基于 Transformer 架构的翻译模型实践 - SentencePiece 输出的 token ID 到 Transformer 可处理的词向量
flyfish
参考
bash
https://github.com/shaoshengsong/ pytorch -transformer-en-zh-translation-demo本文的完整代码在文末
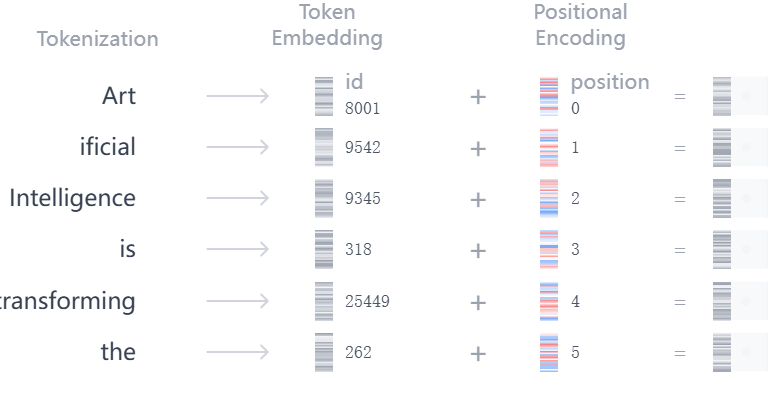
文本 → Token ID → 词嵌入 → 位置编码 → Transformer 编码器
SentencePiece 输出的是整数类型的 Token ID ,这些 ID 是词嵌入层(Embedding Layer)的索引 ;
Transformer 不直接接收 ID,而是接收连续的低维词向量 ,转换过程就是:通过 ID 查表(Lookup Table)取出对应的向量。
- 编码器侧:英文句子 → SP英文分词 → Embedding → +位置编码 → 编码器输入
- 解码器侧:中文标签 → SP中文分词 → Embedding → +位置编码 → 解码器输入
流程(训练/推理通用)
步骤1:SentencePiece 编码得到 Token ID
输入英文句子 → SentencePiece 分词 → 输出整数 ID 序列
例:"I love translation" → [10, 256, 1890, 2](包含开始/结束符)
步骤2:构造模型输入张量
将 ID 序列封装为批量张量,形状:[batch_size, sequence_length]
(Transformer 必须接收批量输入,单条推理也需要加 batch 维度)
步骤3:词嵌入层查表生成词向量
PyTorch 的 Embedding 层内部维护一个权重矩阵 :
行:对应所有 Token ID(0 ~ 词表大小-1)
列:词向量维度(Transformer 常用 512)
输入 ID → 作为索引 → 直接取出对应行的向量 → 得到词向量
步骤4:添加位置编码
词向量 + 位置编码 是最终输入给编码器/解码器的张量。
维度关系
词嵌入层的输入维度
形状:[batch_size, sequence_length]
和词表大小没有任何关系!
