跳表(Skip List)是Redis有序集合(ZSet)底层实现的核心数据结构之一。本文将从数据结构定义到核心算法实现,系统剖析跳表的设计思想与工程细节。通过深入理解跳表,我们不仅能掌握其高效的O(log n) 查找、插入、删除机制,还能为后续深入分析ZSet的完整实现(如何结合字典与跳表实现双重索引)打下坚实基础。
跳表(Skip List)是一种基于有序链表的概率数据结构,通过在链表上建立多级索引,实现了 O(log n) 的查找、插入和删除。它由 William Pugh 在 1990 年提出,核心思想是:如果每两个节点提取一个到上一级,形成"快车道",就能跳过大量无需访问的节点。
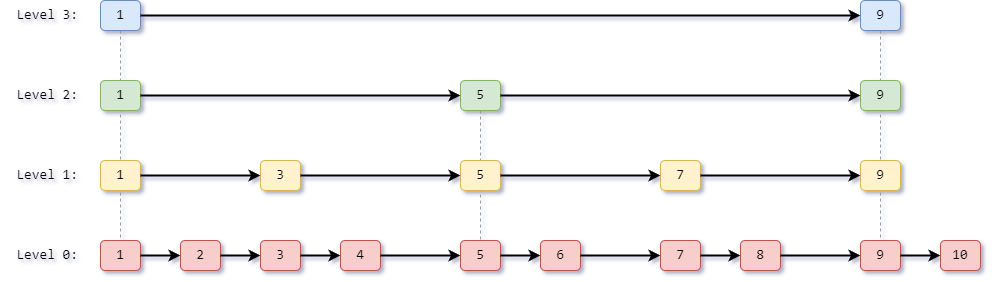
查找时从最高层开始,向右走不动了就往下走,逐层缩小范围。这与二分查找的思想一致,但不需要数组,也不需要平衡操作。
一、Redis 跳表的数据结构定义
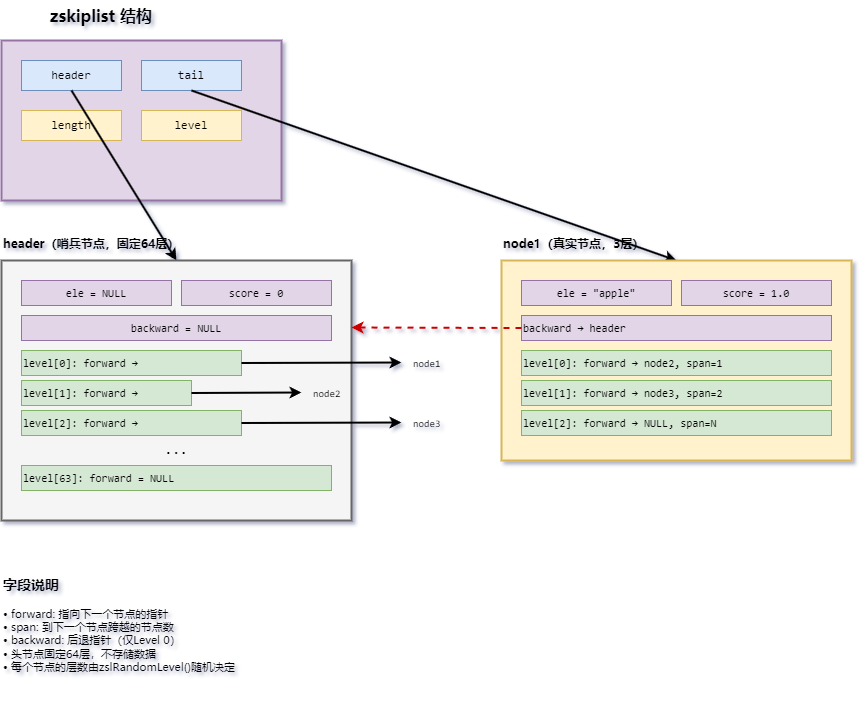
1.1 跳表节点 ------ zskiplistNode
c
// server.h:796-809
typedef struct zskiplistNode {
sds ele; // 成员对象(SDS字符串)
double score; // 分值,用于排序
struct zskiplistNode *backward; // 后退指针,类似双向链表的`prev`,只有一级(Level 0的前驱)
struct zskiplistLevel {
struct zskiplistNode *forward; // 该层的前进指针
unsigned long span; // 该层到`forward`节点之间跨越的节点数(不含自身,含forward节点)
} level[]; // 柔性数组,每个元素代表一层,包含forward和span
} zskiplistNode;span的用途 :计算排名。查找时累加各层走过的span,就是节点在有序集合中的排名。这让ZRANK/ZREVRANK可以在O(logn)内完成。
柔性数组level[] :每个节点的层数在创建时随机决定,level数组的大小就是该节点的层数。头节点固定为ZSKIPLIST_MAXLEVEL(64)层。
1.2 跳表 ------ zskiplist
c
// server.h:811-816
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // header: 头节点(哨兵节点,不存真实数据,固定64层),tail: 尾节点指针
unsigned long length; // 节点数量(不含头节点)
int level; // 当前跳表的最大层数(不含头节点的层数)
} zskiplist;1.3 关键常量
c
// server.h:345-346
#define ZSKIPLIST_MAXLEVEL 64
#define ZSKIPLIST_P 0.25- ZSKIPLIST_MAXLEVEL = 64:最大层数。2^64,足以覆盖任何实际数据量
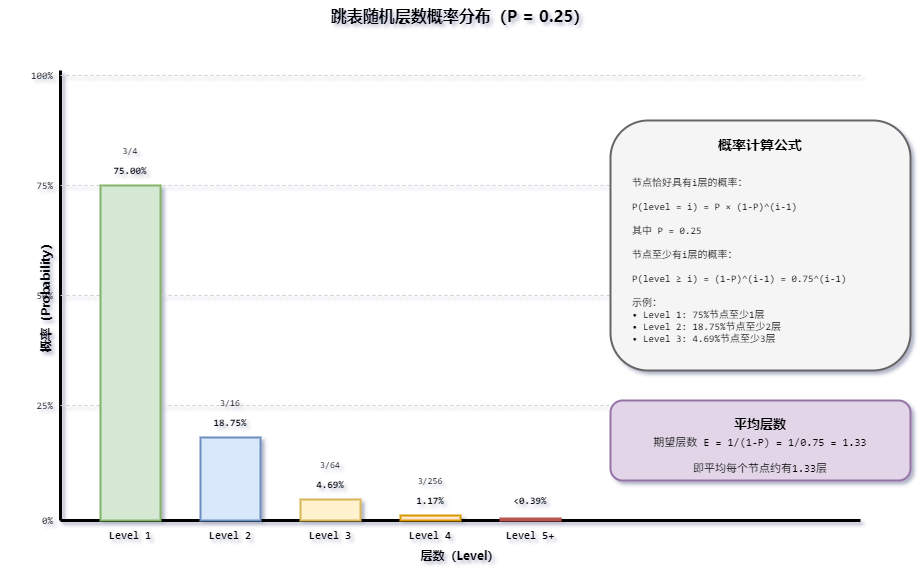
- ZSKIPLIST_P = 0.25:每个节点晋升到上一层的概率为1/4。这意味着约1/4的节点有第2层,1/16的节点有第3层,以此类推
1.4 内存布局
二、随机层数 ------ zslRandomLevel
c
// t_zset.c:55-60
int zslRandomLevel(void) {
int level = 1; // 初始层数为1(最底层)
// 随机决定是否晋升到更高层,每晋升一层概率为ZSKIPLIST_P(0.25)
while ((random()&0xFFFF) < (ZSKIPLIST_P*0xFFFF))
level += 1; // 满足概率条件则层数加1,直到不满足或达到最大层数
