前言
卷积神经网络(CNN)的崛起彻底革新了计算机视觉领域。从 2012 年 AlexNet 打破传统机器学习壁垒,到 VGG、GoogLeNet、ResNet 等模型不断突破性能极限,现代 CNN 不仅推动了学术研究的跨越式发展,更在工业界落地了图像分类、目标检测、语义分割等海量应用。
本章系统拆解AlexNet、VGG、GoogLeNet、ResNet 四大经典模型的设计逻辑、结构细节与技术突破;深入解析批量规范化(BatchNorm) 的核心原理、计算流程与实战用法;基于 CIFAR-10 数据集完成端到端图像分类实战,覆盖数据预处理、模型搭建、训练调优与结果可视化全流程;结合实际学习场景总结避坑指南,配套阶段性学习计划,最后预告下章核心内容。全文兼顾理论深度与实战可操作性,适合深度学习入门者夯实 CNN 基础,也适合进阶开发者梳理经典模型演进脉络。
一、现代 CNN 演进脉络:从 LeNet 到 ResNet
在深入经典模型前,需先理清现代 CNN 的演进逻辑 ------网络深度逐步加深、卷积核尺寸逐步缩小、特征提取效率持续提升、梯度传播难题不断被解决。
1.1 前 CNN 时代的困境
2012 年之前,图像分类任务主流依赖手工特征提取 + 传统分类器(如 SVM) 的组合。手工特征(如 SIFT、HOG)依赖人工设计,泛化能力差,难以适配复杂场景;传统全连接网络处理图像时,参数规模随图像像素数爆炸(如 224×224 彩色图输入全连接层需 15 万 + 参数),易过拟合且训练效率极低。
1.2 现代 CNN 的核心突破方向
现代 CNN 通过三大核心设计,彻底解决上述困境:
- 局部感知与权重共享:卷积层仅感知局部特征,同一卷积核遍历全图,大幅减少参数量;
- 深层特征分层提取:浅层提取边缘、纹理等基础特征,深层组合基础特征形成部件、目标等高级特征;
- 梯度与正则化优化:ReLU 激活、批量规范化、残差连接等技术,解决深层网络梯度消失 / 爆炸、过拟合等问题。
1.3 经典模型演进时间线
- 1998 年:LeNet-5(7 层)------ 首个成功应用的 CNN,用于手写数字识别,奠定 CNN 基础架构;
- 2012 年:AlexNet(8 层)------ 深度学习 CV 开山之作,ImageNet 竞赛夺冠,开启 CNN 主导时代;
- 2014 年:VGG(16/19 层)------ 验证 "深度 = 性能",堆叠 3×3 小卷积核构建深层网络;
- 2014 年:GoogLeNet(Inception v1)(22 层)------ 多尺度特征融合,1×1 卷积降维,平衡性能与效率;
- 2015 年:ResNet(18/34/50/101/152 层)------ 残差连接突破深层瓶颈,解决网络退化问题。
二、经典现代 CNN 模型深度解析
2.1 AlexNet:深度学习 CV 的 "破冰者"(2012)
2.1.1 核心定位与突破
AlexNet 由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 设计,在 2012 年 ImageNet 竞赛中,将 Top-5 错误率从传统方法的 26% 降至16% ,以绝对优势夺冠,首次证明深层 CNN 在大规模复杂图像任务中的有效性,直接点燃深度学习在 CV 领域的研究热潮。
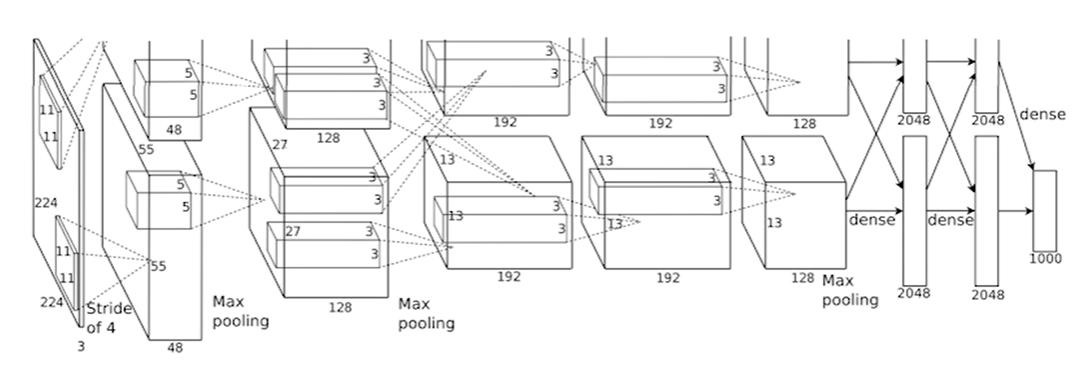
2.1.2 网络结构细节(输入:224×224×3 彩色图)
AlexNet 共 8 层:5 个卷积层 + 3 个全连接层,输出 1000 类分类结果,结构拆解如下:
- 卷积层 1(Conv1):96 个 11×11 卷积核,步长 4,ReLU 激活;输出 55×55×96,分组双 GPU 训练(每组 48 通道);
- 池化层 1(Pool1) :3×3 最大池化,步长 2;输出 27×27×96,引入重叠池化(池化核尺寸 > 步长),提升特征提取能力;
- 卷积层 2(Conv2):256 个 5×5 卷积核,步长 1,padding=2,ReLU 激活;输出 27×27×256,分组双 GPU 训练;
- 池化层 2(Pool2):3×3 最大池化,步长 2;输出 13×13×256;
- 卷积层 3(Conv3):384 个 3×3 卷积核,步长 1,Padding=1,ReLU 激活;输出 13×13×384(单 GPU);
- 卷积层 4(Conv4):384 个 3×3 卷积核,步长 1,Padding=1,ReLU 激活;输出 13×13×384(分组双 GPU);
- 卷积层 5(Conv5):256 个 3×3 卷积核,步长 1,Padding=1,ReLU 激活;输出 13×13×256(分组双 GPU);
- 池化层 3(Pool3):3×3 最大池化,步长 2;输出 6×6×256;
- 全连接层 1(FC1) :4096 神经元,ReLU 激活,Dropout(p=0.5) 防止过拟合;
- 全连接层 2(FC2):4096 神经元,ReLU 激活,Dropout(p=0.5);
- 全连接层 3(FC3) :1000 神经元,Softmax 激活,输出分类概率。
