从零实现Transformer:第 2 部分 - 缩放点积注意力(Scaled Dot-Product Attention)
flyfish
对于一些名词分不清的,我特写了一篇
Transformer 架构里关于 Attention 概念的澄清
欢迎继续阅读《从零实现Transformer》系列!在第1篇:输入嵌入与位置编码 中,完成了输入预处理:将词元ID转化为融合语义信息与位置信息的向量。
接下来看注意力机制。
本篇将聚焦实现《Attention Is All You Need》论文中定义的基础模块:缩放点积注意力 。该机制能让模型在处理序列中某个元素时,自主衡量序列内其他内容的关联权重。本文将搭建缩放点积注意力的机制,完整实现掩码操作与缩放计算逻辑。
本篇学习目标
- 理解注意力三大向量:查询Q、键K、值V的底层逻辑( Query, Key, Value);
- 分步拆解缩放点积注意力计算公式;
- 基于 PyTorch 编写可复用的注意力函数;
- 利用测试数据验证代码有效性。
一、注意力:查询、键、值(Q/K/V)
可以把注意力机制类比为在图书馆检索资料:
查询向量 Q :代表「当前想查找的信息」。针对序列里的某个单词,查询向量会提出问题:序列中哪些单词和我相关?
键向量 K :代表「信息的标签(label)与标识」。序列中每个单词都有专属键向量,用来描述:我包含哪类信息?
值向量 V:代表「真实的内容信息」。每个单词的值向量,就是最终会被提取、融合的有效内容。
注意力的运行逻辑
- 将当前单词的查询向量 ,与序列所有单词的键向量逐一比对(包含自身);
- 通过向量相似度计算关联分数,分数越高,代表两者关联性越强;
- 把原始分数转化为总和为1的概率权重;
- 用权重对所有值向量做加权求和;
- 最终输出的向量,就融合了序列中所有相关单词的上下文信息。
二、缩放点积注意力
论文图中1,2,3 用的都是 缩放点积注意力
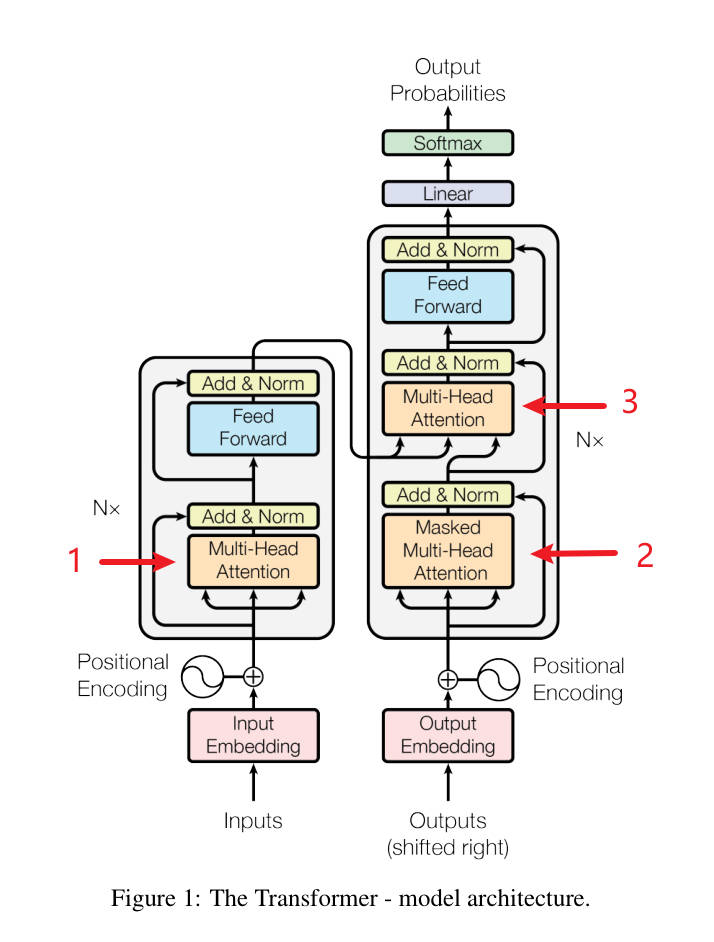
Attention部分放大了看选一个 看 蓝色的3
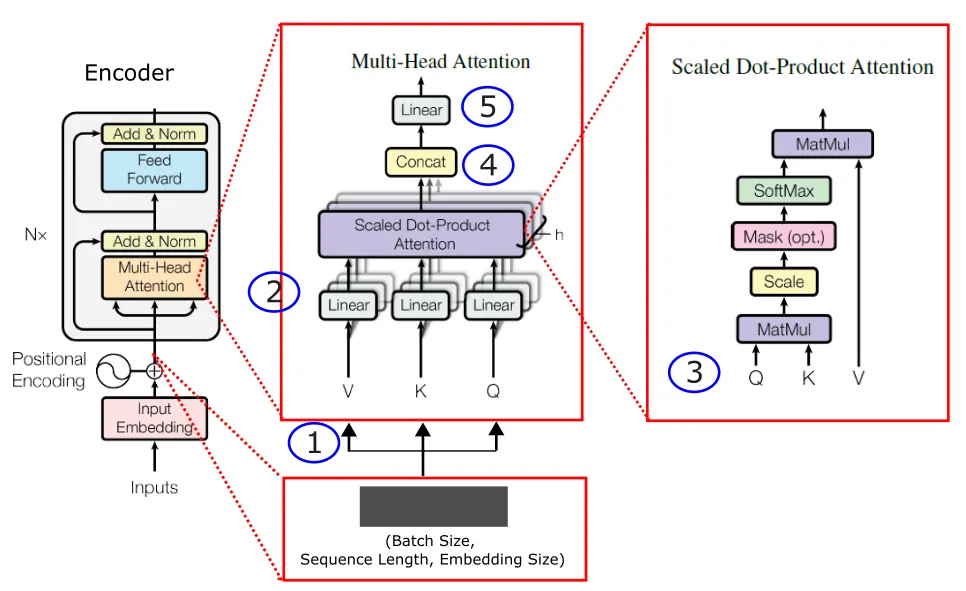
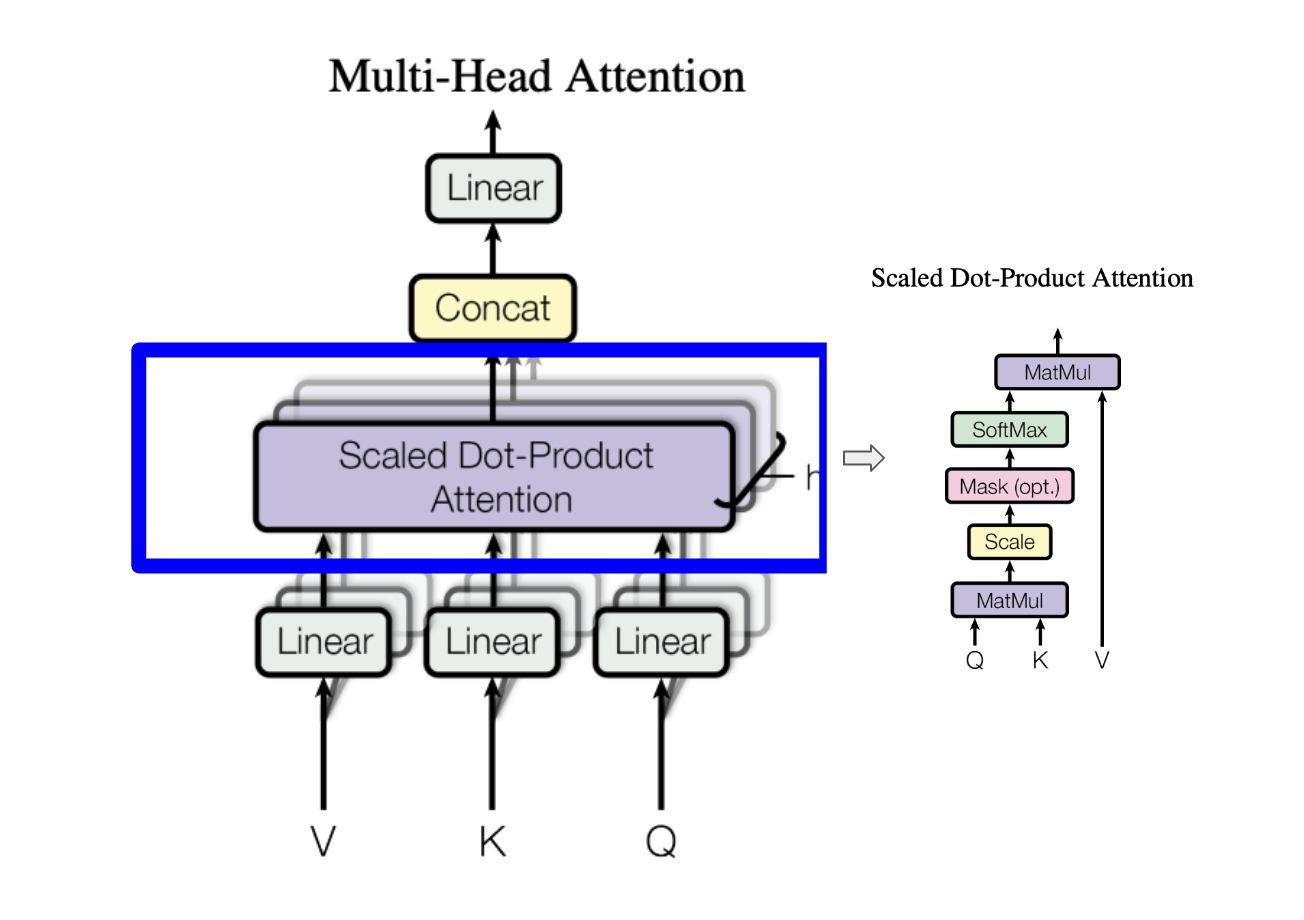
原版 Transformer 采用的注意力形式即为缩放点积注意力,计算公式源自论文《Attention Is All You Need》3.2.1章节:
