1. 定位导航
上一篇解决的是"算法是什么":
text
问题 → 输入 → 有限步骤 → 输出这一篇继续往前走,讨论另一个更工程化的问题:
为什么算法不是附属品,而是一种真正的核心技术?
原因很简单:算法直接决定了系统在数据规模变大时的成本增长方式。
比如有两个程序:
- 程序 A 在小数据下很快;
- 程序 B 在小数据下也差不多;
- 但 A 的步骤数按 n2n^2n2 增长,B 的步骤数按 nlognn \log nnlogn 增长。
当 nnn 很小时,它们看起来差不多;当 nnn 很大时,它们就不再是"慢一点"和"快一点"的区别,而是"还能跑"和"跑不动"的区别。
2. 概念术语
| 术语 | 定义 | 举例 |
|---|---|---|
| 技术能力 | 可被复用、可被放大、可影响系统上限的能力 | 索引、排序、缓存、调度 |
| 输入规模 | 算法处理的数据大小,通常记为 nnn | 数组长度、节点数、请求数 |
| 增长速度 | 输入规模变大时,计算成本如何增加 | nnn、nlognn \log nnlogn、n2n^2n2 |
| 渐近分析 | 关注规模足够大时的增长趋势 | 比较 O(n)O(n)O(n) 与 O(n2)O(n^2)O(n2) |
