摘要
模仿学习在构建通用机器人方面展现出巨大潜力,但其扩展性严重依赖于高质量专家示范数据 。与此同时,互联网上存在海量的、蕴含丰富动态信息的无动作标注视频数据,却难以直接用于策略学习。
本文提出 Unified World Models (UWM) ,一个创新的扩散学习框架。UWM 将动作扩散 与视频扩散 耦合在统一的 Transformer 架构中,通过为每种模态设置独立的扩散时间步 ,使得一个模型能灵活地扮演策略网络 、前向/逆动力学模型 以及视频生成器。实验证明,UWM 能有效利用大规模机器人和无动作视频数据进行预训练,显著提升策略的泛化能力和鲁棒性。
关键词:机器人学习;扩散模型;世界模型;模仿学习;多模态预训练
1. 研究背景与动机
1.1 模仿学习的困境
行为克隆(Behavior Cloning, BC)通过监督学习拟合专家动作分布 p(a∣o)p(a|o)p(a∣o),在机器人操作中取得了显著成功。然而,其局限性同样明显:
| 问题 | 说明 |
|---|---|
| 数据依赖 | 依赖昂贵的遥操作数据,采集成本高 |
| 分布外脆弱性 | 训练分布外的场景下表现急剧下降 |
| 信息利用不足 | 未充分利用轨迹中的时间动态信息 |
1.2 世界模型的潜力
世界模型(World Model)通过学习环境动态 p(o′∣o,a)p(o'|o,a)p(o′∣o,a),能够从更广泛的数据中学习,包括:
- 非专家的"玩耍"数据
- 无动作标注的视频数据
核心问题:如何将世界模型学到的动态信息用于提升策略的鲁棒性?
1.3 本文工作
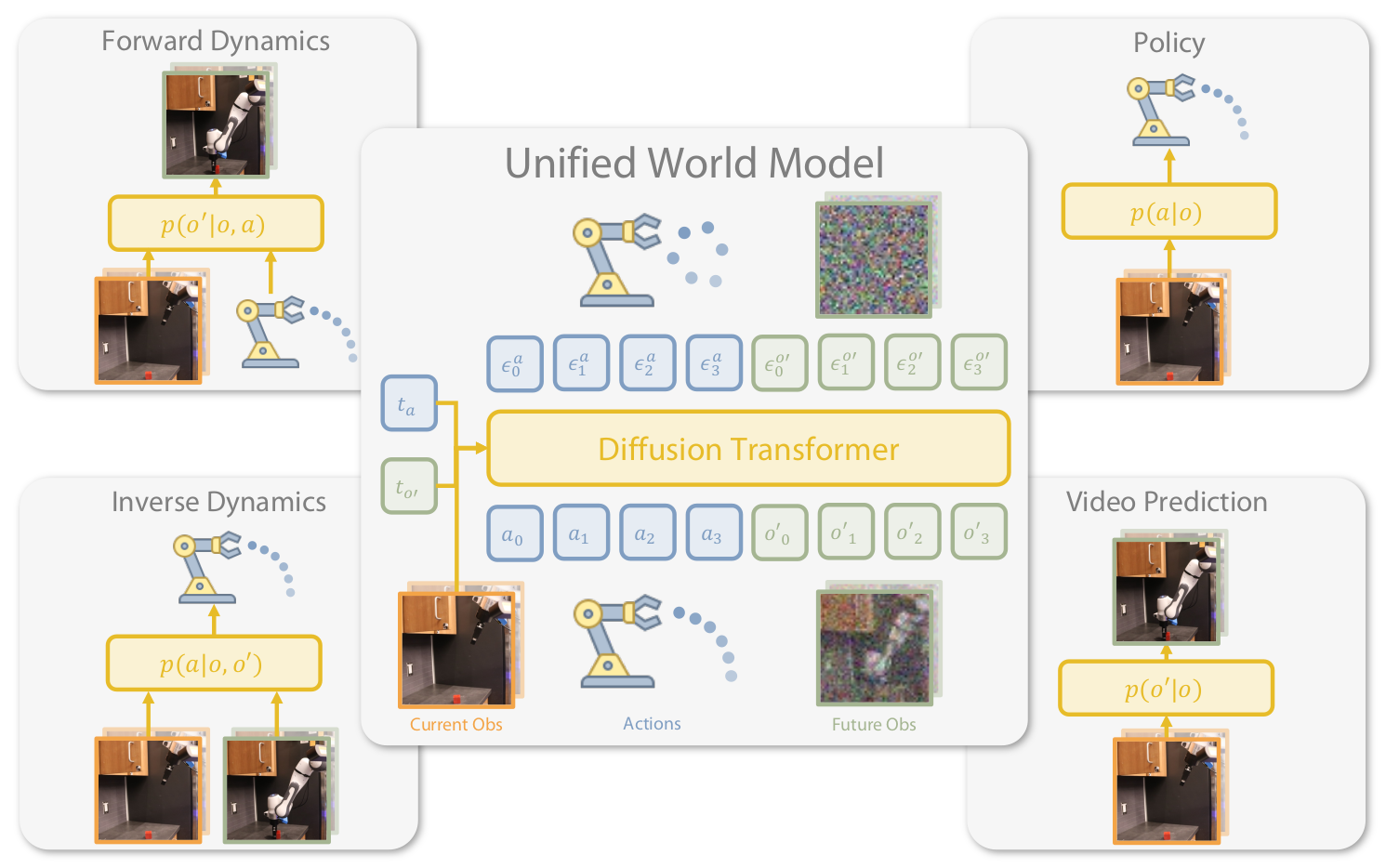
本文提出 Unified World Models (UWM) ,一个统一的扩散框架,同时建模联合分布 p(o,a,o′)p(o,a,o')p(o,a,o′),通过独立控制模态的扩散时间步,实现:
- 策略学习 p(a∣o)p(a|o)p(a∣o)
- 前向动力学 p(o′∣o,a)p(o'|o,a)p(o′∣o,a)
- 逆动力学 p(a∣o,o′)p(a|o,o')p(a∣o,o′)
- 视频预测 p(o′∣o)p(o'|o)p(o′∣o)
2. 方法:Unified World Models
2.1 核心思想
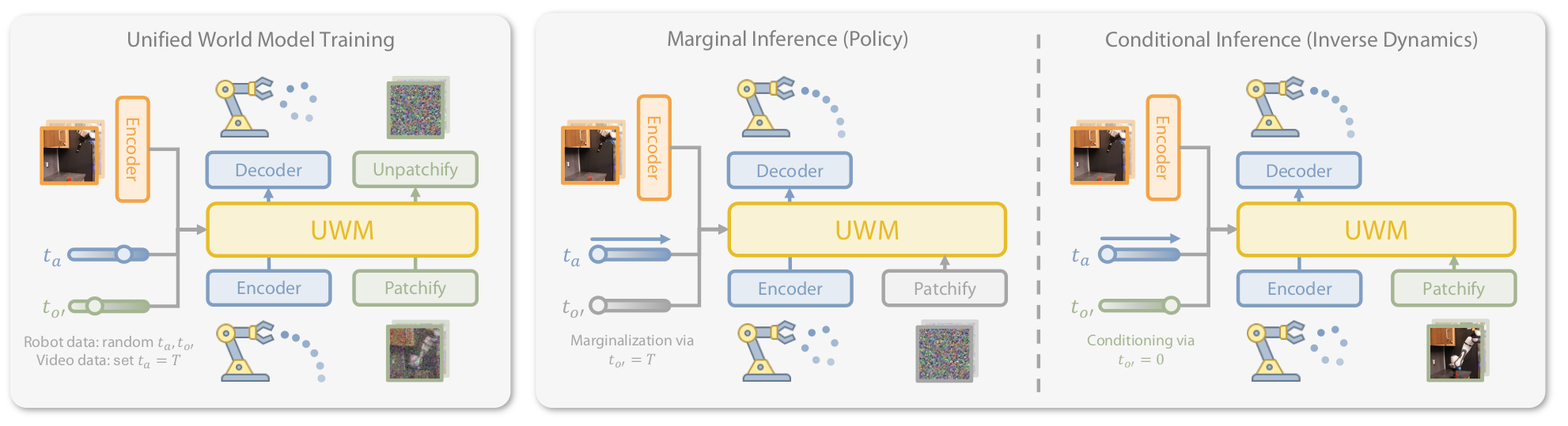
UWM 将动作扩散和图像扩散耦合,为两者设置独立的扩散时间步 tat_ata 和 to′t_{o'}to′。通过独立控制这两个时间步,实现灵活的推理模式:
| 模式 | tat_ata 设置 | to′t_{o'}to′ 设置 | 功能 |
|---|---|---|---|
| 策略 | 正常采样 | to′=Tt_{o'}=Tto′=T(完全掩码) | p(a∣o)p(a \mid o)p(a∣o) |