Attention ( Q , K , V ) = softmax ( Q ⋅ K ⊤ d k ) ⋅ V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{Q \cdot K^\top}{\sqrt{d_k}} \right) \cdot V Attention(Q,K,V)=softmax(dk Q⋅K⊤)⋅V
公式与图的对应关系
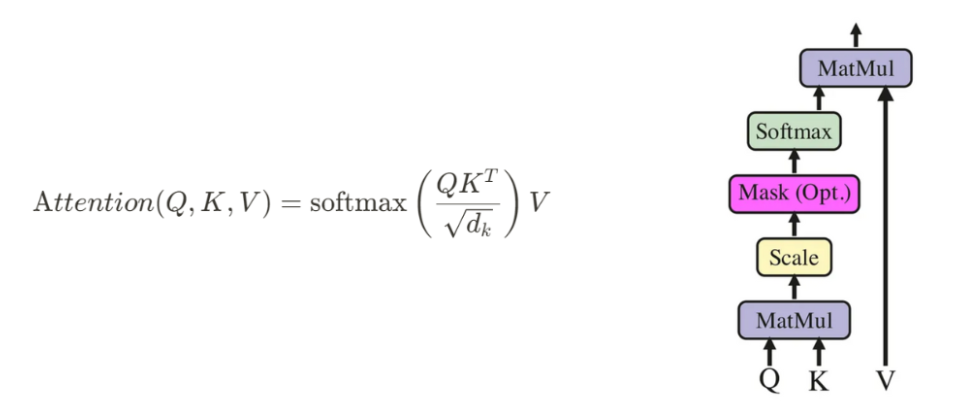
分步拆解公式:
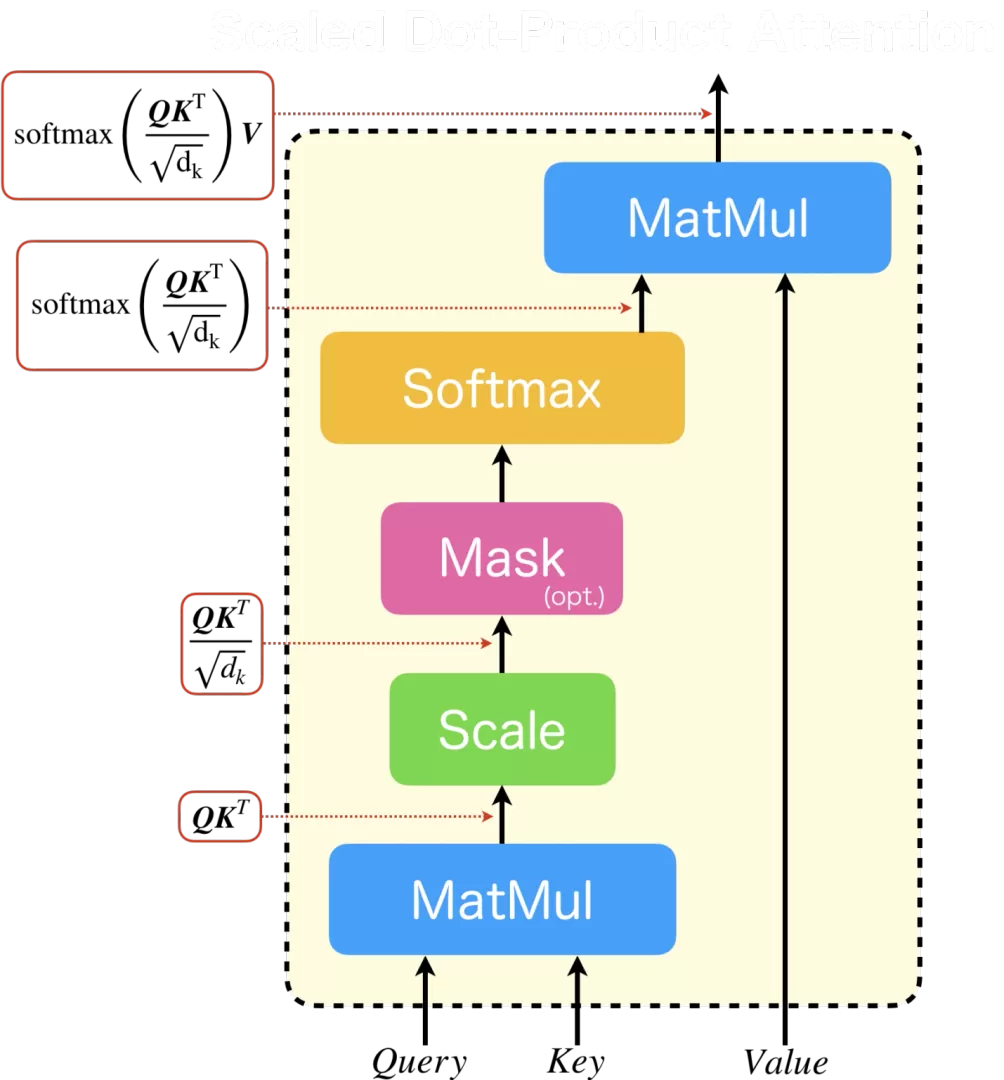
1. 矩阵相乘: Q ⋅ K ⊤ Q \cdot K^\top Q⋅K⊤
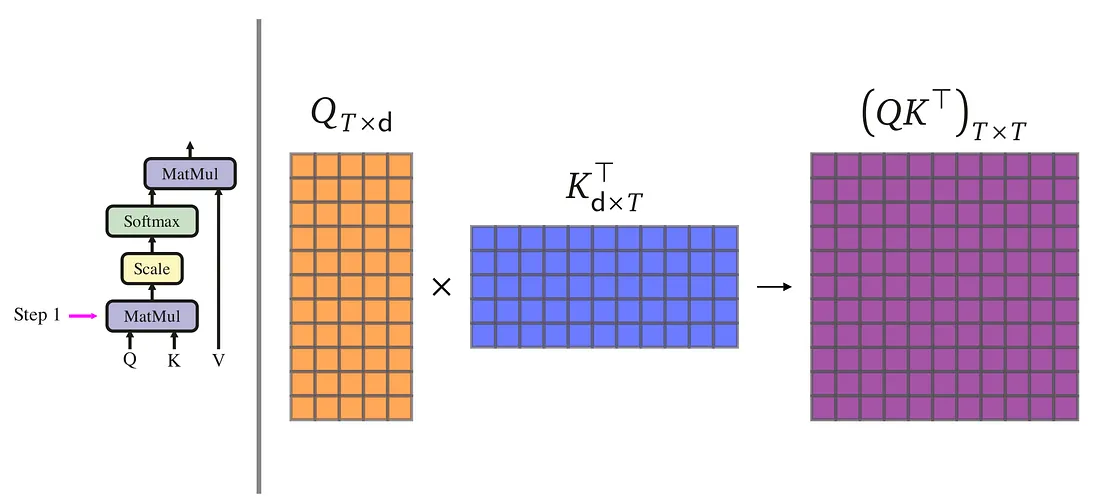 举个例子就是
举个例子就是
- 计算每个查询向量Query 与所有键向量Key的点积相似度;
- 维度规则:若 Q Q Q 形状为
[批次, 头数, 查询序列长度, 键维度], K K K 形状为[批次, 头数, 键序列长度, 键维度],则键转置后完成矩阵运算; - 输出结果:注意力原始分数矩阵,矩阵中每个数值代表两个位置的关联度。
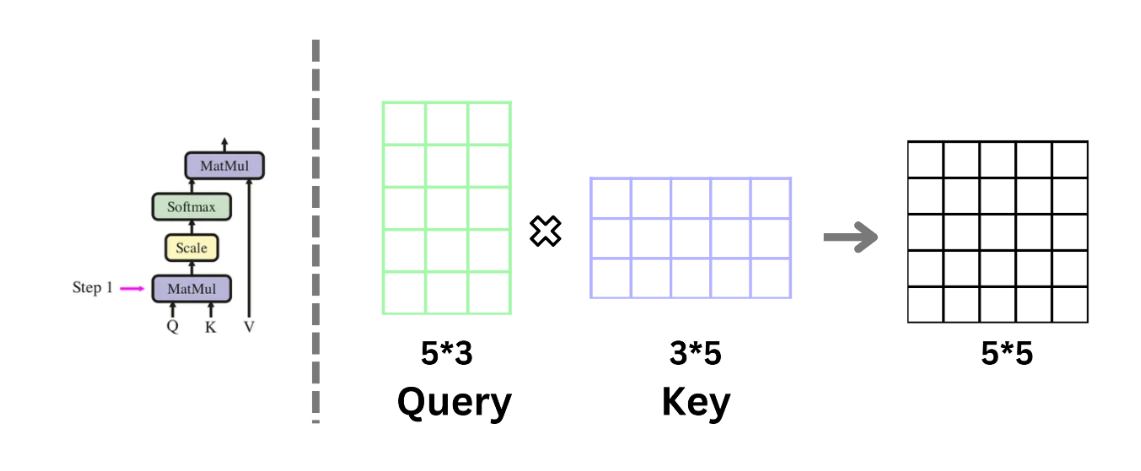
2. 缩放操作: ÷ d k \boldsymbol{\div \sqrt{d_k}} ÷dk
将分数除以键向量维度的平方根 进行缩放。
原因:当键向量维度 d k d_k dk 较大时,点积结果数值会急剧变大;
弊端:过大的数值输入 Softmax 后,梯度会趋近于0,导致模型训练困难;
作用:缩放可以限制点积数值范围,保证梯度稳定。
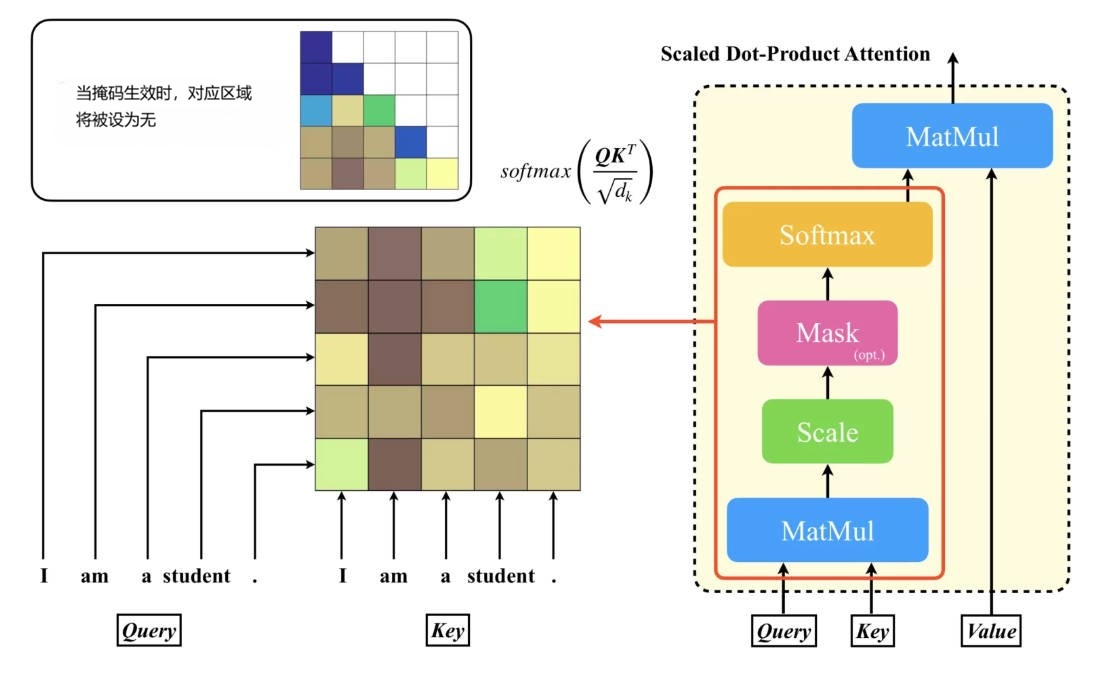
3. 可选:掩码 Mask
在执行 Softmax 归一化之前 ,通常需要添加掩码:
将需要屏蔽的位置,填充为极小负数(如 − ∞ -\infty −∞),经过 Softmax 后,这些位置的权重会趋近于0。
两种常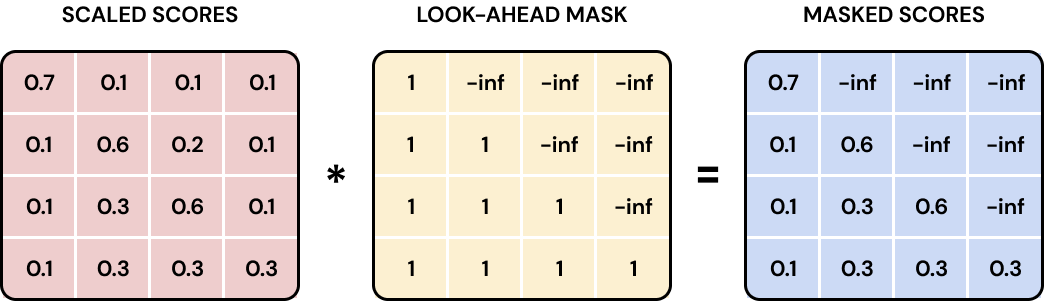
用掩码
- 填充掩码:屏蔽批次内补齐序列用的无效填充符,避免模型关注无意义占位字符;
- 前瞻掩码(解码器专用) :禁止当前位置读取序列后续内容,保证解码器自回归生成的特性(只能用前文预测下文)。
