上篇基础篇过了一遍后,我们继续,简单总结下:
智能体任务中的典型收益场景
-
重复系统提示缓存
例如复杂的智能体指令、工具说明、策略文档和数据结构定义等固定内容。这些信息每轮交互都相同,特别适合进行缓存优化。
-
增量历史上下文处理
随着对话进行,历史记录会逐步增长。对于已经处理过的历史片段,只需计算新增部分即可实现高效复用。
-
高频文档片段复用
在RAG场景中,同一批文档片段可能会被多次引用。通过缓存机制可以高效复用这些内容对应的键值对。
-
分布式部署支持
在多实例部署环境下,当请求被分发到不同vLLM实例时,配合远程存储或P2P网络,缓存机制能够实现跨实例的内容复用。
claude code源码泄露很久了,网上解析满天飞,但是你要知道,整个顶尖工程师们打磨的商用级产品,真的能让大家用大模型扫几下就全部解读完成,去完成所有细节和思路的把控嘛?你能范范而谈和能做出来和 做好 是三个层次区别! 可不仅仅是思路方向正确,缺少代码级别的细粒度实现和对模型还有agent的历史演进了解才是问题所在,在这个Ai coding趋势下,No prompt No framework code is cheap show me your token的氛围下, 一切都变得浮躁了。介于harness的理念理解基本是两类型,一个是all is harness, 另一个是harness 是agent 脑,但是这里有所不同的是:cluade code 源码是很厚重的,给到的直观感觉就是 :code is not cheap! 没错就是这么反直觉,原因就是工程级别的细粒度和策略实现。今天我们来挖一下最让我感兴趣的部分------更高级的缓存协议,通过本篇分析,你可以知道什么才是一个真正AI Agent 工作应该掌握具备的能力边界。你真的以为agent源码在手你就能复刻100%效果了嘛?
提示:第二部分附带过度解读 谨慎观看
文章目录
- 前缀缓存技术回顾
- [从 Codex 到 Claude Code:两种 LLM Agent 前缀缓存架构的工程拆解](#从 Codex 到 Claude Code:两种 LLM Agent 前缀缓存架构的工程拆解)
-
- [1. Prefix Cache 的本质:缓存的是"稳定前缀",不是"语义相似"](#1. Prefix Cache 的本质:缓存的是“稳定前缀”,不是“语义相似”)
- [2. Codex 路线:稳定会话键 + 严格前缀增量](#2. Codex 路线:稳定会话键 + 严格前缀增量)
-
- [2.1 `prompt_cache_key = conversation_id`](#2.1
prompt_cache_key = conversation_id) - [2.2 HTTP 与 WebSocket 路径不同](#2.2 HTTP 与 WebSocket 路径不同)
- [2.3 WebSocket 增量协议:三步严格校验](#2.3 WebSocket 增量协议:三步严格校验)
- [2.4 请求级失效 vs 会话级失效](#2.4 请求级失效 vs 会话级失效)
- [2.5 History 与 Context Diff](#2.5 History 与 Context Diff)
- [2.6 Compact:replacement history + window generation](#2.6 Compact:replacement history + window generation)
- [2.7 Codex 小结](#2.7 Codex 小结)
- [2.1 `prompt_cache_key = conversation_id`](#2.1
- [3. Claude Code 路线:显式断点 + 后端缓存协议协同](#3. Claude Code 路线:显式断点 + 后端缓存协议协同)
-
- [3.1 请求层:`cache_control` 是显式缓存断点](#3.1 请求层:
cache_control是显式缓存断点) - [3.2 System prompt:静态段缓存,动态段隔离](#3.2 System prompt:静态段缓存,动态段隔离)
- [3.3 TTL / scope / beta header:会话内必须锁存](#3.3 TTL / scope / beta header:会话内必须锁存)
- [3.4 Compact:用 boundary 承认历史重写](#3.4 Compact:用 boundary 承认历史重写)
- [3.5 Compact summary 自身也复用缓存](#3.5 Compact summary 自身也复用缓存)
- [3.6 Microcompact:warm cache 下不改本地历史](#3.6 Microcompact:warm cache 下不改本地历史)
- [3.7 Cache break detector:缓存下降必须可归因](#3.7 Cache break detector:缓存下降必须可归因)
- [3.8 Claude Code 小结](#3.8 Claude Code 小结)
- [3.1 请求层:`cache_control` 是显式缓存断点](#3.1 请求层:
- [4. Codex vs Claude Code:本质差异](#4. Codex vs Claude Code:本质差异)
- [5. Claude Code 工具结果压缩与缓存稳定性优化](#5. Claude Code 工具结果压缩与缓存稳定性优化)
-
- [5.1 关键术语](#5.1 关键术语)
- [5.2 标准场景流程](#5.2 标准场景流程)
- [5.3 API 请求前后对比](#5.3 API 请求前后对比)
-
- 编辑前:基线请求
- [编辑后:旧 `tool_result` 增加 `cache_reference`](#编辑后:旧
tool_result增加cache_reference) - [编辑后:最后一条用户消息插入 `cache_edits`](#编辑后:最后一条用户消息插入
cache_edits)
- [5.4 生效验证](#5.4 生效验证)
- [5.5 为什么 `cache_edits` 要跨轮 pin](#5.5 为什么
cache_edits要跨轮 pin)
- [6. Claude 推理端技术:我们能确定什么,不能确定什么](#6. Claude 推理端技术:我们能确定什么,不能确定什么)
-
- [6.1 可以确认的协议线索](#6.1 可以确认的协议线索)
- [6.2 推测中的后端数据结构](#6.2 推测中的后端数据结构)
- [6.3 `cache_control` 可能是合法 KV 存储/恢复边界](#6.3
cache_control可能是合法 KV 存储/恢复边界) - [6.4 `skipCacheWrite` 暗示 read-only / no-tail-write 模式](#6.4
skipCacheWrite暗示 read-only / no-tail-write 模式) - [6.5 `cache_edits/cache_reference` 暗示缓存条目删除或失效](#6.5
cache_edits/cache_reference暗示缓存条目删除或失效) - [6.6 没有覆盖什么](#6.6 没有覆盖什么)
- [7. 过度解读区:从 KV Cache 物理本质到 Mycro 架构假设](#7. 过度解读区:从 KV Cache 物理本质到 Mycro 架构假设)
-
- [7.1 Transformer KV Cache 的物理本质](#7.1 Transformer KV Cache 的物理本质)
- [7.2 标准 vLLM Page 的限制](#7.2 标准 vLLM Page 的限制)
- [7.3 Mycro 假设:Local Page 与 Dense Page 分离](#7.3 Mycro 假设:Local Page 与 Dense Page 分离)
- [7.4 对 vLLM 的迁移边界](#7.4 对 vLLM 的迁移边界)
- [8. 旁支补充:Qwen3.5 Hybrid Attention 新一代混合模型可能就是正解](#8. 旁支补充:Qwen3.5 Hybrid Attention 新一代混合模型可能就是正解)
-
- [8.1 Qwen3.5 的 hybrid attention 是另一类问题](#8.1 Qwen3.5 的 hybrid attention 是另一类问题)
- [8.2 Full attention 的缓存](#8.2 Full attention 的缓存)
- [8.3 Linear attention 的缓存更像状态寄存器](#8.3 Linear attention 的缓存更像状态寄存器)
- [8.4 为什么这段值得写进文章?](#8.4 为什么这段值得写进文章?)
- 总结
前缀缓存技术回顾
首先在了解工具缓存技术协议设计和实现之前,我们先要知道前缀稳定性工程和上下文压缩技术,以及claude code如何实现的。
为啥要把前缀和上下文压缩放一起说,man 你知道的,其实Agent上下文管理、工具、技能、压缩、等本质上都是物理耦合的,逻辑上是交叉的 这也是当前大部分开源agent的工程设计。
为什么要做Kvcache 命中? 原因如下
节省TOKEN和提高推理速度和首Token延迟,比如大家用Opus-4.6这种就按Token计费的话 每次多轮交互都会消耗大量TOKEN,如果利用前缀缓存,那么推理端就会缓存上一次的TOKEN block的KV值复用,这样核心做法思路就是三个原则:
1.它先把请求拆成"真正稳定的静态前缀"和"不可避免会变的动态尾部"。
2.它再把所有可能中途翻转的开关锁住,让同一会话里发送给模型的前缀尽量不变。
3.当必须压缩历史工具结果时,它尽量不继续改正文,而是把删除意图转成专门的 request sidecar,并在后续请求中原位重放,维持缓存键稳定。 这块不清楚的可以移步上篇前缀缓存工程(一)
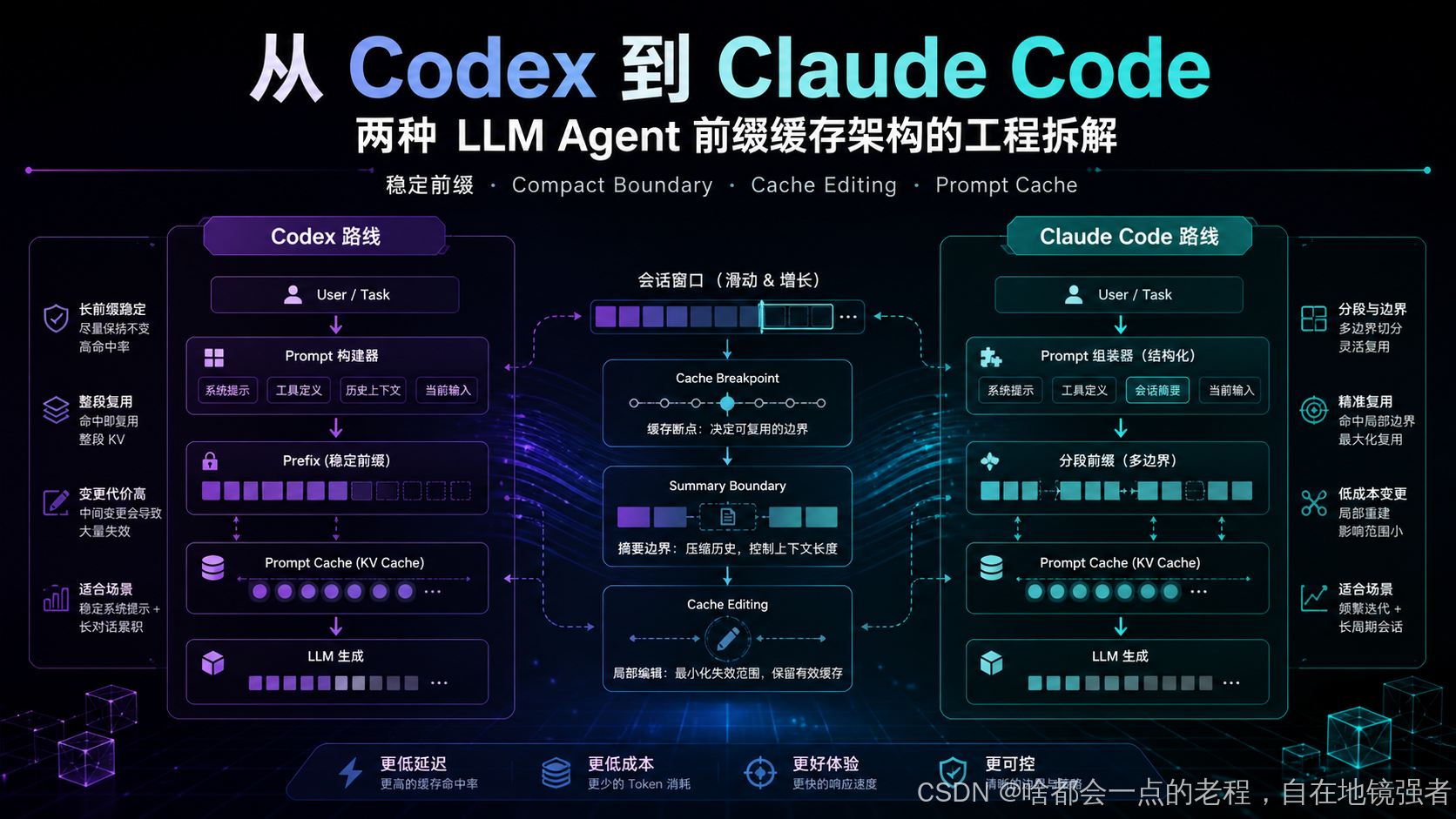
从 Codex 到 Claude Code:两种 LLM Agent 前缀缓存架构的工程拆解
面向做 Agent、Copilot、Coding Tool、Harness、推理网关或 vLLM 服务的工程师。
重点回答三个问题:
- 为什么"每轮总结历史"会破坏 prefix cache?