// 层数不能超过ZSKIPLIST_MAXLEVEL(64),否则截断为最大层数
return (level < ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}这是跳表的核心概率机制:
- 从第1层开始
- 每次产生一个随机数,如果小于
ZSKIPLIST_P * 0xFFFF(约1/4),层数加1 - 重复直到随机数不符合条件或达到最大层数
各层节点数期望:
| 层数 | 期望节点数(相对总量 N) |
|---|---|
| 1 | N |
| 2 | N/4 |
| 3 | N/16 |
| 4 | N/64 |
| ... | ... |
| k | N/4^(k-1) |
为什么选P=0.25而不是P=0.5?Pugh论文中P=0.5是经典选择。Redis选择P=0.25的原因是减少内存占用:
| P值 | 平均层数/节点 | 查找复杂度 | 内存开销 |
|---|---|---|---|
| 0.5 | 2.0 | O(log₂N) | 基准 |
| 0.25 | 1.33 | O(log₄N) | -33% |
P=0.25时每个节点平均只有1.33层,比P=0.5的2层节省了33%的内存,而查找复杂度仍然是对数级(底数从2变为4,常数因子略增,但实际差异很小)。相关的计算感兴趣的可以阅读一下之前写的这篇文章:《Redis探究之跳表》
三、创建跳表 ------ zslCreate
c
// t_zset.c:62-81
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl)); // 分配跳表结构体内存
zsl->level = 1; // 初始化跳表层数为1(初始时只有头节点,无真实节点)
zsl->length = 0; // 初始化节点数为0(不含头节点)
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL); // 创建头节点(哨兵节点),固定64层,score=0,ele=NULL
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL; // 初始化头节点每层的前进指针为NULL(表示该层为空)
zsl->header->level[j].span = 0; // 初始化头节点每层的跨度为0(头节点到NULL的距离为0)
}
zsl->header->backward = NULL; // 头节点的后退指针为NULL(头节点没有前驱)
zsl->tail = NULL; // 初始化尾指针为NULL(跳表为空)
return zsl;
}头节点始终为64层,所有层的前进指针初始化为NULL,span初始化为0。头节点不计入length。
四、插入节点 ------ zslInsert
这是跳表最复杂的操作,也是理解跳表的关键。
c
// t_zset.c:155-231
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; // update[i]:记录每一层插入位置的前驱节点
unsigned long rank[ZSKIPLIST_MAXLEVEL]; // rank[i]:记录每一层前驱节点距离头节点的跨度
int i, level;
x = zsl->header; // 从头节点开始查找插入位置
// 从最高层(zsl->level-1)到第0层,逐层查找插入点
for (i = zsl->level-1; i >= 0; i--) {
rank[i] = (i == (zsl->level-1)) ? 0 : rank[i+1]; // rank[i]初始为上一层的rank,最高层为0
// 在第i层向右查找,直到找到第一个score大于等于目标score的节点,
// 或score相等但ele字典序大于等于目标ele的节点
