详解美团Leaf与百度UidGenerator:分布式ID生成器的工业级实践
作者 :Weisian
发布时间:2026年4月

直击痛点:
"雪花算法时钟回拨导致ID重复,面试官问怎么解决?你说'等待时钟追上',面试官笑了:生产环境每秒几百万请求,等5ms会积压多少请求你知道吗?另一个场景:分库分表后需要严格递增的ID,雪花算法的趋势递增不够用怎么办?------这就是工业级ID生成器要解决的核心问题。"
在上一篇文章中,我们详细剖析了雪花算法的原理和时钟回拨问题。但原生雪花算法在生产环境存在诸多痛点:
- 机器ID难分配:1024个节点需要手动配置,容器化部署时每次重启IP变化;
- 时钟回拨无解:只能等待或抛异常,高并发下不可接受;
- 性能天花板:单机400万QPS虽然高,但百度UidGenerator能做到600万;
- ID连续性:号段模式可做到严格递增,雪花算法只能趋势递增。

美团Leaf 和百度UidGenerator 正是为了解决这些问题而生的工业级方案。本文将从源码级 深度剖析这两个框架的设计精髓:
✅ Leaf号段模式:双Buffer优化、动态步长、DB容灾;
✅ Leaf雪花模式:ZK自动分配机器ID、时钟回拨检测与恢复;
✅ 百度UidGenerator:可配置位数、RingBuffer预生成、600万QPS的秘密;
✅ 两大框架全方位对比:架构、性能、适用场景;
✅ 生产级避坑指南:DB宕机、ZK抖动、RingBuffer拒绝策略;
✅ 高频面试题标准答案(直接背)。
📌 核心一句话 :
美团Leaf提供号段模式 (严格递增、高可用)和雪花模式 (趋势递增、高性能)双方案,用双Buffer和ZK协调解决了原生算法的两大痛点;百度UidGenerator在雪花算法基础上重构,通过RingBuffer预生成 和可配置位数,单机QPS突破600万,是超高并发场景的首选。两者都是生产级分布式ID的首选,Leaf更稳、UidGenerator更快。
📌 面试金句先记牢:
- 原生雪花:时钟回拨会生成重复ID,不可直接上生产;
- Leaf号段模式核心是双Buffer:当前号段用到10%时异步加载下一个号段,切换无感知,TP999延迟<1ms;
- Leaf雪花模式用ZooKeeper存储机器ID和工作时间戳,时钟回拨时根据ZK记录决定是否可用;
- 百度UidGenerator的RingBuffer 预先生成ID,取ID时O(1)时间复杂度,用消费未来时间替代系统时间,彻底不依赖时钟;
- UidGenerator的位数可配置:时间戳28位(秒级)、机器ID22位(支持420万节点)、序列号13位(8192/秒);
- Leaf号段模式4C8G机器QPS≈5万 ,UidGenerator的CachedUidGenerator单机QPS≈600万;
- 容器化部署首选UidGenerator(支持实例重启自动分配机器ID),对有序性要求高选Leaf号段模式。

一、为什么原生方案不能直接上生产?
1.1 原生雪花算法的三大痛点
| 痛点 | 问题描述 | 生产环境后果 |
|---|---|---|
| 机器ID分配 | 10位机器ID需手动配置(0-1023) | 容器化部署时每次重启IP变化,无法自动注册 |
| 时钟回拨 | 依赖系统时间,回拨导致ID重复 | NTP同步、运维误操作时系统崩溃 |
| 性能瓶颈 | 每毫秒4096个ID,约400万QPS | 超高并发场景(双11、秒杀)可能不够用 |
生活类比:原生雪花算法就像一把锋利的刀,但需要你自己磨(配置机器ID)、自己防锈(处理时钟回拨)。而Leaf和UidGenerator是带刀鞘、带磨刀石的"成品刀"------开箱即用。

1.2 工业级方案的核心改进
| 框架 | 核心改进 | 解决痛点 |
|---|---|---|
| 美团Leaf-号段模式 | 双Buffer + 数据库号段 | 严格递增、DB容灾 |
| 美团Leaf-雪花模式 | ZK分配机器ID + 时钟回拨检测 | 机器ID自动分配、时钟回拨可恢复 |
| 百度UidGenerator | RingBuffer预生成 + 可配置位数 | 600万QPS、容器化友好 |
二、美团Leaf号段模式(Leaf-segment)
2.1 核心设计思想
一句话概括:一次从数据库获取一批ID(号段),缓存在本地内存,用完了再去取。用双Buffer优化解决"取号段时卡顿"的问题。
生活类比:你去食堂打饭,一次性领10张饭票(号段),用完了再去窗口领新的。双Buffer就像你手上有两个票本,一本快用完时,食堂阿姨提前把下一本准备好------你永远不会因为"等发票"而饿肚子。
2.2 数据库表结构
sql
-- Leaf号段模式核心表
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT '业务标识(订单、用户等)',
`max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT '当前已分配的最大ID',
`step` int(11) NOT NULL COMMENT '号段步长(每次获取多少个ID)',
`description` varchar(256) DEFAULT NULL COMMENT '业务描述',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 初始化订单号段
INSERT INTO leaf_alloc(biz_tag, max_id, step, description)
VALUES('order', 1, 2000, '订单ID生成器');字段说明:
biz_tag:不同业务隔离使用,如order、user、productmax_id:当前已经分配出去的最大ID(下次从这里开始)step:每次获取号段的大小,默认2000
2.3 双Buffer机制(核心优化)
问题:如果没有双Buffer,号段用完的那一刻去数据库取新号段,所有请求必须阻塞等待,TP999指标会瞬间飙升。
解决方案:Leaf在内存中维护两个Segment(号段缓冲区),当前号段用到10%时,异步加载下一个号段到备用Buffer。
核心原理:
- 数据库表存储号段配置(biz_tag、max_id、step);
- 服务启动时,批量获取一个号段(如
1~2000); - 本地内存自增发号,号段耗尽时异步更新数据库获取新号段;
- 双Buffer缓冲,解决号段切换毛刺。

java
/**
* Leaf号段模式核心实现(简化版)
*/
public class LeafSegmentService {
// 双Buffer结构:每个biz_tag对应一个SegmentBuffer
private final Map<String, SegmentBuffer> cache = new ConcurrentHashMap<>();
