B 端SaaS 一接入 Agent,就会遇到一个比模型效果更硬的问题:同一套 Agent 引擎同时服务很多企业时,任何一次上下文串租、知识库串租、工具权限串租,都可能直接变成数据事故。
传统多租户系统通常把隔离重点放在数据库、缓存、对象存储和权限表上。Agent 场景会把隔离面继续拉长。**模型上下文、工具调用、向量检索、Prompt 模板、记忆、审批和审计日志,**都必须知道当前请求属于哪个租户。
为适配多租户的生产场景,租户上下文需要从入口开始贯穿整条执行链。Agent 引擎可以共享,但计算沙箱、RAG 检索面、Prompt 装载和工具授权必须按租户收口。
多租户 Agent 需要让每一次推理、检索和行动都带着可验证的租户边界。
一、Agent 把多租户隔离从数据层推到执行层
多租户,也就是 Multi-Tenant,指的是同一套软件平台同时服务多个客户组织。对 SaaS 来说,这本来是基础能力。一个租户通常对应一家企业、一个部门集团或一套独立业务空间。
Agent 进入 SaaS 后,租户边界不再只存在于数据库查询条件里。Agent 会读文档、查向量库、调用业务工具、生成草稿、触发审批,还会把中间推理结果放进上下文或任务状态里。任何一个环节忘记租户边界,都会让原本隔离良好的 SaaS 变成高风险自动化系统。
多租户 Agent 设计需要先扩大隔离对象。数据库里的 tenant_id 只是起点,完整方案还要覆盖执行、检索、Prompt 和审计。
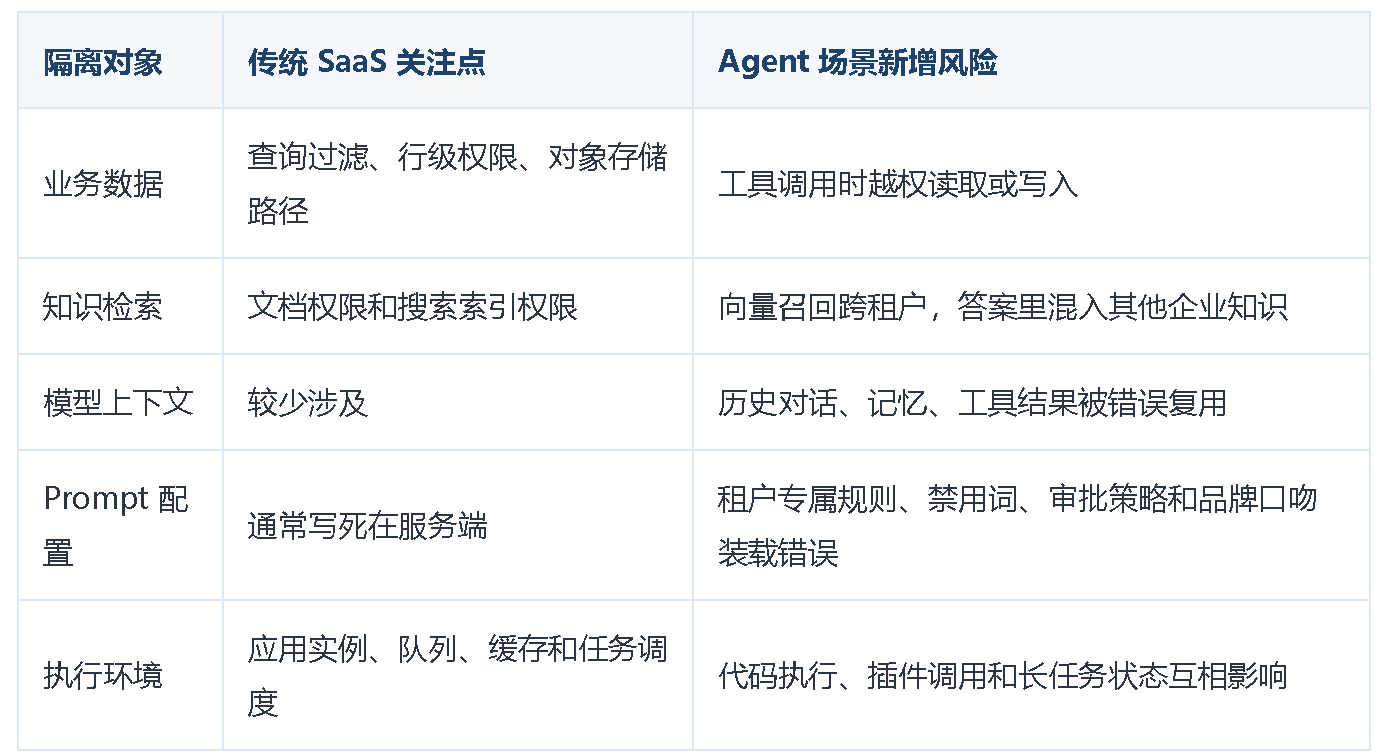
隔离面扩大之后,架构上需要先建立一个租户控制面。没有控制面,后面的计算隔离、RAG 隔离和 Prompt 装载都会变成散落在各个模块里的临时判断。
二、租户控制面负责把身份、配置和策略装进每次执行