本文代码中,统一使用 -1e9 作为掩码填充值。
前瞻掩码(Look-Ahead Mask),也叫因果掩码(Causal Mask),是 Transformer 解码器(Decoder)中用于保证自回归生成的机制。
cpp
位置: 1 2 3 4 5
┌─────────────────────┐
1 │ 0 1 1 1 1 │ ← 位置1只能看自己
2 │ 0 0 1 1 1 │ ← 位置2能看1,2
3 │ 0 0 0 1 1 │ ← 位置3能看1,2,3
4 │ 0 0 0 0 1 │
5 │ 0 0 0 0 0 │ ← 位置5能看全部
└─────────────────────┘
0=允许关注 1=屏蔽(未来位置)未来位置的 attention score 被设为 -1e9
softmax 后这些位置的概率趋近于 0
加权求和时,未来位置的 value 几乎不参与计算
训练时:防止信息泄露
让模型学会"根据前n个词预测第n+1个词"
没有掩码:位置3可以同时看到位置4、5的词 → 作弊!
有掩码:位置3只能看到位置1、2、3 → 正确学习因果依赖
4. Softmax 归一化
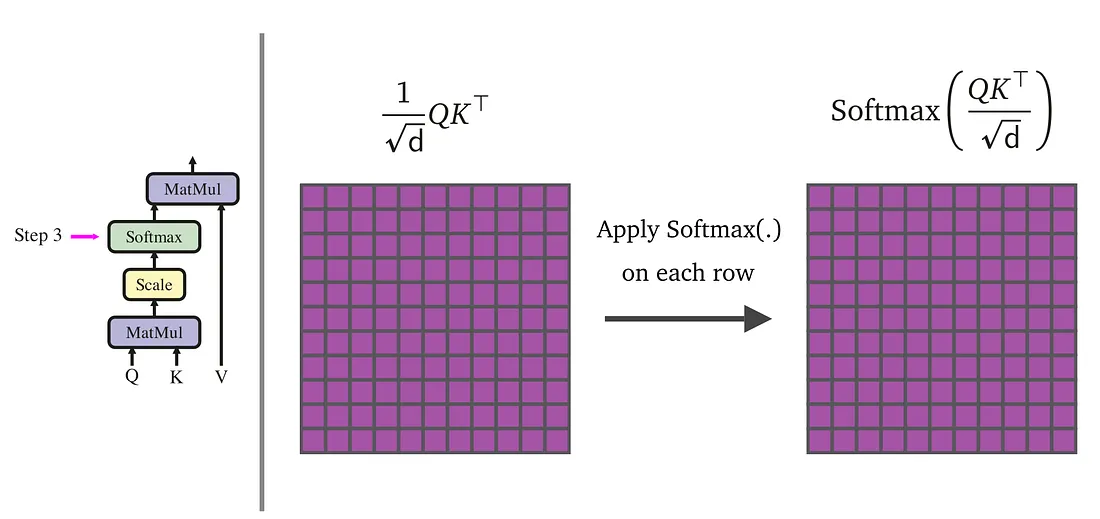
在键向量维度上做 Softmax 运算,把原始分数转为概率分布;
最终得到注意力权重矩阵,所有权重数值总和为1,直观体现每个位置的关联占比。
5. 加权求和:权重 × 值矩阵
用归一化后的注意力权重,与值矩阵 V V V 相乘;
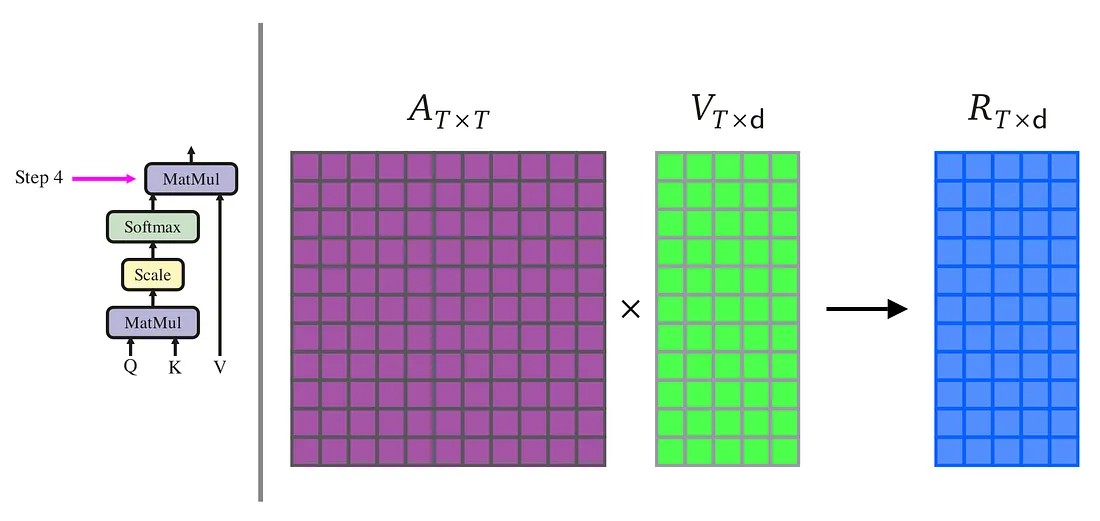
最终输出:融合全局上下文的特征向量,每个位置都结合了全序列的关联信息。
三、代码实现(PyTorch)
python
import torch
import torch.nn as nn
import math
def scaled_dot_product_attention(
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: torch.Tensor = None,
dropout: nn.Dropout = None
):
"""
实现缩放点积注意力机制
参数:
query: 查询张量,形状 [批次大小, 多头数, 查询序列长度, 键维度]