- Codex 和 Claude Code 分别如何稳定缓存命中?
- 自研 Agent / vLLM 系统应该先抄哪一套、哪些不能照搬?
本文综合了两份源码级报告:一份偏全局方案、vLLM 迁移和 xwork-agent 校准;另一份偏 Codex / Claude Code 的源码路径、字段和协议细节。
长会话、多工具、多轮 Agent 场景下,如何让模型请求的前缀尽量稳定,从而复用服务端已经算过的 KV / prompt cache?
我们重点对比两条路线:
| 系统 | 核心范式 | 一句话解释 |
|---|---|---|
| Codex | 稳定会话键 + 严格 append-only + WebSocket delta | 客户端尽量让下一轮 input 是上一轮 input 的严格扩展;能证明是扩展就发 delta,不能证明就发完整请求 |
| Claude Code | 显式 cache breakpoint + cache editing + cache break 归因 | 客户端直接参与 Anthropic 后端 cache 协议,告诉后端哪里缓存、哪里只读、哪些 cached tool result 可以删 |
最重要的共同点是:
两者都没有采用"每轮重新总结历史,然后把 summary 插入历史中间"的方案。
因为这个方案会让模型可见 prompt 的 token 前缀持续变化。一旦在中间插入、删除、改写内容,prefix cache 通常只能命中插入点之前的部分,插入点之后的 token 位置、chunk/page 边界都会漂移。
1. Prefix Cache 的本质:缓存的是"稳定前缀",不是"语义相似"
很多人会误以为:
"我只是加了一段 summary,语义差不多,应该还能命中缓存吧?"
不行。Prefix cache 关心的不是语义,而是模型可见 token 序列的前缀是否一致。
它至少依赖三类稳定性:
- 文本 token 前缀稳定:前 N 个 token 必须一致。
- 非文本 cache key 字段稳定:model、tools、system、reasoning config、cache marker、beta/header 等不能漂。
- 历史压缩必须是边界事件:compact 不能每轮随意改写历史中间。
稳定前缀
system + tools + old history
新增尾部
user turn
高命中
append-only
稳定前缀
system + tools
中间插入
summary / dynamic context
后续 token 位置变化
chunk/page 边界漂移
低命中
只能命中插入点之前
所以 Agent 系统里最危险的事情,不是 prompt 变长,而是:
text
把会变化的东西插到稳定历史之前或中间。例如:
- 每轮重新生成 summary,放到 history 前面;
- 每轮把 runtime context 全量插到历史前;
- skill catalog / tool directory 变化后仍放在 old history 前;
- 清理旧 tool result 时直接改写本地历史中间内容;
- tools schema 顺序或 JSON 字段顺序不稳定;
- provider header、reasoning config、cache ttl/scope 每轮重新计算。
这些都会让 prefix cache "看起来开着,实际命中率漂"。
2. Codex 路线:稳定会话键 + 严格前缀增量
Codex 的核心思想是:
不要在客户端精细操纵 KV cache。客户端维护稳定会话窗口和严格 append-only 的 input 形状,缓存执行交给 Responses 后端。
它不是完全"不管缓存",而是把职责拆成两层:
Codex client
维护请求形状
append-only / strict prefix
稳定 prompt_cache_key
conversation_id
Responses backend
服务端 prompt / KV cache
WebSocket 路径
结构化 prefix 校验
通过则 previous_response_id + delta
不通过则完整 response.create
2.1 prompt_cache_key = conversation_id
Codex 使用 OpenAI Responses API 的 prompt_cache_key。客户端显式传入的值就是当前 conversation_id。这意味着在客户端层面,整个会话生命周期内的 prompt_cache_key 是稳定的。
可以抽象成:
text
Turn 1:
prompt_cache_key = conversation_id
input = [system, tools, user1]
Turn 2:
prompt_cache_key = conversation_id
input = [system, tools, user1, assistant1, user2]
Turn 3:
prompt_cache_key = conversation_id
input = [system, tools, user1, assistant1, user2, assistant2, user3]但这里要非常谨慎:
客户端显式字段里没有把账号、模型、reasoning、终端等编码进
prompt_cache_key,不代表服务端最终 cache key 只由 conversation id 构成。
更严谨的说法是:
text
Codex 客户端没有在 prompt_cache_key 字段里显式编码这些维度;
实际服务端大概率还会结合模型、租户、tokenizer、request fingerprint 等做隔离。否则会让人误解成"切模型还能复用同一份 KV",这在标准推理语义下显然不成立。
2.2 HTTP 与 WebSocket 路径不同
Codex 一个容易被忽略的点是:
HTTP Responses 请求体里没有
previous_response_id;previous_response_id只出现在 WebSocket 请求结构中。
也就是说,Codex 有两层优化:
| 路径 | 请求方式 | 缓存方式 |
|---|---|---|
| HTTP Responses | 发送完整 input + prompt_cache_key |
依赖服务端按稳定 key 和前缀做 prompt cache |
| WebSocket Responses | 严格 prefix 成立时发送 previous_response_id + delta input |
客户端只发新增尾部,服务端接续上一轮 response 链 |
是
否
Codex 请求
HTTP Responses
WebSocket Responses
发送完整 input
携带 prompt_cache_key
服务端前缀缓存匹配
客户端 strict prefix 校验
通过?