只和「批量大小」「句子最大长度」有关。
词嵌入层的权重矩阵维度
形状:[vocab_size, d_model]
词表大小 = 权重矩阵的行数
词表越大,需要存储的词向量越多,模型参数越大。
输出维度(词向量)
形状:[batch_size, sequence_length, d_model]
这就是 Transformer 编码器/解码器的标准输入。
python
import torch
import torch.nn as nn
import math
# ===================== 超参数设置 =====================
d_model = 512 # 模型向量维度
vocab_size = 32000 # 模拟词表大小 (和SentencePiece一致)
max_seq_len = 10 # 句子最大长度
batch_size = 1 # 批量大小(单句推理)
# ===================== 1. 模拟 SentencePiece 分词 =====================
# 原始英文句子
sentence = "Hello, this is machine translation"
# 模拟SP输出的Token ID(替代外部模型,保证代码可直接运行)
token_ids = [1, 8667, 4, 57, 16, 2702, 7962, 2]
print("原始句子:", sentence)
print("Token ID 序列:", token_ids)
# 填充到固定长度 + 构造模型输入张量 [batch_size, seq_len]
padding_length = max_seq_len - len(token_ids)
token_ids += [0] * padding_length # 用<pad>填充
input_ids = torch.tensor([token_ids])
print("输入张量形状 (input_ids):", input_ids.shape) # [1, 10]
# ===================== 2. 词嵌入层 (ID → 连续向量) =====================
embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=d_model)
word_embeddings = embedding(input_ids) # 查表生成词向量
print("词向量形状 (word_embeddings):", word_embeddings.shape) # [1, 10, 512]
# ===================== 3. 标准位置编码 (Transformer 官方实现) =====================
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(1, max_len, d_model)
pe[0, :, 0::2] = torch.sin(position * div_term)
pe[0, :, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1)]
# 初始化位置编码
pos_encoder = PositionalEncoding(d_model)
# 词向量 + 位置编码 → Transformer 最终输入
transformer_input = pos_encoder(word_embeddings)
print("加入位置编码后形状:", transformer_input.shape) # [1, 10, 512]
# ===================== 4. 输入 Transformer 编码器 =====================
# 定义极简Transformer编码器
encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=8, batch_first=True)
transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=2)
# 前向传播
encoder_output = transformer_encoder(transformer_input)
print("Transformer编码器输出形状:", encoder_output.shape) # [1, 10, 512]
# ===================== 结束 =====================
print("\n代码执行成功!全流程数据流完成!")输出
python
原始句子: Hello, this is machine translation
Token ID 序列: [1, 8667, 4, 57, 16, 2702, 7962, 2]
输入张量形状 (input_ids): torch.Size([1, 10])
词向量形状 (word_embeddings): torch.Size([1, 10, 512])
加入位置编码后形状: torch.Size([1, 10, 512])
Transformer编码器输出形状: torch.Size([1, 10, 512])
代码执行成功!全流程数据流完成!手动模拟查表 和 nn.Embedding 查表做对比
Token ID = 行号,直接取矩阵的一行就是词向量
nn.Embedding(input_ids) 等价于 查找表[input_ids]
Token ID 就是行号,没有任何计算,纯索引取值!
python
import torch
# ===================== 1. 构造一个「嵌入查找表」(矩阵) =====================
# 词表大小 = 5 (ID 0,1,2,3,4)
# 词向量维度 = 3
# 这就是 nn.Embedding 内部的权重矩阵!
lookup_table = torch.tensor([
[0.1, 0.2, 0.3], # ID=0 对应的向量
[0.4, 0.5, 0.6], # ID=1 对应的向量
[0.7, 0.8, 0.9], # ID=2 对应的向量
[1.0, 1.1, 1.2], # ID=3 对应的向量
[1.3, 1.4, 1.5] # ID=4 对应的向量
])
# ===================== 2. 输入 Token ID,直接查表取向量 =====================
token_id = 2 # 我们要查 ID=2 的向量
# 直接用 ID 当索引,取矩阵的第 2 行!
vector = lookup_table[token_id]
# ===================== 打印结果 =====================
print("查找表(嵌入矩阵):")
print(lookup_table)
print(f"\nToken ID = {token_id}")
print(f"直接查表取出的向量:{vector.numpy()}")
import torch
import torch.nn as nn
# 1. 定义 Embedding 层
emb = nn.Embedding(num_embeddings=5, embedding_dim=3)
# 2. 把上面的查找表赋值给 Embedding 的权重
emb.weight = torch.nn.Parameter(lookup_table)
# 3. 输入 ID=2
token_id = torch.tensor([2])
# 4. nn.Embedding 内部就是做了 lookup_table[token_id]
vector = emb(token_id)
print("nn.Embedding 取出的向量:", vector.detach().numpy()[0])输出
python
查找表(嵌入矩阵):
tensor([[0.1000, 0.2000, 0.3000],
[0.4000, 0.5000, 0.6000],
[0.7000, 0.8000, 0.9000],
[1.0000, 1.1000, 1.2000],
[1.3000, 1.4000, 1.5000]])
Token ID = 2
直接查表取出的向量:[0.7 0.8 0.9]
nn.Embedding 取出的向量: [0.7 0.8 0.9]