多租户 Agent 的入口必须先解析租户上下文。这个上下文来自域名、组织 ID、用户会话、API Key、企业微信应用、SAML/OIDC 登录态或内部网关签名。入口层要把它变成统一的 tenant_context,后续所有模块只认这一份上下文。
租户控制面存三类信息。
第一类是身份与权限,说明用户属于哪个租户、哪个角色、能调用哪些工具。
第二类是资源与配额,说明这个租户能使用哪些模型、多少并发、多少向量索引、多少任务队列。
第三类是运行策略,说明默认 Prompt、知识库范围、审批规则、审计要求和数据保留周期。

控制面统一之后,执行层才能做到"共享引擎,隔离运行"。这也是大规模 B 端 SaaS 最常见的取舍:引擎不一定为每家企业单独部署,但每次执行都要带着租户边界运行。
三、计算隔离要按租户等级分层
Agent 的计算隔离包含模型调用、工具执行、代码沙箱、异步任务和缓存状态。隔离强度需要和成本约束一起评估。给所有租户都做独立集群,安全边界最清楚,但资源利用率低。所有租户完全混跑,成本最低,但风险会集中到调度器、缓存和插件运行时。
**按租户风险等级选择隔离模型,是兼顾安全边界和资源利用率的基础做法。**普通租户走共享池,大客户或高合规租户走独立队列、独立索引或独立执行空间。极高合规租户再进入专属集群或私有化部署。
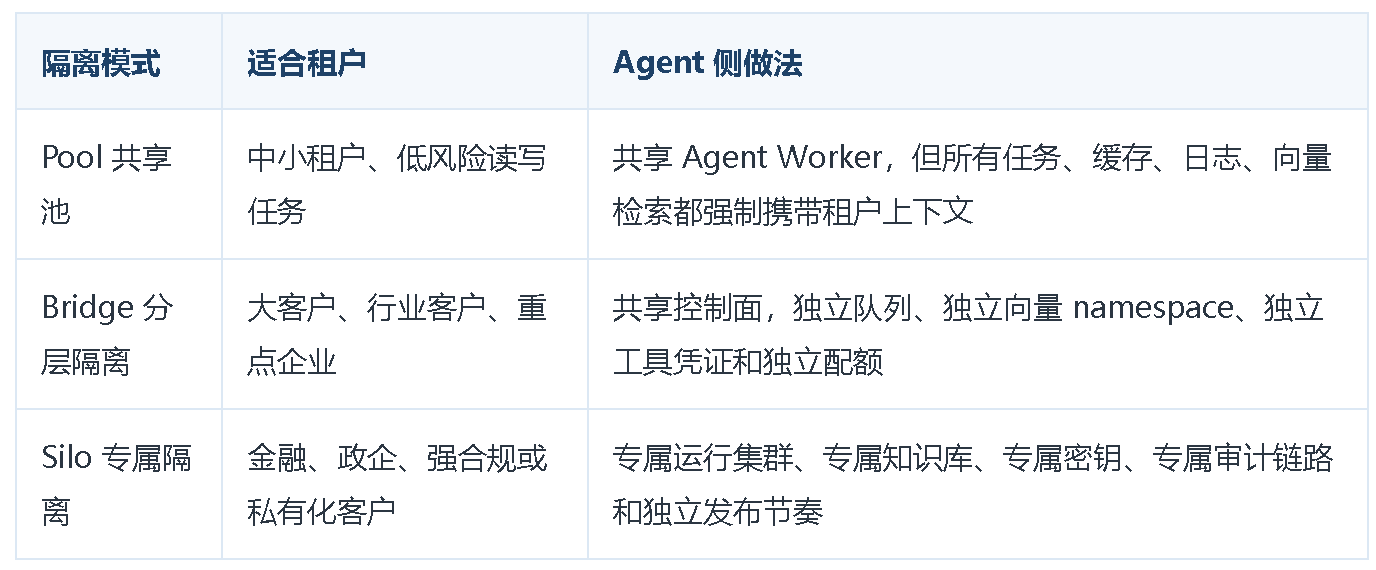
计算隔离还要特别处理长任务。Agent 任务可能运行几十分钟,期间会暂停、等待审批、重试或恢复。任务状态、检查点和临时文件都要按租户分区,并在恢复、重试和回放时持续校验租户边界。
如果 Agent 允许执行代码或插件,沙箱边界要再收紧一层。每次执行都应注入租户级临时目录、网络访问策略、工具允许名单和资源限额。模型可以共享,执行副作用必须隔离。
四、RAG 隔离需要在检索前完成租户过滤
