摘要------低秩张量补全 (Low-rank tensor completion,LRTC) 旨在从有限的观测条目中恢复高维结构的缺失数据。尽管最近取得了显著成功,但在 LRTC 算法中,数据张量的原始结构仍未得到有效保留,导致恢复结果的准确性较低。
此外,LRTC 算法通常会产生较高的计算成本,从而阻碍了其适用性。在这项工作中,我们提出了一种注意力引导的低秩张量补全(attention-guided low-rank tensor completion,AGTC)算法,该算法通过深度展开的注意力引导张量分解,能够忠实地恢复数据张量的原始结构(faithfully restore the original structures of data tensors)。
-
首先,我们将 LRTC 任务公式化为基于低秩和稀疏误差假设(based on low-rank and sparse error assumptions)的鲁棒分解问题。低秩张量恢复由注意力机制引导,以更好地保留原始数据的结构。
-
我们还开发了隐式正则化项来补偿建模中的不准确性。
-
然后,我们采用迭代技术来解决优化问题。
-
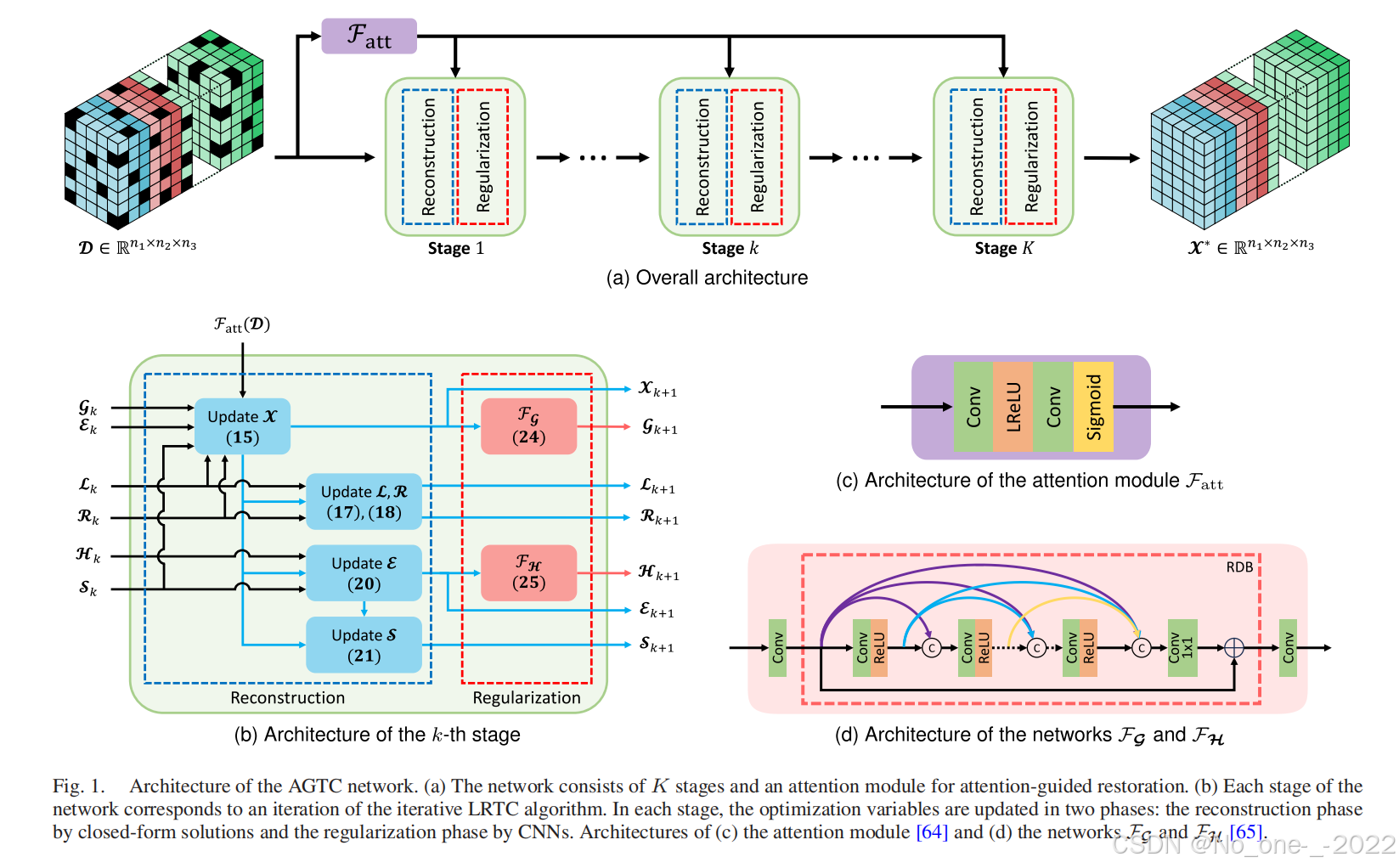
最后,我们通过展开迭代算法设计了一个多阶段深度网络,其中每个阶段对应于算法的一次迭代;在每个阶段,优化变量和正则化项(optimization variables and regularizers)分别由解析解和学习到的深度网络进行更新。
针对高动态范围成像和高光谱图像恢复的实验结果表明,所提出的算法优于现有的最先进算法。
索引术语------低秩张量补全,鲁棒张量分解,算法展开,高动态范围 (high dynamic range,HDR) 成像,高光谱图像 (hyperspectral image,HSI) 恢复。
文章目录
-
- [II. RELATED WORK](#II. RELATED WORK)
-
- [A. Low-Rank Tensor Completion](#A. Low-Rank Tensor Completion)
- [B. CNN-Aided Low-Rank Tensor Completion](#B. CNN-Aided Low-Rank Tensor Completion)
- [C. Algorithm Unfolding](#C. Algorithm Unfolding)
- [III. PROPOSED ALGORITHM---AGTC](#III. PROPOSED ALGORITHM—AGTC)
-
- [A. Notations and Definitions](#A. Notations and Definitions)
- [B. Problem Formulation](#B. Problem Formulation)
II. RELATED WORK
A. Low-Rank Tensor Completion
张量的多维结构导致了复杂的内在属性。因此,人们提出了不同的张量秩定义,从不同的方面来表征张量的秩。最常用的张量秩定义是 CANDECOMP/PARAFAC (CP) 秩 9、Tucker 秩 10、张量列秩 11、张量环秩 12 和张量管秩 13。由于这些不同的定义,针对 LRTC 开发了不同的算法。
CP 秩 9 定义为秩一 (rank-one) 张量(即形成给定张量的向量)的最小数量。尽管 CP 秩在理论方面 28, 29 和实际应用 30, 31, 32 中都取得了显著的成功,但采用 CP 秩的 LRTC 仍然具有挑战性,因为确定最优的 CP 分解是一个 NP-hard 问题 33。因此,人们提出了几种张量秩的定义,以有效表示张量的多维依赖关系。
Tucker 秩 10 是基于给定张量沿所有维度的所有展开矩阵的秩来定义的。由于该定义基于矩阵的秩,因此可以使用矩阵秩的凸替代来形成 Tucker 秩的凸替代 7。因此,Tucker 秩已被适用于几种数据补全应用 34, 35, 36。然而,Tucker 秩无法捕获展开模式之间的全局相关性,因为张量被展开成矩阵并因此丢失了它们的原始结构 37。