| 视频预测 | ta=Tt_a=Tta=T(完全掩码) | 正常采样 | p(o′∣o)p(o' \mid o)p(o′∣o) |
| 前向动力学 | ta=0t_a=0ta=0(条件) | 正常采样 | p(o′∣o,a)p(o' \mid o,a)p(o′∣o,a) |
| 逆动力学 | 正常采样 | to′=0t_{o'}=0to′=0(条件) | p(a∣o,o′)p(a \mid o,o')p(a∣o,o′) |
关键洞察 :扩散时间步与"掩码"存在天然联系。t=Tt=Tt=T 时变量完全被噪声掩盖,t=0t=0t=0 时变量保持干净作为条件。
2.2 扩散模型预备知识
去噪扩散概率模型(DDPM)定义前向过程:
q(xt∣xt−1)=N(xt∣1−βtxt−1,βtI)q(x_t|x_{t-1}) = N(x_t | \sqrt{1-\beta_t} x_{t-1}, \beta_t I)q(xt∣xt−1)=N(xt∣1−βt xt−1,βtI)
逆向过程学习噪声预测网络 sθ(xt,t)s_\theta(x_t, t)sθ(xt,t),训练目标为:
minθEx0,t,ϵ∥sθ(xt,t)−ϵ∥2\min_\theta E_{x_0, t, \epsilon} \\\|s_\\theta(x_t, t) - \\epsilon\\\|\^2 θminEx0,t,ϵ∥sθ(xt,t)−ϵ∥2
2.3 联合建模与时间步解耦
UWM 定义联合噪声预测网络:
(ϵθa,ϵθo′)=sθ(o,ata,oto′′,ta,to′)(\epsilon_\theta^a, \epsilon_\theta^{o'}) = s_\theta(o, a_{t_a}, o'{t{o'}}, t_a, t_{o'})(ϵθa,ϵθo′)=sθ(o,ata,oto′′,ta,to′)
训练时 tat_ata 和 to′t_{o'}to′ 独立采样,模型暴露于所有噪声组合。
训练损失 :
L=Ewa∥ϵθa−ϵa∥2+wo′∥ϵθo′−ϵo′∥2L = E w_a \\\|\\epsilon_\\theta\^a - \\epsilon_a\\\|\^2 + w_{o'} \\\|\\epsilon_\\theta\^{o'} - \\epsilon_{o'}\\\|\^2 L=Ewa∥ϵθa−ϵa∥2+wo′∥ϵθo′−ϵo′∥2
其中带噪样本由下式生成:
ata=αˉtaa+1−αˉtaϵaa_{t_a} = \sqrt{\bar{\alpha}{t_a}} a + \sqrt{1-\bar{\alpha}{t_a}} \epsilon_aata=αˉta a+1−αˉta ϵa
