.function()` 装饰器包装 FastAPI app
2. 配置 `Image` 依赖(避免在函数内部 import,放在 Image 构建阶段)
3. 执行 `modal deploy modal_app.py`
4. 验证:访问返回的 URL
## 已知坑
- Modal 冷启动约 3-8 秒,生产环境建议开启 `keep_warm=1`
- 本地文件路径不可用,必须通过 `modal.Volume` 挂载持久存储🛠️ 实战:手动提取一个技能
bash
# 场景:你刚完成了一个复杂的数据库迁移任务
# 在对话中告诉 Hermes:
hermes chat
> 我刚刚完成了把 50GB MySQL 数据库在零停机时间内迁移到 PostgreSQL 的任务,
> 请把整个流程提炼为一个 SKILL.md,存储到技能库中,下次遇到类似任务直接复用。Hermes 会自动调用 skill_manager_tool,将方案固化到 ~/.hermes/skills/mysql-to-postgres-migration.md,下一次你(或同一实例的任何平台)遇到类似迁移任务,这个经验会自动出现在系统提示词中。
3.4 全局 FTS5 历史检索
SQLite FTS5 全文检索支持以下查询语法,通过 session_search_tool 调用:
sql
-- 前缀匹配:找所有提到 PostgreSQL 相关的历史
SELECT * FROM messages_fts WHERE messages_fts MATCH 'postgres*';
-- 短语搜索:精确匹配短语
SELECT * FROM messages_fts WHERE messages_fts MATCH '"zero downtime migration"';
-- 布尔运算:找提到 Redis 但没提到 Celery 的对话
SELECT * FROM messages_fts WHERE messages_fts MATCH 'redis NOT celery';为什么不用向量检索? 纯向量检索在"精确事实回溯"场景下容易产生语义漂移(幻觉)。比如你问"上周三我用的那个正则表达式是什么",向量检索会给你语义相似的内容,但可能不是你真正想要的那个字符串。FTS5 保证精确匹配,代价是不支持模糊语义。Hermes 的设计是两者互补。
4. 极致工程匠心:让系统在生产环境活下去
这一节是给真正要部署 Hermes 到生产环境的读者看的。这些"底层细节"决定了系统能不能在凌晨三点、网络抖动、进程崩溃时还能正常工作。
fcntl.flock LOCK_EX NB
是
否
tempfile + os.replace
即使崩溃
静默 Flush
_print_fn = lambda noop
_install_safe_stdio
管道断开
多实例启动
获取锁成功?
正常运行
直接退出,不竞争
写入记忆
原子写入
文件要么完整,要么未写入
会话结束
创建临时 AIAgent
无输出地固化记忆
Docker/systemd 环境
包裹 stdout/stderr
捕获 OSError 5,不崩溃
| 机制 | 解决的痛点 | 技术细节 |
|---|---|---|
平台锁 flock |
多实例竞争 bot token | `LOCK_EX |
| 静默 Flush | 会话结束时记忆持久化不打扰用户 | _print_fn = lambda *a, **k: None 屏蔽所有输出 |
| Safe stdio | 守护进程因管道断开崩溃 | 包裹 stdout/stderr,捕获 OSError: [Errno 5] |
| 原子写入 | 崩溃留下半写文件 | tempfile 写入 + os.replace() 原子替换 |
| WAL + Jitter 重试 | 并发数据库锁冲突 | BEGIN IMMEDIATE + 20-150ms 随机退避,最多 15 次 |
| 前缀缓存保护 | 每轮修改 system prompt 导致缓存失效 | 动态内容注入 user message,不触碰 system prompt |
5. 缓存友好的上下文引擎:Token 成本优化
随着使用时间增长,对话历史越来越长,Token 成本会指数级上升。Hermes 的 ContextCompressor 是一个双目标优化器:既保留足够上下文让 AI 不"断片",又最大化压缩成本。
压缩策略:"保护头尾、摘要中间"
否
是
estimate_request_tokens_rough
tokens ≥ threshold?