张量列秩 11 和张量环秩 12 分别由给定张量分解出的相互连接的核心张量的列或环计算得出,提出它们是为了克服 Tucker 秩的局限性。张量列秩可以更好地捕获全局相关性,从而提高张量恢复性能 37, 38, 39。作为张量列秩的推广,张量环秩 12 也取得了显著的成功 17, 40, 41。然而,由于其复杂的分解过程,采用张量列秩和张量环秩的算法仍然受到繁重计算的困扰。
管秩(tubal rank) 13 是基于张量奇异值分解 (t-SVD) 42 为三阶张量提出的,它比其他定义能更好地表征低秩性质,同时避免信息丢失 13, 42。管核范数 43 作为管秩的凸替代,已被广泛应用于各种成像和视觉任务的 LRTC 模型中,因为它们可以由三阶张量表示 3, 44, 45。此外,人们也尝试将管秩扩展到更高维的张量 46, 47。管秩具有优越的低秩结构建模能力,并在 LRTC 应用中展现了最先进的性能 8, 44, 45, 48。然而,尽管采用管秩的 LRTC 算法展现出了一些优势,但它们需要使用 SVD 来计算奇异张量,这在计算上是非常昂贵的。
尽管人们使用不同的张量秩定义对 LRTC 算法进行了广泛的研究,但数据张量的原始结构在它们的数学模型中仍然没有得到充分考虑,导致恢复结果不够准确。此外,优化问题的解可能会变得不准确,因为在某些情况下,真实的信号张量仅仅是近似低秩的。
B. CNN-Aided Low-Rank Tensor Completion
开发 CNN 辅助的 LRTC 算法是为了通过利用 CNN 从数据中学习多种特征并执行复杂推断的能力,来克服数学模型的局限性。例如,将 CNN 集成到 LRTC 公式中,通过从数据中提取潜在特征来学习先验知识 20, 23, 24, 25。LRTC 算法还利用 CNN 将数据张量变换到其他域,以更有效地表示低秩结构。例如,
- Bragilevsky 和 Bajić 19 采用 CNN 将输入图像变换到特征域,然后开发了一种 LRTC 算法来恢复深度特征张量。
- Liu 等人 22 和 Wang 等人 26 开发了非线性变换,以使用 CNN 对低秩张量进行建模。
- Luo 等人 21 提出了一种在变换域中基于 LRTC 的 HSI 恢复方法,其中变换是通过自监督学习使用 CNN 执行的。
- Mai 等人 5 提出了一种可解释的 HDR 成像算法,该算法将迭代 LRTC 算法展开为具有基于 CNN 的近端算子的深度网络。
尽管采用 CNN 取得了显著的成功,但由于传统的 CNN 辅助 LRTC 算法中采用的数学模型是基于范数公式的(their norm-based formulations,例如 5, 20, 45),因此它们在捕获恢复张量所需的结构信息和空间依赖性方面仍然无效;这使得忠实地保留和恢复损坏数据的原始结构这一问题仍然是一个开放的挑战。此外,传统的 CNN 辅助 LRTC 算法在计算上仍然非常昂贵,因为它们需要复杂的算子(例如 20 中的 SVD)以及复杂的深度神经网络(如 5 所示)。
C. Algorithm Unfolding
算法展开 27 是一种将基于模型的迭代算法转化为多阶段深度网络的技术,其中每个阶段对应于算法的一次单次迭代。因此,通过将迭代算法的理论鲁棒性与深度网络的数据驱动学习能力相结合,算法展开得益于这两种方法的优势,即更好的性能和可解释性。由于具有这些优势,算法展开在广泛的成像和计算机视觉应用中取得了显著的成功。
算法展开最初是为稀疏编码和压缩感知 49 开发的,这二者主要是迭代算法。后来,算法展开被应用于在各种成像应用中学习未知的模型参数,例如扩散滤波器 50、模糊核 51 和测量矩阵 52。此外,在底层计算机视觉任务中,先验和正则化项,如稀疏先验 53、去噪先验 54, 55、高斯先验 56 和退化先验 57, 58, 59,也是使用算法展开进行学习的。在这项工作中,我们提出了一种通过算法展开实现的注意力引导且计算高效的 LRTC 算法,以解决上述传统 LRTC 算法的局限性。
III. PROPOSED ALGORITHM---AGTC
我们首先介绍本文中使用的符号和定义。然后,我们开发了一个注意力引导的 LRTC 问题和一个求解它的迭代算法。最后,我们通过展开迭代优化算法,构建了一个计算高效的深度网络。
A. Notations and Definitions