previous_response_id + delta input
完整 response.create
所以不能简单说"Codex 每轮都只发 delta"。更准确是:
Codex 在 WebSocket 路径上支持 delta;HTTP 路径仍发送完整 input,只是用
prompt_cache_key提示服务端做缓存复用。
2.3 WebSocket 增量协议:三步严格校验
Codex 的 WebSocket 增量不是"看起来像追加"就行,而是结构化 ResponseItem 列表级别的严格判断。
它会做三步:
-
非 input 字段必须完全一致
instructions、tools、reasoning、text、service_tier、include 等字段只要变了,本轮就不能发 delta。
-
构造 baseline
baseline = 上一轮 request.input + 上一轮 response.items_added。
-
当前 input 必须 starts_with(baseline)
成立才发送
current_input[baseline_len..],否则退回完整请求。
是
否
previous_request.input
baseline
last_response.items_added
current_request.input
current input
starts_with baseline?
发送 delta
current_inputbaseline_len..
发送完整 input
这套逻辑朴素但稳:
text
能证明是严格前缀扩展,就走增量;
不能证明,就不要赌,直接完整发送。这就是 Codex 的工程哲学:失败路径简单、边界清晰、不会在不确定时强行修补历史。
2.4 请求级失效 vs 会话级失效
Codex 的缓存失效可以分成两类。
请求级失效
这一轮不能走 WebSocket delta,但会话窗口还在,下一轮仍然可能继续增量。
| 触发 | 后果 |
|---|---|
| instructions / tools / reasoning / text / service_tier 变化 | 本轮完整 response.create |
| 当前 input 不是上一轮 baseline 的严格前缀扩展 | 本轮完整 response.create |
| 上一轮 API 错误,没有 LastResponse | 本轮完整 response.create |
| 第一轮请求 | 本轮完整 response.create |
会话级失效
整个 WebSocket 增量状态清空,通常发生在 compact / replacement history 后。
是
否
普通回合
字段变化或非严格前缀?
本轮全量
下一轮仍可增量
继续 delta
compact / replacement history
advance_window_generation
清空 websocket cached session
新窗口重新开始
一句话:
Codex 把普通 drift 视为"本轮全量",把 compact 视为"窗口重开"。
2.5 History 与 Context Diff
Codex 每次采样都会从 session history 生成模型可见 input。它会 normalize history,例如确保 tool call / tool output 配对、处理不支持的 image、按 policy 截断 tool outputs。
更重要的是,它的 TurnContext 是 diff 化的:
否
是
Session history
for_prompt
normalize
call/output 配对
strip unsupported images
Responses input
TurnContext
reference_context_item exists?
注入 full initial context
只 append settings diff
这避免了一个常见错误:
text
每轮把完整动态上下文重放到历史前面。Codex 的 steady-state 方式是:首次全量注入,之后只追加 diff。
2.6 Compact:replacement history + window generation
Codex compact 也不是每轮总结。它会生成 replacement history,然后调用 replace_compacted_history 替换当前历史。安装完成后,推进 window_generation,清掉 WebSocket 增量状态。
Current history
Compact task
生成 summary
收集真实 user messages
跳过旧 summary
保留尾部 user messages
控制 token 上限
replacement history
tail user messages + summary
replace_compacted_history
advance_window_generation
reset websocket incremental state
这里的核心不是 summary 本身,而是边界语义:
compact 是一次明确的 history rewrite boundary。旧的
previous_response_id链不能继续假装有效。
2.7 Codex 小结
Codex 的优点:
- 客户端实现相对简单;
- 普通回合 append-only,失败路径清晰;
- WebSocket delta 的判断条件明确;
- compact 后直接重开窗口,不制造半失效状态。
Codex 的代价:
- 中间编辑能力弱;
- 没有 Claude 那种
cache_edits/cache_reference; - 命中遥测主要依赖
cached_input_tokens; - 没有同等级别的 cache break detector;
- 会话恢复后,
previous_response_id是瞬态状态,第一轮通常需要全量。
一句话总结:
Codex 把 prompt 当成 append-only log,把会话窗口当成缓存边界。
3. Claude Code 路线:显式断点 + 后端缓存协议协同
Claude Code 的路线更复杂,也更强控制。
它的核心思想是:
客户端不仅拼 prompt,还显式参与 Anthropic first-party 后端的 prefix cache 协议。
它会做几件事:
- 在 message / system block 上摆
cache_controlbreakpoint; - 把 system prompt 切成静态段和动态段;
- 把 TTL / scope / beta header 等影响 cache key 的字段锁存;
- compact 时用 boundary 处理历史重写;
- 生成 compact summary 时也复用主线程缓存;
- warm cache 下通过
cache_reference/cache_edits删除旧 tool result; - 用 prompt cache break detector 做命中下降归因。
3.1 请求层:cache_control 是显式缓存断点
Claude Code 在 Anthropic 请求里设置 cache_control。普通请求中,message-level marker 放在最后一条 message;如果是 skipCacheWrite 的 fork 请求,则 marker 放在倒数第二条共享前缀 message 上。
false 普通请求
true fork / read-only 请求
messages for API
normalizeMessagesForAPI
addCacheBreakpoints
skipCacheWrite?