2.1.3 关键技术创新(影响深远)
- ReLU 激活函数 :替代传统 Sigmoid/Tanh,公式为f(x)=max(0,x),解决梯度消失问题,收敛速度提升 10 倍以上;
- Dropout 正则化 :训练时随机丢弃 50% 神经元,打破神经元共线性,抑制过拟合,成为后续模型标配;
- 局部响应归一化(LRN) :对相邻通道特征归一化,模拟生物视觉 "侧抑制" 机制,增强泛化能力(后续被 BatchNorm 替代);
- 双 GPU 并行训练:模型拆分到两块 GPU,突破硬件算力限制,为大模型训练提供范式;
- 数据增强 :训练时随机裁剪、水平翻转、颜色抖动,扩充数据多样性,进一步降低过拟合风险。
2.1.4 优缺点总结
- 优点:首次验证深层 CNN 有效性,技术创新(ReLU、Dropout)奠定现代 CNN 基础;
- 缺点:卷积核尺寸大(11×11、5×5),参数量达 60M,计算成本高;LRN 效果有限,后续被 BatchNorm 取代。
2.2 VGG:极简堆叠,深度为王(2014)
2.2.1 核心定位与突破
VGG(Visual Geometry Group)由牛津大学视觉几何团队设计,2014 年 ImageNet 竞赛亚军。核心贡献是验证 "网络深度是性能的关键" ,通过堆叠 3×3 小卷积核替代大卷积核,构建 16~19 层深层网络,结构极简、扩展性强。
2.2.2 核心设计理念:小卷积核替代大卷积核
VGG 证明:2 个 3×3 卷积核堆叠感受野等价于 1 个 5×5 卷积核,3 个 3×3 卷积核堆叠感受野等价于 1 个 7×7 卷积核,但有两大优势:
- 非线性更强:每堆叠 1 个 3×3 卷积核,多 1 层 ReLU 激活,增强特征表达能力;
- 参数量更少:3 个 3×3 卷积核参数量(3×3×C2×3)远少于 1 个 7×7 卷积核(7×7×C2),计算效率更高。
2.2.3 VGG 块与网络结构
(1)VGG 块(核心复用单元)
VGG 网络由5 个 VGG 块 堆叠而成,每个 VGG 块结构统一:N 个 3×3 卷积层(Padding=1,保持特征图尺寸)+ ReLU 激活 + 1 个 2×2 最大池化层(步长 2,下采样)。
PyTorch 实现 VGG 块:
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
"""
构建VGG块
num_convs: 卷积层数量
in_channels: 输入通道数
out_channels: 输出通道数
"""
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
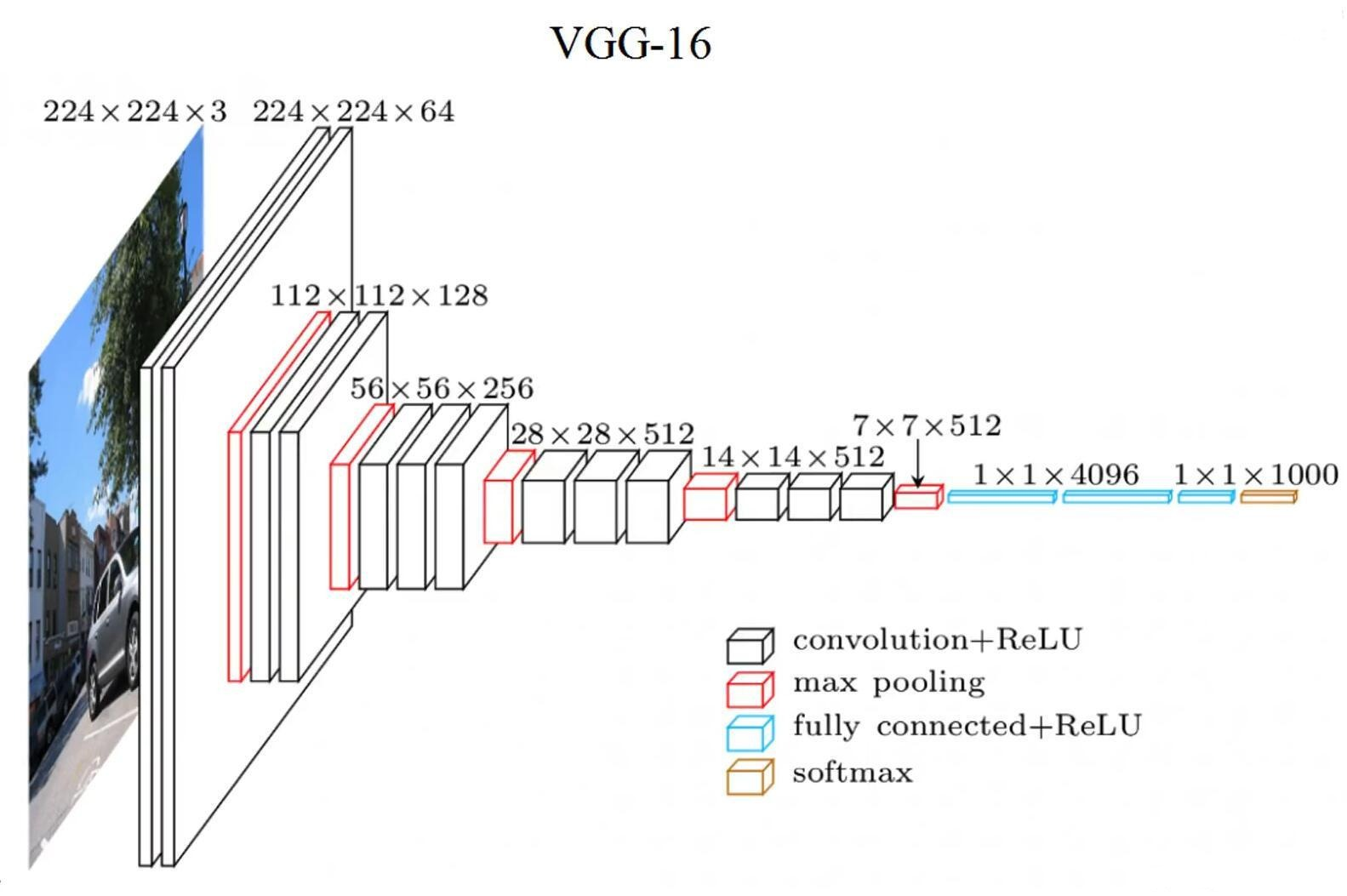
return nn.Sequential(*layers)(2)VGG-16 结构(最经典版本)
输入:224×224×3,共 16 层(13 个卷积层 + 3 个全连接层):
- 块 1:2 个卷积层(64 通道)→ 池化 → 输出 112×112×64;
- 块 2:2 个卷积层(128 通道)→ 池化 → 输出 56×56×128;
- 块 3:3 个卷积层(256 通道)→ 池化 → 输出 28×28×256;
- 块 4:3 个卷积层(512 通道)→ 池化 → 输出 14×14×512;
- 块 5:3 个卷积层(512 通道)→ 池化 → 输出 7×7×512;
- 全连接层 1:4096 神经元 + ReLU + Dropout;
- 全连接层 2:4096 神经元 + ReLU + Dropout;
- 全连接层 3:1000 神经元 + Softmax。
2.2.4 VGG-16 PyTorch 实现
# 定义VGG-16的卷积块配置:(卷积层数, 输出通道数)
conv_arch = ((2, 64), (2, 128), (3, 256), (3, 512), (3, 512))
def vgg(conv_arch):
"""构建VGG网络"""
conv_blks = []
in_channels = 3 # 输入RGB图像,3通道
# 堆叠卷积块
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
# 全连接层
return nn.Sequential(
*conv_blks, nn.Flatten(),
nn.Linear(512 * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 1000)
)
# 初始化VGG-16模型
vgg16 = vgg(conv_arch)
# 测试输入输出维度
X = torch.randn(1, 3, 224, 224)
for blk in vgg16:
X = blk(X)
print(blk.__class__.__name__, 'output shape:\t', X.shape)2.2.5 优缺点总结
- 优点:结构极简规整,易理解、易实现、易扩展;小卷积核堆叠增强非线性,特征提取能力强;