我们用粗体书法体拉丁字母或大写希腊字母表示张量(例如, A \boldsymbol{\mathcal{A}} A 或 Γ \boldsymbol{\Gamma} Γ ),而非粗体书法体拉丁字母用于表示函数,例如 F att ( ⋅ ) \mathcal{F}_{\text{att}}(\cdot) Fatt(⋅) 。矩阵用粗体大写字母表示(例如, A \mathbf{A} A ),标量用斜体拉丁字母或希腊字母表示(例如, k k k 、 N N N 或 λ \lambda λ )。
在这项工作中,我们专注于三阶张量的 LRTC 问题,因为它们是图像处理和计算机视觉中最常见的数据格式。对于三阶张量 A ∈ R n 1 × n 2 × n 3 \boldsymbol{\mathcal{A}} \in \mathbb{R}^{n_1 \times n_2 \times n_3} A∈Rn1×n2×n3 ,我们将位置 ( i 1 , i 2 , i 3 ) (i_1, i_2, i_3) (i1,i2,i3) 处的元素表示为 A ( i 1 , i 2 , i 3 ) \boldsymbol{\mathcal{A}}(i_1, i_2, i_3) A(i1,i2,i3) ,并将其第 i i i 个水平切片、侧向切片和正面切片分别表示为 A ( i , : , : ) \boldsymbol{\mathcal{A}}(i, :, :) A(i,:,:) 、 A ( : , i , : ) \boldsymbol{\mathcal{A}}(:, i, :) A(:,i,:) 和 A ( : , : , i ) \boldsymbol{\mathcal{A}}(:, :, i) A(:,:,i) 。由于我们在这项工作中重点关注正面切片,为简单起见,我们将第 i i i 个正面切片表示为 A ( i ) \boldsymbol{\mathcal{A}}^{(i)} A(i) 。
接下来,我们介绍本文中使用的基本张量运算。对于一元运算,张量的 ℓ 1 \ell_1 ℓ1 范数 ∥ A ∥ 1 \|\boldsymbol{\mathcal{A}}\|_1 ∥A∥1 和 Frobenius 范数 ∥ A ∥ F \|\boldsymbol{\mathcal{A}}\|_F ∥A∥F 分别定义为
∥ A ∥ 1 = ∑ i 1 , i 2 , i 3 ∣ A ( i 1 , i 2 , i 3 ) ∣ , (2) \|\boldsymbol{\mathcal{A}}\|1 = \sum{i_1, i_2, i_3} |\boldsymbol{\mathcal{A}}(i_1, i_2, i_3)|, \tag{2} ∥A∥1=i1,i2,i3∑∣A(i1,i2,i3)∣,(2)
∥ A ∥ F = ∑ i 1 , i 2 , i 3 ∣ A ( i 1 , i 2 , i 3 ) ∣ 2 , (3) \|\boldsymbol{\mathcal{A}}\|F = \sqrt{\sum{i_1, i_2, i_3} |\boldsymbol{\mathcal{A}}(i_1, i_2, i_3)|^2}, \tag{3} ∥A∥F=i1,i2,i3∑∣A(i1,i2,i3)∣2 ,(3)
对于二元运算,两个张量 A , B ∈ R n 1 × n 2 × n 3 \boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}} \in \mathbb{R}^{n_1 \times n_2 \times n_3} A,B∈Rn1×n2×n3 的内积 ⟨ ⋅ , ⋅ ⟩ \langle \cdot, \cdot \rangle ⟨⋅,⋅⟩ 定义为
⟨ A , B ⟩ = ∑ i 1 , i 2 , i 3 A ( i 1 , i 2 , i 3 ) B ( i 1 , i 2 , i 3 ) . (4) \langle\boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}}\rangle = \sum_{i_1, i_2, i_3} \boldsymbol{\mathcal{A}}(i_1, i_2, i_3)\boldsymbol{\mathcal{B}}(i_1, i_2, i_3). \tag{4} ⟨A,B⟩=i1,i2,i3∑A(i1,i2,i3)B(i1,i2,i3).(4)
