

专栏:Redis 修行录
个人主页:手握风云
目录
[一、Set 类型](#一、Set 类型)
[1.1. 概述与特点](#1.1. 概述与特点)
[1.2. 基础命令](#1.2. 基础命令)
[1. SADD 和 SMOVE](#1. SADD 和 SMOVE)
[2. SREM 和 SPOP](#2. SREM 和 SPOP)
[3. SMEMBERS、SISMEMBER、SCARD 和 SRANDMEMBER](#3. SMEMBERS、SISMEMBER、SCARD 和 SRANDMEMBER)
[1.3. 集合间操作命令](#1.3. 集合间操作命令)
[1. SINTER 和 SINTERSTORE](#1. SINTER 和 SINTERSTORE)
[2. SUNION 和 SUNIONSTORE](#2. SUNION 和 SUNIONSTORE)
[3. SDIFF 和 SDIFFSTORE](#3. SDIFF 和 SDIFFSTORE)
[1.4. 内部编码](#1.4. 内部编码)
[1.5. 典型使用场景](#1.5. 典型使用场景)
一、Set 类型
1.1. 概述与特点
Redis 中的 Set(集合)类型是一种用于保存多个字符串元素的无序集合。与列表(List)不同,Set 中的元素是无序的,并且不允许存在重复的元素。一个 Set 最多可以存储 2^32 - 1 个元素。除了基本的增删查改操作外,Set 还支持多个集合之间的交集、并集和差集运算。
1.2. 基础命令
1. SADD 和 SMOVE
bash
SADD key member [member ...]SADD 命令的主要功能是向集合中添加一个或多个成员,如果指定的 key 不存在,系统会在添加前自动创建一个新的集合,同时会自动忽略已经存在于该集合中的指定成员。该命令的时间复杂度为添加每个元素 O(1)(批量添加 N 个元素时为 O(N)),并且会返回实际成功添加到集合中的新元素数量;需要注意的是,如果目标 key 存储的不是集合类型,则会返回错误。
bash
SMOVE source destination memberSMOVE 命令则用于将特定的成员从一个源集合移动到目标集合中,此移动操作是原子性的,其时间复杂度固定为 O(1)。执行该命令时,如果源集合不存在或其中不包含指定的成员,命令将不执行任何操作并返回 0;如果源集合包含该成员,则会将其从源集合中移除并添加到目标集合中(若目标集合已存在该元素,则仅仅从源集合中移除即可),成功移动后会返回。
bash
SADD set1 5 1 3 6 0 -4 -8
SMOVE set1 set2 6
SMOVE set1 set3 1
SMOVE set4 set2 5
SMOVE set1 set2 100
SET LLM Gemini
SADD LLM ChatGPT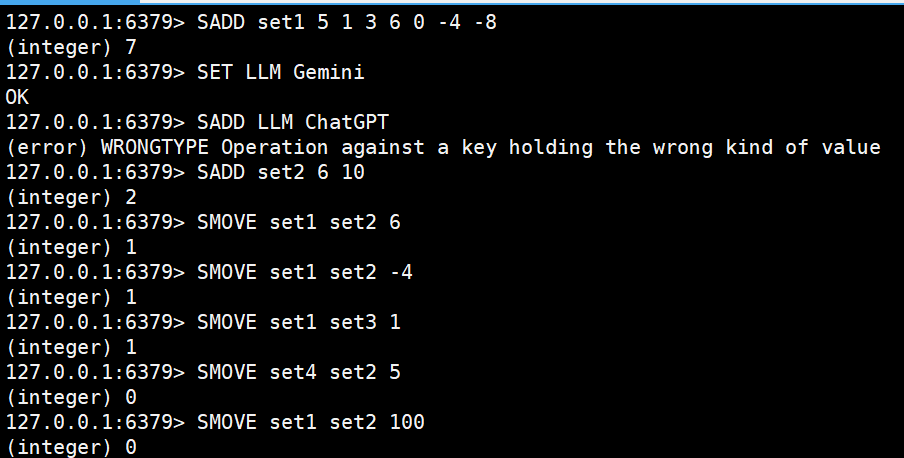
2. SREM 和 SPOP
bash
