
veStack 是火山引擎自主研发的企业级混合云平台,旨在将公有云的高效、弹性和丰富的服务能力,延展至企业的本地数据中心。
近日,深度求索(DeepSeek)正式发布其全新系列模型 DeepSeek-V4 并开源,受到了许多企业用户的关注。火山引擎 veStack 混合云平台 依托自主研发技术和深厚的 AI 服务经验,已完成对该模型的适配与支持,用户无需等待,即可在本地数据中心快速、安全地部署这一前沿 AI 能力------真正实现"模型在身边,数据不出域"。
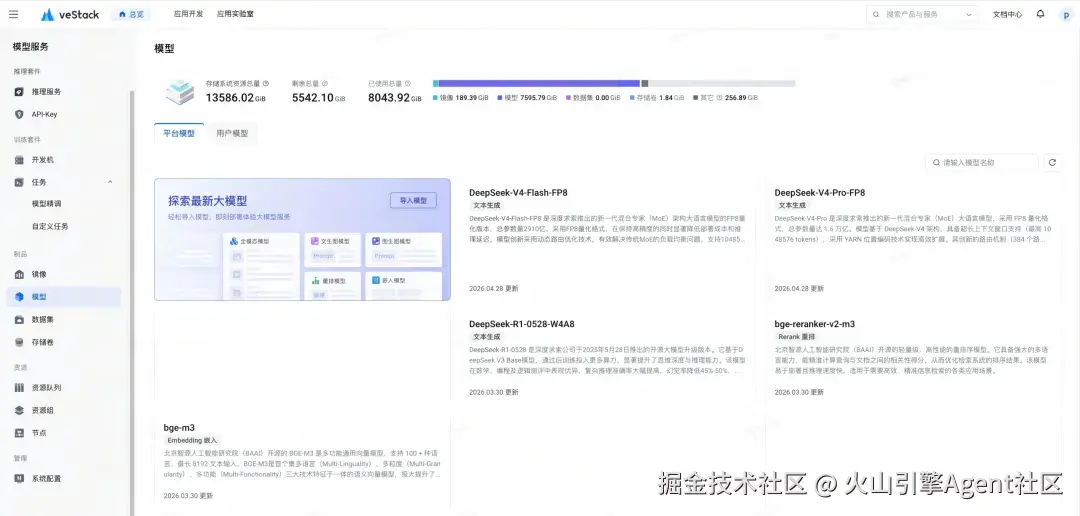
用户在 veStack 平台部署 DeepSeek-V4 大模型
DeepSeek-V4 私有化部署:能力与落地
新发布的国产大模型 DeepSeek-V4 凭借其百万级超长上下文、强化的 Agent 能力与高效的推理性能,全面对标国际闭源旗舰。该系列包含两个主要版本:
- DeepSeek-V4-Pro:拥有 1.6T 总参数与 49B 激活参数,专为复杂推理、长文档理解和智能体任务设计。
- DeepSeek-V4-Flash:拥有 284B 总参数与 13B 激活参数,主打低成本与高并发,适配更轻量化的应用场景。
火山引擎 veStack 从实际业务场景出发,对推理引擎、分布式多级缓存(KV Cache)和智能路由等进行了深度优化,为 DeepSeek-V4 的私有化部署提供了一套稳定、高效的解决方案,支持更加多元、自主可控的模型服务提供路径,让 DeepSeek-V4 能真正落地于高合规要求的企业环境:
- 真正的"一键落地": 告别繁琐的依赖配置。veStack 提供一站式优化的部署方案及清晰的部署指引,可帮助企业高效启动并平稳运行;
- 专属的"企业智慧": 实现完全私有化部署,无外部依赖,确保业务合规。同时支持与模型调度网关集成,可实现敏感数据使用私有化部署的 DeepSeek、非敏感数据交由外部模型处理的智能路由;
- 性能不打折的承诺: 即使在私有化环境下,使用火山引擎的推理加速引擎,V4 模型在处理长文档、复杂逻辑推理时,依然保持出色的响应速度与精度;
- 无缝融入现有业务: 通过与 veStack 自带的智能助手 ArkClaw 和 Agent 开发平台 AgentKit 的预集成,DeepSeek 可与之无缝嵌入,开箱即用。