| 常数因子 | 与硬件、语言、实现细节相关的固定倍数 | 机器快 10 倍 |
| 复杂度 | 描述时间或空间增长趋势的表达方式 | O(n)O(n)O(n)、O(logn)O(\log n)O(logn) |
| 算法工程化 | 将算法转化为稳定可维护的系统能力 | 搜索排序、数据库索引 |
关键澄清:
- 算法不是只为考试存在,它决定系统规模化能力。
- 硬件提升通常优化常数因子,算法优化可能改变增长阶。
- 小数据下差距不明显,不代表大数据下也不明显。
- 工程系统里的很多性能瓶颈,本质上都是算法或数据结构选择问题。
3. 为什么算法是一种技术
技术不是"会写某个语法",而是能稳定解决一类问题的能力。
算法之所以是一种技术,是因为它具备三个特点:
- 可迁移:同一种思想可以用在不同语言、不同系统里。
- 可放大:数据规模越大,算法差距越明显。
- 可复用:排序、查找、索引、调度、最短路径等能力可以反复出现在不同系统中。
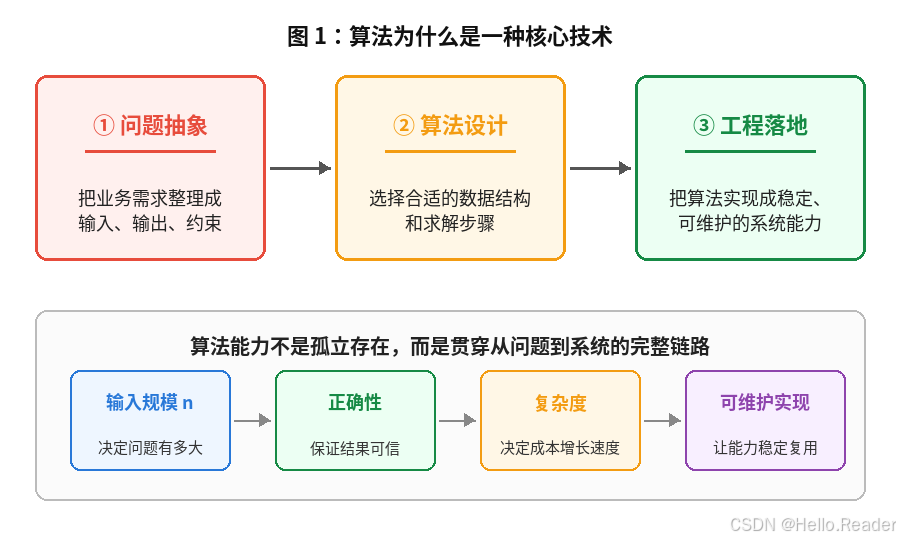
从图里可以看到,算法能力并不是孤立存在的。它连接了三个层面:
- 问题抽象:把真实需求拆成输入、输出和约束;
- 算法设计:选择合适的步骤和数据结构;