cache_control 放最后一条 message
cache_control 放倒数第二条共享前缀
Anthropic API
后端 KV/page cache
这个设计的意义是:
| 场景 | marker 位置 | 目的 |
|---|---|---|
| 普通请求 | 最后一条 message | 写入当前稳定前缀 |
| forked compact / 短命子任务 | 倒数第二条共享前缀 | 只读父线程缓存,不把 fork tail 写进主线程 KV |
抽象成:
text
普通请求:
[system + tools + history + new user] <-- cache marker
fork 请求:
[system + tools + shared history] <-- cache marker
[compact summary request / child task] <-- 不污染主线程 cacheClaude Code 的关键能力在这里:
它不只是"希望前缀稳定",而是显式告诉后端"缓存边界在这里"。
3.2 System prompt:静态段缓存,动态段隔离
Claude Code 把 system prompt 切成多段:
SystemPrompt\[\]
billing / attribution header
no cache
CLI system prompt prefix
org/no cache by mode
static blocks before boundary
global/org cache
dynamic blocks after boundary
not global cached
设计原则是:
text
稳定内容扩大缓存面;
动态内容不要污染全局缓存。| 内容类型 | 应该怎么处理 |
|---|---|
| 固定系统指令 | 放入稳定 system prefix |
| 静态工具说明 | 稳定排序后缓存 |
| 动态用户状态 | 不进 global cache |
| 时间、overage、feature flag | 不能中途改变 cache key |
| runtime context | 尽量放到尾部或 diff 化 |
3.3 TTL / scope / beta header:会话内必须锁存
Claude Code 不是简单设置 ttl: '1h' 或 scope: 'global'。它更重要的做法是:
凡是会影响
cache_control或服务端 cache key 的字段,都要在 session 内稳定。
例如:
- 1h cache TTL 的 eligibility;
- GrowthBook allowlist;
- overage 状态;
- cache editing beta header;
- AFK mode beta header;
- global cache strategy。
这些字段会在 bootstrap / state 中 sticky latch,避免中途实验配置刷新或用户状态变化导致 cache key 翻转。
首次请求
计算 eligibility / allowlist / beta headers
写入 bootstrap state
Turn 1 使用固定值
Turn 2 使用固定值
Turn N 使用固定值
中途 overage / 实验配置变化
不改变本 session cache 字段
这条经验非常值得自研 Agent 学:
text
不要在每一轮请求时重新计算会影响 cache key 的策略字段。否则你会遇到一种非常难查的问题:
text
prompt 文本没变,但 cache miss 了。原因可能只是某个 header、TTL、scope、beta flag 或 reasoning config 变了。
3.4 Compact:用 boundary 承认历史重写
Claude Code compact 的核心是:
- 旧历史生成 summary;
- 创建
compact_boundary; - 模型可见历史从最后一个 boundary 后开始;
- compact 后通知 cache break detector 重置 baseline。
否
是
完整 REPL history
需要 compact?
继续 append-only 追加
创建 compact_boundary
生成 compact summary
新上下文
boundary + summary + retained state
notifyCompaction + markPostCompaction
重置 cache baseline
它的原则和 Codex 一样:
compact 是边界事件,不是每轮历史微改写。
区别在于:
| 系统 | compact 后的边界表达 |
|---|---|
| Codex | replacement history + advance_window_generation |
| Claude Code | compact_boundary + compact summary + notifyCompaction |
3.5 Compact summary 自身也复用缓存
Claude Code 更进一步:生成 summary 的请求本身也要尽量复用主线程 cache。
它通过 forked agent 做 compact summary,并把主线程的 cache-safe 参数传进去:
- system prompt;
- user context;
- system context;
- tools;
- model;
- parent context messages;
- thinking/reasoning 相关配置。
然后设置 skipCacheWrite: true,避免 fork tail 污染主线程缓存。
主线程请求
system/tools/history prefix 已缓存
保存 CacheSafeParams
触发 compact
forked compact agent
同 system/tools/model/history prefix
只追加 summary request
复用主线程 prefix cache
skipCacheWrite
不污染主线程 KV
这点对长会话 Agent 很关键:
text
compact 本身通常发生在上下文很长的时候;
如果 compact summary 请求不能命中缓存,它会非常贵。3.6 Microcompact:warm cache 下不改本地历史
长工具链 Agent 会产生大量 tool result。最直接的压缩方式是:
text
把旧 tool result 改成 [cleared]但这样会改写历史中间内容,破坏后续前缀。
Claude Code 的做法是分情况:
是
否,TTL 过期
旧 tool_result 太多
server prefix cache 仍 warm?