- 缺点:参数量巨大(VGG-16 约 138M),全连接层占比超 90%,计算与内存成本高;深层网络仍存在梯度消失风险。
2.3 GoogLeNet(Inception v1):多尺度融合,高效轻量(2014)
2.3.1 核心定位与突破
GoogLeNet 由 Google 团队设计,2014 年 ImageNet 竞赛冠军。核心突破是平衡性能与效率 :提出Inception 块 实现多尺度特征并行提取,用1×1 卷积降维大幅减少参数量,参数量仅为 AlexNet 的 1/12(约 6M),可高效部署在低算力设备。
2.3.2 Inception 块(核心创新单元)
(1)设计动机
单一尺寸卷积核难以适配不同尺度目标(如大目标需大卷积核,小目标需小卷积核)。Inception 块通过并行 4 条路径,同时提取 1×1、3×3、5×5 尺度特征,最后在通道维度拼接,实现多尺度特征融合。
(2)结构细节
Inception 块包含 4 条并行路径,输出通道拼接:
- 路径 1(1×1 卷积):直接提取细粒度特征,输出通道数 C1;
- 路径 2(1×1 卷积→3×3 卷积):1×1 卷积降维(减少 3×3 卷积计算量),再提取中等尺度特征,输出通道数 C2;
- 路径 3(1×1 卷积→5×5 卷积):1×1 卷积降维,再提取大尺度特征,输出通道数 C3;
- 路径 4(3×3 最大池化→1×1 卷积):池化降维,再提取特征,输出通道数 C4;
- 最终输出:C1+C2+C3+C4 通道特征图,尺寸与输入一致。
(3)1×1 卷积的核心作用
- 降维:减少 3×3、5×5 卷积的输入通道数,大幅降低计算量(如 192 通道→96 通道,计算量减半);
- 升维:可灵活调整输出通道数,适配后续网络层;
- 增强非线性:1×1 卷积后接 ReLU,增加网络非线性表达能力。
2.3.3 GoogLeNet 整体结构
- 输入:224×224×3;
- 前置层:1 个 7×7 卷积 + 池化→1 个 3×3 卷积 + 池化;
- 主体层:9 个 Inception 块堆叠,分 3 组(每组 3 个块),组间用池化下采样;
- 辅助分类器:2 个中间层辅助分类器(缓解梯度消失,增强监督);
- 输出层:全局平均池化(替代全连接层)+ Softmax,输出 1000 类概率。
2.3.4 优缺点总结
- 优点:多尺度特征融合,表达能力强;1×1 卷积降维,参数量少、计算高效;全局平均池化减少过拟合;
- 缺点:Inception 块结构复杂,设计时需手动调优各路径通道数;后续深层版本(Inception v2~v4)虽优化,但复杂度持续上升。
2.4 ResNet:残差连接,突破深层瓶颈(2015)
2.4.1 核心定位与突破
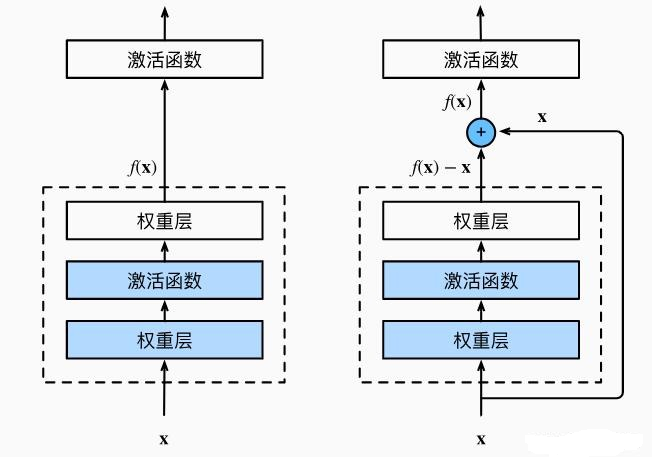
ResNet(残差网络)由何恺明团队设计,2015 年 ImageNet 竞赛冠军,现代 CNN 的里程碑模型 。核心突破是解决深层网络的 "退化问题":当网络层数超过 20 层后,准确率不升反降(梯度消失 / 爆炸导致浅层参数无法更新)。
ResNet 通过残差连接(跳跃连接) ,让网络学习 "残差函数" 而非直接学习输出,使梯度可通过恒等映射直接回传浅层,支持训练 1000 + 层超深网络,且性能随深度增加持续提升。
2.4.2 残差块(核心创新单元)
(1)残差学习原理
传统网络学习直接映射 :H(x)=F(x)(x为输入,F(x)为网络层学习的特征,H(x)为输出);ResNet 学习残差映射:H(x)=F(x)+x(F(x)为残差特征,x为恒等映射,直接跳过当前层)。
核心优势:
- 若最优映射为恒等映射(H(x)=x),网络只需学习F(x)=0,比学习恒等映射更容易;
- 梯度可通过x直接回传,避免反向传播中梯度消失,深层网络可有效训练。
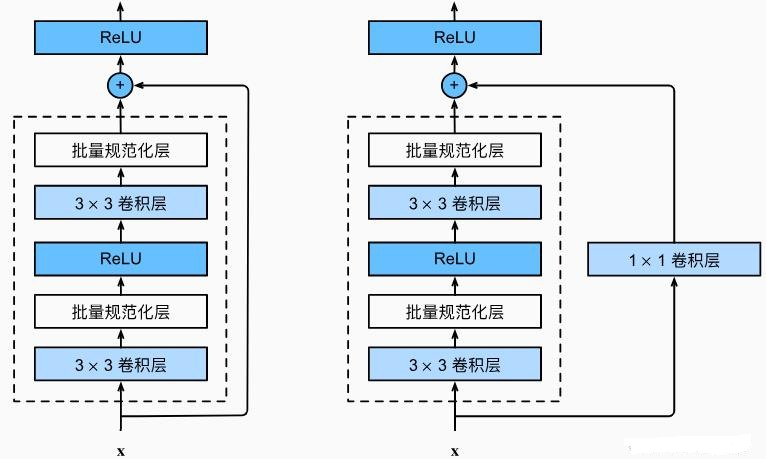
(2)基础残差块(ResNet-18/34)
适用于浅层 ResNet,结构:2 个 3×3 卷积层 + ReLU 激活 + 残差连接,输入输出通道数一致时直接恒等映射,不一致时用 1×1 卷积调整通道数。
PyTorch 实现基础残差块:
class Residual(nn.Module):
"""基础残差块"""
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
# 第一个卷积层
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
self.bn1 = nn.BatchNorm2d(num_channels)
# 第二个卷积层
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(num_channels)
# 1×1卷积(调整通道数/步长)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
def forward(self, X):
Y = torch.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X # 残差连接