两个张量 A ∗ B \boldsymbol{\mathcal{A}} * \boldsymbol{\mathcal{B}} A∗B 乘积后的张量维度是 R n 1 × n 4 × n 3 \mathbb{R}^{n_1 \times n_4 \times n_3} Rn1×n4×n3
两个张量 A ∈ R n 1 × n 2 × n 3 \boldsymbol{\mathcal{A}} \in \mathbb{R}^{n_1 \times n_2 \times n_3} A∈Rn1×n2×n3 和 B ∈ R n 2 × n 4 × n 3 \boldsymbol{\mathcal{B}} \in \mathbb{R}^{n_2 \times n_4 \times n_3} B∈Rn2×n4×n3 的张量-张量乘积(tensor-tensor product,t-product)42 定义为
A ∗ B = fold ( bcirc ( A ) unfold ( B ) ) , (5) \boldsymbol{\mathcal{A}} * \boldsymbol{\mathcal{B}} = \text{fold}(\text{bcirc}(\boldsymbol{\mathcal{A}})\text{unfold}(\boldsymbol{\mathcal{B}})), \tag{5} A∗B=fold(bcirc(A)unfold(B)),(5)
其中 bcirc ( A ) ∈ R n 1 n 3 × n 2 n 3 \text{bcirc}(\boldsymbol{\mathcal{A}}) \in \mathbb{R}^{n_1 n_3 \times n_2 n_3} bcirc(A)∈Rn1n3×n2n3 是 A \boldsymbol{\mathcal{A}} A 的块循环矩阵
bcirc ( A ) = A ( 1 ) A ( n 3 ) ... A ( 2 ) A ( 2 ) A ( 1 ) ... A ( 3 ) ⋮ ⋮ ⋱ ⋮ A ( n 3 ) A ( n 3 − 1 ) ... A ( 1 ) , (6) \text{bcirc}(\boldsymbol{\mathcal{A}}) = \begin{bmatrix} \boldsymbol{\mathcal{A}}^{(1)} & \boldsymbol{\mathcal{A}}^{(n_3)} & \dots & \boldsymbol{\mathcal{A}}^{(2)} \\ \boldsymbol{\mathcal{A}}^{(2)} & \boldsymbol{\mathcal{A}}^{(1)} & \dots & \boldsymbol{\mathcal{A}}^{(3)} \\ \vdots & \vdots & \ddots & \vdots \\ \boldsymbol{\mathcal{A}}^{(n_3)} & \boldsymbol{\mathcal{A}}^{(n_3-1)} & \dots & \boldsymbol{\mathcal{A}}^{(1)} \end{bmatrix}, \tag{6} bcirc(A)= A(1)A(2)⋮A(n3)A(n3)A(1)⋮A(n3−1)......⋱...A(2)A(3)⋮A(1) ,(6)
unfold ( B ) = B ( 1 ) ; B ( 2 ) ; ... ; B ( n 3 ) ∈ R n 1 n 3 × n 2 \text{unfold}(\boldsymbol{\mathcal{B}}) = \\boldsymbol{\\mathcal{B}}\^{(1)}; \\boldsymbol{\\mathcal{B}}\^{(2)}; \\dots ; \\boldsymbol{\\mathcal{B}}\^{(n_3)} \in \mathbb{R}^{n_1 n_3 \times n_2} unfold(B)=B(1);B(2);...;B(n3)∈Rn1n3×n2 ,而 fold \text{fold} fold 是 unfold \text{unfold} unfold 的逆运算,即 fold ( unfold ( B ) ) = B \text{fold}(\text{unfold}(\boldsymbol{\mathcal{B}})) = \boldsymbol{\mathcal{B}} fold(unfold(B))=B 。