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span; // 累加跨度,统计到当前位置的节点数
x = x->level[i].forward; // 沿forward指针向右移动
}
update[i] = x; // 记录每层查找停止的前驱节点
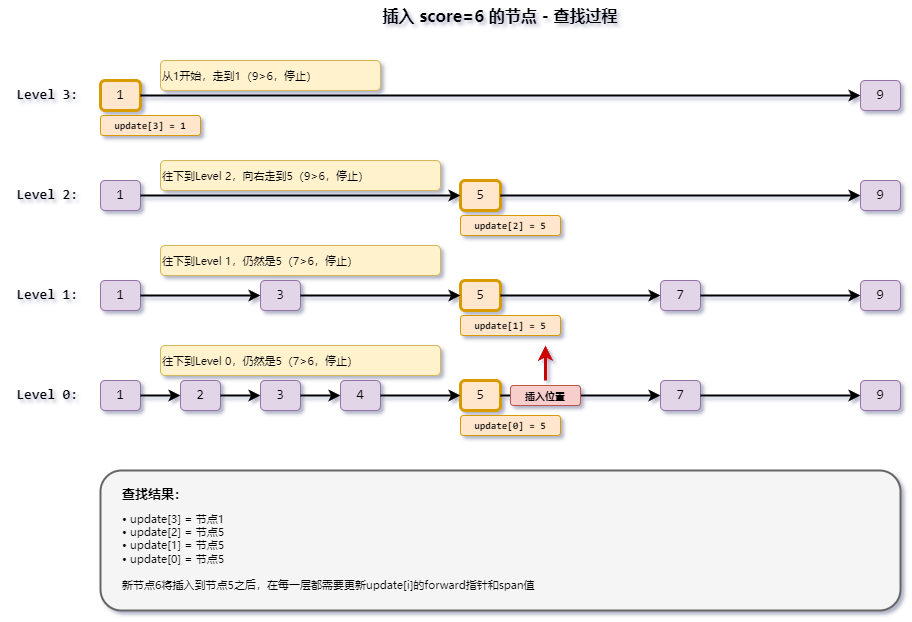
}4.1 查找插入位置
update[]数组 :记录每一层中,插入位置的前驱节点。插入后,新节点在每一层都要插在update[i]之后。
rank[]数组 :记录每一层中,update[i]距离头节点的跨度。用于后续计算span。
查找过程(从最高层往下):
- 从头节点开始,向右走(
forward),条件是forward节点的score更小,或score相同但ele字典序更小 - 走不动了就往下走(
i--) - 记录每层停下的节点到
update[i] - 同时累加
rank[i]
4.2 随机层数与扩层
c
level = zslRandomLevel(); // 随机生成新节点的层数(1~64,期望1.33)
if (level > zsl->level) { // 如果新节点层数超过当前跳表最大层数,需要扩展跳表
for (i = zsl->level; i < level; i++) {
rank[i] = 0; // 新增的高层rank初始化为0(头节点)
update[i] = zsl->header; // 新层的前驱节点都是头节点
update[i]->level[i].span = zsl->length; // 新层的span为当前跳表长度(头节点到尾节点的跨度)
}
zsl->level = level; // 更新跳表的最大层数
}如果新节点的层数超过了当前跳表的最大层数,需要:
- 初始化新层的
update为头节点 - 头节点新层的
span设为跳表总长度(因为头节点到尾节点跨越所有节点) - 更新跳表的
level
4.3 创建节点并插入
c
x = zslCreateNode(level,score,ele); // 创建新节点,层数为level,score/ele为参数
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward; // 新节点的forward指向前驱的forward(即原本的后继)
update[i]->level[i].forward = x; // 前驱的forward指向新节点
// 新节点的span = 前驱原span - (新节点与前驱之间的节点数)
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// 前驱的span = 新节点与前驱之间的节点数 + 1(即新节点本身)
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}span计算解析:
rank[0]是插入位置在Level 0的排名(距头节点的节点数)rank[i]是update[i]在Level i的排名rank[0] - rank[i]是update[i]到插入位置之间的节点数
新节点的span :update[i]原来的span减去update[i]到新节点之间的节点数
update[i]原来的span = update[i]到forward的距离
update[i]到新节点的距离 = rank[0] - rank[i] + 1
新节点的span = update[i]原来的span - (rank[0] - rank[i])updatei的新span :就是update[i]到新节点的距离
update[i]的新span = rank[0] - rank[i] + 14.4 处理超出新节点层数的层
c
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}新节点没有这些层,所以update[i]到forward的距离增加了1(多跨了一个节点)。
4.5 设置后退指针和尾指针
c
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}backward指向Level 0的前驱节点- 如果新节点是尾节点(
level[0].forward == NULL),更新tail
五、删除节点 ------ zslDeleteNode
c
// t_zset.c:234-257
// 删除跳表中的节点x,并维护各层指针和span
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
// 遍历每一层,更新前驱节点的forward和span
for (i = 0; i < zsl->level; i++) {
// 如果该层前驱节点的forward正好指向x,说明x在该层存在
if (update[i]->level[i].forward == x) {
// 合并span:前驱的span加上x的span再减1(跨过x,直接连到x的后继)
update[i]->level[i].span += x->level[i].span - 1;
// 前驱的forward指向x的后继
update[i]->level[i].forward = x->level[i].forward;
} else {
// 如果该层没有x,只需把span减1(下层有x,整体长度减少)
update[i]->level[i].span -= 1;
}
}
// 维护Level 0的backward指针和跳表tail指针
if (x->level[0].forward) {
// 如果x不是最后一个节点,后继的backward指向x的前驱
x->level[0].forward->backward = x->backward;
} else {
// 如果x是最后一个节点,更新跳表的tail指针
zsl->tail = x->backward;
}
// 如果最高层已经没有节点,降低跳表层数
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
// 跳表节点数减1
zsl->length--;
}删除比插入简单:
- 更新span和forward :遍历每一层,如果
update[i]在该层与x相邻(forward == x),则合并span;否则只减1 - 更新backward :后继节点的
backward指向x的前驱 - 收缩level:如果最高层变空,降低跳表层数
5.1 查找并删除 ------ zslDelete
c
// t_zset.c:259-286
// 删除跳表中指定score和ele的节点,成功返回1,否则返回0
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header; // 从头节点开始
// 从最高层往下,逐层查找目标节点的前驱节点,记录到update[]
for (i = zsl->level-1; i >= 0; i--) {
// 在第i层不断向右走,直到下一个节点的score大于目标score,
// 或score相等但ele字典序大于等于目标ele为止
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x; // 记录每层查找停止的前驱节点
}
// 到Level 0后,前进到第一个可能匹配的节点
x = x->level[0].forward;
// 检查score和ele是否都匹配,只有完全匹配才删除
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update); // 调用辅助函数删除节点并维护指针
if (!node)
zslFreeNode(x); // 如果不需要返回被删节点,直接释放内存
else
*node = x; // 否则返回被删节点指针
return 1; // 删除成功
}
return 0; // 未找到目标节点,删除失败
}先查找再删除。只有当score和ele都匹配时才删除------因为不同成员可能有相同的score。
六、更新分数 ------ zslUpdateScore
c
// t_zset.c:333-376
// 更新跳表中指定节点的分数,如果位置不变则直接赋值,否则删除后重新插入
zskiplistNode *zslUpdateScore(zskiplist *zsl, double curscore, sds ele, double newscore) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header; // 从头节点开始
// 从最高层往下,逐层查找目标节点的前驱节点,记录到update[]
for (i = zsl->level-1; i >= 0; i--) {
// 在第i层不断向右走,直到下一个节点的score大于目标curscore,
// 或score相等但ele字典序大于等于目标ele为止
while (x->level[i].forward &&
(x->level[i].forward->score < curscore ||
(x->level[i].forward->score == curscore &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x; // 记录每层查找停止的前驱节点
}
// 到Level 0后,前进到目标节点
x = x->level[0].forward;
// 断言找到的节点必须和参数完全匹配
serverAssertWithInfo(NULL,x,x->score == curscore && sdscmp(x->ele,ele) == 0);
// 如果新分数不会影响节点在跳表中的相对位置(前驱<newscore<后继),直接赋值即可
if ((x->backward == NULL || x->backward->score < newscore) &&
(x->level[0].forward == NULL || x->level[0].forward->score > newscore))
{
x->score = newscore;
return x;
}
// 否则,先删除节点,再以新分数重新插入
zslDeleteNode(zsl, x, update);
zskiplistNode *newnode = zslInsert(zsl, newscore, ele);
return newnode;
}优化判断:如果新分数不影响节点在跳表中的位置(前驱的score仍小于新score,后继的score仍大于新score),直接修改score即可,O(1)。
否则,先删除再插入,O(logn)。这是一个很实用的优化------很多ZINCRBY操作只改变了微小分数,位置不变的概率很高。
七、排名查询 ------ zslGetRank
c
// t_zset.c:440-463
// 计算指定元素在跳表中的排名(1-based),不存在则返回0
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x;
unsigned long rank = 0;
int i;
x = zsl->header; // 从头节点开始
// 从最高层往下逐层查找目标节点
for (i = zsl->level-1; i >= 0; i--) {
// 在第i层不断向右走,直到下一个节点的score大于目标score,
// 或score相等但ele字典序大于目标ele为止
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) <= 0)))
{
// 每向右走一步,累加该层的span(即跨越的节点数)
rank += x->level[i].span;
x = x->level[i].forward;
}
// 如果当前节点就是目标节点,返回累计的rank
if (x->ele && sdscmp(x->ele,ele) == 0) {
return rank;
}
}
// 没找到目标节点,返回0
return 0;
}从最高层开始,向右走时累加span,找到目标节点时返回累加值。O(logn)。
span的存在让排名查询无需遍历Level 0的所有前驱节点,这是跳表相比普通有序链表的关键优势。
八、范围查询 ------ zslFirstInRange / zslLastInRange
c
// t_zset.c:378-430
// 查找跳表中第一个在指定范围内的节点(score >= min 且 score <= max)
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {
zskiplistNode *x;
int i;
// 先判断整个跳表是否与范围有交集,无交集直接返回NULL
if (!zslIsInRange(zsl,range)) return NULL;
x = zsl->header; // 从头节点开始
// 从最高层往下,逐层定位第一个score >= min的节点
for (i = zsl->level-1; i >= 0; i--) {
// 在第i层不断向右走,直到下一个节点的score >= min(即满足范围下界)
while (x->level[i].forward && !zslValueGteMin(x->level[i].forward->score,range))
x = x->level[i].forward;
}
// 到达Level 0后,前进到第一个可能在范围内的节点
x = x->level[0].forward;
serverAssert(x != NULL); // 理论上此时x必不为NULL
// 检查该节点是否超过范围上界(score > max),超出则返回NULL
if (!zslValueLteMax(x->score,range)) return NULL;
// 否则返回第一个在范围内的节点
return x;
}先快速判断范围是否与跳表有交集(zslIsInRange),然后从最高层开始定位第一个>=min的节点,最后检查是否<=max。
zslLastInRange对称地定位最后一个<=max的节点。
这些函数是ZRANGEBYSCORE、ZREVRANGEBYSCORE等范围命令的底层支撑。
九、复杂度
| 操作 | 函数 | 平均 | 最坏 |
|---|---|---|---|
| 创建跳表 | zslCreate |
O(1) | O(1) |
| 插入节点 | zslInsert |
O(log n) | O(n) |
| 删除节点 | zslDelete |
O(log n) | O(n) |
| 更新分数 | zslUpdateScore |
O(1)~O(log n) | O(n) |
| 查找节点 | zslFind |
O(log n) | O(n) |
| 获取排名 | zslGetRank |
O(log n) | O(n) |
| 范围查询起点 | zslFirstInRange |
O(log n) | O(n) |
| 范围遍历 | 逐层 forward |
O(log n + m) | O(n) |
| 获取长度 | zsl->length |
O(1) | O(1) |
注:m为范围内节点数,最坏情况O(n)发生在极端不平衡时(概率极低)。
十、为什么选择跳表而不是红黑树?
在实现有序集合(ZSet)时,需要一个既能按score排序、又支持高效查找和范围查询的数据结构。业界最经典的答案是红黑树 ------Java的TreeMap、C++的std::map都选择了它。但Redis的作者Antirez选择了跳表。
这不是一个随意的决定。Antirez在Redis邮件列表和多个场合解释过这个选择,核心考量是ZSet的具体操作需求。
10.1 ZSet需要哪些操作?
先看Redis有序集合的核心命令及其底层操作:
| 命令 | 底层操作 | 复杂度要求 |
|---|---|---|
ZADD |
插入/更新元素 | O(logn) |
ZREM |
删除元素 | O(logn) |
ZSCORE |
按成员查分数 | O(1) |
ZRANK |
查排名 | O(logn) |
ZRANGE |
按排名范围查询 | O(logn+m) |
ZRANGEBYSCORE |
按分数范围查询 | O(logn+m) |
ZREVRANGE |
反向范围查询 | O(logn+m) |
ZINCRBY |
增减分数 | O(logn) |
ZCARD |
获取元素数 | O(1) |
ZCOUNT |
范围内计数 | O(logn) |
10.2 跳表vs红黑树
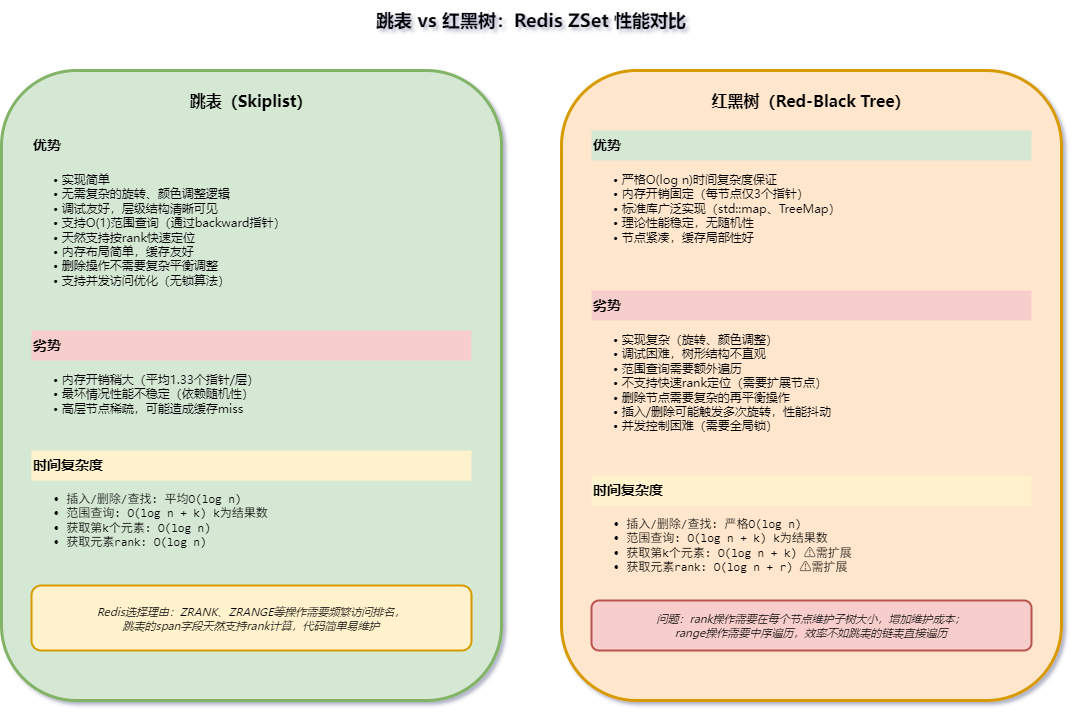
10.2.1 基本操作复杂度
| 操作 | 跳表 | 红黑树 |
|---|---|---|
| 查找 | O(logn) | O(logn) |
| 插入 | O(logn) | O(logn) |
| 删除 | O(logn) | O(logn) |
| 范围查询 | O(logn+m) | O(logn+m) |
| 排名查询 | O(logn)* | O(logn)* |
| 反向遍历 | O(m) | O(m) |
跳表通过span字段天然支持O(logn)排名;红黑树需要额外的子树大小字段(顺序统计树)才能实现O(logn)排名。基本操作复杂度两者相当,没有本质差异。
10.2.2 范围查询------跳表的优势项
跳表的范围查询:
找到起点(O(logn))→沿Level 0的forward逐个遍历(O(m))跳表的Level 0本身就是一个有序链表,范围遍历只需沿forward指针走,缓存友好,指针跳转少。
红黑树的范围查询:
找到起点(O(logn))→找后继节点(每步O(logn))→重复m次红黑树的中序遍历需要不断找后继,每次可能向上回溯再向下,指针跳转多,缓存不友好。
实测影响:范围查询是ZSet最高频的操作之一,跳表的线性遍历在m较大时明显快于红黑树的中序遍历。
10.2.3 反向遍历------跳表的优势项
跳表 :Level 0有backward指针,反向遍历就是沿backward走,O(m)。
红黑树 :需要找前驱节点(prev),每次可能涉及多次指针跳转,O(m*logn)最坏,O(m)平均但常数更大。
Redis的ZREVRANGE、ZREVRANGEBYSCORE等反向命令依赖此操作。
10.2.4 排名查询------跳表天然支持
跳表 :span字段记录每层跨越的节点数,查找时累加span即可得到排名,O(logn)。
红黑树 :原生不支持排名查询。要实现O(logn)排名,需要将红黑树扩展为顺序统计树(Order Statistic Tree),每个节点额外维护子树大小字段。这增加了:
- 额外的内存开销
- 插入/删除时维护子树大小的额外逻辑
- 旋转时重新计算子树大小的复杂度
10.2.5 实现复杂度------跳表完胜
| 维度 | 跳表 | 红黑树 |
|---|---|---|
| 插入 | 找位置+随机层数+修改指针 | 找位置+插入+旋转重平衡 |