return torch.relu(Y)(3)瓶颈残差块(ResNet-50/101/152)
适用于深层 ResNet,用1×1 卷积降维→3×3 卷积提取特征→1×1 卷积升维,减少深层网络计算量(如 ResNet-50 用瓶颈块,参数量仅为同深度基础块的 1/4)。
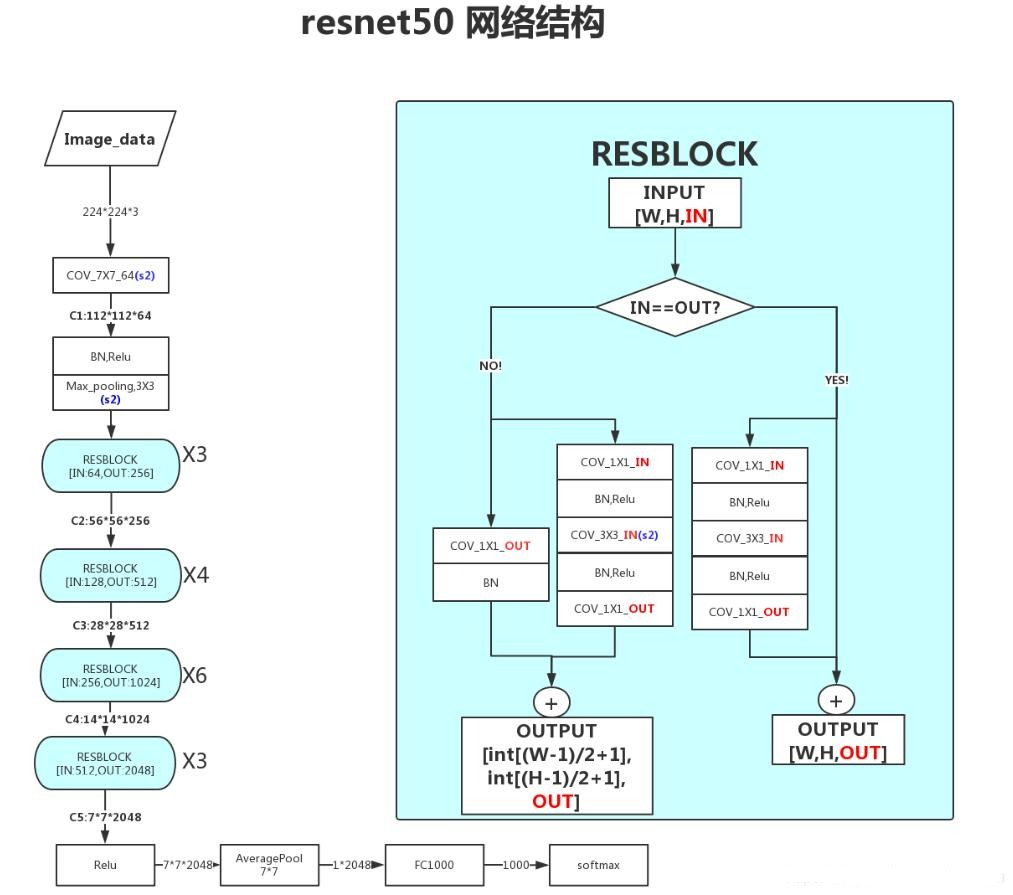
2.4.3 ResNet-18 整体结构(最常用轻量版本)
- 输入:224×224×3;
- 初始层:1 个 7×7 卷积(64 通道,步长 2)→ BatchNorm → ReLU → 3×3 最大池化(步长 2);
- 残差块组:4 组残差块(每组 2 个基础残差块),通道数依次为 64→128→256→512,组间用步长 2 下采样;
- 输出层:全局平均池化 → 全连接层(1000 神经元)→ Softmax。
2.4.4 ResNet-18 PyTorch 实现
# 定义VGG-16的卷积块配置:(卷积层数, 输出通道数)
conv_arch = ((2, 64), (2, 128), (3, 256), (3, 512), (3, 512))
def vgg(conv_arch):
"""构建VGG网络"""
conv_blks = []
in_channels = 3 # 输入RGB图像,3通道
# 堆叠卷积块
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
# 全连接层
return nn.Sequential(
*conv_blks, nn.Flatten(),
nn.Linear(512 * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 1000)
)
# 初始化VGG-16模型
vgg16 = vgg(conv_arch)
# 测试输入输出维度
X = torch.randn(1, 3, 224, 224)
for blk in vgg16:
X = blk(X)
print(blk.__class__.__name__, 'output shape:\t', X.shape)2.4.5 优缺点总结
优点:残差连接解决深层退化问题,支持超深网络训练;性能强、泛化能力好,成为 CV 领域 "通用骨架"(目标检测、分割等任务均基于 ResNet);
缺点:深层版本(ResNet-101/152)计算量仍较大,需 GPU 算力支持;残差连接增加内存占用。
三、批量规范化(BatchNorm):深层网络的 "加速器"
3.1 核心问题:内部协变量偏移(ICS)
训练深层网络时,前层参数更新会导致后层输入分布持续变化(如前层权重微调,输出均值 / 方差改变,后层需不断适应新分布),这种现象称为内部协变量偏移(ICS)。
ICS 的危害:
-
收敛速度慢:后层需反复适应新分布,训练效率极低;
-
梯度消失 / 爆炸:输入分布超出激活函数敏感区(如 Sigmoid 两端饱和区),梯度趋近于 0 或无穷大;
-
对初始化敏感:参数初始值稍有偏差,网络易陷入局部最优。
3.2 BatchNorm 核心原理
批量规范化(BatchNorm,BN)由 Ioffe 和 Szegedy 于 2015 年提出,核心思想:将输入数据标准化为 "均值 0、方差 1" 的标准分布,再通过可学习参数恢复表达能力,强制每一层输入分布稳定,彻底解决 ICS 问题。
3.3 BatchNorm 计算流程(4 步走)
针对某一层输入特征x(形状:m×C×H×W,m为 batch size,C为通道数,H/W为特征图高 / 宽),BN 对每个通道独立规范化,公式如下:
步骤 1:计算批量均值(μB)
μB=m⋅H⋅W1∑i=1m∑j=1H∑k=1Wxi,j,k(当前批次所有样本、所有空间位置的均值,按通道计算)
步骤 2:计算批量方差(σB2)
σB2=m⋅H⋅W1∑i=1m∑j=1H∑k=1W(xi,j,k−μB)2(当前批次所有样本、所有空间位置的方差,按通道计算)
步骤 3:标准化(x^)
x^=σB2+ϵx−μB(ϵ=10−5,防止分母为 0;输出均值 0、方差 1)
步骤 4:缩放与偏移(y,恢复表达能力)
y=γx^+β
- γ(缩放因子)、β(偏移因子):可学习参数,维度与通道数一致;
- 作用:若标准化破坏原始特征分布,网络可通过γ和β自适应调整,恢复表达能力;
- 最终输出:y(均值β、方差γ2)。
3.4 训练与推理的差异
训练阶段
- 用当前 batch 的均值 / 方差(μB/σB2) 规范化;
- 同时维护移动平均均值 / 方差(running_mean/running_var),公式:running_mean=0.9×running_mean+0.1×μBrunning_var=0.9×running_var+0.1×σB2
- (0.9 为动量系数,累积全局统计量)
推理阶段
- 用训练阶段累积的移动平均均值 / 方差 规范化,不使用当前 batch 统计量;
- 原因:推理时 batch size 可能为 1,统计量无意义;需用全局统计量保证稳定性。