最后,我们将 P Ω : R n 1 × n 2 × n 3 ↦ R n 1 × n 2 × n 3 \mathcal{P}_{\Omega} : \mathbb{R}^{n_1 \times n_2 \times n_3} \mapsto \mathbb{R}^{n_1 \times n_2 \times n_3} PΩ:Rn1×n2×n3↦Rn1×n2×n3 表示为张量 A ∈ R n 1 × n 2 × n 3 \boldsymbol{\mathcal{A}} \in \mathbb{R}^{n_1 \times n_2 \times n_3} A∈Rn1×n2×n3 到对应于观测元素集合 Ω \Omega Ω 的子空间上的正交投影,即
P Ω ( A ) ( i 1 , i 2 , i 3 ) = { A ( i 1 , i 2 , i 3 ) , 如果 ( i 1 , i 2 , i 3 ) ∈ Ω , 0 , 其他情况 . (7) \\mathcal{P}_{\\Omega}(\\boldsymbol{\\mathcal{A}})(i_1, i_2, i_3) = \begin{cases} \boldsymbol{\mathcal{A}}(i_1, i_2, i_3), & \text{如果 } (i_1, i_2, i_3) \in \Omega, \\ 0, & \text{其他情况}. \end{cases} \tag{7} PΩ(A)(i1,i2,i3)={A(i1,i2,i3),0,如果 (i1,i2,i3)∈Ω,其他情况.(7)
B. Problem Formulation
我们考虑三阶张量的一般鲁棒 LRTC 问题,其中输入张量被分解为目标低秩张量和稀疏误差分量。具体而言,给定一个观测数据张量 D ∈ R n 1 × n 2 × n 3 \boldsymbol{\mathcal{D}} \in \mathbb{R}^{n_1 \times n_2 \times n_3} D∈Rn1×n2×n3 ,其条目是不完整的并且受到噪声破坏,用于数据恢复的鲁棒 LRTC 问题可以公式化为
minimize X , E rank ( X ) + ∥ E ∥ 0 subject to P Ω ( X + E ) = P Ω ( D ) , (8) \begin{aligned} \mathop{\text{minimize}}{\boldsymbol{\mathcal{X}}, \boldsymbol{\mathcal{E}}} \quad & \text{rank}(\boldsymbol{\mathcal{X}}) + \|\boldsymbol{\mathcal{E}}\|0 \\ \text{subject to} \quad & \mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{X}} + \boldsymbol{\mathcal{E}}) = \mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{D}}), \end{aligned} \tag{8} minimizeX,Esubject torank(X)+∥E∥0PΩ(X+E)=PΩ(D),(8)
其中 X \boldsymbol{\mathcal{X}} X 是待恢复的低秩张量, E \boldsymbol{\mathcal{E}} E 是稀疏误差分量, Ω ⊆ n 1 × n 2 × n 3 \boldsymbol{\Omega} \subseteq n_1 \times n_2 \times n_3 Ω⊆n1×n2×n3 是观测条目的集合, P Ω \mathcal{P}_{\boldsymbol{\Omega}} PΩ 是 (7) 中定义的投影。
正如第二节中所提到的,人们已经提出了几种张量秩的定义,以从不同方面表征张量的低秩性。在不同的定义中,我们采用管秩(tubal rank),它比其他定义能更有效地表征低秩性,同时避免信息丢失 13, 42。然而,大多数现有的采用管秩的 LRTC 算法(例如 5, 20, 45)使用 t-SVD 来计算张量范数,这需要很高的计算资源。为了克服这个限制,我们采用了一种张量分解策略 14 来实现低复杂度的 LRTC。