key: 键张量,形状 [批次大小, 多头数, 键序列长度, 键维度]
value: 值张量,形状 [批次大小, 多头数, 值序列长度, 值维度]
mask: 掩码张量,支持广播适配分数矩阵,True 代表需要屏蔽的位置
dropout: 可选dropout层,用于注意力权重正则化
返回:
output: 注意力输出特征
attention_weights: 注意力权重矩阵
"""
# 获取Q/K的向量维度
d_k = query.shape[-1]
# 1. 计算Q与K转置的点积,得到原始注意力分数
attention_scores = torch.matmul(query, key.transpose(-2, -1))
# 2. 维度缩放
attention_scores = attention_scores / math.sqrt(d_k)
# 3. 应用掩码
if mask is not None:
attention_scores = attention_scores.masked_fill(mask == True, -1e9)
# 4. Softmax归一化,得到注意力权重
attention_weights = torch.softmax(attention_scores, dim=-1)
# 5. 可选dropout
if dropout is not None:
attention_weights = dropout(attention_weights)
# 6. 权重与值向量加权求和,得到最终输出
output = torch.matmul(attention_weights, value)
return output, attention_weights代码说明
key.transpose(-2, -1):仅转置张量最后两个维度,适配批量矩阵运算;masked_fill:精准屏蔽无效位置,保证掩码逻辑生效;- 函数同时返回输出特征 与注意力权重,方便后续可视化分析与调试。
四、代码测试验证
我们构造随机测试张量、搭建解码器前瞻掩码,完整验证函数功能:
python
import torch
# 超参数定义
batch_size_test = 2 # 批次大小
num_heads_test = 8 # 注意力头数(下篇多头注意力会用到)
seq_len_q_test = 5 # 查询序列长度
seq_len_k_test = 7 # 键/值序列长度
