目录
[COW 的核心工作机制](#COW 的核心工作机制)
[1. 正常拷贝 vs COW 拷贝](#1. 正常拷贝 vs COW 拷贝)
[2. 触发分离的时机](#2. 触发分离的时机)
[3. 关键技术支撑](#3. 关键技术支撑)
[C++ 精简版 COW 手动实现](#C++ 精简版 COW 手动实现)
[1. 设计思路](#1. 设计思路)
[2. 代码实现步骤](#2. 代码实现步骤)
[3. 代码演示](#3. 代码演示)
[4. 多线程安全考量](#4. 多线程安全考量)
[实现二:使用 std::shared_ptr 封装](#实现二:使用 std::shared_ptr 封装)
[1. 设计思路](#1. 设计思路)
[2. 代码演示](#2. 代码演示)
[1. 操作系统进程管理](#1. 操作系统进程管理)
[2. 虚拟化与容器](#2. 虚拟化与容器)
[3. COW 文件系统的代表](#3. COW 文件系统的代表)
[COW 的代价与适用边界](#COW 的代价与适用边界)
[1. 性能代价](#1. 性能代价)
[2. 实现复杂度](#2. 实现复杂度)
[3. 何时不该用 COW](#3. 何时不该用 COW)
COW(Copy-on-Write, 写时复制)一种将昂贵的复制 操作推迟到真正需要写入时才执行的优化策略。
它是延迟计算思想在内存和资源管理领域的一种特化应用。两者都遵循"不到万不得已,不做昂贵之事"的原则。
COW 的核心工作机制
1. 正常拷贝 vs COW 拷贝
- 正常拷贝:立即分配新内存,复制全部数据(时间复杂度 O(N))。
就像我手里有一本《C++ 从入门到入土》,你说你想看,好,我二话不说立马跑到打印店花钱给你打印一本,就算你在这本书上画个小王八,那都跟我没任何关系。
代价:花钱(内存)、花时间(CPU),就为了个万一我们用不着的改动。
- COW 拷贝:仅复制指针和增加引用计数(时间复杂度 O(1)),内存中只有一份数据。
过会儿我手里又有一本《C++ 从入土到刨坟》,你又想看,这次我开窍了,用手机直接给你发一个共享链接,我们一起看一份 PDF。
这时候引用计数 = 2,内存还是那一份。你翻页、查看内容(只读操作),我俩相安无事,速度快得飞起。
精髓:只要你不改,我们就是异父异母的亲兄弟。
2. 触发分离的时机
这是 COW 机制最坑爹的地方,分水岭就在于 const。
触发分离的信号:
当我们调用了一个非 const 成员函数时,比如 operator\[\](用作左值修改)、iterator begin() 且解引用修改,或者 .push_back()。
底层逻辑的内心独白是:
"哎呦喂,这小子想画个小王八?大事不好啦!这 PDF 是大家公用的,不能让他瞎涂。"
这时候就需要深度拷贝:
-
看计数器:if (ref_count > 1),这就有人共享
-
分配新内存: new charcapacity。
-
复制原数据:memcpy 把老数据原封不动复制一份。
-
断舍离:把当前对象的指针指向新内存,老共享区的 ref_count--,新内存的 ref_count = 1。
-
在新副本上修改:你改你的,别人看别人的,世界和平。
3. 关键技术支撑
要想 COW 玩的转,就得保证这些玩意正常:
原子引用计数
-
干嘛的:记录现在有几个对象在共享这块数据。
-
必须是线程安全的原子操作,否则多线程下计数器崩了,就是内存泄漏或双重释放的主场了。
数据的私有封装
-
结构长这样: RefCount (4字节) \| Data (N字节)
-
或者更骚的操作是侵入式(把计数塞进数据头里),亦或者非侵入式(std::shared_ptr 那种独立控制块)。
延迟分配策略
-
绝不主动揽活,能拖就拖。
-
如果我们只是预留空间就不必分离,只有真的往里 memset 写入时,发现这是共享的才进行分离。
C++ 精简版 COW 手动实现
理论完了,就得来点实操。
1. 设计思路
-
引用计数:记录现在有几个人在用。
-
数据:真正的字符数组。
-
关键逻辑:谁想修改数据,先看看锁上显示是不是只有一个,如果不是,赶紧复制一份出来,不动公用的。
一个简单的数据结构示意图:
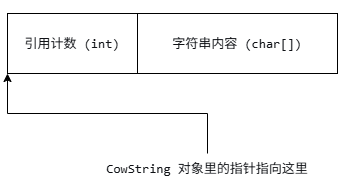
2. 代码实现步骤
-
定义内部存储结构 Rep:包含引用计数和数组。
-
构造函数:分配内存时会多申请 4 字节放计数,指针指向数据区。
-
拷贝构造:不加锁,只加计数。把指针指过去,ref_count++。
-
写时复制分离函数 detach():任何非 const 操作进来先喊它一声。
-
析构函数:ref_count--,如果归零了,与 Rep 一起回收。
3. 代码演示
cpp
class CowString
{
private:
// 这就是共享的控制块 + 数据块,粘在一起分配
struct Rep
{
std::atomic<int> ref_count; // 原子计数
