OpenAI 官方发布了 GPT-5.5 的 Prompt Guidance,整篇文档传递了一个反直觉的信号------你的 prompt 越短,效果可能越好。这不是偷懒,是范式转移。本文拆解十个关键转变,帮你从旧模型的 prompt 债务中解脱出来。

GPT-5.5 距离上一代 GPT-5.4 只隔了六周,API 定价每百万输入 Token 5 美元、输出 30 美元,上下文窗口 100 万 Token,目前已面向 Plus、Pro、Business 和 Enterprise 用户开放。模型本身的变化各家媒体已经报道过,这份提示词指南更值得关注的是它暗示的使用方式转变。
最近几天我一直在反复读 OpenAI 新发的 GPT-5.5 Prompt Guidance,读完最大的感受是:我们过去两年写 prompt 的方式,可能要推倒重来了。
不是夸张。这份指南里几乎每一条建议,都在告诉我们------别再往 prompt 里堆东西了。
如果你之前是 GPT-5.4 甚至更早模型时代的用户,你一定经历过那种"写 prompt 像写法律条文"的日子。为了防止模型跑偏,你把每一步操作都写得清清楚楚:先做这个,再做那个,千万别忘了那个,绝对不能做这个。一个 prompt 写下来几百行,比你业务代码还长。
但 GPT-5.5 官方指南说:别这么干了。
这篇文章,我想系统性地聊聊这份指南传递的十个核心转变。不是翻译,是我自己读完之后的理解和实战思考。

GPT-5.5 Prompt 封面
一. 最大的变化:从"教模型怎么做"到"告诉模型你要什么"
这是整份指南最核心的一条。
GPT-5.5 的推理能力已经强到------你不需要告诉它每一步该走,你只需要告诉它终点在哪,它会自己找路。
官方原话是: "Shorter, outcome-first prompts tend to outperform process-heavy prompt stacks."
翻译一下:短的、结果导向的 prompt,通常比长的、过程堆叠的 prompt 效果更好。
这不是说 prompt 不重要了。恰恰相反,prompt 变得更重要了,但重要的方式变了。以前你在 prompt 里写的是"操作手册",现在你需要写的是"验收标准"。
看个对比就明白了。
旧风格(过程导向):
css
First inspect A, then inspect B, then compare every field,
then think through all possible exceptions, then decide which
tool to call, then call the tool, then explain the entire
process to the user.新风格(结果导向):
vbnet
Resolve the customer's issue end to end.
Success means:
- the eligibility decision is made from the available policy and account data
- any allowed action is completed before responding
- the final answer includes completed_actions, customer_message, and blockers
- if evidence is missing, ask for the smallest missing field看到区别了吗?旧风格在教模型走路,新风格在告诉模型目的地。
官方还特别警告了一件事:不要从旧模型搬运 prompt。 以前那些为了补偿模型能力不足而添加的流程指令,对 GPT-5.5 只会"添加噪音、收窄搜索空间、导致机械回答"。这些指令在过去是拐杖,现在是脚镣。对开发者来说,这意味着需要重新审视手头积攒的提示词模板------以前管用的"保姆式"写法,现在可能适得其反。
我自己有类似的体会。之前我用 GPT-5.4 做客服 Agent,prompt 里有大量"先确认用户意图,再查知识库,再组织回答,语气要友好但不能太随意"之类的流程指令。模型确实需要这些指导。但切到 GPT-5.5 之后,我把那些流程指令全删了,只写"解决用户问题,成功标准是 X",效果反而更好,而且响应更快。
prompt 的重心,从过程控制转向结果定义。
这才是 GPT-5.5 时代写 prompt 的第一性原理。
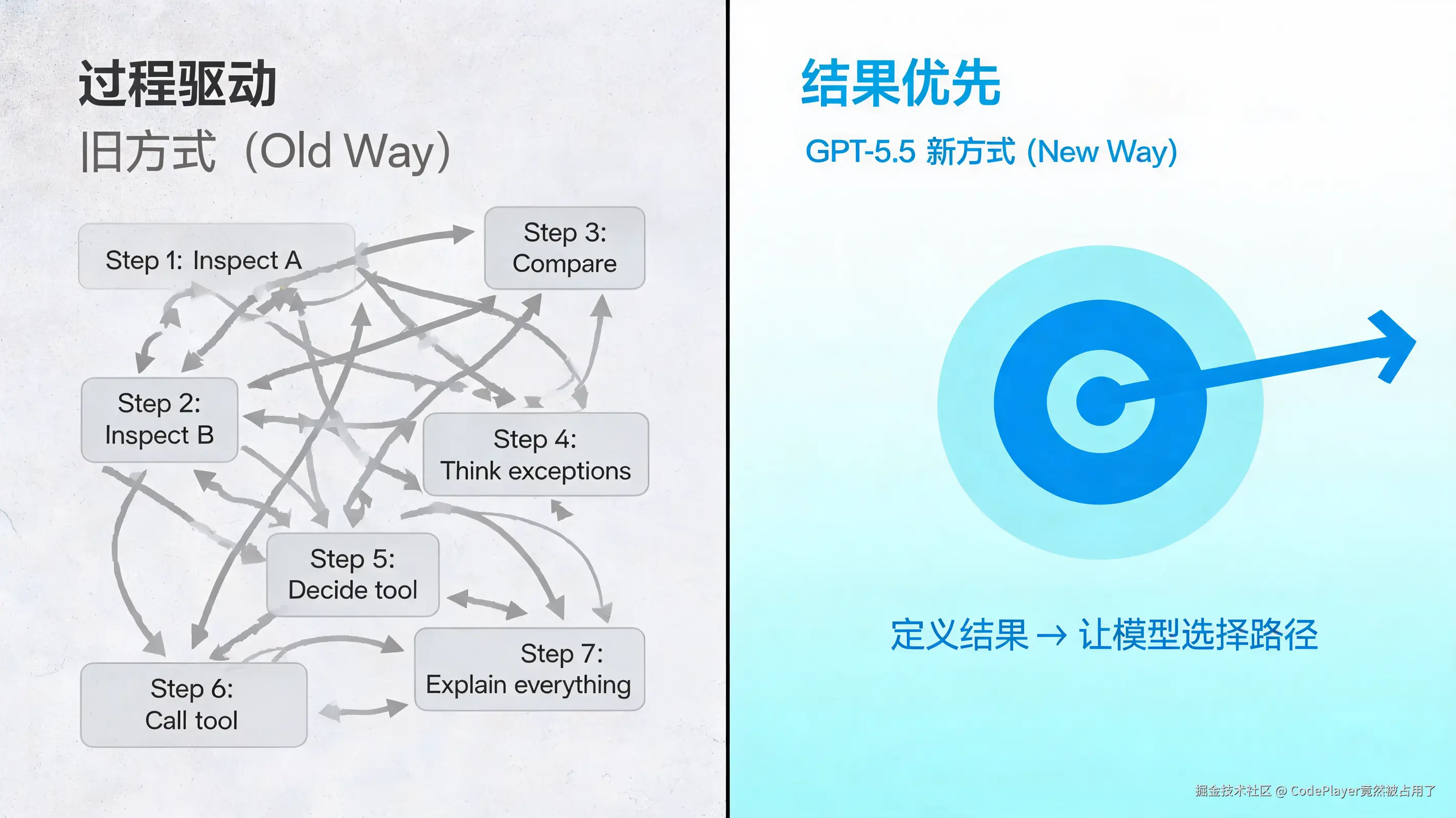
过程导向 vs 结果导向 Prompt 对比
二. 人格不是装饰,是产品体验的核心控件
GPT-5.5 的默认风格是"高效、直接、任务导向"。这听起来很好,对吧?生产环境嘛,谁不想要高效。
但如果你做的是面向 C 端的产品------一个 AI 客服、一个 AI 陪聊、一个 AI 写作助手------"高效直接"可能恰恰不是用户想要的。用户要的是被理解、被陪伴、被温和地引导。
官方给出的方案很精妙:把人格拆成两个维度------Personality 和 Collaboration Style。
Personality 控制听起来怎样:语气、温暖度、正式度、幽默感、同理心、精致程度。
Collaboration Style 控制工作起来怎样:什么时候提问 vs 什么时候假设、主动程度、给多少上下文、什么时候该检查工作、不确定时怎么办。
这两个维度要分开定义,而且都要短。
举个例子,官方给了一个"稳重型任务助手"的人格定义:
sql
# Personality
You are a capable collaborator: approachable, steady, and direct.
Assume the user is competent and acting in good faith.