目前,veStack 的两大核心版本:全栈版 和轻量智算版,均已完成对 DeepSeek-V4 的适配。企业可根据自身的数字化阶段和业务目标,灵活选择合适的落地路径:
veStack 全栈版:企业级私有云的坚实底座
如果您正在构建一个全面、稳定、可扩展的私有云环境,veStack 全栈版会是一个推荐底座方案。它与火山引擎公有云同构,将完整的 IaaS、PaaS、数据库、大数据、安全与 AI 能力一并交付到您的本地数据中心。
- 适用场景:构建企业级智算中心、纳管超大规模 GPU 集群(支持万卡以上)、统一调度多元算力(兼容 NVIDIA 及主流国产卡)。
- 核心收益:在保障数据安全与合规的前提下,获得一个真正可演进的混合云战略,从容应对复杂业务挑战。
veStack 轻量智算版:AI 应用的敏捷起点
如果您的团队更希望"先跑起来、快速验证",veStack 轻量智算版提供了一个专注、高效的选择。它聚焦 AI 模型的推理、训练以及 Agent 的开发运维,可以用更轻量的方式帮您搭建智算基础设施。
- 适用场景:快速验证 AI 应用、开发与部署 Agent 智能体、聚焦模型推理与调优。
- 核心收益:无需投入庞大的初期基建建设,即可快速搭建起支持 DeepSeek-V4 等先进模型的运行环境,让想法尽快转化为业务价值。
从模型到 Agent:veStack 的全栈 AI 能力
部署 DeepSeek-V4 只是起点,veStack 还将火山引擎公有云同源的 AI 全系列产品集成到私有化环境中,提供了从智能助手、Agent 开发到推理加速的全栈能力,让模型从"能用"走向"好用"。
ArkClaw:7×24 在线专属智能伙伴
ArkClaw 是火山引擎的云端 AI 智能体(Agent)服务,可以帮助用户一键部署 OpenClaw,从而安全、高效地构建和管理专属"数字员工"。目前 OpenClaw 社区已将 DeepSeek V4 作为默认模型,进一步验证了该模型在此场景中的应用价值。ArkClaw 可通过 "模型调度网关"与 DeepSeek-V4 对接,让 DeepSeek-V4 的能力触达每一位员工:
- 企业级安全合规:提供技能安全扫描、大模型防火墙、权限管控与行为审计等能力,为企业构建安全护城河。