d_k_test = 64 // num_heads_test
d_v_test = 64 // num_heads_test
# 构造随机测试张量
dummy_q = torch.randn(batch_size_test, num_heads_test, seq_len_q_test, d_k_test)
dummy_k = torch.randn(batch_size_test, num_heads_test, seq_len_k_test, d_k_test)
dummy_v = torch.randn(batch_size_test, num_heads_test, seq_len_k_test, d_v_test)
# 1. 无掩码测试
print("===== 无掩码测试 =====")
output_no_mask, weights_no_mask = scaled_dot_product_attention(dummy_q, dummy_k, dummy_v)
print(f"输出特征形状:{output_no_mask.shape}")
print(f"注意力权重形状:{weights_no_mask.shape}")
# 校验:权重每行总和近似为1
assert torch.allclose(weights_no_mask.sum(dim=-1), torch.ones_like(weights_no_mask.sum(dim=-1)))
print("无掩码测试通过\n")
# 2. 解码器前瞻掩码测试
mask_size = seq_len_q_test
# 生成上三角掩码(屏蔽未来位置)
look_ahead_mask = torch.triu(torch.ones(mask_size, mask_size), diagonal=1).bool()
# 拓展维度,支持广播运算
dummy_mask = look_ahead_mask.unsqueeze(0).unsqueeze(0)
# 适配自注意力:统一Q/K/V序列长度
dummy_k_masked = torch.randn(batch_size_test, num_heads_test, seq_len_q_test, d_k_test)