3.5 BatchNorm 的核心作用
- 加速收敛:稳定输入分布,使梯度始终处于激活函数敏感区,收敛速度提升 5~10 倍;
- 缓解梯度消失 / 爆炸:避免输入分布极端化,梯度稳定在合理范围;
- 降低初始化敏感性:参数初始值可在更大范围选择,无需精细调优;
- 正则化效果:批量统计量引入噪声,抑制过拟合,减少 Dropout 依赖;
- 支持大学习率:可使用更大学习率,进一步加速训练。
3.6 PyTorch 中的 BatchNorm 实战
(1)常用 API
- 二维卷积层 BN:
nn.BatchNorm2d(num_features)(num_features = 通道数); - 全连接层 BN:
nn.BatchNorm1d(num_features); - 三维卷积层 BN:
nn.BatchNorm3d(num_features)。
(2)使用位置(黄金法则)
卷积层 / 全连接层 → BatchNorm → 激活函数 (BN 在激活函数前,效果最优)。
错误用法:卷积→激活→BN(激活后分布易饱和,BN 效果差)。
(3)实战示例(ResNet 残差块中的 BN)
前文 ResNet 残差块已嵌入 BN,核心代码片段:
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
self.bn1 = nn.BatchNorm2d(num_channels) # BN层,对应输出通道数
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(num_channels) # BN层
# ... 后续代码
def forward(self, X):
Y = torch.relu(self.bn1(self.conv1(X))) # 卷积→BN→激活
Y = self.bn2(self.conv2(Y))
# ... 后续代码3.7 优缺点与注意事项
- 优点:即插即用,适配所有 CNN;效果显著,工业界模型标配;
- 缺点:依赖 batch size,小 batch(<8)时效果差(统计量噪声大);增加少量参数(γ/β)与计算量;
- 注意:BN 层权重衰减设为 0 (γ/β无需正则化);推理时模型需设为
eval()模式,冻结移动平均统计量。
四、图像分类实战:基于 PyTorch 与 CIFAR-10
4.1 任务与数据集介绍
4.1.1 任务目标
训练一个 CNN 模型,对 CIFAR-10 数据集的 10 类彩色图像进行分类,目标准确率≥85%。
4.1.2 CIFAR-10 数据集
- 规模:60000 张 32×32 彩色图(50000 训练集 + 10000 测试集);
- 类别:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车(每类 6000 张);
- 特点:图像分辨率低(32×32),但场景复杂、目标多样,适合入门级 CNN 实战。

4.2 环境准备与依赖安装
# 安装PyTorch与torchvision(GPU版本,需CUDA支持)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装辅助库
pip install matplotlib d2l torchinfo4.3 数据预处理与加载
4.3.1 数据增强(训练集)
- 随机裁剪:32×32→28×28,再补回 32×32,增加位置鲁棒性;
- 随机水平翻转:概率 0.5,增强视角多样性;
- 归一化:像素值 0,255→-1,1,适配 ReLU 激活;
- 转换为张量:适配 PyTorch 输入格式。
4.3.2 数据加载代码
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 设备配置(优先GPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 训练集预处理(含数据增强)
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化到[-1,1]
])
# 测试集预处理(无增强,仅归一化)
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载数据集
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train
)
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test
)
# 数据加载器(batch size=128,shuffle=True打乱训练集)
trainloader = DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
# 类别标签
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']4.4 模型搭建(改进版 ResNet-18)