/**
* 号段缓冲区(双Buffer核心)
*/
static class SegmentBuffer {
private Segment current; // 当前使用的号段
private Segment next; // 下一个号段(异步加载)
private volatile boolean nextReady; // 下一个号段是否就绪
private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
public SegmentBuffer(String bizTag, int step) {
this.current = loadSegment(bizTag, step);
this.nextReady = false;
}
/**
* 获取ID(核心方法)
*/
public long getId() {
lock.readLock().lock();
try {
// 1. 从当前号段取ID
long id = current.nextId();
// 2. 检查是否需要异步加载下一个号段(当前号段使用超过90%)
if (current.getRemainPercent() < 10 && !nextReady) {
// 异步加载下一个号段(避免阻塞)
asyncLoadNext();
}
return id;
} finally {
lock.readLock().unlock();
}
}
/**
* 异步加载下一个号段
*/
private void asyncLoadNext() {
// 防止重复加载
if (nextReady) return;
ThreadPoolFactory.getAsyncPool().submit(() -> {
lock.writeLock().lock();
try {
if (!nextReady) {
// 从数据库加载新号段到next
next = loadSegment(bizTag, step);
nextReady = true;
}
} finally {
lock.writeLock().unlock();
}
});
}
/**
* 切换号段(当前号段用完时调用)
*/
public void switchSegment() {
lock.writeLock().lock();
try {
if (nextReady) {
current = next;
nextReady = false;
// 异步加载新的next
asyncLoadNext();
} else {
// 降级:同步加载
current = loadSegment(bizTag, step);
}
} finally {
lock.writeLock().unlock();
}
}
}
/**
* 从数据库加载号段(使用乐观锁)
*/
private Segment loadSegment(String bizTag, int step) {
// 使用乐观锁更新数据库
String updateSql = "UPDATE leaf_alloc SET max_id = max_id + ?, update_time = NOW() " +
"WHERE biz_tag = ? AND max_id = ?";
String selectSql = "SELECT max_id, step FROM leaf_alloc WHERE biz_tag = ?";
int retry = 3;
while (retry-- > 0) {
// 1. 查询当前max_id
Map<String, Object> row = jdbcTemplate.queryForMap(selectSql, bizTag);
long oldMaxId = (Long) row.get("max_id");
int dbStep = (Integer) row.get("step");
// 2. CAS更新
int updated = jdbcTemplate.update(updateSql, dbStep, bizTag, oldMaxId);
if (updated > 0) {
// 更新成功,返回号段 [oldMaxId + 1, oldMaxId + step]
return new Segment(oldMaxId + 1, oldMaxId + dbStep);
}
// 更新失败,重试
}
throw new RuntimeException("加载号段失败,bizTag=" + bizTag);
}
/**
* 号段(内存中的ID池)
*/
static class Segment {
private final long start; // 起始ID
private final long end; // 结束ID
private AtomicLong current; // 当前已分配的ID
public Segment(long start, long end) {
this.start = start;
this.end = end;
this.current = new AtomicLong(start);
}
public long nextId() {
long id = current.getAndIncrement();
if (id > end) {
throw new RuntimeException("号段已用完");
}
return id;
}
public int getRemainPercent() {
long remain = end - current.get();
long total = end - start;
return (int) (remain * 100 / total);
}
}
}2.4 动态步长调整
Leaf还能根据历史消费速度动态调整步长(step),让号段消耗周期维持在一个合理区间:
java
/**
* 动态步长调整逻辑
*/
public class DynamicStepAdjuster {
// 配置参数
private static final long SPEED_FAST_THRESHOLD = 15 * 60 * 1000; // 15分钟
private static final long SPEED_SLOW_THRESHOLD = 30 * 60 * 1000; // 30分钟
private static final int MAX_STEP = 100000; // 最大步长
private static final int MIN_STEP = 1000; // 最小步长
/**
* 根据消耗速度调整步长
* @param lastCostTime 上一轮号段消耗耗时(毫秒)
* @param currentStep 当前步长
*/
public int adjustStep(long lastCostTime, int currentStep) {
if (lastCostTime < SPEED_FAST_THRESHOLD) {
// 消耗太快(<15分钟),流量大,加倍获取
int newStep = currentStep * 2;
System.out.println("流量增大,步长翻倍:" + currentStep + " -> " + newStep);
return Math.min(newStep, MAX_STEP);
} else if (lastCostTime > SPEED_SLOW_THRESHOLD) {
// 消耗太慢(>30分钟),流量小,减半获取
int newStep = currentStep / 2;
System.out.println("流量减小,步长减半:" + currentStep + " -> " + newStep);
return Math.max(newStep, MIN_STEP);
}
return currentStep;
}
}
2.5 号段模式优缺点
| 优点 | 缺点 |
|---|---|
| ✅ 严格递增,对MySQL索引友好 | ❌ ID连续,可能泄露业务量信息 |
| ✅ 有本地缓存,DB宕机可继续服务10-20分钟 | ❌ 强依赖DB,DB彻底不可用时服务终将中断 |
| ✅ 性能高,4C8G机器QPS≈5万,TP999<1ms | ❌ 需要维护数据库表 |
| ✅ 水平扩展方便,增加Leaf节点即可 | ❌ ID不够随机,安全性稍差 |
三、美团Leaf雪花模式(Leaf-snowflake)
3.1 核心改进:ZK自动分配机器ID + 时钟回拨检测
原生雪花算法最大的两个问题是:机器ID手动配置麻烦、时钟回拨无解。Leaf-snowflake用ZooKeeper同时解决了这两个问题。
生活类比:ZK就像公司的"人事部",每个新员工(Leaf节点)入职时去人事部登记,拿到唯一的工号(workerId)。人事部还记录每个员工的上次打卡时间,如果有人把钟表往回拨,人事部会检测到异常并阻止他上班。

3.2 架构图
┌─────────────────────────────────────────────────────────────┐
│ ZooKeeper集群 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ /leaf_forever/{ip:port} → {workerId, timestamp} │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Leaf节点1 │ │ Leaf节点2 │ │ Leaf节点3 │
│ workerId=1│ │ workerId=2│ │ workerId=3│
└──────────┘ └──────────┘ └──────────┘3.3 机器ID自动分配(ZK持久节点)
java
/**
* Leaf雪花模式 - ZK机器ID分配器
*/
public class SnowflakeZookeeperHolder {
private static final String PATH_FOREVER = "/snowflake/leaf_forever";
private ZooKeeper zk;
private String ip;
private int port;
private int workerId;
/**
* 初始化:从ZK获取或创建workerId
*/
public void init() {
String path = PATH_FOREVER + "/" + ip + ":" + port;
try {
// 1. 检查节点是否已存在
if (zk.exists(path, false) != null) {
// 已存在,读取workerId
byte[] data = zk.getData(path, false, null);
String dataStr = new String(data);
this.workerId = extractWorkerId(dataStr);
// 检查ZK中记录的时间戳
long lastTimestamp = extractTimestamp(dataStr);
long currentTime = System.currentTimeMillis();
if (currentTime < lastTimestamp) {
// 时钟回拨!启动失败
throw new RuntimeException(
String.format("时钟回拨检测失败!ZK记录时间=%d,本地时间=%d,offset=%d",
lastTimestamp, currentTime, lastTimestamp - currentTime));
}
} else {
// 2. 不存在,创建顺序节点,获取workerId
String createdPath = zk.create(path,
buildNodeData().getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL); // 临时顺序节点
// 从路径中提取顺序号作为workerId
this.workerId = extractSequenceFromPath(createdPath);
}
// 3. 启动定时任务:每3秒上报一次当前时间到ZK
ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();
executor.scheduleAtFixedRate(() -> {
try {
String newData = buildNodeData(); // 包含当前时间戳
zk.setData(path, newData.getBytes(), -1);
} catch (Exception e) {
// 上报失败,记录日志
System.err.println("上报时间到ZK失败:" + e.getMessage());
}
}, 3, 3, TimeUnit.SECONDS);
} catch (Exception e) {
throw new RuntimeException("ZK初始化失败", e);
}
}
/**
* 构建节点数据:workerId + 当前时间戳
*/
private String buildNodeData() {
return workerId + ":" + System.currentTimeMillis();
}
/**
* 弱依赖ZK的设计:本地文件缓存workerId
* 即使ZK宕机,重启也能从文件恢复workerId
*/
private void cacheWorkerIdToLocal() {
File cacheFile = new File("/tmp/leaf_workerId.cache");
try (FileWriter writer = new FileWriter(cacheFile)) {
writer.write(String.valueOf(workerId));
} catch (IOException e) {
// 缓存失败不影响主流程
}
}
}3.4 时钟回拨解决方案
Leaf通过ZooKeeper彻底解决时钟回拨:
- WorkerId分配 :ZK持久节点自动分配
dataCenterId+workerId,保证唯一; - 最大时间戳记录 :ZK临时节点存储每台机器的历史最大生成时间戳;
- 启动校验 :服务启动时,若当前系统时间 < ZK记录的最大时间戳,直接拒绝启动,强制报警;
- 运行时防护:生成ID时实时校验,回拨则拒绝生成。
java
/**
* Leaf雪花模式 - 时钟回拨处理
*/
public class LeafSnowflakeIdGenerator {
private long lastTimestamp = -1L;
private SnowflakeZookeeperHolder zkHolder;
public synchronized long nextId() {
long currentTimestamp = System.currentTimeMillis();
// ============ 第一层:启动时检查 ============
// 在init()阶段已经对比过本地时间 vs ZK记录时间
// ============ 第二层:运行时检查 ============
if (currentTimestamp < lastTimestamp) {
long offset = lastTimestamp - currentTimestamp;
if (offset <= 5) {
// 轻微回拨(≤5ms):等待时钟追上
try {
wait(offset * 2); // 等待2倍时间
currentTimestamp = System.currentTimeMillis();
if (currentTimestamp < lastTimestamp) {
// 等待后仍然异常,抛异常
throw new ClockBackException("时钟回拨严重");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("等待被中断");
}
} else {
// ============ 第三层:严重回拨 ============
// 获取集群中其他节点的时间,判断是否整体回拨
long avgTimestamp = zkHolder.getAverageTimestamp();
if (Math.abs(currentTimestamp - avgTimestamp) > 10) {
// 本机时间与其他节点差异超过10ms,启动失败
throw new ClockBackException(
String.format("本机时间异常!本地=%d,集群平均=%d",
currentTimestamp, avgTimestamp));
}
// 否则等待
try {
wait(offset);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 正常生成ID逻辑...
if (currentTimestamp == lastTimestamp) {
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
currentTimestamp = waitNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = currentTimestamp;
return ((currentTimestamp - START_EPOCH) << TIMESTAMP_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}
}3.5 雪花模式优缺点
| 优点 | 缺点 |
|---|---|
| ✅ 无需数据库,纯内存计算 | ❌ 需要引入ZooKeeper组件 |
| ✅ 机器ID自动分配,容器化友好 | ❌ 趋势递增,不是严格递增 |
| ✅ 时钟回拨有完善的处理机制 | ❌ 对ZK有弱依赖(ZK宕机仍可运行) |
| ✅ 性能高,QPS≈5万+ | ❌ 时钟回拨超过阈值仍会抛异常 |
四、百度UidGenerator
4.1 核心设计思想
UidGenerator是百度开源的高性能分布式ID生成器,在雪花算法基础上做了两大革命性改进:
- 可配置位数:根据业务场景自由调整时间戳、机器ID、序列号的位数
- RingBuffer预生成:用环形缓冲区提前生成ID,取ID时O(1)时间复杂度
官方数据 :单机QPS可达6,000,000(600万)。
生活类比:传统雪花算法是"现点现做"的餐厅------来一个客人做一份菜;UidGenerator是"自助餐"------提前把所有菜做好放在取餐区,客人来了直接拿,所以速度极快。
UidGenerator最大创新:不直接使用系统时间 ,而是使用虚拟时间(delta seconds),从服务启动时间开始自增,彻底摆脱对系统时钟的依赖。

4.2 可配置的位数设计
原生雪花算法位数是固定的(41-10-12),UidGenerator允许自定义:
默认分配方案(可配置):
┌───┬──────────────────────────┬─────────────────────┬─────────────┐
│ 1 │ 28位时间戳 │ 22位机器ID │ 13位序列号 │
│符号│ (秒级) │ (支持420万节点) │ (8192/秒) │
└───┴──────────────────────────┴─────────────────────┴─────────────┘配置示例:
yaml
# Spring配置
uid:
timeBits: 28 # 时间戳位数(秒级),可用8.5年
workerBits: 22 # 机器ID位数,支持419万次启动
seqBits: 13 # 序列号位数,每秒8192个ID
epochStr: "2024-01-01" # 起始时间为什么时间戳用秒而不是毫秒?
- 秒级时间戳28位可用8.5年,毫秒级41位可用69年
- 牺牲了部分可用年限,换来了更多位数分配给机器ID(22位 vs 10位)
- 适合容器化部署场景(实例频繁重启,需要更多机器ID位)
4.3 两种实现:DefaultUidGenerator vs CachedUidGenerator
UidGenerator提供两种实现:
| 实现 | 特点 | QPS | 适用场景 |
|---|---|---|---|
| DefaultUidGenerator | 同步计算,每次实时生成 | ~100万 | 一般高并发场景 |
| CachedUidGenerator | RingBuffer预生成,异步填充 | ~600万 | 超高并发、秒杀场景 |
4.4 RingBuffer核心原理(重点)
CachedUidGenerator是UidGenerator的精髓,用RingBuffer预先生成ID,彻底解决并发瓶颈。
java
/**
* 百度UidGenerator - RingBuffer核心实现(简化版)
*/
public class CachedUidGenerator {
// RingBuffer:环形数组,预先生成ID
private final RingBuffer ringBuffer;
// 填充因子:当剩余ID低于此百分比时,触发异步填充
private final int paddingFactor = 50; // 默认50%
// 扩容因子:RingBuffer初始大小 = 2^13 = 8192,扩容后 = 8192 << boostPower
private final int boostPower = 3; // 扩容后 8192 * 8 = 65536
public CachedUidGenerator() {
int bufferSize = 1 << (13 + boostPower); // 65536个槽位
this.ringBuffer = new RingBuffer(bufferSize);
// 初始化:预先生成bufferSize个ID填满RingBuffer
initRingBuffer();
}
/**
* 初始化RingBuffer:预先生成所有ID
*/
private void initRingBuffer() {
for (int i = 0; i < ringBuffer.capacity(); i++) {
long uid = generateUid(); // 调用雪花算法生成ID
ringBuffer.put(i, uid);
}
// 启动异步填充线程
startPaddingThread();
}
/**
* 获取ID(核心:O(1)时间复杂度)
*/
public long getUID() {
return ringBuffer.take();
}
/**
* RingBuffer核心实现
*/
class RingBuffer {
private final long[] slots; // 存储ID的数组
private final AtomicLong cursor = new AtomicLong(-1L); // 消费指针
private final AtomicLong tail = new AtomicLong(-1L); // 生产指针
private final int bufferSize;
private final int mask; // 用于位运算替代取模(高性能)
public RingBuffer(int bufferSize) {
this.bufferSize = bufferSize;
this.mask = bufferSize - 1; // 因为bufferSize是2的幂
this.slots = new long[bufferSize];
}
/**
* 取ID(消费者)
*/
public long take() {
long currentCursor = cursor.incrementAndGet();
int slotIndex = (int) (currentCursor & mask);
// 检查是否追上了生产指针(RingBuffer已空)
if (currentCursor > tail.get()) {
throw new RuntimeException("RingBuffer已空,无可用ID");
}
return slots[slotIndex];
}
/**
* 填充ID(生产者)- 异步调用
*/
public void fill() {
long currentTail = tail.get();
long nextTail = currentTail + bufferSize; // 填充一整轮