dummy_v_masked = torch.randn(batch_size_test, num_heads_test, seq_len_q_test, d_v_test)
print("===== 前瞻掩码测试 =====")
output_masked, weights_masked = scaled_dot_product_attention(dummy_q, dummy_k_masked, dummy_v_masked, mask=dummy_mask)
print(f"掩码形状:{dummy_mask.shape}")
print(f"掩码输出特征形状:{output_masked.shape}")
# 校验:掩码位置权重强制为0
assert torch.all(weights_masked.masked_select(dummy_mask) == 0)
print("掩码测试通过")测试逻辑说明
- 无掩码场景:校验张量维度、注意力权重归一化效果;
- 掩码场景:利用上三角矩阵屏蔽未来时间步,模拟解码器自回归约束;
- 通过断言校验逻辑,确保掩码、缩放、Softmax 全部生效。
完整源码
cpp
import torch
import torch.nn as nn
import math
def scaled_dot_product_attention(query, key, value, mask=None, dropout=None):
d_k = query.shape[-1]
attention_scores = torch.matmul(query, key.transpose(-2, -1))
attention_scores = attention_scores / math.sqrt(d_k)
if mask is not None:
attention_scores = attention_scores.masked_fill(mask == True, -1e9)
attention_weights = torch.softmax(attention_scores, dim=-1)
if dropout is not None:
attention_weights = dropout(attention_weights)
output = torch.matmul(attention_weights, value)
return output, attention_weights