Prefer making progress over stopping for clarification
when the request is already clear enough.
Ask for clarification only when missing information
would materially change the answer or create meaningful risk.注意这个设计的巧妙之处------它没有写"你要温柔"、"你要热情"这种空话。它写的是行为规则:什么时候往前走,什么时候停下来问。人格不是形容词堆砌,是行为指引。
官方还提醒了一句我特别认同的话: "Use personality to shape the experience, not to compensate for unclear goals or missing task instructions." 人格是锦上添花,不是雪中送炭。目标不清楚,人格写得再好也救不了。
三. Preamble:一个看似不起眼但极其实用的技巧
这个技巧我之前没怎么重视,看完官方指南后发现真的聪明。
问题场景是这样的:在流式应用中,GPT-5.5 可能需要花时间推理、规划、准备工具调用,然后才开始输出可见文本。这段时间用户看到的是------什么都没有。光标闪啊闪,用户心想"是不是挂了?"
解决方案极其简单:让模型先输出一段简短的确认。
sql
Before any tool calls for a multi-step task, send a short
user-visible update that acknowledges the request and states
the first step. Keep it to one or two sentences.比如用户问"帮我查一下订单 #12345 的状态",模型不是默默开始调用工具,而是先说一句"好的,我来查一下订单 #12345 的状态",然后再去干活。
这不改变任何底层逻辑,但显著改善了用户感知的响应速度。
说个真实的场景。我自己用 AI 助手的时候,如果超过 3 秒没有任何反馈,我就会开始焦虑,觉得是不是卡了,然后开始疯狂刷新。但如果第一时间看到一句"收到了,正在处理",哪怕实际处理时间一样长,我的感受会好很多。
这不是什么高深的心理学,就是人需要被回应。AI 产品也是。
对编码 Agent,官方建议更具体:在分析通道中,如果任务需要调用工具,必须先输出一条中间更新,确认请求并说明第一步。
Preamble 本质上是 UX 技巧,不是 Prompt 技巧。 但在 AI 产品中,prompt 就是 UX 的一部分。

有无 Preamble 的用户体验对比
四. 停止条件:让模型知道什么时候该收手
这个问题在 Agent 场景下特别严重。
你有没有遇到过这种情况:一个 Agent 在那儿反复搜索、反复调用工具、反复验证,就是不给你最终答案?或者反过来,它搜索了一次就觉得够了,给你一个半吊子的回答?
官方给的方案是:显式定义停止规则。
vbnet
Resolve the user query in the fewest useful tool loops,
but do not let loop minimization outrank correctness,
accessible fallback evidence, calculations, or required
citation tags for factual claims.
After each result, ask: "Can I answer the user's core
request now with useful evidence and citations for the
factual claims?" If yes, answer.这段话的设计很精妙。它同时做了两件事:一是鼓励效率(最少的工具调用循环),二是防止过度压缩(不能为了少调工具而牺牲正确性)。然后给了一个自检机制:每次拿到结果后问自己一个问题------"我现在能不能回答用户的核心请求了?"
另外,对于证据不足的情况,官方建议明确行为规则:
css
Use the minimum evidence sufficient to answer correctly,
cite it precisely, then stop."最少充分证据"------这个表述特别精准。不是"尽可能少的证据",而是"刚刚好够用的证据"。少一分不行,多一分浪费。
没有停止条件的 Agent,就像没有刹车的车。 它可能很努力,但不知道什么时候该停下来。
五. 格式控制:可控不等于要控制
GPT-5.5 对输出格式的控制力比前代强很多。官方说的是"highly steerable"。
但可控不代表你要控制一切。
官方的建议很有节制:
- 用
text.verbosity控制冗长度,默认medium,短回答用low - 描述预期的输出形状,但只在"提升可读性或产品适配"时用重结构
- 默认用自然段落,标题、加粗、列表只在必要时用
- 添加受众和长度指引
sql
Write for a senior business audience. Keep the answer
under 400 words. Use short paragraphs and only include
bullets when they improve scannability. Prioritize the
conclusion first, then the reasoning, then caveats.这条建议我觉得特别好:"Let formatting serve comprehension." 格式是服务于理解的,不是服务于好看的。
还有一个实用模式叫"Preserve-Then-Improve"------先保留,再优化。用在编辑、改写、摘要等场景:
vbnet
Preserve the requested artifact, length, structure, and
genre first. Quietly improve clarity, flow, and correctness.