- 统一管理与运维:通过企业管理端,实现对员工助手的统一配置、监控运维、资源授予、成本分析,全面提升管理效率。
- 沉淀企业数字资产:支持构建记忆体系、技能中心、以及面向企业内部数据集成的 Connector,集成企业已有体系、沉淀企业与员工知识,让 AI 越用越懂业务。
AgentKit:企业级 AI Agent 平台
AgentKit 是一个覆盖 AI Agent 全生命周期的企业级平台,可以帮助用户快速构建并规模化落地 Agent 应用。DeepSeek-V4 提供了 Flash 和 Pro 两个版本及多种思考深度,为不同性能与精度要求的 Agent 场景带来了灵活的选择。通过 AgentKit Runtime,用户可以轻松调用并驾驭这些模型能力。
- 加速开发孵化:提供 Agent 运行时、身份认证、MCP和技能管理、知识与记忆库等基础设施,让开发者专注于业务逻辑,无需重复"造轮子"。
- 保障生产级落地:内置多租户隔离、身份鉴权、大模型防火墙和内容安全护栏,确保 Agent 服务达到生产可用的安全与稳定标准。
- 灵活开放,多框架兼容:开源深度集成的开发框架 veADK 和 工具链 Agent CLI,同时支持 LangChain 等其他开源项目。
ServingKit:高性能推理引擎,充分释放模型潜能
veStack 能够高效稳定地承载 DeepSeek-V4 等大规模模型,离不开其内置的 AI 云原生推理套件 ServingKit。该套件沉淀了字节跳动在超大规模 AI 业务中的实践经验,其核心优势包括:
- 出色的性能与效率: 通过算子加速、KV 缓存优化和模型极速启动技术,大幅提升模型推理速度,降低时延。
- 强大的稳定与扩展性:依托容器化编排与 PD 分离架构,轻松应对大规模 GPU 集群的调度与管理,保障服务持续稳定。
- 全面的可观测性:提供从 AI 网关到推理实例的全链路观测能力,帮助运维团队快速定位并解决问题。
三步轻松部署 DeepSeek-V4
现在,是时候开始部署你的 DeepSeek-V4 了!火山引擎 veStack 已经为用户准备好了全部所需,整体流程如下图所示:
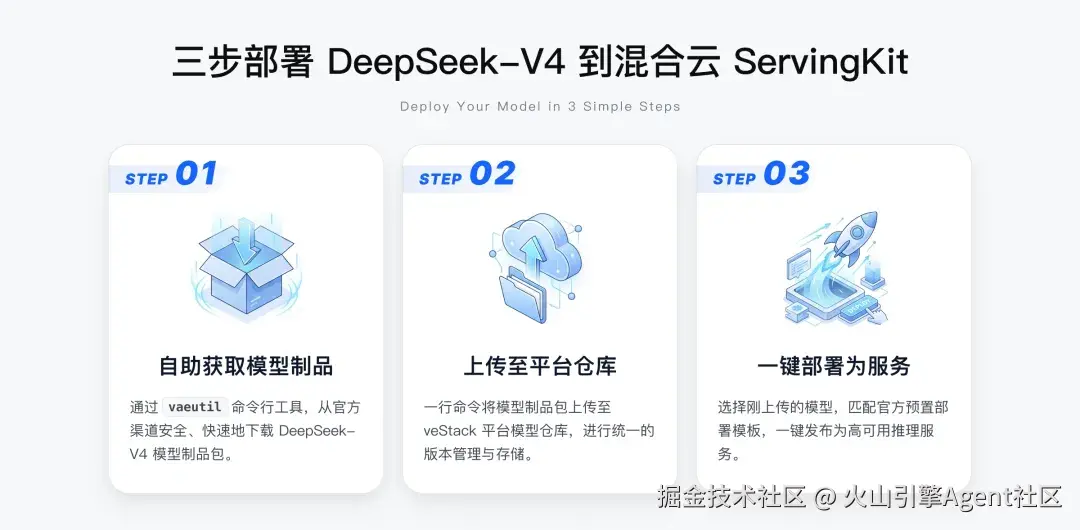
只需三步,您就能在自己的私有环境中让模型跑起来!
1. 自助获取模型制品