if __name__ == "__main__":
batch_size_test = 2
num_heads_test = 8
seq_len_q_test = 5
seq_len_k_test = 7
d_k_test = 64 // num_heads_test
d_v_test = 64 // num_heads_test
dummy_q = torch.randn(batch_size_test, num_heads_test, seq_len_q_test, d_k_test)
dummy_k = torch.randn(batch_size_test, num_heads_test, seq_len_k_test, d_k_test)
dummy_v = torch.randn(batch_size_test, num_heads_test, seq_len_k_test, d_v_test)
print("--- 无掩码测试 ---")
output_no_mask, weights_no_mask = scaled_dot_product_attention(dummy_q, dummy_k, dummy_v)
print(f"输出形状: {output_no_mask.shape}")
print(f"权重形状: {weights_no_mask.shape}")
assert torch.allclose(weights_no_mask.sum(dim=-1), torch.ones_like(weights_no_mask.sum(dim=-1)))
print("无掩码测试通过")
print("\n--- 前瞻掩码测试 ---")
mask_size = seq_len_q_test
look_ahead_mask = torch.triu(torch.ones(mask_size, mask_size), diagonal=1).bool()
dummy_mask = look_ahead_mask.unsqueeze(0).unsqueeze(0)
dummy_k_masked = torch.randn(batch_size_test, num_heads_test, seq_len_q_test, d_k_test)