Do not add new claims, extra sections, or a more promotional
tone unless explicitly requested.这个模式的精髓在"Quietly"------安静地改善,不要大张旗鼓地重构。你要改的是文字质量,不是内容范围。
六. 检索预算:够了就够了
这条是我个人觉得最实用、但也是之前最容易忽略的建议。
在 RAG 或搜索增强的场景中,模型经常会有一种"强迫症"------搜索一次不够,再搜一次,还是不够,再来一次。结果为了回答一个简单的问题,调了五次检索 API,token 烧了一大堆,延迟也上去了。
官方给了一个概念叫"Retrieval Budget"------检索预算。本质上是给搜索行为定义停止规则。
sql
For ordinary Q&A, start with one broad search using short,
discriminative keywords. If the top results contain enough
citable support for the core request, answer from those
results instead of searching again.普通问答,一次广搜索就够了。结果里有足够的可引用证据,就直接回答,不要再搜了。
什么时候该搜第二次?官方给了明确的条件清单:
- 核心问题没被回答
- 缺少必需的事实、参数、日期等
- 用户要求全面覆盖或对比
- 需要读取特定文档
- 不搜就会导致重要的事实性主张没有支撑
什么时候不该再搜?
- 为了改善措辞
- 为了添加更多例子
- 为了引用非必要细节
- 为了支撑那些可以安全地泛化表述的措辞
说白了就是:不要为了完美而浪费。
这个建议背后的工程哲学我很认同------AI 系统的资源消耗是实际成本,不是抽象概念。每一次多余的 API 调用都是钱,每一毫秒多余的延迟都是用户体验的损失。定义检索预算,本质上是在做成本和质量的权衡。对做客服、做知识问答产品的团队来说,搜索次数直接关联 Token 消耗,设好预算能省不少钱。
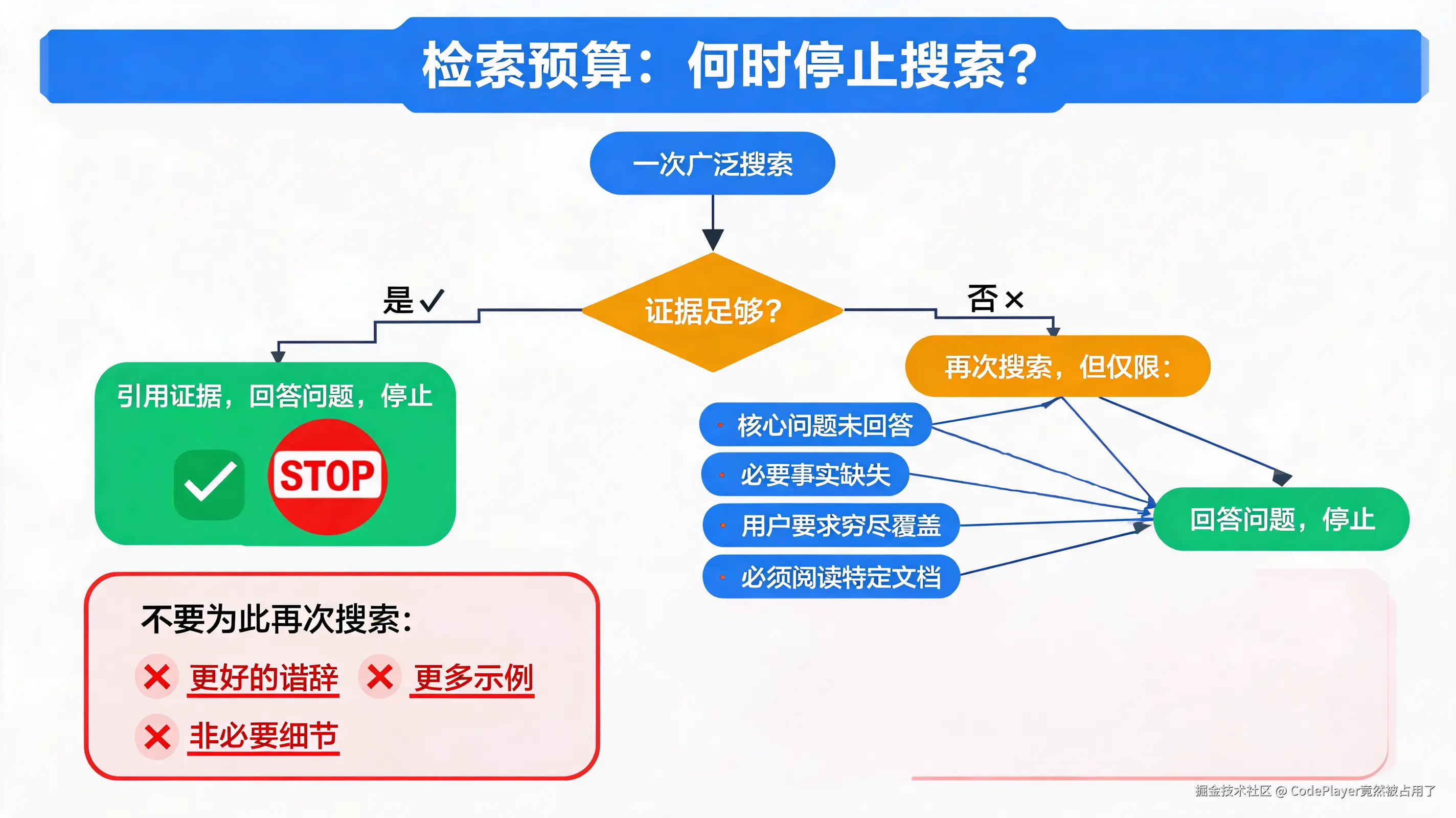
检索预算决策流程
七. 创意写作护栏:哪些能编,哪些不能编
这条对做内容生成产品的同学特别重要。
问题场景:你让 AI 写一篇产品发布稿、一篇高管演讲、一页 PPT。模型会编。它会编客户名字、编数据指标、编路线图状态、编产品功能------因为这些东西让文案听起来更有力。
但这些都是事实性声明,编不得。
官方给的规则很清楚:
- 必须有来源的:具体产品信息、客户信息、指标、路线图状态、日期、能力、竞品声明------这些必须来自检索或提供的资料,并且要引用
- 不能编的:具体的名字、一手数据、指标、路线图状态、客户成果、产品能力------不要为了让草稿听起来更强而编造这些
- 没有足够来源时:写一个有用的通用草稿,用占位符或标注假设,而不是编造具体信息
csharp
If there is little or no citable support, write a useful
generic draft with placeholders or clearly labeled assumptions