for (long i = currentTail + 1; i <= nextTail; i++) {
int slotIndex = (int) (i & mask);
slots[slotIndex] = generateUid(); // 实时生成新ID
}
tail.set(nextTail);
}
/**
* 检查是否需要填充(剩余容量 < paddingFactor%)
*/
public boolean needPadding() {
long available = tail.get() - cursor.get();
long remainPercent = available * 100 / bufferSize;
return remainPercent < paddingFactor;
}
}
/**
* 异步填充线程:当RingBuffer剩余ID不足时,自动填充
*/
private void startPaddingThread() {
ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();
executor.scheduleAtFixedRate(() -> {
if (ringBuffer.needPadding()) {
// 异步填充,不阻塞取ID的线程
ringBuffer.fill();
}
}, 1, 1, TimeUnit.MILLISECONDS);
}
}4.5 解决时钟回拨的创新方式
UidGenerator解决时钟回拨的方式非常巧妙:用消费未来时间替代系统时间。
- 如果系统时间大于最新记录时间,按照系统时间正常分配。
- 如果系统时间小于最新记录时间(时钟回拨),按照最大记录时间+1秒,消费未来时间。
java
/**
* 百度UidGenerator - 消费未来时间
*/
public class FutureTimeConsumer {
// 不使用System.currentTimeMillis(),而是用AtomicLong自增
private final AtomicLong lastSecond = new AtomicLong();
/**
* 获取当前时间(秒级)
* 核心:从lastSecond获取,而不是从系统时间
*/
private long getCurrentSecond() {
long currentSecond = System.currentTimeMillis() / 1000;
long lastSecondValue = lastSecond.get();
if (currentSecond < lastSecondValue) {
// 时钟回拨了!但我们不依赖系统时间
// 直接使用上一次的时间+1(消费未来时间)
return lastSecond.incrementAndGet();
} else if (currentSecond > lastSecondValue) {
// 时间正常前进
lastSecond.set(currentSecond);
return currentSecond;
}
// 同一秒内
return currentSecond;
}
}关键点:UidGenerator生成ID中的时间戳可能"快进"到未来时间,但这不影响唯一性,只是ID中的时间字段不精确而已。
4.6 伪共享问题与CacheLine填充
UidGenerator还解决了一个底层性能问题:伪共享(False Sharing)。
在多核CPU中,L1/L2/L3缓存以"缓存行"(Cache Line,通常64字节)为单位加载。如果多个变量在同一个缓存行中,不同核心修改不同变量会导致缓存行反复失效。

java
/**
* 百度UidGenerator - 避免伪共享
*/
@sun.misc.Contended // Java 8的注解,在字段前后填充空白,确保独占缓存行
public class PaddedAtomicLong {
public volatile long value;
// 通过@Contended注解,JVM会在这个字段前后填充128字节
// 确保不同的AtomicLong不在同一个缓存行中
}4.7 数据库WorkerId分配
sql
-- UidGenerator WorkerId分配表
CREATE TABLE WORKER_NODE (
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT '自增ID,作为workerId',
HOST_NAME VARCHAR(64) NOT NULL COMMENT '主机名',