正常对话,不压缩
ContextCompressor.compress
🔒 保护前 3 条消息\n(任务定义·初始指令)
🔒 保护后 6 条消息\n(最近上下文)
📝 中间消息送辅助模型摘要
摘要保留:关键决策·错误修复\n最终状态·待办事项
替换为单条 summary 消息
旧 session end_session()\n新 session 携带 parent_session_id
FTS5 仍可检索原始内容
成本估算示例:
| 场景 | 不压缩 | 压缩后 | 节省 |
|---|---|---|---|
| 20 轮对话(约 8000 tokens) | ¥0.48/次 | ¥0.18/次 | ~62% |
| 50 轮对话(约 25000 tokens) | ¥1.50/次 | ¥0.28/次 | ~81% |
注意: 压缩后原始 session 被标记为结束,新 session 的
parent_session_id指向旧 session。这意味着通过 FTS5 搜索仍然可以找到压缩前的完整对话------没有任何信息丢失,只是不再被默认放入 Context Window。
6. 环境抽象:从本地到 GPU 集群的无缝穿越
Hermes 彻底解耦了逻辑层与执行环境。通过统一的 BaseEnvironment 接口,同一段 Agent 逻辑可以在 7 种后端上运行,切换只需改一行配置。
AIAgent.terminal_tool
BaseEnvironment.execute
Local\n原生运行
Docker\n沙箱隔离
SSH\n远程服务器
Daytona\n开发环境管理
Singularity\nHPC 容器
Modal\nServerless
ManagedModal\n托管 Modal
所有环境返回统一格式:
python
{
"stdout": "...",
"stderr": "...",
"returncode": 0
}🛠️ 实战:用 Telegram 控制 Modal GPU 集群做数据处理
配置:
yaml
# ~/.hermes/config.yaml
platforms:
telegram:
enabled: true
bot_token: "YOUR_TOKEN"
agent:
environment: "modal" # 核心:指向 Modal 环境
modal:
app_name: "hermes-runner"
gpu: "A10G"
timeout: 3600实际使用:
# 在 Telegram 中发送:
帮我处理 /data/raw/logs_2025_04.parquet,
过滤 error_code > 500 的记录,
按 user_id 聚合统计,
结果保存到 /data/processed/error_summary.csvModal Volume(持久存储) Modal GPU 实例 Hermes Gateway 你(Telegram) Modal Volume(持久存储) Modal GPU 实例 Hermes Gateway 你(Telegram) 发送数据处理指令 modal.run() 启动 A10G 实例 读取 logs_2025_04.parquet Pandas/Polars 过滤聚合 写入 error_summary.csv 返回执行结果(行数·耗时·异常) "处理完成:过滤后 23,847 条记录,按 user_id 聚合为 1,204 行,耗时 47s,结果已保存"
你不需要在本地安装任何依赖,GPU 实例在任务结束后自动销毁,按秒计费。
7. 外部记忆插件:Honcho 集成
MemoryManager 有一个关键约束:最多只能有一个外部 memory provider(防止多后端提供同名工具导致 schema 冲突)。
Honcho 是目前官方支持的外部记忆后端,提供三种召回模式:
Honcho Provider
context 模式\n自动注入上下文\n不暴露工具
tools 模式\n暴露工具\n不自动注入
hybrid 模式(默认)\n自动注入 + 工具可用
成本控制配置:
yaml
# ~/.hermes/config.yaml
memory:
external_provider: "honcho"
honcho:
api_key: "YOUR_HONCHO_KEY"
mode: "hybrid"
# 每隔 5 轮才调用一次 Honcho API(降低成本)
injection_frequency: 5
# 上下文调用间隔
context_cadence: 38. 完整 Quick Start 清单
读完了原理,现在是时候动手了。下面是从零到运行的最短路径:
bash
# 1. 安装
pip install hermes-agent
# 2. 配置 Claude API Key
export ANTHROPIC_API_KEY="sk-ant-..."
# 3. 初始化(生成默认配置和记忆文件)
hermes init
# 4. 第一次对话(CLI)
hermes chat
# 5. 告诉 Hermes 你是谁(这会被写入 USER.md,永久记住)
> 我叫 [你的名字],是一名后端工程师,主要使用 Python + FastAPI。
> 我的代码规范:类型注解必须完整,变量名用英文,注释用中文。
> 回复我时,先给结论再给细节。
# 6. (可选)启动 Telegram Gateway
hermes gateway run验证记忆是否生效:
bash
# 新开一个终端,开新会话
hermes chat
> 我的技术栈是什么?
# 期望输出:Hermes 应该能正确说出你的技术栈,无需你再次介绍9. 结语:从工具到分身的临界点
Hermes 构建的是一个知识复利系统:
- 成功经验 →
SKILL.md→ 全局复用 - 用户偏好 →
MEMORY.md/USER.md→ 永久记忆 - 历史对话 → SQLite FTS5 → 精确召回
- 多平台消息 → Gateway → 无论在哪里,记忆一致
一个有趣的思想实验: 当这个系统运行 6 个月后,它积累的 MEMORY.md、USER.md 和 skills/ 目录,某种程度上是你工作方式和决策逻辑的数字化表达。这份"知识快照"可以被克隆到新机器上,立刻恢复你的完整工作上下文。
这不再是一个 AI 工具,而是你认知能力的外部存储介质。