具体而言,具有管秩 r r r 的低秩张量 X ∈ R n 1 × n 2 × n 3 \boldsymbol{\mathcal{X}} \in \mathbb{R}^{n_1 \times n_2 \times n_3} X∈Rn1×n2×n3 可以分解为张量-张量乘积(t-product) X = L ∗ R \boldsymbol{\mathcal{X}} = \boldsymbol{\mathcal{L}} * \boldsymbol{\mathcal{R}} X=L∗R ,其中 L ∈ R n 1 × r × n 3 \boldsymbol{\mathcal{L}} \in \mathbb{R}^{n_1 \times r \times n_3} L∈Rn1×r×n3 且 R ∈ R r × n 2 × n 3 \boldsymbol{\mathcal{R}} \in \mathbb{R}^{r \times n_2 \times n_3} R∈Rr×n2×n3 。该策略避免了在 LRTC 公式中需要 SVD 来计算张量范数,从而使其在计算上更加高效。此外,张量分解防止了输入数据形状的改变并 保留了空间依赖性(preserves spatial dependencies),这在几种传统算法中是难以实现的,因为它们在执行优化之前会变换张量。例如,
- LRT-HDR 5 需要将图像向量化以用作输入,
- 而 HTNN-DCT 60 计算展平张量的张量范数。
相比之下,所提出的算法可以直接处理图像,使其适用于更广泛的应用,例如高光谱成像。通过张量分解强制管秩(By enforcing the tubal rank via tensor factorization),并使用 ℓ 1 \ell_1 ℓ1 范数 ∥ E ∥ 1 \|\boldsymbol{\mathcal{E}}\|_1 ∥E∥1 放松 ℓ 0 \ell_0 ℓ0 范数 ∥ E ∥ 0 \|\boldsymbol{\mathcal{E}}\|_0 ∥E∥0 ,(8) 中的 LRTC 问题变为
minimize L , R , X , E 1 2 ∥ L ∗ R − X ∥ F 2 + λ ∥ E ∥ 1 subject to P Ω ( X + E ) = P Ω ( D ) , (9) \begin{aligned} \mathop{\text{minimize}}_{\boldsymbol{\mathcal{L}}, \boldsymbol{\mathcal{R}}, \boldsymbol{\mathcal{X}}, \boldsymbol{\mathcal{E}}} \quad & \frac{1}{2} \|\boldsymbol{\mathcal{L}} * \boldsymbol{\mathcal{R}} - \boldsymbol{\mathcal{X}}\|F^2 + \lambda \|\boldsymbol{\mathcal{E}}\|1 \\ \text{subject to} \quad & \mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{X}} + \boldsymbol{\mathcal{E}}) = \mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{D}}), \end{aligned} \tag{9} minimizeL,R,X,Esubject to21∥L∗R−X∥F2+λ∥E∥1PΩ(X+E)=PΩ(D),(9)
其中参数 λ \lambda λ 控制两项之间的相对重要性。
请注意,(9) 中的优化问题具有与传统 LRTC 算法相同的局限性。具体而言,决定恢复张量的第一项 ∥ L ∗ R − X ∥ F 2 \|\boldsymbol{\mathcal{L}} * \boldsymbol{\mathcal{R}} - \boldsymbol{\mathcal{X}}\|_F^2 ∥L∗R−X∥F2 没有考虑恢复张量跨多个维度的空间属性和/或依赖关系(the spatial properties and/or dependencies across multiple dimensions of the recovered tensors),从而降低了它们的质量。为了解决这个问题,我们结合了注意力机制,通过定位重要区域来保留多维空间依赖关系,从而提高重建张量的完整性。(9) 中的张量分解使得集成注意力机制成为可能,因为它处理的是原始数据张量,而基于范数的公式(例如 5, 20, 45)在傅里叶变换域中处理数据张量的奇异值,这使得分析、解释和控制注意力对重建低秩张量的影响变得极其困难。然后,在注意力引导下,(9) 中的 LRTC 公式被重写为