oto′′=αˉto′o′+1−αˉto′ϵo′o'{t{o'}} = \sqrt{\bar{\alpha}{t{o'}}} o' + \sqrt{1-\bar{\alpha}{t{o'}}} \epsilon_{o'}oto′′=αˉto′ o′+1−αˉto′ ϵo′
2.4 四种推理模式
以策略采样为例(to′=Tt_{o'}=Tto′=T):
at−1=1αt(at−βt1−αˉtsθ(o,at,oT′,t,T))+σtδta_{t-1} = \frac{1}{\sqrt{\alpha_t}}(a_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}t}} s\theta(o, a_t, o'_T, t, T)) + \sigma_t \delta_tat−1=αt 1(at−1−αˉt βtsθ(o,at,oT′,t,T))+σtδt
其他模式同理,通过设置 tat_ata 或 to′t_{o'}to′ 为 000 或 TTT 实现条件/边缘采样。
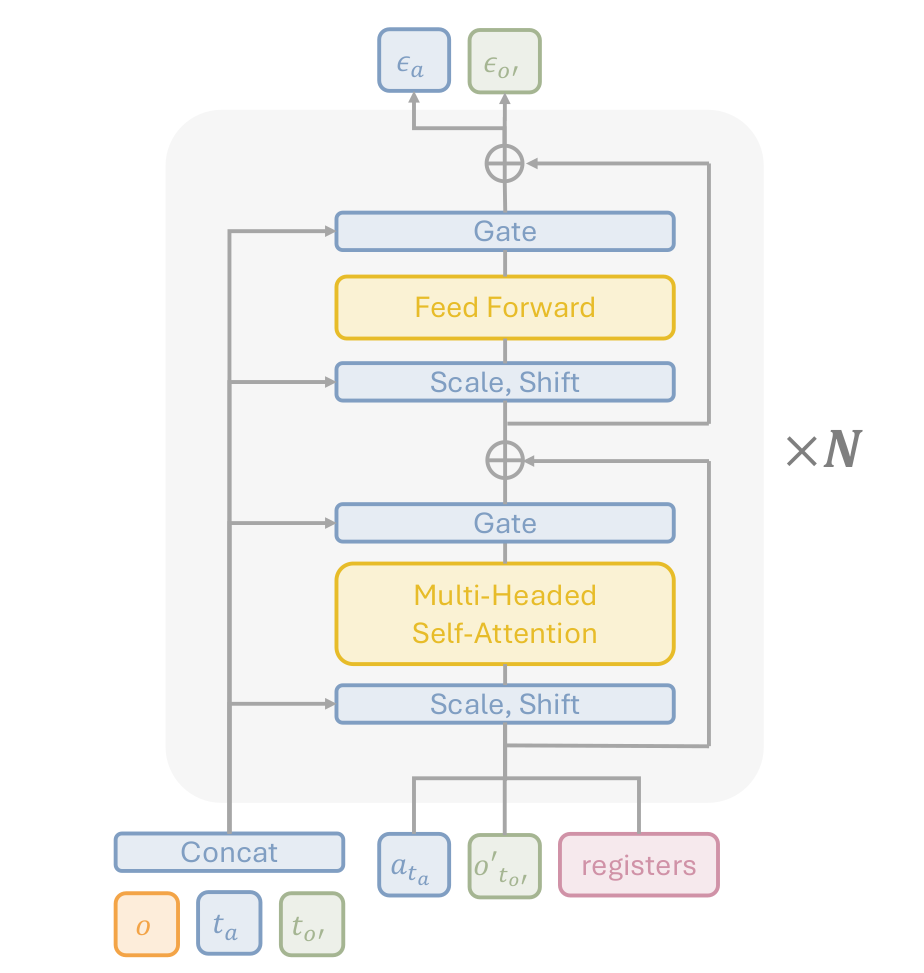
2.5 模型架构
| 组件 | 说明 |
|---|---|
| 观测编码 | ResNet-18 编码多视角图像 |
| 潜在扩散 | SDXL VAE 压缩图像到 28×28×428 \times 28 \times 428×28×4 潜在空间 |
| 动作编码 | MLP 编码动作块为 token |
| 时间步编码 | 正弦编码 tat_ata 和 to′t_{o'}to′ |
| 主干网络 | Diffusion Transformer,AdaLN 条件注入 |
| Register Tokens | 可学习 token,促进模态间信息交换 |
3. 实验设计
3.1 数据集
| 数据 | 来源 | 数量 | 用途 |
|---|---|---|---|
| 机器人数据 | DROID | 2000 轨迹 | 预训练 |
| 无动作视频 | DROID(去动作) | 2000 轨迹 | 协同训练 |
| 真实任务 | 遥操作采集 | 50-150/任务 | 微调 |
| 仿真基准 | LIBERO-100 | 90+10 任务 | 标准化评估 |
3.2 真实世界任务
| 任务 | 难度 | 成功标准 |
|---|---|---|
| Stack-Bowls | 精确定位 | 粉碗叠放于蓝碗上 |
| Block-Cabinet | 多阶段 | 开门→抓块→放入柜 |
| Paper-Towel | 精确操作 | 纸巾直立放置不倒 |
| Hang-Towel | 可变形物体 | 毛巾挂于钩上 |
| Rice-Cooker | 长时程 | 倒米→放内胆→合盖 |
3.3 基线方法