char data[1]; // 占位用的,虽然未初始化,但在这里问题不大
static Rep* create(const char* str)
{
size_t len = strlen(str);
// 分配内存:Rep 结构体大小 + 字符串长度
void* raw = operator new(sizeof(Rep) + len);
Rep* rep = new(raw) Rep();
rep->ref_count = 1; // 初始为一
memcpy(rep->data, str, len + 1);
return rep;
}
void destroy()
{
this->~Rep();
operator delete(this);
}
};
Rep* rep; // 指向共享数据区
public:
// 构造函数
CowString(const char* str = "") : rep(Rep::create(str)) {}
// 拷贝构造
CowString(const CowString& other) : rep(other.rep)
{
++rep->ref_count; // 原子加一
}
// 赋值操作
CowString& operator=(const CowString& other)
{
if (this != &other)
{
// 减引用
if (--rep->ref_count == 0)
{
rep->destroy();
}
rep = other.rep;
++rep->ref_count;
}
return *this;
}
// 析构
~CowString()
{
if (--rep->ref_count == 0)
{
rep->destroy();
}
}
// 写时复制分离函数
void detach()
{
if (rep->ref_count.load() == 1)
{
return; // 就一个,随便玩
}
// 共享中,分配个新的
Rep* new_rep = Rep::create(rep->data);
// 不要忘了还回去
if (--rep->ref_count == 0)
{
rep->destroy();
}
rep = new_rep;
}
// 只读接口(const),绝不触发分离
const char* c_str() const { return rep->data; }
size_t size() const { return strlen(rep->data); }
char operator[](size_t pos) const { return rep->data[pos]; } // 只读
// 可写接口
char& operator[](size_t pos)
{
detach(); // 有人要修改,进行分离
return rep->data[pos];
}
// 追加字符串也会改数据
void append(const char* suffix)
{
detach();
// 这里假设空间足够
strcat(rep->data, suffix);
}
};使用示例:
cpp
// 测试
int main()
{
CowString s1("Hello");
CowString s2 = s1; // 共享中,没发生拷贝
std::cout << "s1: " << s1.c_str() << " s2: " << s2.c_str() << std::endl;
s2[0] = 'J'; // 写操作,触发分离
std::cout << "After COW: s1 = " << s1.c_str()
<< ", s2 = " << s2.c_str() << std::endl;
return 0;
}4. 多线程安全考量
在单线程中,上面代码没有什么大问题。但在多线程里,那就是哪哪都是问题。
主要有俩大坑:
- 坑一:引用计数的竞争
如果不用 std::atomic<int>,两个线程同时拷贝同一个对象,都执行 ++ref_count,可能结果变成只加了 1 次。
后果就是内存泄漏(永远减不到 0)或提前释放容易引发悬垂指针,所以在上面的代码我们直接使用了 std::atomic<int>。
- 坑二:那个经典的 Detach 竞态窗口
看这段危险代码:
cpp
// 线程 A 可能刚知道 ref_count > 1 然后准备新建,线程 B 此时析构了原对象导致 ref_count 变 0
void detach()
{
if (rep->ref_count.load() == 1) return; // 这里只是读,没锁
// 如果在这里发生线程切换,B 把 ref_count 减到 1 或者 0,那完蛋了
Rep* new_rep = Rep::create(rep->data);
// ...