minimize L , R , X , E 1 2 ∥ F att ( D ) ⊙ ( L ∗ R − X ) ∥ F 2 + λ ∥ E ∥ 1 subject to P Ω ( X + E ) = P Ω ( D ) , (10) \begin{aligned} \mathop{\text{minimize}}{\boldsymbol{\mathcal{L}}, \boldsymbol{\mathcal{R}}, \boldsymbol{\mathcal{X}}, \boldsymbol{\mathcal{E}}} \quad & \frac{1}{2} \|\sqrt{\mathcal{F}{\text{att}}(\boldsymbol{\mathcal{D}})} \odot (\boldsymbol{\mathcal{L}} * \boldsymbol{\mathcal{R}} - \boldsymbol{\mathcal{X}})\|F^2 + \lambda \|\boldsymbol{\mathcal{E}}\|1 \\ \text{subject to} \quad & \mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{X}} + \boldsymbol{\mathcal{E}}) = \mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{D}}), \end{aligned} \tag{10} minimizeL,R,X,Esubject to21∥Fatt(D) ⊙(L∗R−X)∥F2+λ∥E∥1PΩ(X+E)=PΩ(D),(10)
其中 F att ( D ) ∈ R n 1 × n 2 × n 3 \mathcal{F}_{\text{att}}(\boldsymbol{\mathcal{D}}) \in \mathbb{R}^{n_1 \times n_2 \times n_3} Fatt(D)∈Rn1×n2×n3 是使用 CNN 从输入数据张量计算出的注意力图, ⋅ \sqrt{\cdot} ⋅ 和 ⊙ \odot ⊙ 分别表示逐元素平方根和乘法。现在,项 ∥ L ∗ R − X ∥ F 2 \|\boldsymbol{\mathcal{L}} * \boldsymbol{\mathcal{R}} - \boldsymbol{\mathcal{X}}\|_F^2 ∥L∗R−X∥F2 由基于 CNN 的注意力引导,以更好地保留原始张量的结构,确保忠实的张量恢复。因此,基于 CNN 的注意力组件(the CNN-based attention component)缓解了忽略目标张量结构的基于范数项的局限性。
(10) 中用于 LRTC 的张量分解模型是基于某些假设建立的,即分别针对 X \boldsymbol{\mathcal{X}} X 和 E \boldsymbol{\mathcal{E}} E 的低秩性和稀疏性。然而,该模型可能无法准确表示现实世界的场景,例如,原始数据仅仅是近似低秩的,或者误差实际上是密集的;这些建模上的不准确会降低恢复精度。
因此,为了通过补偿建模误差来克服模型的局限性,我们分别对 X \boldsymbol{\mathcal{X}} X 和 E \boldsymbol{\mathcal{E}} E 采用了两个隐式正则化函数(two implicit regularization functions),即 g X : R n 1 × n 2 × n 3 ↦ R g_{\boldsymbol{\mathcal{X}}} : \mathbb{R}^{n_1 \times n_2 \times n_3} \mapsto \mathbb{R} gX:Rn1×n2×n3↦R 和 h E : R n 1 × n 2 × n 3 ↦ R h_{\boldsymbol{\mathcal{E}}} : \mathbb{R}^{n_1 \times n_2 \times n_3} \mapsto \mathbb{R} hE:Rn1×n2×n3↦R 。