- 工程落地:把算法变成稳定的系统能力。
所以,算法不是"写完代码之后再考虑的东西",而是系统设计早期就应该考虑的核心因素。
4. 增长速度比单次速度更重要
在小规模输入下,不同算法可能差别很小。
比如处理 10 个元素:
- n2=100n^2 = 100n2=100
- nlog2n≈33n \log_2 n \approx 33nlog2n≈33
差距只有几倍。
但如果处理 1,000,000 个元素:
- n2=1012n^2 = 10^{12}n2=1012
- nlog2n≈2×107n \log_2 n \approx 2 \times 10^7nlog2n≈2×107
这时差距已经不是几倍,而是几万倍。
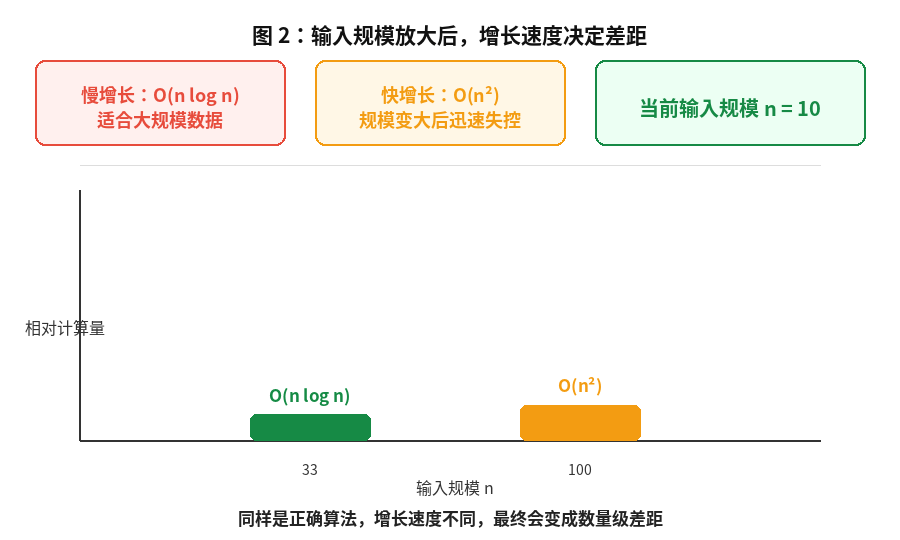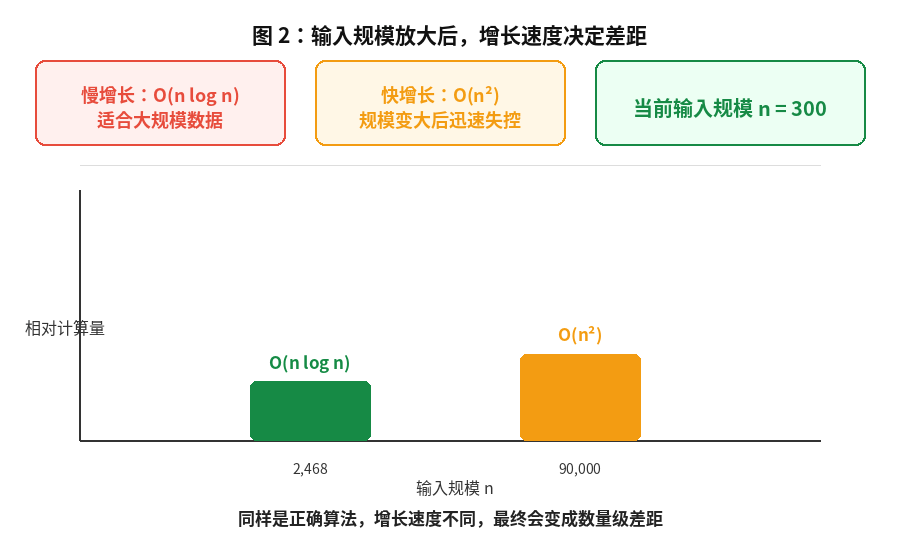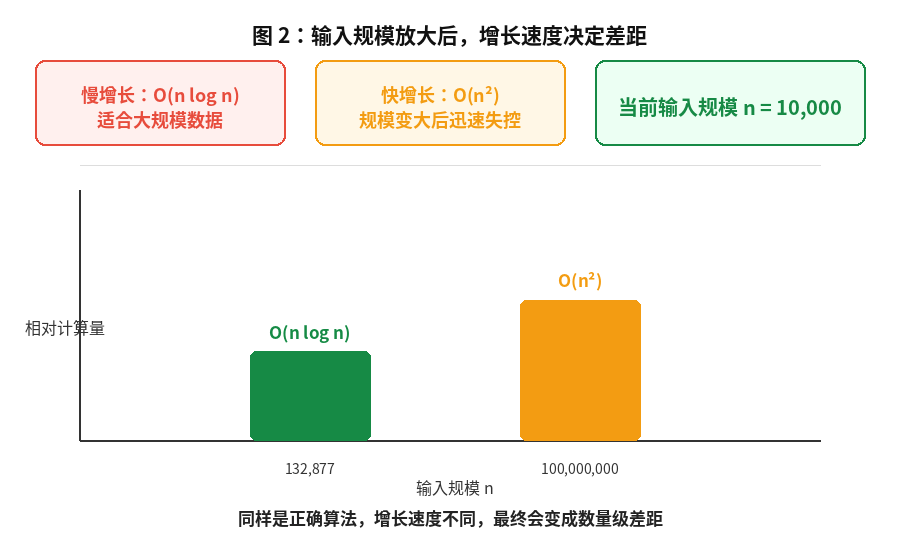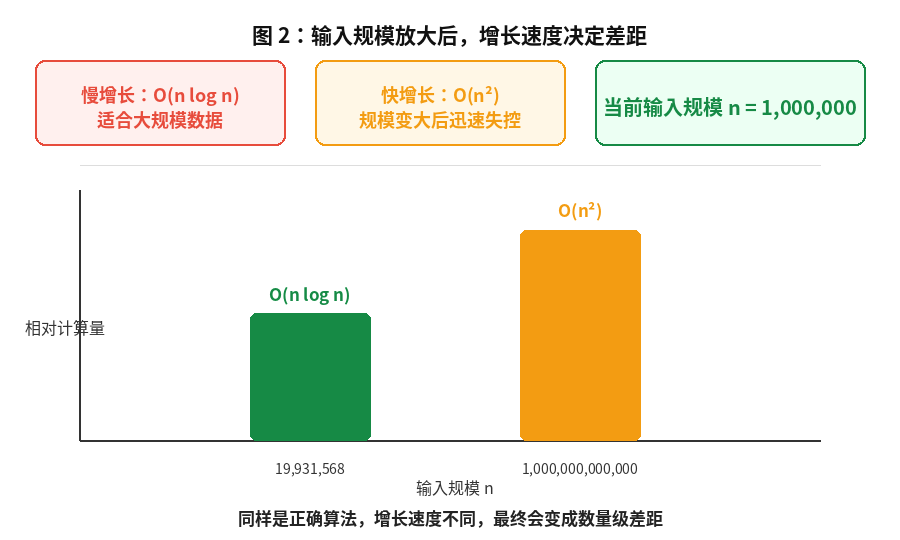
可以把这个结论记成一句话:
小数据看实现,大数据看增长阶。
这也是为什么工程中不能只看"当前测试很快",还要问:
- 数据量扩大 10 倍会怎样?
