一、一个被反复踩坑的问题:短剧翻译为什么不能直接调通用翻译接口?
做过短剧出海的团队,几乎都走过同一条弯路。
拿到一部中文短剧,第一反应是调 Google Translate API 或者 DeepL,把字幕文件扔进去,几秒钟出结果,成本极低。看起来很完美------直到你把翻译结果发给海外运营,对方回来一句:"这什么意思?"
这不是翻译质量的问题,是翻译范式的问题。
通用翻译接口解决的是语言映射:输入一段文字,输出另一种语言的对应文字。但短剧出海翻译本质上是三个性质完全不同的子问题叠加在一起:
第一,原材料问题。 大多数短剧没有独立的字幕文件,字幕是硬烧在视频画面里的。翻译之前,你得先把字幕从视频帧里提取出来,这是 OCR 的活,翻译接口管不了。
第二,文化语义问题。 "契约婚姻"直译是 Contract Marriage ,但英语语境里这个概念叫 Marriage of convenience ;"月光"这个角色名直译是 Moonlight ,但它承载的情感内核对应的是 The one that got away。这类映射关系不是统计规律,是文化知识,翻译模型在没有上下文的情况下大概率译错。
第三,时间轴约束问题。 字幕有时间码,翻译后的文本长度必须和原始时间窗口匹配。英文字符比中文占更多空间,一句话翻完可能膨胀两倍,字幕就溢出了。通用翻译接口不处理这件事。
三个问题,三种性质,没有一个单一接口能同时解决。这是 NarratorAI 选择多Agent流水线架构的根本原因。
二、架构全貌:四Agent流水线
在展开每个 Agent 之前,先看整体数据流:
-
内容输入:导入 MP4 视频、SRT 字幕文件
-
智能 Agent 1・字幕处理依托 OCR 识别提取内容,自动生成标准带时间轴 SRT 原始字幕
-
智能 Agent 2・本土化适配结合目标地区风土、语境完成文化分析,输出本土化优化清单
-
智能 Agent 3・精准翻译以原始字幕 + 本土化清单为双参考输入,完成语义级精准翻译,产出多语种目标字幕文件
-
智能 Agent 4・视频合成将翻译字幕批量压制至视频画面,最终输出成品视频与独立 SRT 字幕文件
四个 Agent,职责边界清晰,数据单向流转,每个节点的输入输出都是明确定义的结构化数据。这是典型的 Pipeline 架构 ,在工程上的好处是:任何一个节点出问题,可以单独调试和替换,不影响其他节点。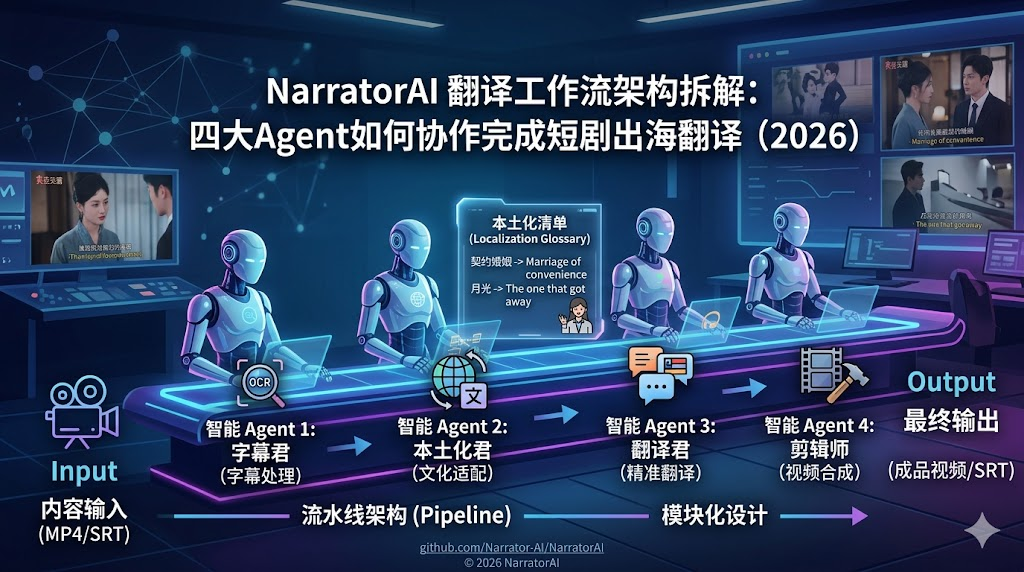
同时,每个 Agent 都可以作为独立工具单独调用------如果你已经有 SRT 文件,可以跳过字幕君直接进翻译流程;如果你只需要提取字幕不需要翻译,可以只调字幕君。这种模块化设计在 API 层面有直接体现,后面会展开。
三、Agent 1:字幕君------从视频帧到SRT的OCR链路
字幕君解决的是"原材料获取"问题。
很多短剧在制作时没有留存独立的字幕文件,字幕是直接烧录在视频画面里的。要翻译,第一步就是把这些字幕从画面里"抠"出来,还原成带时间轴的文本文件。
字幕君的处理链路分为10个步骤:
加载视频文件(10%)