RAG,也就是检索增强生成,通常会把企业文档切块、向量化,再按用户问题召回相关内容给模型回答。多租户 RAG 的主要风险集中在召回阶段跨租户。答案生成出来以后再做文本过滤,已经太晚了。
向量隔离通常有三种做法。
第一种是每个租户一个独立索引或集合,边界清楚,成本较高。
第二种是共享索引,用 namespace、partition 或 tenant 分区隔离。
第三种是共享索引加元数据过滤,用 tenant_id 作为必选过滤条件。实际架构可以混合使用,但检索请求进入向量库之前就要带上租户范围。

向量数据库厂商给出的多租户能力名称不同,但工程目标一致。Pinecone 常用 namespace 隔离租户。Weaviate 有 collection 级多租户能力。Qdrant 可以通过 payload 过滤与分片策略处理多租户。Milvus 常见做法是按 database、collection、partition 或分区键拆分租户。
目前市面上主流的向量数据库可以根据其原生性 和托管方式分为以下四大类:
- 托管式云原生向量数据库(Serverless/Managed)
这类数据库专为云端设计,用户无需维护基础设施,开箱即用。
-
Pinecone:
-
特点: 目前商业化最成功的闭源向量数据库。全托管模式,支持实时索引更新和高并发查询。
-
适用场景: 追求极致部署速度和易用性的企业级 AI 应用。
-
-
Zilliz:
- 特点: 基于开源 Milvus 构建的公有云版本,提供强大的自动扩缩容能力。
- 专业开源向量数据库(Open Source & Dedicated)
这类数据库是目前技术选型的主流,通常具有极高性能的索引算法(如 HNSW)。
-
Milvus:
-
特点: 全球最受欢迎的开源向量数据库之一。采用分布式架构,能够处理海量的(十亿级)向量数据。
-
适用场景: 具有自建机房需求、对数据隐私敏感且数据量巨大的项目。
-