针对 CIFAR-10(32×32 小图),简化 ResNet-18:移除初始 7×7 卷积与池化,改用 3×3 卷积,避免特征图尺寸过小。
import torch.nn as nn
import torch.nn.functional as F
# 残差块(复用前文Residual类)
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
self.bn1 = nn.BatchNorm2d(num_channels)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(num_channels)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
# 改进版ResNet-18(适配CIFAR-10)
class CIFARResNet18(nn.Module):
def __init__(self):
super().__init__()
# 初始层:3×3卷积(适配32×32输入)
self.b1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1, stride=1),
nn.BatchNorm2d(64), nn.ReLU()
)
# 残差块组
self.b2 = nn.Sequential(*self._resnet_block(64, 64, 2, first_block=True))
self.b3 = nn.Sequential(*self._resnet_block(64, 128, 2))
self.b4 = nn.Sequential(*self._resnet_block(128, 256, 2))
self.b5 = nn.Sequential(*self._resnet_block(256, 512, 2))
# 输出层
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512, 10)
def _resnet_block(self, input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
def forward(self, X):
X = self.b1(X)
X = self.b2(X)
X = self.b3(X)
X = self.b4(X)
X = self.b5(X)
X = self.avg_pool(X)
X = torch.flatten(X, 1)
X = self.fc(X)
return X
# 初始化模型并移至GPU
model = CIFARResNet18().to(device)4.5 损失函数、优化器与训练配置
import torch.optim as optim
# 损失函数:交叉熵损失(分类任务标配)
criterion = nn.CrossEntropyLoss()
# 优化器:Adam(自适应学习率,收敛快、稳定)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
# 学习率调度器:每10轮学习率减半
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 训练轮数
NUM_EPOCHS = 254.6 训练与评估循环
import matplotlib.pyplot as plt
# 记录训练过程
history = {
'train_loss': [],
'train_acc': [],
'test_loss': [],
'test_acc': []
}
def train_epoch(model, loader, optimizer, criterion, device):
"""训练1轮"""
model.train()
running_loss = 0.0
correct = 0
total = 0
for i, data in enumerate(loader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播、计算损失、反向传播、参数更新
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 统计损失与准确率
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 每100个batch打印日志
if i % 100 == 99:
print(f'[{epoch + 1}, {i + 1}] loss: {running_loss / 100:.3f}')
running_loss = 0.0
# 计算本轮训练准确率
train_acc = 100 * correct / total
return running_loss / len(loader), train_acc
def test_epoch(model, loader, criterion, device):
"""测试1轮"""
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for data in loader:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_acc = 100 * correct / total
return test_loss / len(loader), test_acc
# 开始训练
print("开始训练...")
for epoch in range(NUM_EPOCHS):
# 训练
train_loss, train_acc = train_epoch(model, trainloader, optimizer, criterion, device)
# 测试
test_loss, test_acc = test_epoch(model, testloader, criterion, device)
# 更新学习率
scheduler.step()
# 记录历史
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['test_loss'].append(test_loss)
history['test_acc'].append(test_acc)
# 打印本轮结果
print(f'Epoch {epoch+1} - '
f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, '
f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%')
# 保存模型
torch.save(model.state_dict(), 'cifar_resnet18.pth')
print('训练完成,模型已保存为 cifar_resnet18.pth')4.7 结果可视化与分析
# 绘制损失曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='Train Loss')
plt.plot(history['test_loss'], label='Test Loss')
plt.title('Loss Curve')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# 绘制准确率曲线
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='Train Acc')
plt.plot(history['test_acc'], label='Test Acc')
plt.title('Accuracy Curve')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.tight_layout()
plt.show()预期结果
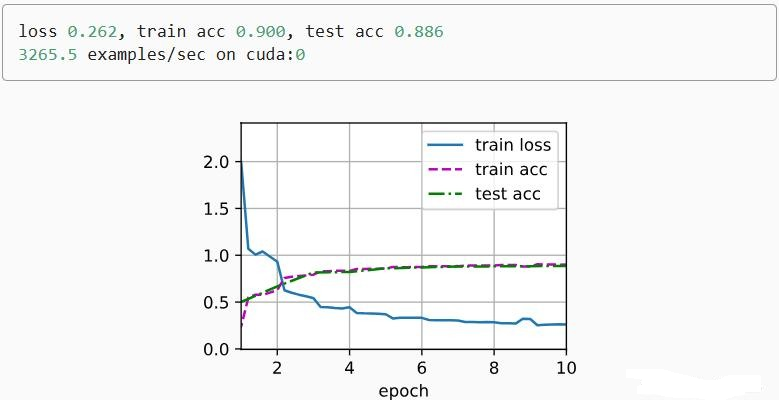
- 训练 25 轮后,测试准确率≥85%,训练准确率≥95%;
- 损失曲线:训练损失持续下降,测试损失先降后稳定,无明显过拟合;
- 准确率曲线:训练与测试准确率同步上升,后期趋于平稳。
4.8 模型推理与单张图像测试
from PIL import Image
# 加载模型
model.load_state_dict(torch.load('cifar_resnet18.pth'))
model.eval()
# 预处理单张图像
def preprocess_image(image_path):
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
image = Image.open(image_path).convert('RGB')
image = transform(image).unsqueeze(0).to(device)
return image
# 推理
def predict_image(image_path):
image = preprocess_image(image_path)
with torch.no_grad():
outputs = model(image)
_, predicted = torch.max(outputs, 1)
return classes[predicted[0]]
# 测试(替换为你的图像路径)
image_path = 'test_plane.jpg'
print(f'预测结果:{predict_image(image_path)}')五、实际学习场景 & 避坑指南
5.1 经典模型学习避坑
(1)AlexNet
- 坑 1:直接用原始 AlexNet 训练小数据集(如 CIFAR-10)→ 过拟合严重;✅ 解法:减少卷积层通道数、增加 Dropout 概率、强化数据增强;
- 坑 2:忽略 LRN 层→ 复现准确率低;✅ 解法:严格按原始结构实现 LRN,或直接用 BatchNorm 替代(效果更好)。
(2)VGG