→ 初始化OCR引擎,加载识别模型(20%)
→ 分析视频帧率和总时长(30%)
→ 提取关键帧,执行OCR处理(40%)
→ 应用文本识别算法(50%)
→ 整合时间码信息(60%)
→ 生成SRT格式字幕文件(70%)
→ 执行字幕时间轴校准(80%)
→ 清理识别结果中的噪声字符(90%)
→ 保存字幕文件,处理完成(100%)

这个链路里有几个细节值得展开:
关键帧提取而非逐帧处理。视频通常是 24fps 或 30fps,逐帧 OCR 的计算成本极高,而且字幕在相邻帧之间几乎不变。字幕君通过分析帧率和字幕切换时机,只对关键帧做 OCR,大幅降低计算量。
时间码整合。OCR 提取的是文字,但 SRT 格式需要的是"时间码 + 文字"的组合。字幕君需要把每段文字对应的出现时间和消失时间准确标注出来,这是后续时间轴校准的基础。
噪声清理。OCR 识别结果里经常混入杂字------画面里的装饰文字、水印、台标等都可能被误识别为字幕。噪声清理这一步负责过滤掉这些干扰项。
如果用户已经有 SRT 文件,可以直接跳过字幕君,把 SRT 文件上传后从本土文化君开始执行。这在 API 层面对应的是直接调用 srt_translation 任务类型,而不是 video_translation。
对应 API 端点:
POST https://openapi.jieshuo.cn/api/narrator/ai/v1/tasks/extract-subtitle
四、Agent 2:本土文化君------为什么翻译之前要先做文化分析?
这是整个架构里最反直觉、也最有价值的设计。
大多数人对翻译流程的理解是:输入原文 → 输出译文 。本土文化君的存在,把这个流程改成了:输入原文 → 分析文化语境 → 生成本土化清单 → 输入原文+清单 → 输出译文。
多了一个中间层。为什么?
因为翻译模型本质上是一个"语言映射器",它的训练目标是找到两种语言之间的统计对应关系。但文化语境不是统计关系,是知识。"契约婚姻"在中文短剧里是一个高频情节设定,它对应的英语表达是 Marriage of convenience ,这是一个固定的文化概念,不是逐字翻译能得到的结果。翻译模型如果没有被明确告知这个映射关系,大概率会输出 Contract Marriage------语言上没错,文化上失准。
本土文化君的工作就是在翻译之前,把这些"翻译模型不知道但必须知道"的文化知识提取出来,整理成一份清单,作为翻译君的上下文输入。
本土文化君的处理链路:
分析文本语言特性
→ 识别固有名词和专有名词(人名、地名、剧名)
→ 提取文化特定元素(成语、网络梗、俚语、隐喻)
→ 建立本土化清单(原文 → 目标文化对应表达)
→ 关联文化背景知识(为每个条目补充文化解释)
→ 标记需要特殊处理的字符(特殊标点、emoji、方言字)
→ 检查本土化冲突(同一词在不同语境下的不同处理方式)
产出物是一份结构化的本土化清单(Localization Glossary)。
以下是几个真实的清单条目示例:
|---------|-------------------|---------------------------------------|------------------------|