SREM key member [member ...]SREM 命令主要用于从集合中移除一个或多个指定的成员。在执行过程中,如果指定的成员原本就不在集合中,则会被自动忽略。若指定的 key 不存在,系统会将其视为一个空集合并返回 0;若 key 存储的并非集合类型的值,则会返回错误。该操作的时间复杂度为 O(N)(N 为需要移除的指定元素个数),并且会返回实际成功从集合中移除的元素数量。
bash
SPOP key [count]SPOP 命令用于从集合中随机移除并返回一个或多个成员。默认情况下它只弹出一个成员,但可以通过增加可选的 count 参数来指定弹出多个成员。SPOP 命令在不使用 count 参数时时间复杂度为 O(1),使用时则为 O(N)(N 为传入的 count 值),执行后会返回被随机取出的元素。不过需要注意,如果业务场景需要保证返回元素的均匀分布,SPOP 命令并不适用。
此外,这两个命令具有一个共同的特性:如果移除操作导致集合中的最后一个成员也被清空,系统会自动删除该集合。
bash
SADD set1 5 1 3 6 0 -4 -9
SREM set1 3 0 -4 100
SPOP set1
SPOP set1 20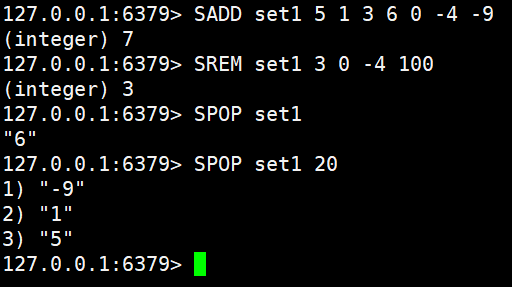
3. SMEMBERS、SISMEMBER、SCARD 和 SRANDMEMBER
SMEMBERS、SISMEMBER、SCARD 和 SRANDMEMBER 都是 Redis 中用于查询和获取集合(Set)内部元素的常用指令。
bash
SMEMBERS keySMEMBERS 命令主要用于获取指定集合中的所有元素,由于集合的特性,返回的元素是无序的,该操作的时间复杂度为 O(N)(N 为集合的元素总数)。
bash
SISMEMBER key memberSISMEMBER 命令用来判断某个特定的元素是否存在于指定集合中,如果存在则返回 1,如果该元素不在集合中或者指定的 key 不存在则返回 0,其时间复杂度固定为 O(1)。
bash
SCARD keySCARD 命令的主要功能是获取集合的基数,即直接返回集合中元素的总个数,若 key 不存在则返回 0,时间复杂度同样为 O(1)。
bash
SRANDMEMBER key [count]SRANDMEMBER 命令则用于从集合中随机获取元素:在不提供 count 参数的情况下,它会随机返回单个元素(时间复杂度为 O(1));如果提供了正数的 count 参数,它将返回一个包含不重复元素的数组(返回数量为 count 或集合总数中较小的一个);如果提供了负数的 count 参数,命令则会返回一个可能包含重复元素的数组(返回的元素数量为 count 的绝对值),在使用 count 参数时,该命令的时间复杂度为 O(N)(N 为传入 count 的绝对值)。
bash
SADD set1 5 1 3 6 0 -4 -9
SMEMBERS set1
SISMEMBER set1 7
SISMEMBER set1 0
SCARD set1
SCARD set2
SRANDMEMBER set1
SRANDMEMBER set1 3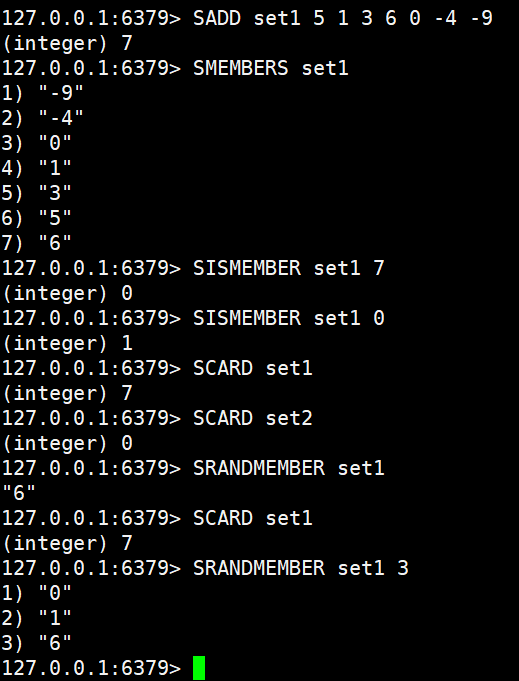
1.3. 集合间操作命令
1. SINTER 和 SINTERSTORE
bash
SINTER key [key ...]