| 方法 | 特点 | 与 UWM 差异 |
|---|---|---|
| Diffusion Policy (DP) | 动作扩散 | 无图像预测 |
| PAD | 联合扩散 | 共享时间步 |
| GR-1 | 回归式 | 非扩散,确定性预测 |
4. 实验结果
4.1 真实机器人结果
Stack-Bowls
| 方法 | ID | OOD |
|---|---|---|
| UWM | 0.86 | 0.76 |
| DP | 0.48 | 0.36 |
| PAD | 0.08 | 0.08 |
| GR-1 | 0.66 | 0.48 |
Block-Cabinet
| 方法 | ID | OOD |
|---|---|---|
| UWM | 0.76 | 0.60 |
| DP | 0.60 | 0.26 |
| PAD | 0.00 | 0.00 |
| GR-1 | 0.66 | 0.44 |
Paper-Towel
| 方法 | ID | OOD |
|---|---|---|
| UWM | 0.78 | 0.78 |
| DP | 0.52 | 0.48 |
| PAD | 0.42 | 0.34 |
| GR-1 | 0.60 | 0.60 |
Hang-Towel
| 方法 | ID | OOD |
|---|---|---|
| UWM | 0.82 | 0.64 |
| DP | 0.64 | 0.28 |
| PAD | 0.52 | 0.30 |
| GR-1 | 0.66 | 0.48 |
Rice-Cooker (ID only)
| 方法 | 成功率 |
|---|---|
| UWM | 0.60 |
| DP | 0.35 |
| PAD | 0.00 |
| GR-1 | 0.40 |
UWM 在所有任务上显著优于基线,OOD 场景下优势更明显。
4.2 视频协同训练效果
| 任务 | 仅预训练 | +视频协同 | 提升 |
|---|---|---|---|
| Stack-Bowls | 0.86 | 0.92 | +6% |
| Block-Cabinet | 0.76 | 0.84 | +8% |
| Paper-Towel | 0.78 | 0.86 | +8% |
UWM 能有效利用无动作视频提升性能。
4.3 仿真基准结果 (LIBERO)
| 方法 | 平均成功率 |
|---|---|
| UWM | 0.79 |
| DP | 0.71 |
| GR-1 | 0.58 |
| PAD | 0.57 |
5. 分析与消融实验
5.1 前向动力学预测
实验:给定当前观测和动作,预测未来图像。UWM 能准确预测机器人和物体的未来位姿。
5.2 逆动力学轨迹跟踪
| 方法 | Book-Caddy | Soup-Cheese |