- 用户量扩大 100 倍会怎样?
- 日志量扩大到 TB 级会怎样?
- 图节点增长到亿级会怎样?
如果增长阶不对,系统迟早会撞到墙。
5. 快机器与快算法的数值推演
假设有两个方案:
| 方案 | 硬件速度 | 算法复杂度 |
|---|---|---|
| A | 快 100 倍 | O(n2)O(n^2)O(n2) |
| B | 普通机器 | O(nlogn)O(n \log n)O(nlogn) |
很多人会直觉地认为:机器 A 快 100 倍,那肯定更强。
但当输入规模变大时,结果并不一定如此。

以 n=1,000,000n = 1,000,000n=1,000,000 为例:
方案 A 的有效计算量大约是:
n2100=1012100=1010 \frac{n^2}{100} = \frac{10^{12}}{100} = 10^{10} 100n2=1001012=1010
方案 B 的计算量大约是:
nlog2n≈1,000,000×20=2×107 n \log_2 n \approx 1,000,000 \times 20 = 2 \times 10^7 nlog2n≈1,000,000×20=2×107
比较一下:
10102×107=500 \frac{10^{10}}{2 \times 10^7} = 500 2×1071010=500
也就是说,即使方案 A 的硬件快 100 倍,它仍然可能比方案 B 慢约 500 倍。
这就是算法的威力:硬件优化常数,算法优化增长方式。
6. 算法能力在工程系统中的位置
在真实系统里,算法并不会总是以"算法题"的样子出现。它经常隐藏在各种工程模块中。
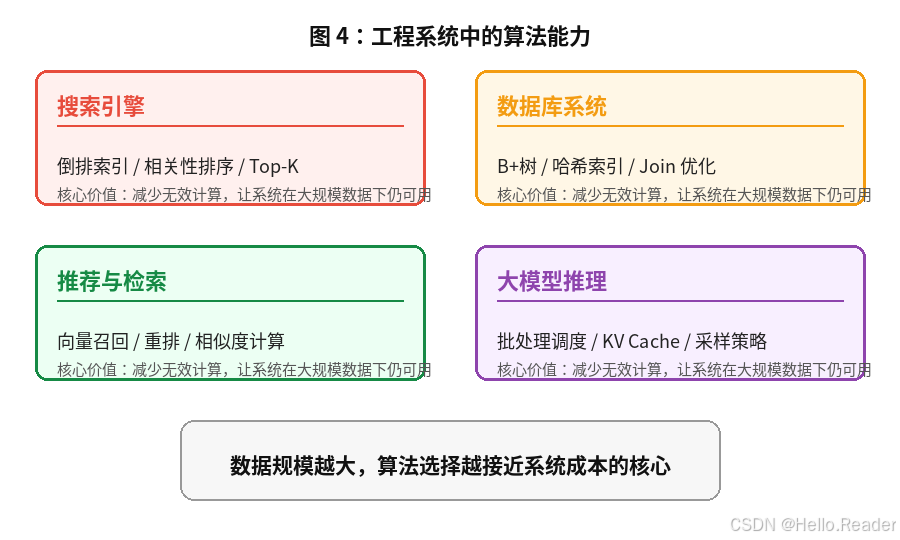
例如:
| 系统场景 | 背后的算法能力 |
|---|---|
| 搜索引擎 | 倒排索引、相关性排序、Top-K |
| 数据库 | B+ 树、哈希索引、Join 优化 |
| 推荐系统 | 召回、粗排、精排、向量检索 |
| 地图导航 | 最短路径、启发式搜索 |
| 操作系统 | 进程调度、页面置换、缓存淘汰 |
| 大模型推理 | 批处理调度、KV Cache、采样算法 |
所以,当系统遇到性能瓶颈时,排查方向不应该只停留在:
text
机器不够?线程不够?缓存不够?还应该继续追问:
text
算法是不是合适?数据结构是不是合适?复杂度是不是已经失控?7. 代码实践
下面用一段简单代码直观看看 n2n^2n2 和 nlognn \log nnlogn 的增长差异。
python
import math
def estimate_cost(n: int):
cost_n2 = n * n
cost_nlogn = int(n * math.log2(n)) if n > 1 else 1
ratio = cost_n2 / cost_nlogn
return cost_n2, cost_nlogn, ratio
if __name__ == "__main__":
sizes = [10, 100, 1_000, 10_000, 100_000, 1_000_000]
print(f"{'n':>12} | {'n^2':>18} | {'n log2 n':>18} | {'差距倍数':>12}")
print("-" * 70)
for n in sizes:
cost_n2, cost_nlogn, ratio = estimate_cost(n)
print(f"{n:>12,} | {cost_n2:>18,} | {cost_nlogn:>18,} | {ratio:>12.1f}")可能输出如下:
text
n | n^2 | n log2 n | 差距倍数
----------------------------------------------------------------------
10 | 100 | 33 | 3.0
100 | 10,000 | 664 | 15.1
1,000 | 1,000,000 | 9,965 | 100.4
10,000 | 100,000,000 | 132,877 | 752.6
100,000 | 10,000,000,000 | 1,660,964 | 6020.6
1,000,000 | 1,000,000,000,000 | 19,931,568 | 50171.7这段输出能说明一个很朴素但非常重要的事实:
输入规模越大,复杂度差异越不可能被"优化一点代码"弥补。
8. 常见误区
误区一:机器更快就一定更好
不一定。机器更快通常只能改善常数因子。如果算法增长阶太高,输入规模扩大后仍然会被拖垮。
误区二:小数据测试快,系统就没问题
不对。小数据只能说明当前规模下可用,不能说明增长后仍然可用。
误区三:算法只是刷题技巧
不对。索引、缓存、调度、检索、排序、规划,都是工程系统中真实存在的算法问题。
误区四:复杂度只是理论
复杂度不是纸面概念,而是在提醒你:当规模上来时,系统成本会按什么方式增长。
9. 现代延伸
现代系统里,算法能力常常体现在下面几个方向:
| 方向 | 典型问题 | 算法价值 |
|---|---|---|
| 高并发服务 | 请求调度、限流、负载均衡 | 降低排队和等待成本 |
| 大数据处理 | Join、GroupBy、排序、聚合 | 减少扫描和中间数据 |
| 搜索系统 | 召回、排序、重排 | 提升相关性和响应速度 |
| 向量数据库 | ANN 检索、图索引、量化 | 在海量向量中快速近似查找 |
| 模型推理 | 批处理、缓存、采样 | 降低延迟和显存压力 |
换句话说,算法能力越强,越容易在架构设计中看到这些问题的本质:
text
不是所有慢都要靠堆机器解决。
很多慢,应该先从算法和数据结构上解决。10. 思考题
- 为什么说硬件主要改善常数因子,而算法可能改变增长阶?
- 当数据规模从 1 万增长到 1 亿时,为什么 O(n2)O(n^2)O(n2) 很容易失控?
- 你工作中有没有遇到"数据量小没问题,数据量大就慢"的场景?它可能是哪类复杂度问题?
- 为什么数据库索引可以看成一种算法能力?
- 如果一个功能当前只服务 100 条数据,你还需要考虑算法复杂度吗?为什么?
11. 本篇小结
这一篇重点想说明:算法不是孤立的知识点,而是一种会直接影响工程系统上限的技术能力。
核心结论有四个:
- 算法决定计算成本如何随规模增长;
- 硬件优化常数,算法优化增长方式;
- 小规模下差距不明显,大规模下差距会被迅速放大;
- 工程系统中的索引、排序、调度、缓存、检索,本质上都离不开算法能力。
所以,学习算法不是为了背模板,而是为了建立一种判断能力:
面对一个问题,我能不能看出它的输入规模、约束条件、增长方式和更优解法?
这才是算法真正有价值的地方。