| 原文 | 直译(错误) | 本土化映射(正确) | 文化背景 |
| 契约婚姻 | Contract Marriage | Marriage of convenience | 英语固定表达,指双方各有目的的婚姻安排 |
| 月光(角色名) | Moonlight | The one that got away | 对应"错过的人"这一情感内核 |
| 霸道总裁 | Domineering CEO | Alpha billionaire | 对应海外 Romance 小说的固定人设标签 |
| 白月光 | White Moonlight | First love / The one I never got over | 对应"心里永远的白月光"这一情感概念 |
这份清单在 NarratorAI 的产品界面里是可编辑的 。用户可以在系统自动生成清单之后,手动修改、增删条目,然后再提交给翻译君执行。这是"人机协作"设计的核心体现------AI 负责批量提取,人负责最终把关。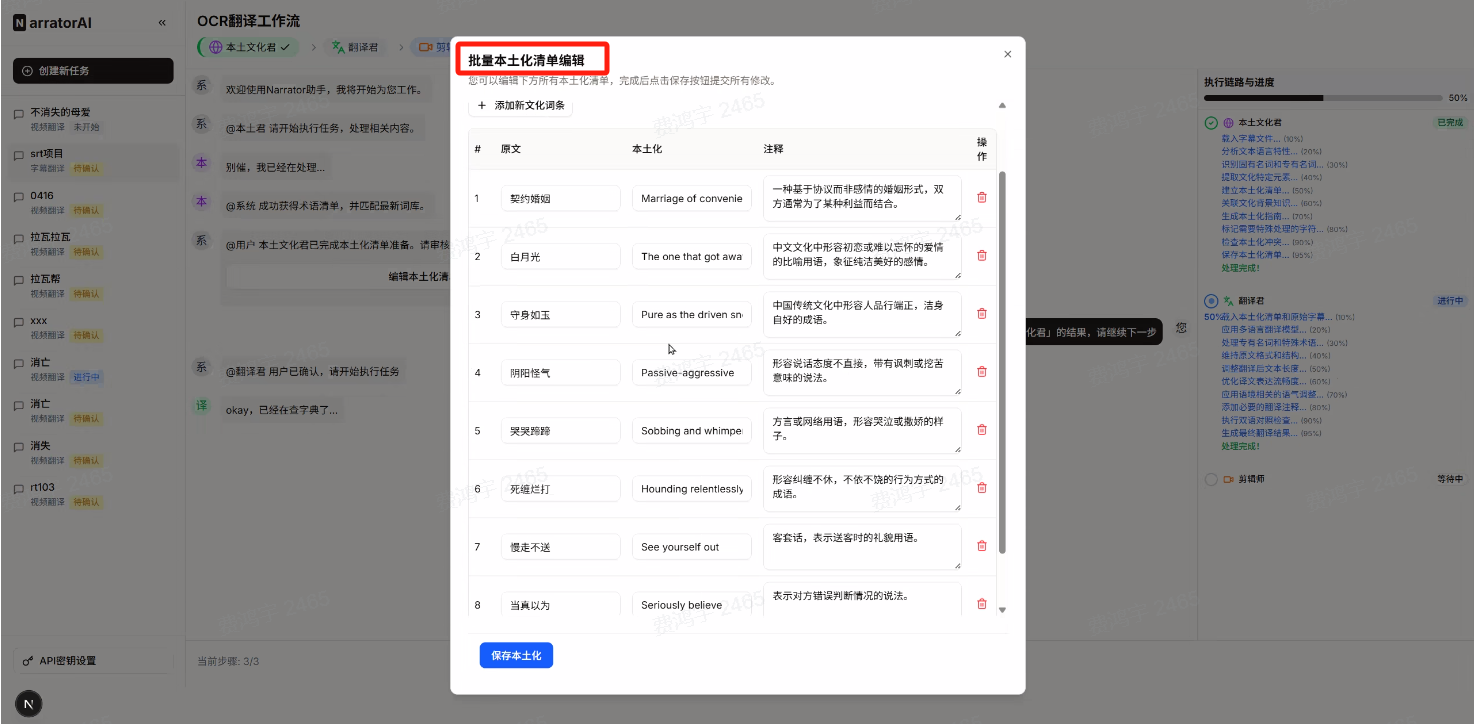
后续版本还将支持 CSV 格式的导入导出,团队可以积累自己的本土化词库,在不同项目之间复用。
五、Agent 3:翻译君------双输入架构与风格模板
翻译君接收两份输入:原始字幕(SRT) + 本土化清单。这是它区别于直接调通用翻译接口的关键------它不是在真空里翻译,而是在有文化上下文的情况下翻译。
翻译君的处理链路:
载入本土化清单和原始字幕(双输入)
→ 应用多语言翻译模型
→ 处理专有名词和特殊术语(优先使用本土化清单中的映射)
→ 维持原文格式和结构(保留时间轴标记)
→ 调整翻译后文本长度(确保字幕不溢出时间窗口)
→ 优化译文表达流畅度
→ 应用语境相关的语气调整(根据风格模板)
→ 添加必要的翻译注释
→ 执行双语对照检查
→ 生成最终翻译结果
翻译风格模板是翻译君的另一个差异化设计。不同的投放平台,观众群体和内容调性不同,翻译风格也应该不同:
-
短剧投流风格:节奏快、情绪强、适合 TikTok 信息流
-
青少年流行语风格:口语化、带网络用语,适合 YouTube Shorts
-
情感类短剧风格:细腻、克制,适合 Instagram
-
古风奇幻风格:保留东方美学意象,适合对中国文化有兴趣的海外受众
-
都市职场风格:正式但不失温度,适合 LinkedIn 系内容
用户也可以用自然语言描述自定义风格,例如:
"面向 TikTok 投放,目标受众是 18-35 岁北美年轻女性,
喜欢 Hallmark 风格的浪漫剧情,翻译要口语化、有情绪张力"
系统会自动匹配对应的润色提示词,不需要用户手写 prompt。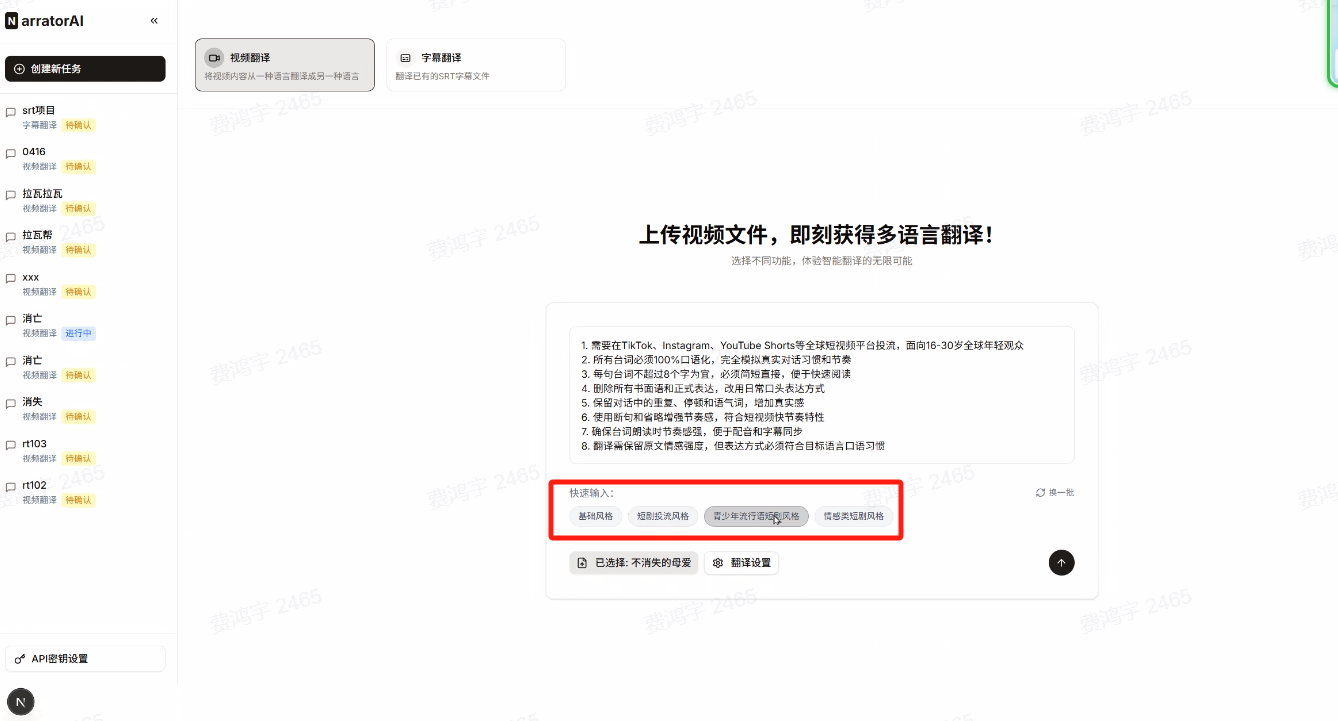
支持 100+ 目标语种,源语言目前支持中文和英文。同一个任务可以同时输出多个目标语种,在 API 参数里体现为 target_languages 数组:
"target_languages": [ {"language": "英语", "area": "美国"}, {"language": "韩文", "area": "韩国"}, {"language": "日语", "area": "日本"}, {"language": "西班牙语", "area": "墨西哥"}, ]
一次任务,四个语种并发输出,不需要跑四次流程。
六、Agent 4:剪辑师------字幕压制与时间轴校准
剪辑师是流水线的最后一道工序,负责把翻译好的字幕"装回"视频。
这个环节看起来简单,实际上有几个工程细节:
时间轴校准。翻译后的文本长度变了,但时间轴是从原始字幕继承来的。剪辑师需要检查每一条字幕的显示时长是否合理------太短的字幕观众来不及读,太长的字幕会和下一条重叠。
字幕样式自定义。不同平台对字幕的视觉要求不同。剪辑师支持配置:
"subtitle_style": { "font_name": "Arial", # 字体"font_size": 40,# 字号(默认40)"font_color": "#FFFFFF",# 字体颜色"bg_color": "#000000",# 背景色"subtitle_position": "bottom"# 位置(bottom/top) }
原始字幕擦除。如果视频里有硬字幕(烧录在画面里的中文字幕),在压制新字幕之前需要先把原始字幕擦除。这是一个独立的处理步骤,对应独立的 API 端点:
POST https://openapi.jieshuo.cn/api/narrator/ai/v1/tasks/erase-subtitle
输出格式。剪辑师支持两种输出:
-
硬字幕成片(字幕烧录进视频,适合直接投放)
-
外挂字幕文件(SRT/ASS 格式,适合需要多语种切换的平台)
七、人机协作:手动确认模式的设计逻辑
NarratorAI 的任务执行有两种模式,通过 auto_run 参数控制:
-
auto_run=1:全自动执行,四个 Agent 依次跑完,直接输出成品 -
auto_run=0:手动确认模式,在关键节点暂停,等待用户审核
手动确认模式下,系统会在以下节点暂停:
-
字幕提取完成后:用户可以校对 OCR 结果,修正识别错误
-
本土化清单生成后:用户可以编辑清单条目,这是最重要的人工干预节点
-
翻译结果生成后:用户可以批量编辑字幕内容
这个设计的逻辑是:AI 负责批量处理,人负责关键决策。对于专业的出海团队来说,本土化清单的审核是不可省略的环节------AI 生成的映射关系可能有 90% 是准确的,但那 10% 的偏差如果出现在关键剧情里,会直接影响海外观众的理解。
手动确认模式的 API 交互流程:
import requests, time API_BASE = "https://openapi.jieshuo.cn" HEADERS = {"Content-Type": "application/json", "APP-KEY": "your_api_key"} 创建任务,开启手动确认模式task = requests.post( f"{API_BASE}/api/narrator/ai/v1/tasks/video-translation", headers=HEADERS, json={ "task_type": "video_translation", "original_language": "中文", "target_languages": [{"language": "英语", "area": "美国"}], "auto_run": 0,# 手动确认模式"style_prompt": "短剧投流风格,面向TikTok年轻观众", "resources": {"file_set_name": "项目名称"}, } ).json() task_id = task["data"]["id"]轮询任务状态,等待节点暂停while True: status = requests.get( f"{API_BASE}/api/narrator/ai/v1/tasks/{task_id}", headers=HEADERS ).json() if status["data"]["status"] == 2:# 暂停,等待确认print("任务暂停,请审核本土化清单") break time.sleep(10)审核并编辑本土化清单(如有需要)requests.post( f"{API_BASE}/api/narrator/ai/v1/videoTasks/update/{task_id}/srt/content", headers=HEADERS, json={"content": "修改后的内容"} )确认继续执行(操作不可逆) requests.post( f"{API_BASE}/api/narrator/ai/v1/confirm/task/flow/{task_id}", headers=HEADERS )
八、开源实现:GitHub 仓库结构与本地部署
NarratorAI 的前端框架完整开源,地址:
开发者可以直接克隆代码、本地部署、审查技术实现。开源的意义不只是"免费",更重要的是可验证性------你可以看到每个 Agent 的实现逻辑,而不是把翻译结果当黑盒接受。
提供从项目创建到视频下载的全链路接口,支持第三方系统集成。
九、架构设计的本质:为什么是流水线而不是单模型?
回到最开始的问题:短剧翻译为什么不能直接调通用翻译接口?
现在可以给出一个更完整的答案:
通用翻译接口是一个单步映射 ,它的能力边界是"语言转换"。短剧出海翻译是一个多步骤工程问题,涉及 OCR 提取、文化适配、语义翻译、时间轴校准、字幕压制五个本质不同的子问题。
把五个不同性质的问题塞进一个模型,要么模型过于复杂难以维护,要么某些子问题被简化处理导致质量下降。流水线架构的价值在于:每个 Agent 只解一个问题,解好一个问题。
本土文化君的存在是这套架构最有价值的设计决策。它把"文化知识"从隐式的模型权重里提取出来,变成显式的、可编辑的结构化数据(本土化清单)。这个设计让人工干预有了明确的介入点,也让翻译质量有了可追溯的改进路径。
这是"AI 工具"和"AI 工作流"之间的本质区别。工具是你调用它,工作流是它和你协作。