从一个问题开始
你有没有用输入法时遇到这样的情况:打了一段话,下一个词的候选列表里,排第一的偏偏不是你想要的那个,但你知道那个词一定在后面几位,因为你刚才已经用过它了。
传统输入法的候选词排序,本质上是一套词频统计系统------它记录的是"全体用户最常用这个词",而不是"你在当前这段话里最可能用这个词"。两者之间的差距,就是语境理解。
这个问题不是工程问题,而是架构问题。词频表天然无法理解上下文。
而大语言模型,恰好把语境理解做到了极致。
一个有意思的想法
大语言模型在生成文字时,做的事情本质上是:给定前面的所有文字,预测下一个词出现的概率。它把整个上下文都考虑进去了------你说了什么话题,用了什么风格,前一句用的哪个词,这些都影响它的预测结果。
那如果我们把这个能力嫁接到输入法里会怎样?
思路其实很直接:用户输入拼音,拼音作为一个过滤条件,在所有能匹配这个拼音的词里,让 LLM 按当前语境打个分,分最高的排第一。
举个例子:你正在写一篇关于编程的文章,打了 ji 这个拼音。传统输入法可能给你「几」「记」「技」「机」,因为这几个字词频都很高。但如果 LLM 知道你在聊编程,它会给「技」(技术)更高的权重,因为这在编程上下文里更自然。
这不是魔法,这是语言模型本来就有的能力,只是以前没有被用在输入法这个场景。
本项目受到 lime 的启发,探索一种新的输入法思路:利用本地大语言模型的语言理解能力来驱动候选词排序,而非依赖传统的 N-gram 统计词库。
llm-ime 是什么
llm-ime 是我做的一个实验性项目,把上面这个思路实现出来,验证它是否真的可行。
项目的核心是一个 Node.js 服务,加载本地 GGUF 格式的量化模型,接收拼音输入,返回按语境排序的候选词。配套一个 React 写的 Web Dashboard,可以直接在浏览器里打字体验效果,顺便看看输入统计和引擎状态。
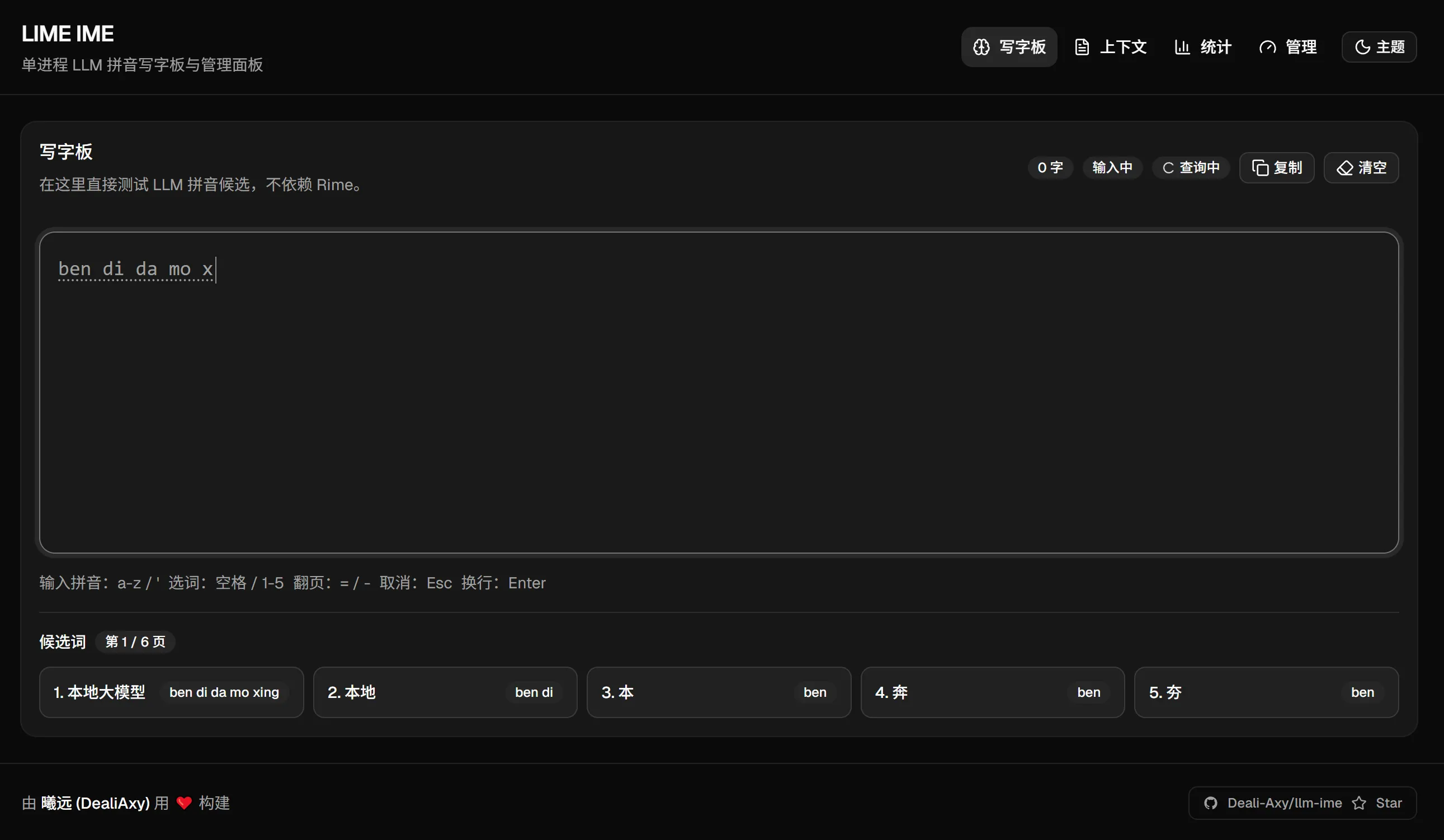
重要说明: 这是一个实验性项目,目前处于 Web 验证阶段。我用 Web 界面来验证引擎逻辑和响应速度是否达标,而不是真的打算让你把浏览器当输入法用。如果引擎跑通了,下一步才是接入真实的输入法框架(比如 RIME),或者自己写一个原生前端。
用的什么模型
Qwen3-0.6B-IQ4_XS,阿里的 0.6B 参数量化版本,文件大小约 350 MB。
选这个模型的理由:
- 够小:350 MB 完全可以接受,不像动辄几十 GB 的大模型让人望而却步
- 够快:CPU 推理也能在秒级出结果,不会让打字等到怀疑人生
- 够准:Qwen3 系列对中文理解做了专门优化,候选词的语境匹配效果比你想象的要好
模型完全在本地运行,不联网,没有任何数据上传,隐私有保障。
技术实现简介
对技术感兴趣的读者,简单说说实现思路。
整个项目是一个 pnpm monorepo,分为三块:
apps/server:LLM 推理引擎 + HTTP API,用 Hono 框架提供接口,node-llama-cpp 做 GGUF 模型加载和推理apps/web:React 前端,TanStack Router + Tailwind CSS + shadcn/ui,支持深色/浅色主题packages/ui:共享组件库
架构上有几个我觉得还挺有意思的地方:
端到端类型安全 :用 Hono RPC 做类型共享,服务端定义路由,前端用 hc<AppType>() 创建客户端,请求和响应类型全自动推导,不用写任何手动类型定义。
防卡顿设计 :打字这种场景对响应延迟很敏感。LLM 推理天然有延迟,如果每个按键都触发一次推理并等待结果,打字体验会很差。项目里做了几层处理:按键时立即更新输入显示(同步,无延迟),候选词请求经过防抖再发出,用 React 的 useTransition 把候选词更新降为低优先级渲染,后端用版本号机制跳过过时的队列请求,前端用 AbortController 取消已发出的旧请求。这几层叠加下来,打字基本感觉不到卡。
模糊拼音:内置声母/韵母模糊匹配,z↔zh、c↔ch、s↔sh、an↔ang、en↔eng 这些常见错误都能容忍,打快了也不怕。
快速上手
如果你想本地跑起来试试,步骤很简单。
1. 克隆项目
bash
git clone https://github.com/Deali-Axy/llm-ime.git
cd llm-ime
pnpm install2. 下载模型
项目提供了一个脚本,只下载需要的那个文件(350 MB),不会拉完整的 20+ GB 模型仓库:
bash
pnpm run model:download3. 启动服务
bash
# 终端 1:后端
pnpm run server:dev
# 终端 2:前端
pnpm run web:dev打开 http://127.0.0.1:5173,就能在浏览器里打字了。
现在的状态和接下来的计划
说实话,现在的效果还有不少值得打磨的地方。候选词排序有时候很准,有时候会有些奇怪的词冒出来,这和模型的 token 粒度、量化精度都有关系。长句联想的效果也不如短词组稳定。
这也是为什么我选择先做 Web 验证------在浏览器里可以很直观地看到引擎的表现,方便调参和改进逻辑。
接下来想做的事:
- 引擎层面:继续优化候选词评分策略,改善长句联想的稳定性
- 前端层面:视规划接入 RIME 框架,或者直接写一个原生输入法前端,让它真正能在日常打字中用起来
- 模型层面:探索更适合这个场景的量化方案,在速度和准确率之间找更好的平衡点
目前这更像是一个"思路验证"阶段,如果你觉得这个方向有意思,欢迎一起聊聊,或者直接来 GitHub 提 Issue / PR。
写在最后
做这个项目的出发点很简单:我觉得现在大家在讲 AI 应用时,总在讲对话、RAG、Agent,但 AI 和更基础的工具的结合(比如输入法)反而很少有人认真做。拼音输入法这个场景天然适合 LLM------有明确的约束(拼音),有丰富的上下文(你打过的字),有即时反馈(你选不选这个词)。
结果出乎意料地不错,350 MB 的模型跑出来的效果比我预想的要好。当然离真正好用还有距离,但这个方向我觉得值得继续探索。
项目代码开放在 GitHub,欢迎 Star、Fork 或者提 Issue 交流想法:
🔗 https://github.com/Deali-Axy/llm-ime
如果你对 AI 工具、开发效率或者有趣的开源项目感兴趣,欢迎关注我:
GitHub @Deali-Axy