给 tool_result 加 cache_reference
插入 cache_edits.delete(ref)
本地 history 不改
客户端 prompt 序列稳定
直接替换旧 tool_result 内容
通知这是预期 cache drop
具体机制包括:
- 给 cached prefix 内的
tool_result打cache_reference = tool_use_id; - 需要删除时生成
cache_editsblock; cache_edits被 pin 到原始 user message 位置;- 后续请求继续重放 pinned edits;
- 对重复
cache_reference做 dedup; - 通知 cache break detector 这是预期下降。
旧 tool_result
cache_reference = tool_use_id
需要删除
cache_edits.delete(ref)
pin 到 user message index
本轮请求插入 cache_edits
后续请求继续重放
按 cache_reference 去重
cache deletion 是预期下降
这里要加一个非常重要的限制:
cache_edits/cache_reference是 Anthropic first-party 后端支持的协议语义,不能直接泛化成"标准 Transformer 后端可以任意删除中间 KV 并复用后缀 KV"。
对 vLLM 这类标准 APC 实现,安全做法只有两种:
| 做法 | 是否安全 | 说明 |
|---|---|---|
| 删除缓存索引,不改变 prompt 语义 | 安全 | 只是让未来不复用这些缓存 |
| 从删除点之后重新 prefill | 安全 | 只复用删除点之前的 prefix |
| 删除中间 KV 但保留后缀 KV | 危险 | position / attention dependency 通常不成立 |
3.7 Cache break detector:缓存下降必须可归因
Claude Code 有专门的 prompt cache break detector。它会记录请求前后的 cache read tokens,并快照一组可能影响 cache key 的字段。
典型字段包括:
| 字段 | 用途 |
|---|---|
| systemHash | system prompt 文本是否变化 |
| toolsHash | tool schema 是否变化 |
| cacheControlHash | ttl / scope / cache marker 是否变化 |
| model | 模型是否变化 |
| effortValue / reasoning | reasoning 配置是否变化 |
| extraBodyHash | provider extra body 是否变化 |
| betas / headers | beta/header 是否变化 |
| cachedMCEnabled | microcompact 状态是否变化 |
| fastMode / globalCacheStrategy | 运行策略是否变化 |
| cacheDeletionsPending | 是否存在预期 cache deletion |
否
是
是
否
请求前
记录 system/tools/cacheControl/model/reasoning/header hash
请求后
读取 cache_read/cache_creation/cache_deleted
cache read 明显下降?
正常
compact / TTL / cache_edit?
预期下降
重置 baseline
真正 cache break
输出字段级 diff
很多系统只记录:
text
cached_tokens = 12345但这只能告诉你"有没有命中",不能告诉你"为什么没命中"。更好的观测应该是:
text
cached_tokens 下降了;
system 没变;
toolsHash 变了;
reasoning_effort 从 medium 变 high;
cache_control ttl 没变;
本轮没有 compact;
因此这是 reasoning config drift 导致的 cache break。3.8 Claude Code 小结
Claude Code 的优点:
- 显式控制缓存断点;
- system 静态/动态切分精细;
- forked compact 可以复用主线程缓存;
- warm cache 下可以通过协议层 edit 处理旧 tool result;
- cache break 归因能力强;
- 适合长会话、多工具、多子 agent 场景。
Claude Code 的代价:
- 客户端复杂度高;
- 强依赖 Anthropic first-party 后端语义;
cache_edits不能随便迁移到 vLLM;- 任何 TTL、scope、beta、header、tool schema hash 漏算都可能导致缓存漂移;
- 需要很强的 telemetry 和测试兜底。
一句话总结:
Claude Code 把 prompt 当成结构化多段文档,并把客户端变成后端 cache 协议的参与者。
4. Codex vs Claude Code:本质差异
共同问题
长会话如何稳定命中 prefix cache?
Codex
Claude Code
prompt_cache_key = conversation_id
普通回合 append-only
WebSocket strict prefix delta
compact 后 window_generation
客户端不编辑 KV cache
cache_control breakpoint
system 静/动切分
ttl/scope/header latch
cache_reference/cache_edits
cache break detector
| 维度 | Codex | Claude Code |
|---|---|---|
| 缓存协议 | Responses prompt_cache_key + WebSocket previous_response_id |
Anthropic cache_control + cache_reference/cache_edits |
| 谁控制缓存断点 | 服务端托管,客户端维护请求形状 | 客户端显式摆放断点 |
| 普通回合策略 | append-only input | 稳定 system/tools/context + message-level marker |
| 增量能力 | WebSocket 严格 prefix 时发 delta | 通过 cache marker 复用服务端 prefix |
| 中段编辑能力 | 无等价机制 | warm cache 下使用 cache editing API |
| compact 语义 | replacement history + window_generation | compact_boundary + summary + baseline reset |
| 子代理缓存 | 依赖同会话 / 同 response 链形状 | CacheSafeParams + skipCacheWrite |
| 遥测 | cached_input_tokens 为主 | cache_read/cache_creation/cache_deleted + break detector |
| 工程复杂度 | 中等 | 高 |
| 迁移到 vLLM | 容易,主要靠网关和 prompt 稳定 | 部分可借鉴,cache_edits 需谨慎 |
两者不是简单的"谁先进谁落后",而是解决问题的层次不同:
text
Codex 解决的是:会话窗口如何稳定延续。
Claude Code 解决的是:扁平 prompt 里的哪些片段应该作为 cache boundary。理论上,这两类能力是正交的,可以组合:
- 用 Codex-like 的 session/window/response_id 管理会话;
- 用 Claude-like 的
cache_control管理显式缓存边界; - 用 Claude-like 的 detector 做缓存归因;
- 用 vLLM APC 做底层自动前缀缓存;
- 用 gateway 做 prefix-aware routing。
5. Claude Code 工具结果压缩与缓存稳定性优化
上面讲的是整体架构。接下来单独展开 Claude Code 里非常有代表性的能力:工具结果压缩与缓存稳定性优化。
在长对话、多工具调用场景中,工具结果尤其容易成为上下文膨胀的来源。比如 Bash、文件搜索、代码 grep、日志分析,一次工具调用就可能返回几千甚至几万 token。
问题是:
text
不清理,后续每轮都背着大量旧工具结果;
直接改本地历史,又会破坏 prefix cache。Claude Code 的思路是:
本地对话历史尽量不变,把删除意图转成协议层 sidecar,由服务端缓存视图处理。
5.1 关键术语
tool_use:模型侧发起的工具调用块,包含唯一 ID、工具名与入参。tool_result:用户侧返回的工具执行结果,关联对应tool_use_id。cache_reference:标记缓存中旧tool_result的标识,通常等于tool_use_id。cache_edits:发送给服务端的缓存删除指令块。
5.2 标准场景流程
以构建日志分析为例:
- 用户请求分析最近 7 天构建失败日志;
- Claude 调用 Bash 工具,生成
tool_use; - Bash 返回超长日志结果,形成
tool_result; - Claude 完成分析后,旧日志结果对后续已经不重要;
- 触发 cached microcompact;
- 本地历史不变,只在请求层加
cache_reference/cache_edits; - 服务端删除或失效对应 cached content;
- cache break detector 把这次 cached tokens 下降标记为预期事件。
5.3 API 请求前后对比
编辑前:基线请求
json
{
"model": "claude-sonnet-4-5",
"system": [{
"type": "text",
"text": "You are Claude Code. Help analyze build failures.",
"cache_control": {"type": "ephemeral"}
}],
"messages": [
{
"role": "user",
"content": [{"type": "text", "text": "分析最近7天构建日志"}]
},
{
"role": "assistant",
"content": [{
"type": "tool_use",
"id": "toolu_01BashOldResult123",
"name": "Bash",
"input": {"command": "rg ERROR logs/build.log"}
}]
},
{
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": "toolu_01BashOldResult123",
"content": "超长日志内容..."