rather than unsupported specifics.这条规则的本质是:创意可以发挥,事实不能编造。 模型需要知道边界在哪。
AI 编故事的能力太强,强到你可能分不清哪些是真的。尤其是在做对外材料的时候,一个编造的客户案例或数据点,后果可能比不写还糟。我觉得这对所有做 AI 内容生成的产品都适用。你不仅仅是在控制输出风格,你是在定义什么是"可接受的创造"和"不可接受的编造"。
八. 让模型检查自己的工作
这条建议有种"让狐狸守鸡窝"的味道,但它真的管用。
核心思路:给模型访问验证工具的能力。
编码场景:
diff
After making changes, run the most relevant validation available:
- targeted unit tests for changed behavior
- type checks or lint checks when applicable
- build checks for affected packages
- a minimal smoke test when full validation is too expensive
If validation cannot be run, explain why and describe the
next best check.视觉场景:
lua
Render the artifact before finalizing. Inspect the rendered
output for layout, clipping, spacing, missing content, and
visual consistency. Revise until the rendered output matches
the requirements.工程/规划场景: 让实现计划可追溯------需求来自哪里、涉及哪些资源、状态转换是什么、验证命令是什么、失败时怎么办、安全和隐私考虑是什么。
这三条建议的共同点是:不只是让模型产出结果,而是让模型验证结果。
这其实是一种工程思维的体现。我们写代码也不是写完就交付,而是跑测试、看日志、做 code review。AI 也应该走同样的流程。
而且注意,官方没有说"让模型检查自己的输出是否正确"------那太抽象了。它说的是"运行最相关的验证"------具体到跑哪个测试、做什么检查。这又回到了结果导向的思路:不是告诉模型"你要检查",而是告诉模型"跑这个测试,看结果"。
九. Phase 参数:区分中间态和终态
这条偏技术细节,但对做 Agent 产品的同学很关键。
从 GPT-5.4 开始,Responses API 支持 phase 参数来区分助手的中间更新和最终答案。GPT-5.5 延续了这个模式。
核心规则:
- 如果你用
previous_response_id,API 会自动保留之前的助手状态 - 如果你的应用手动回放助手的输出项到下一个请求中,必须保留每个原始的
phase值,原封不动地传回去
markdown
If manually replaying assistant items:
- Preserve assistant `phase` values exactly.