}这里我们要么整个互斥锁,简单粗暴,要么牺牲点头发上无锁编程。
这也是为什么现代 std::string 弃用 COW 转投 SSO,就是因为在多核时代,锁的开销已经大于直接复制 15 个字节的开销了。
实现二:使用 std::shared_ptr 封装
std::shared_ptr 自带线程安全的原子引用计数,还附赠自定义删除器功能。我们只需要动点歪脑筋,让它管理一个 std::string 的指针,再在修改前 fork 一下,完美。
1. 设计思路
-
底层数据就是一个普通的 std::string,我们不直接碰它。
-
用 shared_ptr<string> 把它包起来,拷贝构造就是指针赋值,引用计数自动 +1。
-
任何想修改的动作,先判断 use_count() > 1,如果是,就深拷贝一份新的 string,再替换自己的 shared_ptr。
-
删除器?不需要,shared_ptr 默认 delete 很完美。
我们利用了 shared_ptr 对控制块的原子管理,直接规避了手写 RefCount 时多线程下的竞态噩梦。
现在我们只负责写业务,标准库负责给我们兜底。
2. 代码演示
cpp
class CowStringShared
{
private:
// 用一个 shared_ptr 管着一个普通的 string
std::shared_ptr<std::string> data_ptr;
// 分离函数
void detach()
{
// 如果指针非空,且不止一个人在用,就复制一份出来
if (data_ptr && data_ptr.use_count() > 1)
{
data_ptr = std::make_shared<std::string>(*data_ptr);
}
else if (!data_ptr)
{
// 如果是空壳,也造一个空字符串,方便后续操作
data_ptr = std::make_shared<std::string>();
}
}
public:
// 构造函数
CowStringShared(const char* str = "")
: data_ptr(std::make_shared<std::string>(str)) {}
// 拷贝构造:shared_ptr 的拷贝构造会让引用计数 +1,完美
CowStringShared(const CowStringShared&) = default;
// 赋值操作:默认的 shared_ptr 赋值会正确处理旧资源释放和新资源引用
CowStringShared& operator=(const CowStringShared&) = default;
// 析构:shared_ptr 自动搞定,我们啥也不用管,真好
~CowStringShared() = default;
// 只读接口
const char* c_str() const { return data_ptr ? data_ptr->c_str() : ""; }
size_t size() const { return data_ptr ? data_ptr->size() : 0; }
// 只读访问字符
