本文总结了两篇关于时间序列分类与感知的前沿论文,分别应对了模态异构与标签噪声带来的现实挑战。
第一篇针对物理惯导(IMU )与文本对齐不精准的问题提出了Vistar框架,创新性地使用视频作为中间桥梁,结合离线跨模态对比学习与在线检索增强生成(RAG ),赋能大语言模型对复杂传感器信号的理解与感知。第二篇针对时序学习的标签噪声难题提出DREAM,摒弃传统过滤法,从邻域和模型双重数据中心视角分离干净与噪声样本,通过循环特征插值(MixUp)充分利用噪声数据,显著提升了泛化与抗噪鲁棒性。
我整理了2篇论文完整架构图+核心算法和零上手复现教程,感兴趣的可以dd,希望能帮到你!
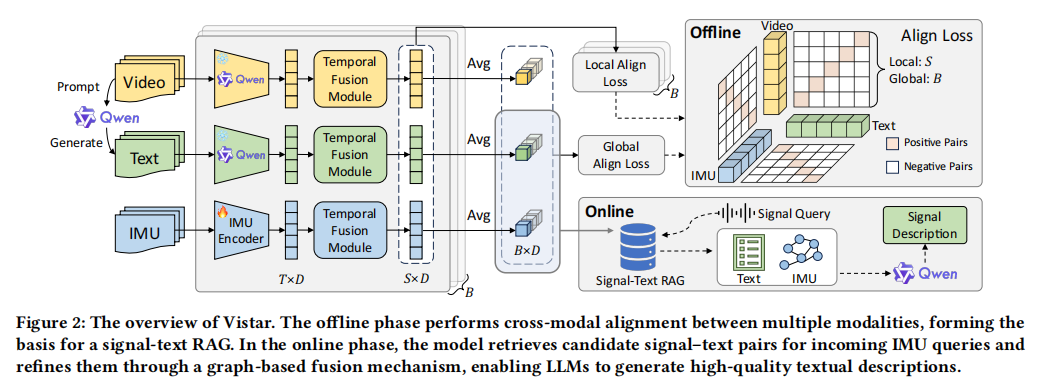
一、论文1:【上海交通大学】Vistar: Enhancing the Perception Capability of LLMs under Imprecise IMU-Text Alignment
方法:
-
桥接对齐:离线阶段以视频为中间桥梁,利用多粒度对比学习捕捉全局和局部时序特征,将IMU编码器与文本空间对齐。
-
图引导检索:在线推理时,利用IMU结构关系构建锚点-集群的语义关系图。
-
计算公式:通过联合全局与局部的跨模态匹配目标函数实现模型优化:
-
增强生成:无需微调,直接将检索到的文本与图结构提示输入大模型,生成精确的动作描述。
创新点:
-
构建了首个自监督LLMs信号感知框架,解决了IMU信号与高层语义间对齐不精准且缺乏标注的难题。
-
设计了一套基于传感器物理相似性(如图中心节点与邻居跳数)的在线RAG机制,大幅减少了模态异构带来的幻觉,在跨模态检索检索中效果提升显著。
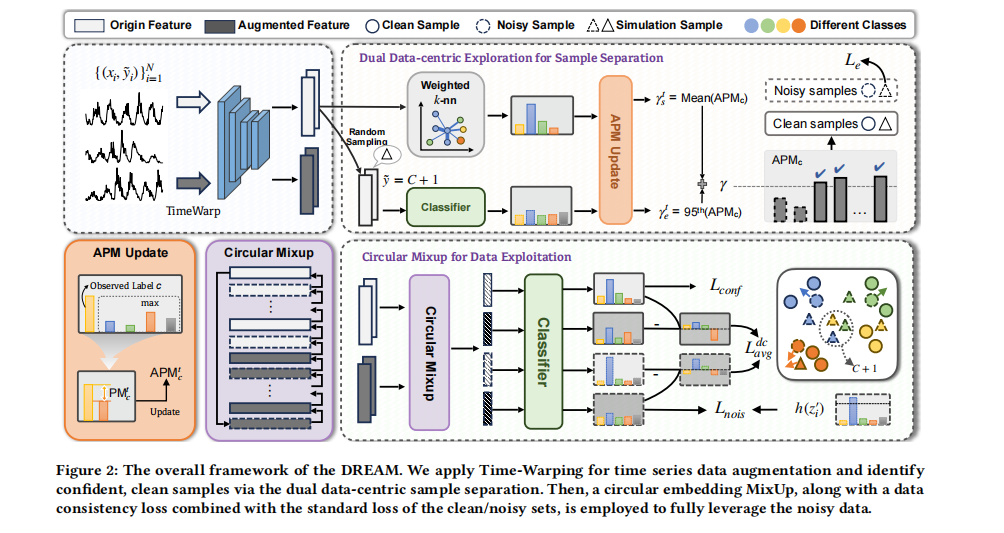
二、论文2:【东北大学】Dual Data-centric Separation with Circular Mixup for Noise-resistant Time Series Learning
方法:
-
双视角分离:依赖邻域亲和力生成伪标签并计算伪边界,结合模拟的错误标签样本,动态估计阈值以分离干净与噪声样本。
-
循环混合:将干净与噪声样本抛入连续的特征嵌入空间进行软插值操作,计算公式如下(其中 为混合强度):
-
一致性学习:引入差异感知模块,最小化同一增强数据下干净集与噪声集的预测概率变化,促使模型充分利用噪声信号进行鲁棒表征学习。
创新点:
-
打破了传统基于当前训练损失过滤样本的局限,通过数据特征与模型动态两个中心视角,实现了高噪环境更精准的样本切分。
-
探索了一种新颖的循环MixUp方式和细粒度的一致性正则化,不仅阻断了错误标签的记忆积累,还有效地稀释了噪声,变废为宝提升了时序检测的泛化性能。