}]
},
{
"role": "assistant",
"content": [{"type": "text", "text": "分析结果"}]
},
{
"role": "user",
"content": [{
"type": "text",
"text": "继续归纳",
"cache_control": {"type": "ephemeral"}
}]
}
]
}编辑后:旧 tool_result 增加 cache_reference
json
{
"type": "tool_result",
"tool_use_id": "toolu_01BashOldResult123",
"cache_reference": "toolu_01BashOldResult123",
"content": "超长日志内容..."
}编辑后:最后一条用户消息插入 cache_edits
json
{
"role": "user",
"content": [
{
"type": "cache_edits",
"edits": [{
"type": "delete",
"cache_reference": "toolu_01BashOldResult123"
}]
},
{
"type": "text",
"text": "继续归纳",
"cache_control": {"type": "ephemeral"}
}
]
}5.4 生效验证
如果服务端返回类似 usage:
json
{
"input_tokens": 18200,
"cache_read_input_tokens": 14600,
"cache_creation_input_tokens": 2200,
"cache_deleted_input_tokens": 1200
}可以这样理解:
cache_read_input_tokens:本轮从缓存读取的 token 数;cache_creation_input_tokens:本轮新写入缓存的 token 数;cache_deleted_input_tokens:本轮删除或失效的缓存 token 数;cache_read_input_tokens下降不一定是异常,可能是cache_edits导致的预期下降。
5.5 为什么 cache_edits 要跨轮 pin
cache_edits 不是"发一次就完了"的临时字段。为了让服务端后续请求仍然保持一致的缓存视图,Claude Code 会把 edits pin 到原始 user message 位置,并在后续请求继续原位重放,同时对重复 cache_reference 做 dedup。
这个细节很关键:
text
如果本轮删除了缓存,下一轮却不再带删除指令,服务端视图可能重新回到完整前缀匹配,缓存行为会变得不稳定。所以 cached microcompact 的重点不是"删掉一段文本",而是维护一个跨轮稳定的 request-side deletion plan。
6. Claude 推理端技术:我们能确定什么,不能确定什么
这里需要特别区分两层。
我们能确认的是:
Claude Code 客户端暴露出了明显的 first-party 推理后端缓存协议痕迹。
但我们不能说:
已经掌握了 Claude 模型推理引擎源码、attention kernel、scheduler 或 KV allocator 的真实实现。
6.1 可以确认的协议线索
Claude Code 不是普通 prompt 拼接客户端,它明显在和 Anthropic first-party 后端缓存协议协作。线索包括:
cache_control:客户端决定服务端在哪个前缀位置建 cache;scope: global/org和ttl: 1h:后端 prompt cache 策略字段;cache_reference:标记可被删除的 tool result cache entry;cache_edits:请求后端删除某些 cached content;cache_deleted_input_tokens:API 返回缓存删除 token;- 源码注释中出现 Mycro、KV pages、KVCC、dense pages、
cache_store_int_token_boundaries等后端缓存相关概念。
这些说明它确实涉及 Claude 推理服务端的缓存协议。
6.2 推测中的后端数据结构
从客户端字段反推,Claude 后端可能维护类似这样的缓存结构:
text
CacheNamespace = scope + tenant/org + model + tokenizer/chat_template + tools hash + beta/reasoning config
BlockHash = hash(parent_hash, token_ids_in_block, extra_hashes, namespace)
CacheEntry {
block_ids: [KVBlockId],
token_start,
token_end,
boundary_kind: cache_control marker,
ttl,
scope,
ref_cnt,
last_access,
cache_references: Map<cache_reference, TokenSpan or BlockSpan>
}也就是说,它可能不是简单按字符串缓存,而是有:
- namespace 隔离;
- block/page 级 KV cache;
- cache boundary;
- TTL / scope;
- cache reference;
- cache edit metadata。
6.3 cache_control 可能是合法 KV 存储/恢复边界
cache_control marker 很可能不是普通 metadata,而是后端可恢复 KV prefix 的"存储边界"。
原因是 Claude Code 对 marker 数量和位置极其敏感,而且相关注释提到了 Mycro、KV pages、cache_store_int_token_boundaries 等概念。
可以理解成:
普通请求
skipCacheWrite
Claude request
tokenize
定位 cache_control marker
计算 block/page hash
查找已缓存 KV blocks
只 prefill 未命中的 suffix
是否写缓存?