char operator[](size_t pos) const { return (*data_ptr)[pos]; }
// 可写接口
char& operator[](size_t pos)
{
detach();
return (*data_ptr)[pos];
}
void append(const std::string& suffix)
{
detach();
*data_ptr += suffix;
}
// 为了方便输出,加个友元
friend std::ostream& operator<<(std::ostream& os, const CowStringShared& s)
{
os << (s.data_ptr ? *s.data_ptr : "");
return os;
}
int get_usecount()
{
return data_ptr.use_count();
}
};使用示例:
cpp
// 测试
int main()
{
CowStringShared s1("Hello");
CowStringShared s2 = s1; // 引用计数现在是 2,内存共享
std::cout << "s1: " << s1 << ", s2: " << s2 << std::endl;
std::cout << "引用计数: " << s1.get_usecount() << std::endl; // 输出 2
s2[0] = 'J'; // 写操作,触发分离
std::cout << "修改后 s1: " << s1 << ", s2: " << s2 << std::endl;
std::cout << "s1 引用计数: " << s1.get_usecount()
<< ", s2 引用计数: " << s2.get_usecount() << std::endl;
// s1 引用计数变为 1,s2 引用计数也是 1,各自独立
return 0;
}为了直观,我们把两种实现进行对比:
| 维度 | 手搓版本 | shared_ptr 封装版 |
|---|---|---|
| 代码量 | 需要管理内存分配/释放、原子计数 | 几乎没有内存管理代码 |
| 多线程安全 | 需要非常小心地设计原子操作 | shared_ptr 的引用计数是原子操作,基础保障有了 |
| 灵活性 | 可以精确控制内存布局(如 Rep 与数据连续) | 数据是独立的 std::string,多一次间接访问 |
用 shared_ptr 造 COW,虽然思想是旧的,但接口是新的,好用就完事了( ◜◡‾)。
典型应用场景
来整点好玩的,看看 COW 是怎么在某些地方撑起半边天(撑地嘿嘿)。
1. 操作系统进程管理
这是 COW 最经典的地方,没有之一。
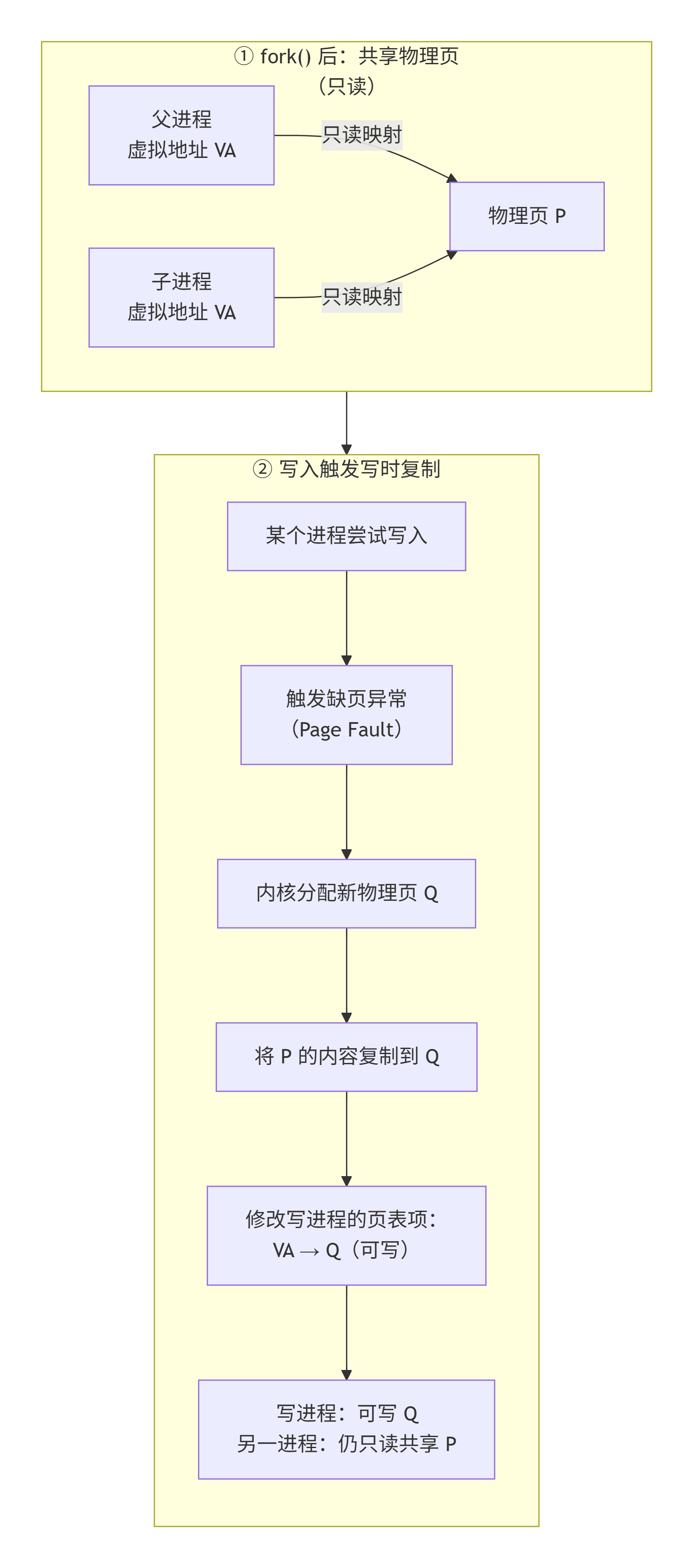
假如我们在 Linux 终端里敲下一个命令,shell 调用 fork() 创建子进程。按照最朴素的逻辑,操作系统应该把父进程的内存完完整整复制一份给子进程------几十 MB 甚至几 GB,想想就肉疼。更要命的是,大多数程序 fork() 之后立刻 exec() 加载新程序,刚才复制的内存全被丢弃。