SINTERSTORE destination key [key ...]SINTER 和 SINTERSTORE 是 Redis 中用于计算多个集合(Set)交集的指令。SINTER 命令的主要功能是获取给定多个集合的交集中的全部元素。在执行过程中,如果指定的 key 不存在,系统会将其视为一个空集合,而任何集合与空集合求交集的结果必然为空,因此只要运算对象中包含空集合,最终返回的结果也为空集合。该命令的时间复杂度为 O(N*M)(其中 N 是参与运算的集合中基数最小的集合元素个数,M 是集合的总数),执行后会直接返回交集中的所有具体元素。SINTERSTORE 命令则用于获取给定集合的交集,并将计算出的交集结果保存到一个指定的目标集合中。该命令的时间复杂度同样是 O(N*M),但与 SINTER 不同的是,SINTERSTORE 成功执行后返回的不是元素内容,而是实际保存在目标集合中的交集元素总个数。
bash
SADD set1 a b c
SADD set2 c d e
SINTER set1 set2
SINTERSTORE set set1 set2
SMEMBERS set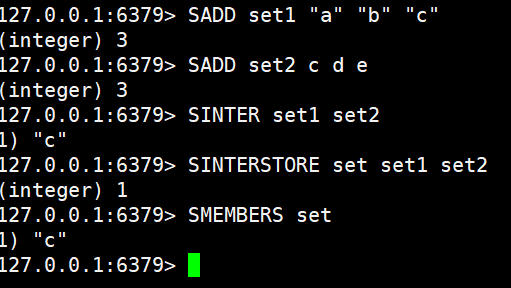
2. SUNION 和 SUNIONSTORE
bash
SUNION key [key ...]
SUNIONSTORE destination key [key ...]SUNION 和 SUNIONSTORE 是 Redis 中用于计算并获取多个集合(Set)并集的指令。SUNION 命令的主要功能是获取给定的多个集合的并集,并直接返回该并集中的所有元素。在执行该命令时,如果参数中指定的某个 key 不存在,系统会自动将其视为空集合参与运算。该命令的时间复杂度为 O(N),其中 N 代表参与运算的所有给定集合中的元素总个数。SUNIONSTORE 命令同样用于计算多个集合的并集,但与 SUNION 不同的是,它不会直接返回具体的并集元素,而是将计算得出的结果保存到一个指定的 destination(目标)集合中;如果这个目标集合已经存在,其原有的内容将会被新的并集结果直接覆盖。SUNIONSTORE 的时间复杂度同样也是 O(N)(N 为所有给定集合的元素总数),并且在成功执行后,该命令返回的是实际保存到目标集合中的并集元素总个数。
bash
SUNION set1 set2
SUNIONSTORE unset set1 set2
SMEMBERS unset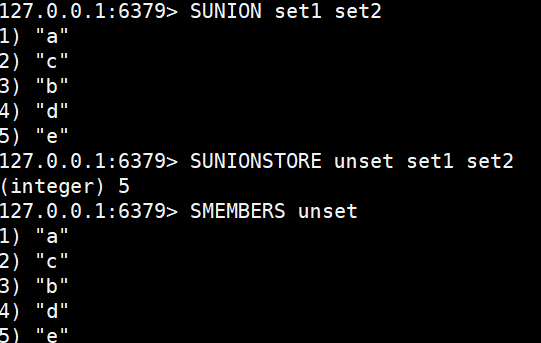
3. SDIFF 和 SDIFFSTORE
bash
SDIFF key [key ...]