-
Weaviate:
- 特点: 支持 GraphQL 查询,深度集成了多种模型。它不仅能存向量,还擅长处理向量与对象之间的关系。
-
Qdrant:
- 特点: 使用 Rust 编写,以高性能和低内存占用著称,非常受开发者欢迎。
-
Chroma:
- 特点: 轻量化、易安装,是很多 LLM 开源项目(如 AutoGPT)的默认推荐。
- 传统数据库的向量插件(Vector Plugins)
如果你已经在用传统数据库,可以通过扩展插件实现向量检索,无需引入新的架构。
-
pgvector (PostgreSQL):
- 特点: 极其流行。通过在 Postgres 中安装插件,让关系型数据库瞬间具备处理向量的能力。
-
Elasticsearch (KNN):
- 特点: 许多公司已有 ES 集群,利用其内置的近似最近邻(ANN)搜索功能可以直接上手。
-
Redis: 通过
RedisSearch模块提供高性能的向量存储和检索。
- 嵌入式/轻量级向量库
这类主要用于本地开发或小型应用,通常不作为独立的数据库服务运行。
-
Faiss (Meta 开源): 严格来说它是一个库(Library)而非数据库,是目前许多高性能向量索引算法的底层实现标准。
-
LanceDB: 一个专为 AI 设计的嵌入式、无服务器向量数据库,直接读写磁盘。
具体选型取决于租户数量、单租户数据量、查询延迟、删除要求和成本。如果租户特别多、每个租户数据量不大,共享索引加强制过滤更经济。如果少数大客户数据量大、合规要求高,独立索引更容易审计、迁移和删除。
五、Prompt 动态装载要走版本化配置系统
多租户 Agent 的 Prompt 会同时承载业务规则、品牌口吻、审批门槛、知识库范围、禁用动作和合规要求。不同企业之间的这些差异进入配置系统之后,后期维护、灰度和审计才有稳定依据。