这时候 COW 就要站出来了:
-
fork() 时,内核只复制页表,让父子进程的虚拟地址指向同一块物理内存。
-
同时把父子两边的页表项都标记为只读。
-
只要两边都只是读数据,大家共用同一份物理页,相安无事。
-
一旦某个进程试图写入,CPU 触发缺页异常,内核捕获后:分配新的物理页 → 复制原内容 → 修改页表映射 → 标记可写。
一张父子进程共享物理页的简图:
2. 虚拟化与容器
如果说 fork 是 COW 在内存里的首秀,那 Docker 就是把 COW 搬到了磁盘上。
问题:假设一个 Ubuntu 基础镜像 200MB,我们基于它跑 10 个容器,如果每个容器都复制一份完整的文件系统,那就是 2GB。更别提镜像本身还有多层(基础层 → 依赖层 → 应用层),每层都要存。
COW 解法:
Docker 镜像由多层只读层叠加而成,容器启动时在最上面加一个可写层(容器层),所有容器共享底下的只读层。
-
读文件:从上往下找,找到就直接用。
-
写文件:如果文件来自下面的只读层,先复制到可写层,再修改。这个操作叫 copy_up。
3. COW 文件系统的代表
传统文件系统修改文件是原地覆盖:新数据直接写回原来的磁盘位置。万一写一半断电咋办?文件可能变成一坨不可描述的东西。
COW 文件系统换个思路:永远不覆盖原数据。每次写操作,先把数据写到新的磁盘块,然后原子性地更新指针指向新块。
两大代表:
-
ZFS(Zettabyte File System):它把文件系统和卷管理整合在一起,靠 COW 实现了快照、克隆、端到端校验和、自修复等一堆高级功能。创建快照几乎瞬间完成,因为只需复制根节点指针。
-
Btrfs(B-tree File System):同样基于 COW,支持子卷、快照、压缩、RAID 等。快照是子卷级别的轻量克隆,创建快照等于新建一个和原子卷共享数据的子卷。
你看,这些场景它们都有共同点:
-
共享优先:能不复制就不复制,大家先共用同一份资源。
-
只读万岁:只要只读,万事大吉。
-
写时分离:一旦有人要改,立即复制一份私有的,绝不污染公共资源。
-
引用计数:记录有多少人还在用,等没人用了再真正释放。
COW 的代价与适用边界
前面的内容凸显了 COW 那么多的优点,你一看,"哎呀,COW 真好用,以后所有的项目我都要用 COW"。
现在是时候泼盆冷水了,这玩意儿要是没缺点,C++11 也不会狠心把 std::string 的 COW 给"优化"掉。
1. 性能代价
COW 最大的陷阱在于:把复制的成本从拷贝时转移到了第一次写入时。
表面上看:拷贝构造函数快得像闪电,O(1) 时间,内存纹丝不动。
实际上:我们欠了一笔技术债,出来混迟早要还(´~`)。
首次写入的情况:
-
触发分离判断:if (ref_count > 1)(原子读,还行)
-
分配新内存:new charsize(可能触发系统调用,慢)
-
完整深拷贝:memcpy(把我们以为省掉的复制工作原样补上)
-
更新引用计数:原子减操作 + 可能的旧内存释放
假设我们要把一个大字符串传给 1000 个线程,每个线程都只读,使用 COW 完美,内存只用一份。但如果其中 999 个线程都只是读,只有一个线程手贱,在某个犄角旮旯写了一个字符。
结果是什么?
那一个线程的写入延迟 = 一次完整的深拷贝 + 内存分配 + 可能的锁竞争。
原本可以在拷贝时平摊的成本,现在被集中到了那个倒霉线程的写操作上。
使用体验:99% 的操作飞快,突然一个操作卡成 PPT,哇,爆率真的很高哎,爆出了传说中的延迟毛刺。
更糟糕的是,如果有多个线程同时触发写入(比如它们各自想追加日志),每个线程都会争先恐后地执行 detach(),结果就是:
-
内存分配器被瞬间打爆
-
引用计数的原子操作在多个 CPU 核心间乒乓缓存
-
原本一份数据被复制成 N 份,内存占用反而爆炸
因此 COW 在实时系统或低延迟场景下,这种不确定性是致命的。
2. 实现复杂度
手搓 COW 写对了是艺术,写错了是事故。
在多线程环境下,简单的 ++ref_count 用默认的 memory_order_seq_cst 没问题,但如果我们想继续优化性能使用更宽松的内存序,哪天没操作好容易完蛋。
并且在 C++11 引入移动语义后,很多场景下浅拷贝 + 转移所有权比 COW 更高效。因为移动操作直接窃取资源,连引用计数的开销都省了。
COW 的共享机制反而阻碍了移动,因为移动要求源对象立刻失效,而 COW 的共享数据不能轻易被窃取。
3. 何时不该用 COW
一、高频小对象
对于只有几十字节的小字符串,COW 是纯纯的负优化。
-
引用计数的 4~8 字节开销可能比数据本身还大。
-
原子操作的 CPU 开销比直接 memcpy 几个字节还高。
-
这正是 C++11 std::string 转向 SSO 的根本原因,短字符串直接塞进对象内部,连堆分配都省了。
二、多线程高并发写入
如果我们的程序是典型的生产者-消费者模型,多个线程频繁修改共享数据,COW 会变成灾难:
-
分离次数激增,内存分配压力山大。
-
引用计数的原子操作在多核间砰砰砰,导致缓存失效。
-
每个线程最终都会拥有一份独立副本,内存占用不降反升。
说了些不该用的地方,那 COW 到底适合什么场景?
-
大对象:数据体积远大于引用计数开销。
-
读多写少:共享远多于修改,分离是稀有事件。
-
拷贝频繁:对象经常被按值传递、返回、存入容器。
结尾
COW 的人生信条就是:能蹭就蹭,蹭不了再买。
我们请他喝果茶,他不要,说"没必要,你先喝,喝不完剩下的给我就行"。
我们要改个文案,他不动,说"先这么用着吧,真要改我再复制一份"。
哎,COW 就是这么的无所谓,但是到了多线程薅他羊毛的时候,他就会急眼:"你改我也改?那我到底听谁的?得,老子不伺候了,你们一人一份自己玩去!"
这就是为啥后来 string 不和他玩了,受不了他这磨磨唧唧的性格,转头找了短小精悍的 SSO。