- Use `phase: "commentary"` for intermediate user-visible updates.
- Use `phase: "final_answer"` for the completed answer.
- Do not add `phase` to user messages.为什么这很重要?因为在多轮工具调用的场景中,一个完整的响应可能包含多条助手消息------有些是中间的"我在做什么"的更新,有些是最终的完整答案。如果你在回放时搞混了 phase,模型的上下文就会错乱。
这不是 prompt 技巧,是工程实践。但在 AI 产品开发中,prompt 和工程的边界本来就很模糊。
十. 建议的 Prompt 结构:七段式模板
官方最后给了一个推荐的 prompt 结构模板,作为复杂 prompt 的起点:
ini
Role: [1-2 sentences defining the model's function, context, and job]
# Personality
[tone, demeanor, and collaboration style]
# Goal
[user-visible outcome]
# Success criteria
[what must be true before the final answer]
# Constraints
[policy, safety, business, evidence, and side-effect limits]
# Output
[sections, length, and tone]
# Stop rules
[when to retry, fallback, abstain, ask, or stop]注意,官方特意说了"Keep each section short. Add detail only where it changes behavior."------每一段都保持简短,只在能改变行为的地方添加细节。
这个结构我对比了一下自己之前的 prompt,发现几个明显差异:
我之前缺的:明确的 Stop rules 和 Success criteria。我一直在隐式地假设模型知道什么时候该停,但其实它不知道。
我之前多余的:大量的流程指令混在 Role 和 Goal 里。现在这些应该删掉,让 Goal 纯粹地描述期望结果。
我之前忽视的:Personality 和 Collaboration Style 的区分。我之前把人格和行为规则混在一起写,没有意识到它们控制的是不同维度。
GPT-5.5 推荐七段式 Prompt 结构
回到那个核心问题
写到这里,我想回到开头那个判断:我们过去两年写 prompt 的方式,可能要推倒重来了。
准确地说,不是推倒重来,而是做减法。
GPT-5.5 Prompt Guidance 传递的核心信息,用一句话概括就是:模型更强了,你的 prompt 应该更短了。
但"更短"不是"更模糊"。你删除的是过程指令,替换的是结果定义。你不再教模型怎么走路,而是告诉它目的地在哪、到了之后的验收标准是什么、路上有哪些红线不能碰、什么情况下该停下来。
Prompt 的重心,从"过程控制"转向了"结果定义 + 边界约束 + 停止条件"。
这是范式转移,不是微调。
如果你现在手里有一套跑在 GPT-5.4 或更早模型上的 prompt stack,我的建议是:别急着全部迁移。先用官方给的七段式模板重写一个最简单的版本,然后跟旧版本对比效果。你会惊讶地发现,减掉 70% 的内容后,效果可能反而更好。
当然,也可能不会。因为每家产品的场景不同,模型行为也有差异。这就是为什么官方说了------"These patterns are starting points to adapt to your specific product, tools, evals, and UX goals."
但方向是清楚的。
少即是多,这四个字,可能就是 GPT-5.5 时代 prompt 工程的第一性原理。
从 GPT-4 时代的"提示词工程"到现在 GPT-5.5 的"少说多做",提示词的写法以前是人适应模型的局限,现在是模型开始适应人的模糊表达。对于还在用旧模型的提示词模板的团队,可能要考虑重写你的提示词了。
参考资料
- GPT-5.5 Prompt Guidance --- OpenAI 官方文档:developers.openai.com/api/docs/gu...
- Using GPT-5.5 Guide --- OpenAI 官方文档:developers.openai.com/api/docs/gu...
- Citation Formatting Guide --- OpenAI 官方文档:developers.openai.com/api/docs/gu...
- Frontend Prompt Guide --- OpenAI 官方文档:developers.openai.com/api/docs/gu...
- OpenAI Codex Docs Skill --- GitHub:github.com/openai/skil...
话题标签:#GPT5.5 #PromptEngineering #OpenAI #AI开发 #大模型
本文使用 mdnice 排版