此外,我们考虑了类似于 5, 61 中的真实数据采集场景,即只有一组被少量噪声破坏的条目被观测到,表示为 P Ω ( D ) = P Ω ( X + E + N ) \mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{D}}) = \mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{X}} + \boldsymbol{\mathcal{E}} + \boldsymbol{\mathcal{N}}) PΩ(D)=PΩ(X+E+N) ,其中 N \boldsymbol{\mathcal{N}} N 是一个噪声张量,其噪声水平对于某个 δ > 0 \delta > 0 δ>0 满足 ∥ P Ω ( N ) ∥ F ≤ δ \|\mathcal{P}_{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{N}})\|_F \le \delta ∥PΩ(N)∥F≤δ 。我们采用一个由松弛变量组成的张量 S \boldsymbol{\mathcal{S}} S 来补偿 D \boldsymbol{\mathcal{D}} D 中的缺失和噪声条目。然后,(10) 中的注意力引导 LRTC 问题可以重写为
minimize L , R , X , E , S 1 2 ∥ F att ( D ) ⊙ ( L ∗ R − X ) ∥ F 2 + λ ∥ E ∥ 1 + g X ( X ) + h E ( E ) subject to X + E + S = P Ω ( D ) , ∥ P Ω ( S ) ∥ F ≤ δ . (11) \begin{aligned} \mathop{\text{minimize}}{\boldsymbol{\mathcal{L}}, \boldsymbol{\mathcal{R}}, \boldsymbol{\mathcal{X}}, \boldsymbol{\mathcal{E}}, \boldsymbol{\mathcal{S}}} \quad & \frac{1}{2} \|\sqrt{\mathcal{F}{\text{att}}(\boldsymbol{\mathcal{D}})} \odot (\boldsymbol{\mathcal{L}} * \boldsymbol{\mathcal{R}} - \boldsymbol{\mathcal{X}})\|F^2 \\ & + \lambda \|\boldsymbol{\mathcal{E}}\|1 + g{\boldsymbol{\mathcal{X}}}(\boldsymbol{\mathcal{X}}) + h{\boldsymbol{\mathcal{E}}}(\boldsymbol{\mathcal{E}}) \\ \text{subject to} \quad & \boldsymbol{\mathcal{X}} + \boldsymbol{\mathcal{E}} + \boldsymbol{\mathcal{S}} = \mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{D}}), \\ & \|\mathcal{P}{\boldsymbol{\Omega}}(\boldsymbol{\mathcal{S}})\|_F \le \delta. \end{aligned} \tag{11} minimizeL,R,X,E,Ssubject to21∥Fatt(D) ⊙(L∗R−X)∥F2+λ∥E∥1+gX(X)+hE(E)X+E+S=PΩ(D),∥PΩ(S)∥F≤δ.(11)
现实世界的数据往往不是完美的数学低秩,或者异常值也不是完美的稀疏。纯数学模型过于死板。因此,作者引入了这两个由神经网络(后文提到的 RDB 网络)隐式表示的正则化项。它们的作用是 凭经验 把 X \boldsymbol{\mathcal{X}} X 和 E \boldsymbol{\mathcal{E}} E 往真实世界数据的分布上拉,用来补偿纯数学建模的误差。