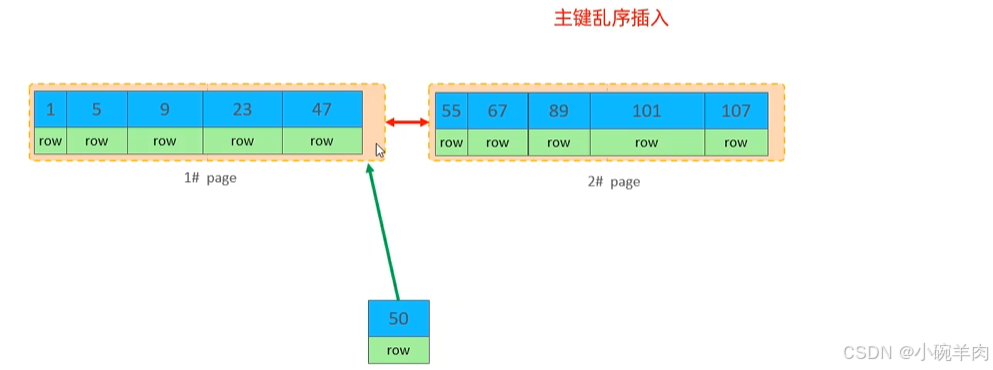
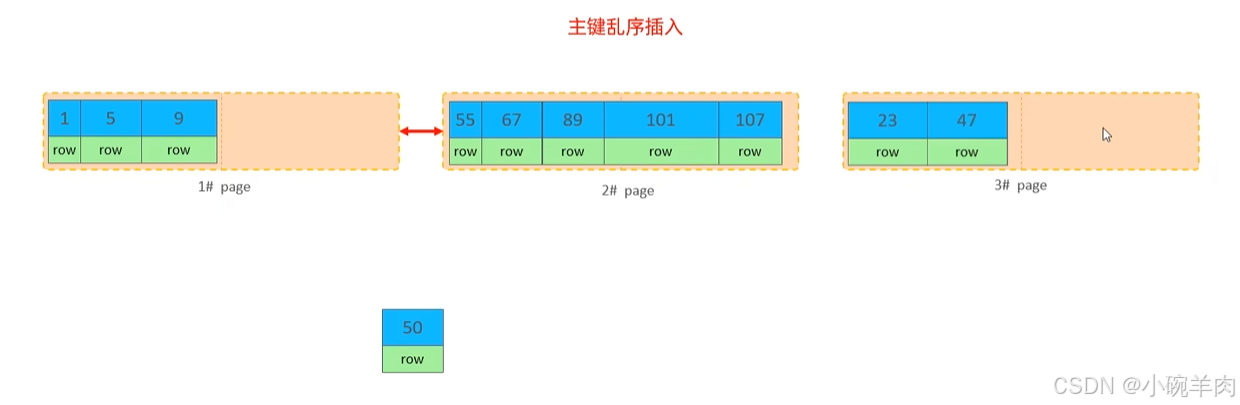
insert into tb_test values(1, 'TOM'),(2, 'CAT'), (3, 'Jerry');
手动提交事务:
sql复制代码
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jery');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;
#客户端连接服务端时,加上参数 --local-infile
mysql--local-infile -u root -p
#设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local infile = 1;
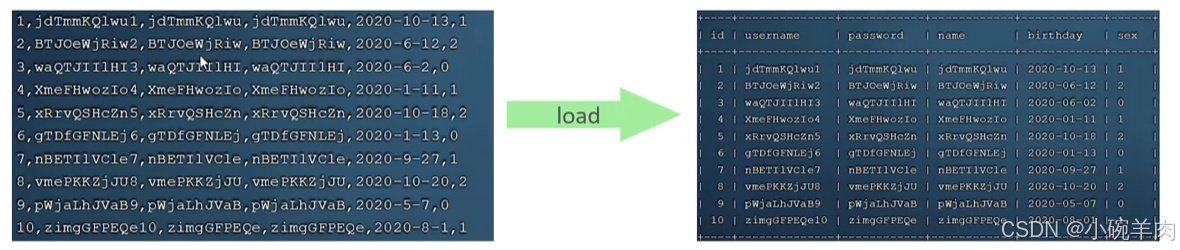
#执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.log' into table 'tb_user'
fields terminated by ','
lines terminated by '\n';
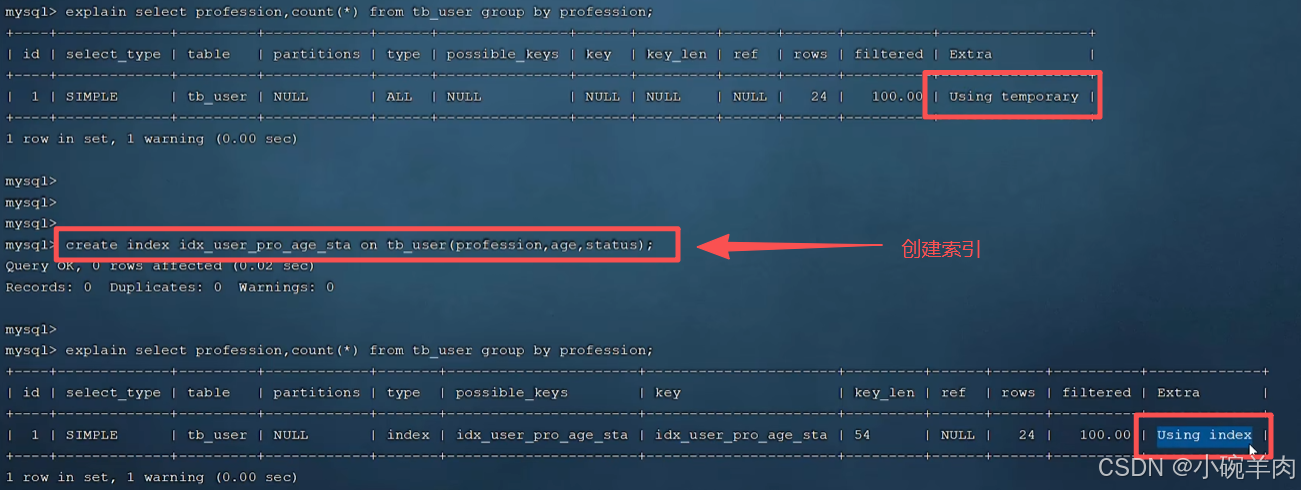
#根据age,phone进行降序一个升序,一个降序
explain select id, age, phone from tb_user order by age asc, phone desc;
#创建索引
create index idx_user_age_phone_ad on tb_user(age asc, phone desc);
#根据age,phone进行降序一个升序,一个降序
explain select id, age, phone from tb_user order by age asc, phone desc;