SDIFFSTORE destination key [key ...]SDIFF 和 SDIFFSTORE 是 Redis 中用于计算多个集合(Set)差集的指令。SDIFF 命令的主要功能是获取给定多个集合的差集(即存在于第一个集合但不存在于其他后续集合中的元素)。在执行过程中,如果给定的某个 key 不存在,系统会自动将其视为空集合。该命令的时间复杂度为 O(N)(N 为所有给定集合中元素的总个数),执行后会直接返回差集中的所有具体元素。SDIFFSTORE 命令同样用于计算多个集合的差集,但它不会直接返回结果元素,而是将计算出的差集结果保存到一个指定的 destination(目标)集合中;如果该目标集合已经存在,其原有的内容将会被新结果直接覆盖。SDIFFSTORE 的时间复杂度同样为 O(N)(N 代表所有给定集合的元素总数),在成功执行后,该命令返回的是实际保存在目标集合中的差集元素总个数。
bash
SDIFF set1 set2
SDIFFSTORE diffset set1 set2
SMEMBERS diffset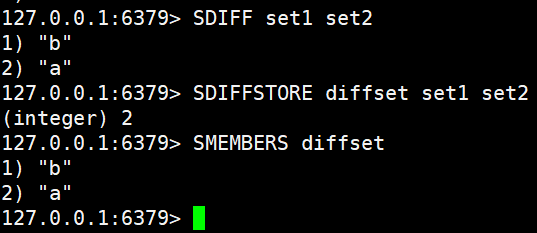
1.4. 内部编码
Redis 会根据 Set 中存储的数据特征,自动选择底层的内部编码以优化内存和性能:
- intset(整数集合): 当 Set 中的元素都是整数,并且元素的个数小于 set-max-intset-entries 配置(默认 512 个)时,Redis 会选用 intset 作为内部实现,从而减少内存的使用。
- hashtable(哈希表): 当 Set 无法满足 intset 的条件时(例如元素个数超过 512 个,或者存在非整数类型的元素),Redis 会使用 hashtable 作为集合的底层内部实现。
bash
SADD set1 1 2 3 4 5
OBJECT ENCODING set1
SADD LLM Gemini ChatGPT Claude
OBJECT ENCODING LLM1.5. 典型使用场景
Set 类型最典型的应用场景是标签(Tag)系统。 例如,在一个内容平台或电子商务网站中:
- 用户画像:用户 A 对"娱乐"、"体育"感兴趣,用户 B 对"历史"、"新闻"感兴趣,这些兴趣点可以被抽象为存储在 Set 中的标签。
- 推荐与社交:通过分析这些数据,可以找到喜欢同一个标签的人,或者计算出用户的共同喜好标签。这些数据对于增强用户体验和用户黏度(如进行不同的产品推荐)非常有帮助。
可以利用 Set 的相关命令实现以下标签功能:
- 给用户添加标签:使用 SADD 将标签加入用户的 Set 中。
- 给标签添加用户:使用 SADD 将用户加入对应标签的 Set 中。
- 删除用户下的标签 / 标签下的用户:使用 SREM 移除对应的数据。
- 计算用户的共同兴趣标签:使用 SINTER 计算两个或多个用户标签 Set 的交集。