Prompt 需要由可版本化的模板和租户配置共同生成。平台提供基础系统 Prompt,行业包提供行业规则,租户配置提供企业专属约束,运行时再根据 tenant_context 装配成最终提示词。 
版本记录决定了后续审计能否复原当时的执行条件。每次 Agent 回复和工具调用,都要记录使用了哪一版 Prompt、哪一版租户策略、哪一组检索结果。否则一旦客户质疑"为什么它这么回答",团队只能去猜当时到底装载了什么配置。
动态装载还要有回退策略。租户配置缺失时,可以回到平台默认规则;租户配置校验失败时,应该拒绝执行高风险动作;Prompt 版本灰度时,要能按租户、部门或任务类型逐步放量。
六、综合图:多租户 Agent 的隔离架构
多租户 Agent 架构可以分成入口鉴权、租户控制面、共享 Agent 引擎、隔离执行面、隔离知识面和审计回放面。编排能力由平台共享,上下文、资源、权限和副作用按租户隔离。
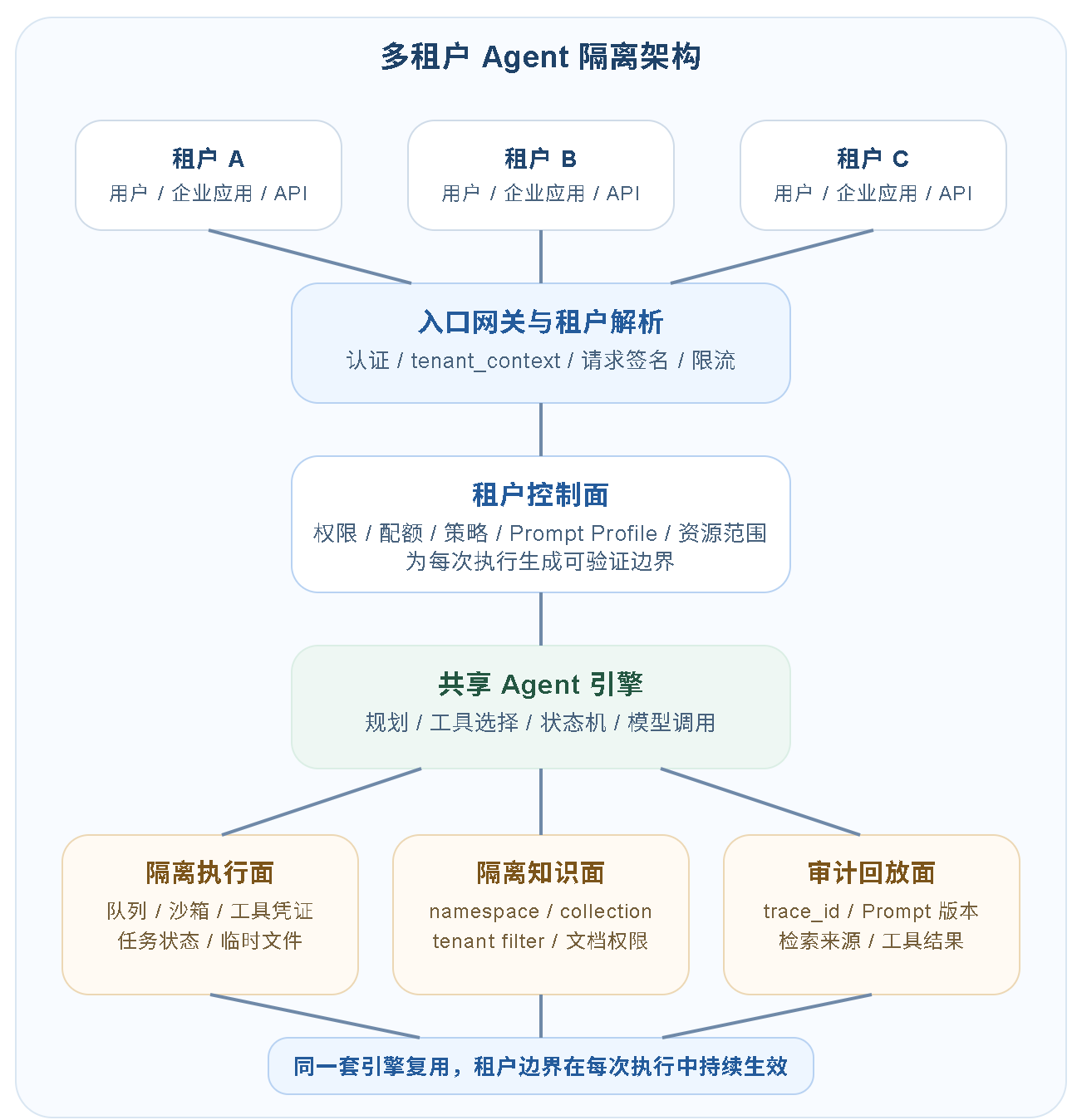
租户控制面位于共享 Agent 引擎之前。Agent 在选择工具、调用知识库、生成 Prompt 和写入状态之前,已经拿到了租户策略。后面每一层都沿用这份策略,避免在各模块里重复推断请求来源。
这种结构让平台保持统一产品能力,同时允许不同租户采用不同隔离等级。普通租户可以复用共享池,大客户可以独立知识库和队列,强合规客户可以进一步走专属部署。
七、上线检查清单:租户边界验证优先于智能能力扩展
多租户 Agent 的上线风险常来自隔离边界滞后于模型能力扩展。上线前的检查标准需要落到每一次执行:它只看到了当前租户允许看的数据,只调用了当前租户允许调用的工具,只使用了当前租户对应的策略和 Prompt。 
多租户 SaaS 的优势来自规模复用,但 Agent 的生产可信度来自边界清楚。引擎可以越来越强,租户边界必须一直可验证。
参考文档: