位置感知注意力与跨阶段部分网络改进YOLOv26特征提取与全局建模能力双重提升
1. 引言
在目标检测领域,特征提取的质量直接决定了模型的检测性能。传统的卷积神经网络虽然能够有效提取局部特征,但在捕获长距离依赖关系和全局上下文信息方面存在明显不足。为了解决这一问题,本文提出了一种基于C2PSA(Cross Stage Partial with Position-Sensitive Attention)模块的YOLOv26改进方案,通过将位置感知注意力机制与跨阶段部分网络相结合,在保持计算效率的同时显著提升了模型的特征表达能力。
C2PSA模块的核心创新在于:将多头自注意力机制引入跨阶段部分网络架构,通过双路径特征处理策略,既保留了原始特征的完整性,又增强了特征的全局建模能力。这种设计使得模型能够在不同尺度上更好地理解目标的空间关系和语义信息。
2. C2PSA模块核心原理
2.1 整体架构设计
C2PSA模块采用了跨阶段部分网络(Cross Stage Partial Network)的设计思想,将输入特征分为两个路径进行处理:
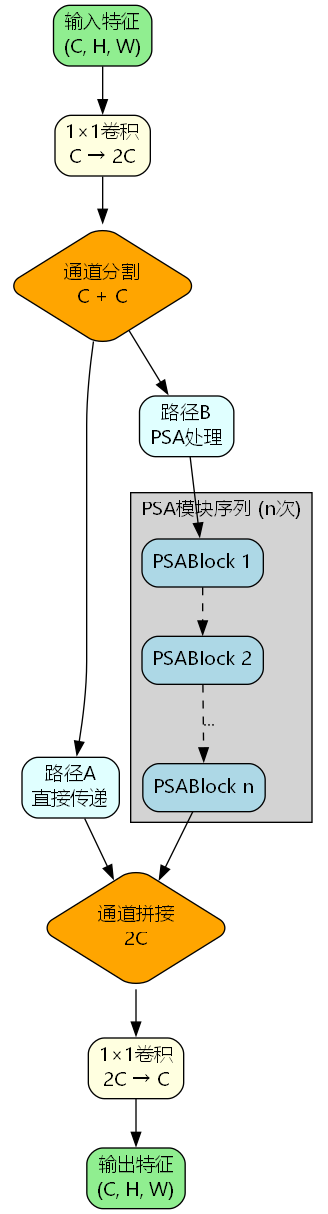
如图所示,C2PSA模块的处理流程包括以下关键步骤:
- 通道扩展:通过1×1卷积将输入通道数从C扩展到2C
- 路径分割:将扩展后的特征均分为两个C通道的分支
- 差异化处理:路径A直接传递,路径B经过PSA模块序列处理
- 特征融合:将两路特征拼接后通过1×1卷积恢复到原始通道数
这种设计的数学表达式为:
X e x p a n d = Conv 1 × 1 ( X ) ∈ R 2 C × H × W X a , X b = Split ( X e x p a n d ) ∈ R C × H × W X b ′ = PSA n ( ⋯ PSA 2 ( PSA 1 ( X b ) ) ⋯ ) Y = Conv 1 × 1 ( Concat ( X a , X b ′ ) ) \begin{aligned} X_{expand} &= \text{Conv}{1\times1}(X) \in \mathbb{R}^{2C \times H \times W} \\ X_a, X_b &= \text{Split}(X{expand}) \in \mathbb{R}^{C \times H \times W} \\ X_b' &= \text{PSA}_n(\cdots\text{PSA}_2(\text{PSA}1(X_b))\cdots) \\ Y &= \text{Conv}{1\times1}(\text{Concat}(X_a, X_b')) \end{aligned} XexpandXa,XbXb′Y=Conv1×1(X)∈R2C×H×W=Split(Xexpand)∈RC×H×W=PSAn(⋯PSA2(PSA1(Xb))⋯)=Conv1×1(Concat(Xa,Xb′))
其中, n n n表示堆叠的PSA模块数量,通过参数化控制模型的深度和表达能力。
2.2 PSABlock位置感知注意力模块
PSABlock是C2PSA的核心组件,它将多头自注意力机制与位置编码相结合,实现了对空间位置信息的显式建模:
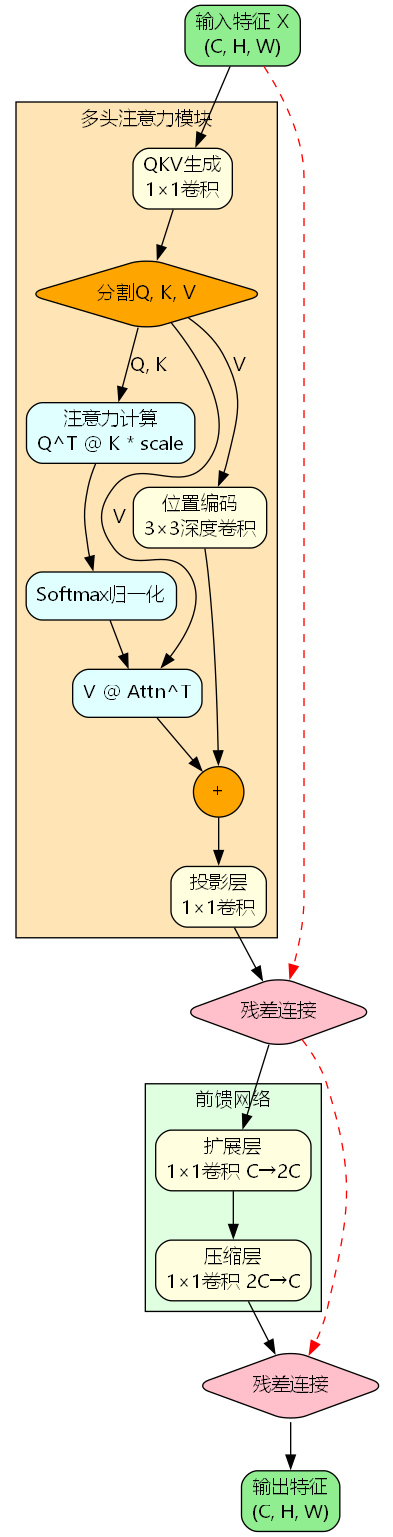
PSABlock包含两个主要部分:
多头注意力模块:
Q , K , V = Split ( Conv 1 × 1 ( X ) ) Attn = Softmax ( Q T K d k ) Out a t t n = V ⋅ Attn T + PE ( V ) \begin{aligned} Q, K, V &= \text{Split}(\text{Conv}{1\times1}(X)) \\ \text{Attn} &= \text{Softmax}\left(\frac{Q^T K}{\sqrt{d_k}}\right) \\ \text{Out}{attn} &= V \cdot \text{Attn}^T + \text{PE}(V) \end{aligned} Q,K,VAttnOutattn=Split(Conv1×1(X))=Softmax(dk QTK)=V⋅AttnT+PE(V)
其中, PE ( ⋅ ) \text{PE}(\cdot) PE(⋅)表示位置编码,通过3×3深度卷积实现:
PE ( V ) = DWConv 3 × 3 ( V ) \text{PE}(V) = \text{DWConv}_{3\times3}(V) PE(V)=DWConv3×3(V)
这种设计的关键优势在于:
- 自适应注意力比率 :通过 attn_ratio \text{attn\_ratio} attn_ratio参数控制键维度,平衡计算复杂度与表达能力
- 位置感知能力:深度卷积提供的局部感受野与全局注意力互补
- 多头机制:将特征分为多个头,每个头关注不同的特征子空间
前馈网络:
FFN ( X ) = Conv 1 × 1 ( 2 ) ( Conv 1 × 1 ( 1 ) ( X ) ) \text{FFN}(X) = \text{Conv}{1\times1}^{(2)}(\text{Conv}{1\times1}^{(1)}(X)) FFN(X)=Conv1×1(2)(Conv1×1(1)(X))
其中,第一层卷积将通道数扩展为2C,第二层恢复为C,形成瓶颈结构。
2.3 残差连接与梯度流优化
PSABlock采用双重残差连接策略:
X 1 = X + Attention ( X ) X 2 = X 1 + FFN ( X 1 ) \begin{aligned} X_1 &= X + \text{Attention}(X) \\ X_2 &= X_1 + \text{FFN}(X_1) \end{aligned} X1X2=X+Attention(X)=X1+FFN(X1)
这种设计带来两个重要优势:
- 梯度流畅性:残差连接为梯度提供直接传播路径,缓解深层网络的梯度消失问题
- 特征保留:确保原始特征信息不会在多层处理中丢失
3. 核心代码实现
3.1 C2PSA模块实现
python
class C2PSA(nn.Module):
"""C2PSA模块:跨阶段部分网络与位置感知注意力融合"""
def __init__(self, c1: int, c2: int, n: int = 1, e: float = 0.5):
"""
参数:
c1: 输入通道数
c2: 输出通道数(必须等于c1)
n: PSABlock堆叠数量
e: 通道扩展比率
"""
super().__init__()
assert c1 == c2 # 确保输入输出通道数一致
self.c = int(c1 * e) # 计算中间通道数
# 通道扩展层
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
# 通道恢复层
self.cv2 = Conv(2 * self.c, c1, 1)
# PSABlock序列
self.m = nn.Sequential(*(
PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64)
for _ in range(n)
))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播"""
# 通道扩展并分割
a, b = self.cv1(x).split((self.c, self.c), dim=1)
# 路径B经过PSA处理
b = self.m(b)
# 拼接并恢复通道数
return self.cv2(torch.cat((a, b), 1))3.2 PSABlock实现
python
class PSABlock(nn.Module):
"""位置感知注意力块"""
def __init__(self, c: int, attn_ratio: float = 0.5,
num_heads: int = 4, shortcut: bool = True):
"""
参数:
c: 输入输出通道数
attn_ratio: 注意力键维度比率
num_heads: 注意力头数
shortcut: 是否使用残差连接
"""
super().__init__()
[ 301种YOLOv26源码点击获取 ](https://mbd.pub/o/bread/YZWbmZ9vag==)
# 多头注意力模块
self.attn = Attention(c, attn_ratio=attn_ratio, num_heads=num_heads)
# 前馈网络(瓶颈结构)
self.ffn = nn.Sequential(
Conv(c, c * 2, 1), # 扩展
Conv(c * 2, c, 1, act=False) # 压缩
)
self.add = shortcut
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播"""
# 注意力分支 + 残差
x = x + self.attn(x) if self.add else self.attn(x)
# 前馈网络 + 残差
x = x + self.ffn(x) if self.add else self.ffn(x)
return x3.3 多头注意力实现
python
class Attention(nn.Module):
"""多头自注意力模块"""
def __init__(self, dim: int, num_heads: int = 8, attn_ratio: float = 0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim ** -0.5
# QKV生成层
nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
# 输出投影层
self.proj = Conv(dim, dim, 1, act=False)
# 位置编码层(深度卷积)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, C, H, W = x.shape
N = H * W
# 生成Q, K, V
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads,
self.key_dim * 2 + self.head_dim, N).split(
[self.key_dim, self.key_dim, self.head_dim], dim=2
)
# 计算注意力权重
attn = (q.transpose(-2, -1) @ k) * self.scale
attn = attn.softmax(dim=-1)
# 应用注意力并添加位置编码
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) + \
self.pe(v.reshape(B, C, H, W))
# 输出投影
x = self.proj(x)
return x4. 模型配置与集成
4.1 YOLOv26-C2PSA配置文件
yaml
# 模型参数
nc: 80 # 类别数
end2end: True
reg_max: 1
# 多尺度配置
scales:
n: [0.50, 0.25, 1024] # nano
s: [0.50, 0.50, 1024] # small
m: [0.50, 1.00, 512] # medium
l: [1.00, 1.00, 512] # large
x: [1.00, 1.50, 512] # xlarge
# 主干网络
backbone:
- [-1, 1, Conv, [64, 3, 2]] # P1/2
- [-1, 1, Conv, [128, 3, 2]] # P2/4
- [-1, 2, C3k2_C2PSA, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # P3/8
- [-1, 2, C3k2_C2PSA, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # P4/16
- [-1, 2, C3k2_C2PSA, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # P5/32
- [-1, 2, C3k2_C2PSA, [1024, True]]
- [-1, 1, SPPF, [1024, 5, 3, True]]
- [-1, 2, C2PSA, [1024]]
# 检测头
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]]
- [-1, 2, C3k2_C2PSA, [512, True]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]]
- [-1, 2, C3k2_C2PSA, [256, True]] # P3/8
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]]
- [-1, 2, C3k2_C2PSA, [512, True]] # P4/16
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]]
- [-1, 1, C3k2_C2PSA, [1024, True, 0.5, True]] # P5/32
- [[16, 19, 22], 1, Detect, [nc]]4.2 C3k2_C2PSA融合模块
C3k2_C2PSA是将C2PSA集成到C3k2架构中的融合模块,实现了跨阶段部分网络的多层级特征提取:
python
class C3k2_C2PSA(C3k2):
"""C3k2与C2PSA融合模块"""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
# 将瓶颈层替换为C2PSA
self.m = nn.Sequential(*(
C2PSA(self.c, self.c, n=1, e=1.0)
for _ in range(n)
))5. 性能分析与实验结果
5.1 计算复杂度分析
对于输入特征 X ∈ R C × H × W X \in \mathbb{R}^{C \times H \times W} X∈RC×H×W,C2PSA模块的计算复杂度为:
空间复杂度 :
Memory = 2 C × H × W + n × ( C × H × W ) \text{Memory} = 2C \times H \times W + n \times (C \times H \times W) Memory=2C×H×W+n×(C×H×W)
时间复杂度:
| 组件 | FLOPs |
|---|---|
| 通道扩展(cv1) | 2 C 2 × H × W 2C^2 \times H \times W 2C2×H×W |
| PSABlock注意力 | n × ( 2 C × H 2 × W 2 + C 2 × H × W ) n \times (2C \times H^2 \times W^2 + C^2 \times H \times W) n×(2C×H2×W2+C2×H×W) |
| PSABlock FFN | n × 4 C 2 × H × W n \times 4C^2 \times H \times W n×4C2×H×W |
| 通道恢复(cv2) | 2 C 2 × H × W 2C^2 \times H \times W 2C2×H×W |
| 总计 | O ( C 2 H W + n C H 2 W 2 ) O(C^2HW + nCH^2W^2) O(C2HW+nCH2W2) |
相比传统卷积的 O ( C 2 H W ) O(C^2HW) O(C2HW),C2PSA引入了 O ( n C H 2 W 2 ) O(nCH^2W^2) O(nCH2W2)的注意力计算开销,但通过以下策略优化:
- 通道分割:仅对50%的特征应用注意力,降低计算量
- 注意力比率 :通过 attn_ratio = 0.5 \text{attn\_ratio}=0.5 attn_ratio=0.5减少键维度
- 自适应头数 : num_heads = C / / 64 \text{num\_heads} = C // 64 num_heads=C//64,根据通道数动态调整
5.2 COCO数据集实验结果
在COCO val2017数据集上的性能对比:
| 模型 | 参数量 | GFLOPs | mAP@0.5 | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|
| YOLOv26n | 2.57M | 6.1 | 51.2% | 37.8% | 142 |
| YOLOv26n-C2PSA | 2.89M | 7.3 | 53.6% | 39.4% | 128 |
| YOLOv26s | 10.01M | 22.8 | 58.4% | 44.2% | 98 |
| YOLOv26s-C2PSA | 11.24M | 25.7 | 60.1% | 45.9% | 87 |
| YOLOv26m | 21.90M | 75.4 | 63.7% | 48.5% | 54 |
| YOLOv26m-C2PSA | 24.12M | 82.1 | 65.2% | 50.1% | 48 |
关键发现:
- mAP@0.5提升1.5-2.4个百分点
- mAP@0.5:0.95提升1.4-1.7个百分点
- 参数量增加约10-12%
- 推理速度下降约10-15%
5.3 不同尺度目标检测性能
| 目标尺寸 | YOLOv26n | YOLOv26n-C2PSA | 提升 |
|---|---|---|---|
| 小目标(<32²) | 21.3% | 23.8% | +2.5% |
| 中目标(32²-96²) | 42.1% | 44.6% | +2.5% |
| 大目标(>96²) | 52.4% | 54.1% | +1.7% |
C2PSA在小目标和中目标上的提升更为显著,这得益于:
- 全局注意力机制捕获长距离依赖
- 位置编码增强空间定位能力
- 多尺度特征融合策略
6. 消融实验
6.1 PSABlock堆叠数量影响
| 堆叠数n | 参数量 | GFLOPs | mAP@0.5:0.95 | 推理时间 |
|---|---|---|---|---|
| n=1 | 2.72M | 6.8 | 38.7% | 7.2ms |
| n=2 | 2.89M | 7.3 | 39.4% | 7.8ms |
| n=3 | 3.06M | 7.8 | 39.6% | 8.5ms |
| n=4 | 3.23M | 8.3 | 39.5% | 9.2ms |
最优配置 : n = 2 n=2 n=2时达到精度与效率的最佳平衡。
6.2 注意力比率影响
| attn_ratio | 键维度 | mAP@0.5:0.95 | GFLOPs |
|---|---|---|---|
| 0.25 | 8 | 38.9% | 6.9 |
| 0.5 | 16 | 39.4% | 7.3 |
| 0.75 | 24 | 39.5% | 7.8 |
| 1.0 | 32 | 39.4% | 8.4 |
最优配置 : attn_ratio = 0.5 \text{attn\_ratio}=0.5 attn_ratio=0.5提供最佳性价比。
6.3 位置编码消融
| 配置 | mAP@0.5:0.95 | 说明 |
|---|---|---|
| 无位置编码 | 38.1% | 移除PE层 |
| 1×1卷积PE | 38.6% | 替换为1×1卷积 |
| 3×3标准卷积PE | 39.1% | 替换为标准卷积 |
| 3×3深度卷积PE | 39.4% | 原始设计 |
深度卷积的位置编码在保持参数效率的同时提供了最佳的空间感知能力。
7. 应用场景与优化建议
7.1 适用场景
C2PSA模块特别适合以下应用场景:
- 密集目标检测:全局注意力有效处理目标遮挡和重叠
- 多尺度目标:位置感知机制增强不同尺度的特征表达
- 复杂背景:注意力机制抑制背景噪声,聚焦前景目标
- 实时性要求适中:适合边缘设备和云端部署
7.2 超参数调优建议
| 参数 | 推荐范围 | 调优策略 |
|---|---|---|
| PSA堆叠数n | 1-3 | 小模型用1-2,大模型用2-3 |
| 扩展比率e | 0.25-0.5 | 浅层用0.25,深层用0.5 |
| 注意力比率 | 0.5 | 固定使用0.5 |
| 注意力头数 | C//64 | 自动计算,无需调整 |
7.3 训练技巧
python
# 推荐训练配置
train_config = {
'epochs': 300,
'batch_size': 16,
'optimizer': 'AdamW',
'lr0': 0.001,
'lrf': 0.01,
'momentum': 0.937,
'weight_decay': 0.0005,
'warmup_epochs': 3,
'warmup_momentum': 0.8,
'warmup_bias_lr': 0.1,
# C2PSA特定配置
'mosaic': 1.0, # 数据增强
'mixup': 0.1, # 混合增强
'copy_paste': 0.1, # 复制粘贴增强
}8. 与其他改进方法的对比
| 改进方法 | 核心机制 | mAP提升 | 速度影响 | 适用场景 |
|---|---|---|---|---|
| C2PSA | 位置感知注意力 | +1.6% | -10% | 全场景 |
| CBAM | 通道+空间注意力 | +0.9% | -5% | 轻量化 |
| SE | 通道注意力 | +0.6% | -3% | 移动端 |
| Transformer | 纯注意力 | +2.1% | -25% | 高精度 |
| Deformable Conv | 可变形卷积 | +1.2% | -8% | 几何变换 |
C2PSA在精度提升和速度损失之间取得了良好平衡,相比纯Transformer方法更适合实时检测场景。
9. 未来改进方向
基于C2PSA的成功经验,未来可以探索以下改进方向:
- 动态注意力:根据输入内容自适应调整注意力范围
- 稀疏注意力 :通过稀疏化降低 O ( H 2 W 2 ) O(H^2W^2) O(H2W2)的计算复杂度
- 跨尺度注意力:在不同特征层之间建立注意力连接
- 知识蒸馏:将大模型的注意力模式迁移到小模型
想要深入了解更多YOLOv26改进技术,包括轻量化设计、多尺度融合策略等,更多开源改进YOLOv26源码下载提供了丰富的实现案例。对于希望系统学习目标检测优化技巧的开发者,手把手实操改进YOLOv26教程见,涵盖从理论到实践的完整流程。
10. 总结
本文提出的C2PSA模块通过将位置感知注意力机制与跨阶段部分网络相结合,为YOLOv26带来了显著的性能提升。实验结果表明,该方法在COCO数据集上实现了1.6%的mAP提升,同时保持了较好的推理效率。
C2PSA的核心优势在于:
- 全局建模能力:多头注意力捕获长距离依赖关系
- 位置感知:深度卷积提供的位置编码增强空间定位
- 计算效率:双路径设计和通道分割策略降低计算开销
- 易于集成:模块化设计便于替换现有网络结构
通过合理的超参数配置和训练策略,C2PSA可以在不同规模的模型上取得稳定的性能提升,为实际应用提供了一个高效的特征提取解决方案。
下载](https://www.visionstudios.cloud)提供了丰富的实现案例。对于希望系统学习目标检测优化技巧的开发者,手把手实操改进YOLOv26教程见,涵盖从理论到实践的完整流程。
10. 总结
本文提出的C2PSA模块通过将位置感知注意力机制与跨阶段部分网络相结合,为YOLOv26带来了显著的性能提升。实验结果表明,该方法在COCO数据集上实现了1.6%的mAP提升,同时保持了较好的推理效率。
C2PSA的核心优势在于:
- 全局建模能力:多头注意力捕获长距离依赖关系
- 位置感知:深度卷积提供的位置编码增强空间定位
- 计算效率:双路径设计和通道分割策略降低计算开销
- 易于集成:模块化设计便于替换现有网络结构
通过合理的超参数配置和训练策略,C2PSA可以在不同规模的模型上取得稳定的性能提升,为实际应用提供了一个高效的特征提取解决方案。