dummy_v_masked = torch.randn(batch_size_test, num_heads_test, seq_len_q_test, d_v_test)
output_masked, weights_masked = scaled_dot_product_attention(dummy_q, dummy_k_masked, dummy_v_masked, mask=dummy_mask)
print(f"掩码输出形状: {output_masked.shape}")
assert torch.all(weights_masked.masked_select(dummy_mask) == 0)
print("掩码测试通过")输出
cpp
--- 无掩码测试 ---
输出形状: torch.Size([2, 8, 5, 8])
权重形状: torch.Size([2, 8, 5, 7])
无掩码测试通过
--- 前瞻掩码测试 ---
掩码输出形状: torch.Size([2, 8, 5, 8])
掩码测试通过至此,完成了 Transformer 最的缩放点积注意力 底层实现。
原论文证明:并行运行多组独立的注意力计算 效果会大幅提升------也就是多头注意力 。下一篇就是 实现多头注意力机制(Multi-Head Attention)
Transformer - 注意⼒机制 Scaled Dot-Product Attention 计算过程
Transformer - 注意⼒机制 代码实现
Transformer - 注意⼒机制 Scaled Dot-Product Attention不同的代码比较
Transformer - 注意⼒机制 代码解释
Transformer - 注意⼒机制 Attention 中的 Q, K, V 解释(1)
Transformer - 注意⼒机制 Attention 中的 Q, K, V 解释(2)
Transformer - 《Attention is All You Need》中的Scaled Dot-Product Attention,为什么要Scaled
扩展阅读
FlashInfer - SparseAttention(稀疏注意力)只计算部分有意义的注意力连接,而非全部 token 对
DeepSpeed-Ulysses 密集自注意力(Dense Self-Attention)和稀疏自注意力(Sparse Self-Attention)