PORT VARCHAR(64) NOT NULL COMMENT '端口',
TYPE INT NOT NULL COMMENT '节点类型',
LAUNCH_DATE DATE NOT NULL COMMENT '启动日期',
MODIFIED TIMESTAMP NOT NULL COMMENT '修改时间',
CREATED TIMESTAMP NOT NULL COMMENT '创建时间',
PRIMARY KEY(ID)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;每次实例启动时,向这张表插入一条记录,返回的自增ID就是workerId。用完即弃,不回收,所以22位(419万次)理论上足够。
五、全方位对比:Leaf vs UidGenerator vs 原生雪花
| 对比维度 | 原生雪花 | 美团Leaf-号段 | 美团Leaf-雪花 | 百度UidGenerator |
|---|---|---|---|---|
| ID类型 | 趋势递增 | 严格递增 | 趋势递增 | 趋势递增 |
| 机器ID分配 | 手动配置 | 无需(DB号段) | ZK自动分配 | DB自动分配 |
| 时钟回拨解决 | 无(抛异常) | 不涉及 | 检测+等待+ZK协调 | 消费未来时间 |
| 外部依赖 | 无 | 数据库 | ZooKeeper | 数据库(仅WorkerId) |
| 单机QPS | ~400万 | ~5万 | ~5万+ | ~600万 |
| ID长度 | 64位 | 64位 | 64位 | 64位(可配置) |
| 容器化友好 | ❌ | ✅ | ✅ | ✅ |
| 运维复杂度 | 低 | 中 | 高(需ZK) | 中 |
| 适用场景 | 中小规模 | 金融、订单 | 通用分布式 | 超高并发、容器化 |

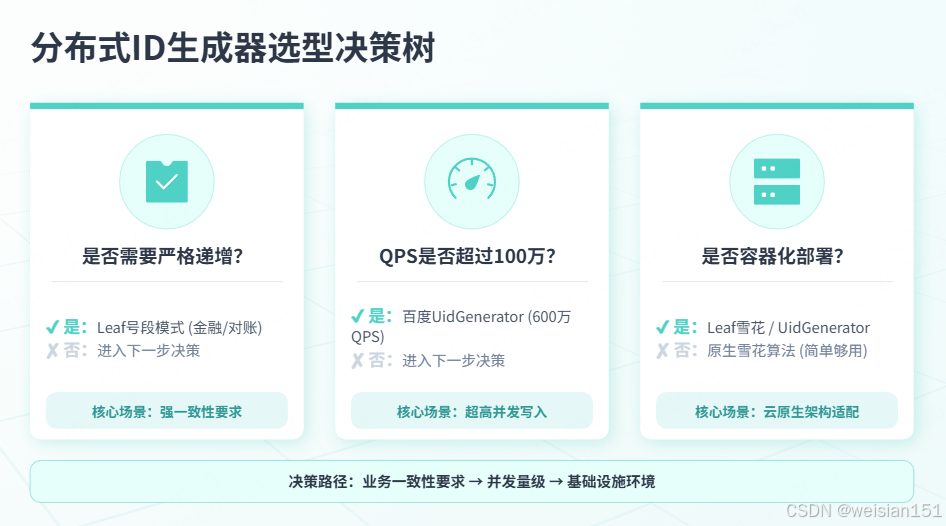
选型建议:
┌─────────────────────────────────────────────────────────────────┐
│ 选型决策树 │
├─────────────────────────────────────────────────────────────────┤
│ 是否需要严格递增? │
│ ├─ 是 → Leaf号段模式(金融、订单、对账场景) │
│ └─ 否 → 继续 │
│ │ │
│ ▼ │
│ QPS是否超过100万? │
│ ├─ 是 → 百度UidGenerator(RingBuffer预生成,600万QPS) │
│ └─ 否 → 继续 │
│ │ │
│ ▼ │
│ 是否容器化部署? │
│ ├─ 是 → Leaf雪花模式 或 UidGenerator(都支持自动分配机器ID) │
│ └─ 否 → 原生雪花算法(简单够用) │
└─────────────────────────────────────────────────────────────────┘
六、生产级避坑指南
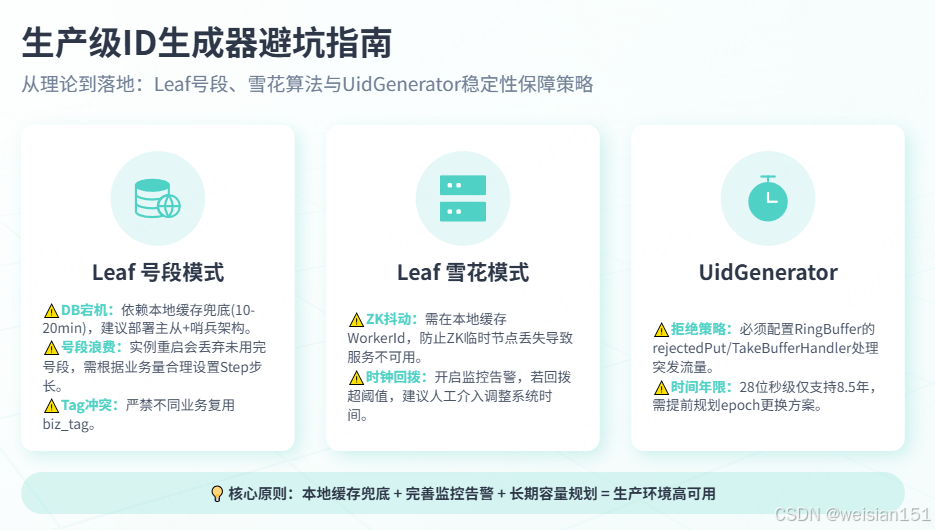
6.1 Leaf号段模式避坑
| 问题 | 解决方案 |
|---|---|
| DB宕机 | 号段缓存在本地,可继续服务10-20分钟;部署DB主从+哨兵 |
| 号段浪费 | 实例重启会丢弃未用完的号段,设置合理的step(如2000) |
| biz_tag冲突 | 不同业务必须用不同biz_tag,否则ID会乱序 |
| 乐观锁重试 | 高并发下CAS可能失败,设置重试次数(默认3次) |
6.2 Leaf雪花模式避坑
| 问题 | 解决方案 |
|---|---|
| ZK抖动 | 本地缓存workerId,ZK临时节点丢失后可恢复 |
| 时钟回拨超阈值 | 配置监控告警,人工介入调整系统时间 |
| workerId耗尽 | 10位最多1024节点,大型集群需扩展位数或使用号段模式 |
6.3 UidGenerator避坑
| 问题 | 解决方案 |
|---|---|
| RingBuffer拒绝策略 | 配置rejectedPutBufferHandler和rejectedTakeBufferHandler |
| 时间戳可用年限 | 28位秒级只够8.5年,提前规划更换epoch |
| workerId耗尽 | 22位支持419万次启动,用完可重置DB表 |
| 伪共享 | 使用@sun.misc.Contended注解确保缓存行对齐 |
七、面试高频真题(标准答案直接背)
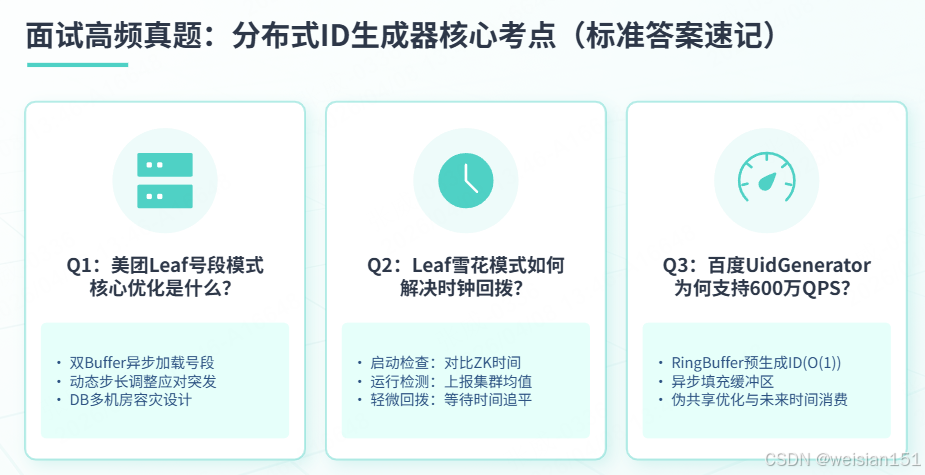
7.1 基础必答
Q1:美团Leaf号段模式的核心优化是什么?