- 坑 1:训练 VGG-16 时显存爆炸→ GPU 内存不足;✅ 解法:减小 batch size(如从 128 降至 32)、用梯度累积、换 ResNet 等轻量模型;
- 坑 2:全连接层参数量过大→ 训练慢、过拟合;✅ 解法:用全局平均池化替代全连接层,减少 90% 参数量。
(3)ResNet
- 坑 1:残差块中 BN 位置错误(激活后)→ 收敛慢、准确率低 ;✅ 解法:严格遵循卷积→BN→激活顺序;
- 坑 2:深层 ResNet(50 + 层)训练时梯度消失→ 准确率不升;✅ 解法:用瓶颈残差块、增加 BatchNorm、调整学习率。
5.2 BatchNorm 实战避坑
- 坑 1:小 batch(<8)用 BatchNorm→ 效果差、不稳定;✅ 解法:改用 LayerNorm、增大 batch size、用梯度累积模拟大 batch;
- 坑 2:推理时模型不设
eval()→ 结果错误 ;✅ 解法:推理前必须model.eval(),训练前model.train(); - 坑 3:BN 层加权重衰减→ 性能下降;✅ 解法:优化器中仅对卷积 / 全连接层权重加衰减,BN 层γ/β不加。
5.3 图像分类实战避坑
- 坑 1:数据增强过度→ 数据失真、准确率下降;✅ 解法:仅用随机裁剪、翻转等基础增强,避免复杂扭曲、噪声;
- 坑 2:学习率过大→ 损失震荡、不收敛;✅ 解法:初始学习率设 0.001(Adam),用学习率调度器动态调整;
- 坑 3:过拟合(训练 acc>95%,测试 acc<70%)→ 泛化差;✅ 解法:增加数据增强、加 Dropout / 权重衰减、减小模型复杂度、早停。
5.4 硬件与环境避坑
- 坑 1:用 CPU 训练深层 CNN→ 速度极慢(1 轮需数小时);✅ 解法:用 GPU 训练(NVIDIA 显卡,CUDA≥11.8),无 GPU 用 Google Colab;
- 坑 2:PyTorch 版本不兼容→ 代码报错;✅ 解法:安装稳定版 PyTorch(2.0+),避免最新测试版。
六、学习计划 & 下章预告
6.1 阶段性学习计划(7 天掌握本章内容)
第 1 天:CNN 基础复习
- 学习目标:掌握卷积、池化、激活函数核心原理;
- 任务:复习 LeNet-5 结构,推导卷积输出维度公式,实现基础卷积层。
第 2 天:AlexNet 与 VGG
- 学习目标:理解 AlexNet 创新点、VGG 小卷积核设计逻辑;
- 任务:复现 AlexNet 与 VGG-16 代码,对比两者参数量差异,训练小数据集验证效果。
第 3 天:GoogLeNet 与 ResNet
- 学习目标:掌握 Inception 块多尺度融合、残差连接解决退化问题;
- 任务:实现 Inception 块与 ResNet-18 残差块,对比 ResNet 与 VGG 训练速度与准确率。
第 4 天:批量规范化(BatchNorm)
- 学习目标:理解 ICS 问题、BatchNorm 计算流程与训练 / 推理差异;
- 任务:在 ResNet 中嵌入 BatchNorm,对比有无 BN 的训练收敛速度,总结 BN 使用技巧。
第 5 天:图像分类实战(数据与模型)
- 学习目标:掌握 CIFAR-10 数据预处理、数据增强、模型搭建;
- 任务:完成数据加载代码,搭建改进版 ResNet-18,调试模型维度匹配问题。
第 6 天:训练调优与结果分析
- 学习目标:掌握损失函数、优化器选择,学习率调度,结果可视化;
- 任务:完成训练与评估循环,调优超参数(学习率、batch size),绘制损失 / 准确率曲线。
第 7 天:复盘与项目实战
- 学习目标:梳理经典模型演进脉络,总结避坑指南;
- 任务:用 ResNet-18 训练自定义小数据集(如花卉分类),完成端到端项目,记录问题与解决方法。
6.2 下章内容预告
下一章将聚焦计算机视觉进阶任务,核心内容包括:
- 目标检测基础:从图像分类到目标检测的任务演进,边界框、交并比(IoU)、非极大值抑制(NMS)核心概念;
- 经典目标检测模型:R-CNN、Fast R-CNN、Faster R-CNN 两阶段检测模型,YOLO、SSD 单阶段检测模型的设计逻辑与优缺点;
- PyTorch 目标检测实战:基于 Faster R-CNN 训练 PASCAL VOC 数据集,实现目标检测、模型评估与结果可视化;
- 进阶优化技巧:锚框设计、损失函数调优、数据增强适配、模型轻量化部署。
七、结尾互动
恭喜你完成本章学习!从 AlexNet 到 ResNet,从理论到实战,你已掌握现代 CNN 核心技术与图像分类端到端流程,为后续计算机视觉进阶打下坚实基础。
互动环节
- 点赞:如果本章内容对你有帮助,点赞支持,鼓励创作更多深度学习干货;
- 收藏:收藏本文,方便后续复习经典模型结构、BatchNorm 原理与实战代码;
- 关注:关注我,持续获取《动手学深度学习》系列完整笔记、实战代码与进阶教程,下章目标检测内容更精彩!
评论区交流
欢迎在评论区留言:
- 你在学习本章时遇到了哪些问题?
- 你最想深入了解哪个模型(AlexNet/VGG/ResNet)?
- 你希望后续实战什么数据集或任务?
我会逐一回复,和大家一起交流学习、共同进步!