veStack 提供专用的 vaeutil 命令行工具,您可以通过授权的火山引擎账号,从官方渠道安全、快速地下载 DeepSeek-V4 模型制品包。
不同版本的获取方式略有差异:
- veStack 轻量智算版:用户自行在模型管理页面找到相关的下载页面,直接获取工具。
- veStack 全栈版:请联系相关的售后支持人员,线下获取。
获取工具后,执行以下命令下载模型:
css
./vaeutil pltpl download [MODEL_NAME] --ak [AK] --sk [SK] [MODEL_DIR]2. 上传至平台仓库
将下载好的模型制品包,通过一行命令轻松上传至 veStack 平台的模型仓库中,进行统一的版本管理和存储。
全栈版:
css
./vaeutil pltpl upload -j 8 -E $TOP --region $REGION --ak $AK --sk $SK --model [MODEL_NAME] [MODEL_DIR]轻量智算版:
css
./vaeutil pltpl put --platform aio -j 8 -E $ENDPOINT -u $USER -p $PASSWORD --model [MODEL_NAME] [MODEL_DIR]请根据实际环境替换命令中的变量(如 TOP、REGION、 ENDPOINT、USER、$PASSWORD 等)。
3. 一键部署为服务
在 veStack 的 VAE 或 ServingKit 界面中,选择您刚才上传的 DeepSeek-V4 模型,并匹配官方预置的部署模板,即可一键将其发布为高可用的在线推理服务。
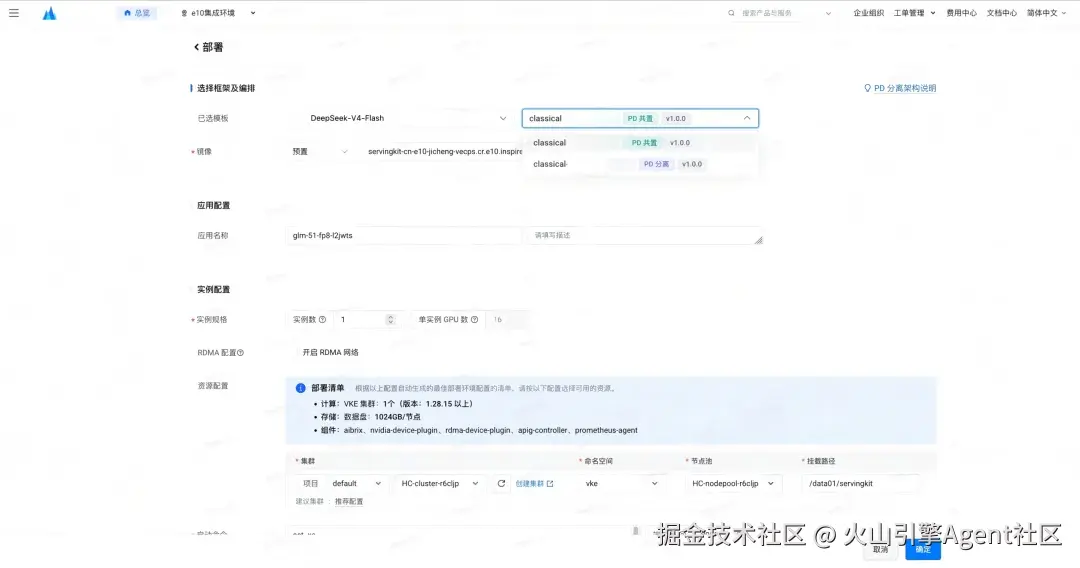
- 全栈版:进入 AI 云原生推理套件(ServingKit),创建模型服务,选择 DeepSeek-V4 模型及对应部署模板。
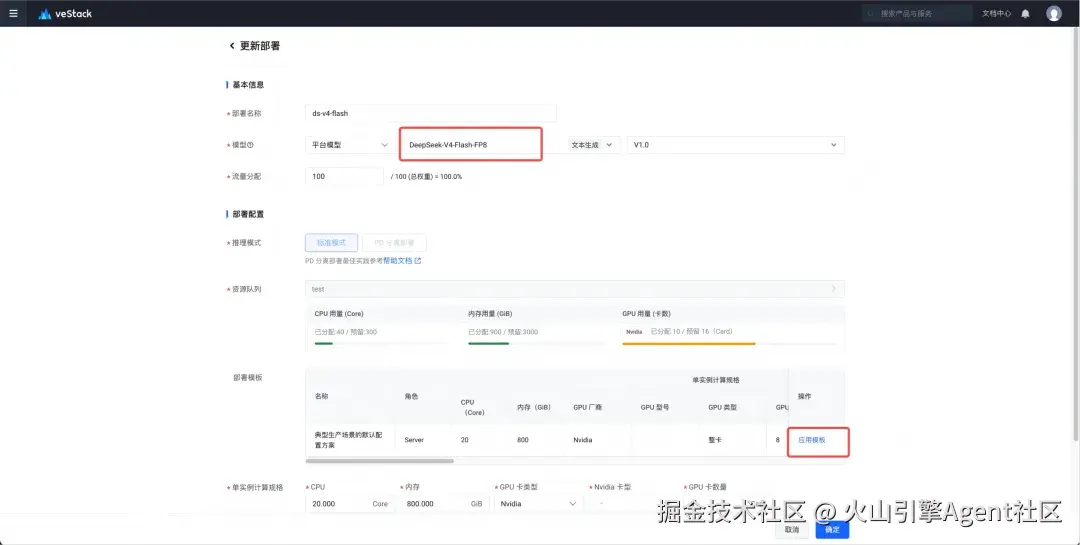
- 轻量智算版:进入 VAE(veStack Agent Engine),创建模型服务,选择 DeepSeek-V4 模型及其部署模板。
准备好在您的私有环境中部署 DeepSeek-V4 了吗?
联系您的客户经理 ,获取 veStack 平台及相关模型制品的详细信息。或访问火山引擎官网提交咨询表单,我们的专家团队将尽快与您联系,提供专属解决方案。