答案:
- 双Buffer机制:当前号段用到10%时异步加载下一个号段,切换无感知,避免"取号段时卡顿";
- 动态步长调整:根据消费速度自动调整step(快则加倍,慢则减半),让号段消耗周期维持合理区间;
- DB容灾:号段缓存在本地,DB宕机可继续服务10-20分钟;
- 性能表现:4C8G机器QPS≈5万,TP999延迟<1ms。
Q2:Leaf雪花模式如何解决时钟回拨?
答案:
- 启动时检查:对比本地时间与ZK记录时间,若本地时间小于ZK记录(发生回拨),启动失败;
- 运行时检测:每3秒上报本机时间到ZK,获取集群平均时间,若本机时间差异超过阈值,拒绝服务;
- 轻微回拨容忍:回拨≤5ms时等待时钟追上;
- 弱依赖ZK:本地缓存workerId,ZK宕机不影响已启动实例。
Q3:百度UidGenerator为什么能支持600万QPS?
答案:
- RingBuffer预生成:提前生成大量ID存储在环形缓冲区,取ID时O(1)时间复杂度,无需实时计算;
- 异步填充:通过后台线程异步填充RingBuffer,不阻塞取ID请求;
- 伪共享优化 :使用
@Contended注解避免缓存行伪共享; - 时间以秒为单位:减少序列号竞争,每秒8192个并发,通过消费未来时间解决时钟回拨。
7.2 深度追问
Q4:Leaf的双Buffer具体怎么工作?
答案:
- 内存中维护两个Segment:current(当前使用)和next(备用);
- 当current消耗达到10%时,异步线程从DB加载新号段到next;
- current用完时,直接切换current=next,nextReady=false;
- 切换后立即异步加载下一个号段到next;
- 整个过程对业务无感知,切换时间<1ms。
Q5:UidGenerator的RingBuffer如果满了会怎样?
答案:
- 可配置拒绝策略:
rejectedPutBufferHandler(生产满)和rejectedTakeBufferHandler(消费空); - 默认策略:记录日志并抛出
UidGenerateException; - 生产建议:增大RingBuffer容量(通过
boostPower参数,如设3则容量=8192×8=65536),提高填充频率。
Q6:Leaf号段模式和UidGenerator如何选择?
答案:
- 严格递增需求(金融、订单):选Leaf号段模式;
- 超高并发需求(QPS>100万):选UidGenerator;
- 容器化部署(频繁重启):UidGenerator更友好(22位workerId);
- 不想引入新组件:原生雪花算法;
- 综合推荐:大多数场景Leaf号段模式足够,追求极致性能用UidGenerator。
Q7:对比原生雪花、Leaf、UidGenerator的时钟回拨处理?
答案:
- 原生雪花:无处理,回拨直接生成重复ID;
- 美团Leaf:ZK记录最大时间戳,启动+运行时双重校验,回拨拒绝生成;
- 百度UidGenerator :虚拟时间,彻底免疫时钟回拨,无需处理。
总结
1. 核心知识点速记口诀
美团Leaf双模式,号段雪花都支持。
号段双Buffer优化,当前用完next接上。
动态步长自适应,快加倍来慢减半。
雪花模式用ZK,机器ID自动拿。
时钟回拨三重检,启动运行时都查。
百度Uid更激进,RingBuffer预生成。
位数可配按需调,秒级时间省位数。
二十二位机器码,容器重启不怕它。
六百万QPS真强悍,超高并发首选它。2. 核心要点回顾
- Leaf号段模式:双Buffer + 动态步长,严格递增,QPS≈5万;
- Leaf雪花模式:ZK分配workerId + 时钟回拨检测,QPS≈5万+;
- UidGenerator:RingBuffer预生成 + 可配置位数,虚拟时间彻底免疫时钟回拨,轻量高性能,QPS≈600万;
- 选型原则:严格递增用Leaf号段,超高并发用UidGenerator,通用场景用Leaf雪花。
3. 实战建议
- 金融订单系统:Leaf号段模式(严格递增,对账友好);
- 秒杀系统:UidGenerator(600万QPS,RingBuffer预生成);
- 微服务通用:Leaf雪花模式(ZK自动分配,运维友好);
- 中小项目:原生雪花算法(简单够用)。
写在最后
从Twitter开源的雪花算法,到美团的Leaf,再到百度的UidGenerator,分布式ID生成器的演进史就是一部"解决生产环境痛点"的历史。
原生雪花算法解决了"本地生成、高性能、趋势递增"的问题,但留下了"机器ID分配、时钟回拨"的坑。Leaf用ZK填了这些坑,同时提供了号段模式满足严格递增需求。而UidGenerator则在性能这条路上走到了极致------RingBuffer预生成、可配置位数、600万QPS。
记住:没有最好的方案,只有最适合场景的方案。在面试中,能完整对比这三个方案的优劣,并给出选型建议,是架构师能力的体现。
如果觉得有帮助,欢迎点赞、收藏、转发!