|---|---|---|
| 逆动力学 | 0.65 | 0.55 |
| 标准策略 | 0.47 | 0.26 |
逆动力学生成的动作能更精确地跟随参考轨迹。
5.3 多类别 OOD 泛化
在光照(L1,L2)、背景(B1,B2)、杂乱(C1,C2)共 30 次测试中:
| 方法 | 成功次数 |
|---|---|
| UWM (+视频) | 21 |
| UWM (仅预训练) | 15 |
| DP | 6 |
5.4 消融实验
| 消融项 | 最佳 | 较差 | 结论 |
|---|---|---|---|
| Register Tokens | 0.88 (8个) | 0.81 (无) | 促进跨模态通信 |
| 预测目标 | 0.86 (未来) | 0.70 (当前) | 动态预测优于重建 |
| 条件注入 | AdaLN | Cross-Attn | AdaLN 更适合动作 |
| 视频来源 | 0.92 (域内) | 0.88 (互联网) | 域内更佳 |
5.5 预训练 vs 从零训练
| 方法 | 从零 | 预训练 | 提升 |
|---|---|---|---|
| UWM | ~0.45 | ~0.86 | 大幅 |
| DP | ~0.40 | ~0.52 | 有限 |
6. 核心创新总结
| 创新点 | 说明 |
|---|---|
| 解耦扩散时间步 | 独立控制 tat_ata 和 to′t_{o'}to′,实现 4 种推理模式 |
| 统一模型框架 | 单模型支持策略/动力学/逆动力学/视频预测 |
| 视频协同训练 | 固定 ta=Tt_a=Tta=T 即可利用无动作视频 |
| Register Tokens | 跨模态通信机制,提升特征共享 |
| 强 OOD 泛化 | 光照/背景/杂乱等场景下保持鲁棒 |
7. 局限性与未来方向
| 局限性 | 未来方向 |
|---|---|
| 未使用人类视频 | 跨具身视频学习 |
| 预测存在伪影 | 更先进的视频生成模型 |
| 单步预测 | 多步密集预测 |
| 计算开销大 | 模型蒸馏、DDIM 加速 |
8. 结论
本文提出的 Unified World Models (UWM) 成功地将策略学习与世界模型统一在一个扩散框架中。通过解耦动作与视频的扩散时间步,UWM 不仅能灵活扮演多种角色,还能有效利用无动作视频数据进行协同训练。
在多项真实和仿真任务中,UWM 显著超越 Diffusion Policy、PAD、GR-1 等基线方法,尤其在分布外场景下优势明显,为构建可扩展的机器人基础模型提供了新思路。
9. 资源
- 项目主页:https://weirdlabuw.github.io/uwm/
- 代码开源:包含训练、评估脚本及预训练权重