| 删除 | 找位置+修改指针 | 找位置+删除+旋转重平衡 |
| 实现复杂度 | 低(无旋转,逻辑线性) | 高(旋转状态多,边界条件复杂) |
红黑树的插入和删除需要旋转来维护平衡,旋转涉及大量指针操作和颜色调整:
红黑树删除的旋转情况:
- 兄弟为红色
- 兄弟为黑色,两个侄子为黑色
- 兄弟为黑色,远侄子为黑色,近侄子为红色
- 兄弟为黑色,远侄子为红色相比之下,跳表的插入只需随机层数+修改前驱后继指针,删除只需修改指针,逻辑极其直观。
10.2.6 并发友好性------跳表的优势
虽然Redis是单线程的,但这个对比仍然有参考价值:
跳表:插入和删除只影响局部节点,锁粒度可以很小(细粒度锁或CAS)。
红黑树:插入和删除可能触发旋转,旋转影响范围大,锁粒度难控制。
Java的ConcurrentSkipListMap选择跳表而非ConcurrentTreeMap就是这个原因。
10.2.7 内存占用------跳表略逊
| 数据结构 | 每节点额外指针/字段 |
|---|---|
| 跳表 | 平均1.33层×(forward+span)+backward≈3.66个字段 |
| 红黑树 | left+right+parent+color=4个字段 |
跳表每个节点平均约4.66个字段(含span),红黑树每个节点4个字段。跳表略多,但差距不大(关于P=0.25的选择原因详见第二章)。
Antirez在Redis Google Group中回答过这个问题,核心观点:
There are a few reasons:
- They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to be in a given level will make then less memory intensive than btrees.
- A sorted set is often target of many ZRANGE or ZREVRANGE operations. Traversing a skip list is like traversing a linked list, while with a tree we need to perform tree rotations or to use a threaded tree (adding two more pointers per node).
- The implementation is much simpler than a balanced tree.
翻译:
- 内存可控:通过调整概率参数,跳表的内存可以比B树更少
- 范围遍历高效:跳表的范围遍历像遍历链表一样简单;红黑树需要旋转或用线索树(额外两个指针)
- 实现简单:比平衡树简单得多
通过上面对跳表的分析,我们系统梳理了Redis跳表的完整实现:从节点结构的精巧设计(span字段支持 O(log n) 排名查询),到随机层数的概率机制(P=0.25 在性能与内存间取得平衡),再到插入、删除、更新等核心操作的算法细节。跳表以简洁的代码和线性的逻辑,实现了与红黑树相当的性能,同时在范围查询、反向遍历和实现复杂度上展现出显著优势。
跳表是Redis有序集合(ZSet)高效运作的基石。在实际应用中,ZSet通过字典+跳表的双重索引结构,同时满足了 O(1) 按成员查分数(字典)和 O(log n) 按分数排序(跳表)的需求。理解跳表的实现原理,是深入掌握ZSet整体架构的关键前提。