在 cache_control boundary 存储 KV
只读共享前缀
不写 fork tail
6.4 skipCacheWrite 暗示 read-only / no-tail-write 模式
skipCacheWrite 的行为暗示后端可能存在类似 read-only cache mode:
text
普通请求:
cache_control 放最后一条 message
fork / skipCacheWrite 请求:
cache_control 放倒数第二条共享前缀 message含义是:
text
共享前缀可以复用;
fork 自己追加的尾部不要写进主线程 cache。这对 compact summary、子代理、短命任务尤其重要。
6.5 cache_edits/cache_reference 暗示缓存条目删除或失效
Claude Code 会给旧 tool_result 打 cache_reference,然后用 cache_edits.delete(cache_reference) 请求后端删除。API 还会返回 cache_deleted_input_tokens。
客户端流程是:
- 给
tool_result加cache_reference: tool_use_id; - 插入
cache_editsblock; cache_edits需要跨轮 pin;- 后续请求继续重放;
- 对重复 delete 做 dedup;
- 删除导致 cache read 下降时,标记为预期下降。
这说明后端至少支持某种"缓存引用 + 删除/失效"的协议面。
但要注意:
这不等于我们知道后端真的能"删除中间 KV 后继续无损复用后缀 KV"。
6.6 没有覆盖什么
| 没有覆盖 | 说明 |
|---|---|
| 模型结构 | 比如 Claude 的 transformer 细节、attention 变体、MoE 与否 |
| CUDA kernel | 没有 kernel / FlashAttention / paged attention 源码 |
| scheduler | 没有 Anthropic 内部调度器实现 |
| KV allocator 源码 | 只从客户端协议推测 KV page/cache store |
| cache eviction 真实算法 | 只看到 TTL/scope/page 相关线索 |
cache_edits 的数学语义 |
不知道到底是删除 cache index、逻辑 tombstone,还是重算后缀 |
最准确的表述应该是:
text
Claude Code 暴露出明显的 first-party 推理后端缓存协议痕迹:
cache_control 对应显式 KV 存储边界,cache_reference/cache_edits 对应可寻址缓存条目删除,
ttl/scope/beta latch 对应 server-side cache key 稳定性,
cache_deleted_input_tokens/cache_read_input_tokens 对应后端缓存遥测。
但这些结论来自客户端源码和 API 字段推断,不等价于掌握 Claude 模型推理引擎源码。
对自建 vLLM 只能借鉴其协议思想,不能直接假设任意中段 KV 删除后仍可复用后缀 KV。7. 过度解读区:从 KV Cache 物理本质到 Mycro 架构假设
这一节是推测,不是已确认源码事实。建议选择性阅读。
7.1 Transformer KV Cache 的物理本质
忘掉上层 API,一个 token 进入多层 Transformer 后,每层都会生成一对 K、V 向量:
text
Token[42]:
Layer 0: K0[42], V0[42]
Layer 1: K1[42], V1[42]
...
Layer N: KN[42], VN[42]粗略估算:
text
单向量:128~256 维 × fp16 ≈ 256~512 字节
单 token 总 KV:层数 × 2 × 单向量大小对于长上下文,这部分显存和带宽成本非常可观。
7.2 标准 vLLM Page 的限制
标准 vLLM / PagedAttention 思路里,KV cache 通常按 block/page 管理。例如 block size = 16 时,一个 page 管理一段连续 token 的 KV。
text
vLLM Page(block_size=16)
┌────────────────────────────┐
│ Token112~127 的多层 KV │
└────────────────────────────┘它的优点是 block 化管理简单、高效、适合 prefix cache。
但如果你要做"中间删除",问题就来了:
text
删除中间 token 后,后续 token 的 position 和 attention 依赖都会变化;
不能简单删掉中间 page,然后假装后缀 page 仍然完全正确。这就是为什么本文反复强调:不能把 cache_edits 简单照搬到标准 vLLM。
7.3 Mycro 假设:Local Page 与 Dense Page 分离
根据客户端注释里出现的 Mycro、KV pages、dense pages 等线索,可以做一个合理猜测:Claude 后端可能不是把所有层的 KV 都绑在同一种 page 里,而是按注意力类型拆分出不同缓存池。
一种可能的抽象是:
- Local Page Pool:存局部 / 滑窗注意力层的 KV;
- Dense Page Pool:存全局注意力层的 KV。
text
Local Page
┌────────────────────────────┐
│ 局部/窗口注意力层 KV │
└────────────────────────────┘
Dense Page
┌────────────────────────────┐
│ 全局注意力层 KV │
└────────────────────────────┘如果模型里存在大量 sliding-window attention 层,那么远距离历史对这些层不可见。删除很久以前的一段工具结果时,局部层可能不需要为全局后缀付出完整重算成本;真正需要谨慎处理的是全局注意力层。
这类结构如果成立,就能解释为什么后端会出现"local pages / dense pages / cache boundaries"这样的工程概念。
但再次强调:
这是一种从协议和注释反推的架构假设,不是 Claude 推理端源码事实。
7.4 对 vLLM 的迁移边界
对自建 vLLM 来说,安全迁移方式是:
text
安全 A:删除缓存索引,不改变 prompt 语义。
安全 B:真正删除 prompt,但从删除点之后重新 prefill。
危险:删除中间 KV,同时保留后缀 KV。中段删除需求
安全 A
删除缓存索引
prompt 不变
安全 B
删除 prompt
从删除点重算后缀
危险
删中间 KV 但保留后缀
position / attention dependency invalid
8. 旁支补充:Qwen3.5 Hybrid Attention 新一代混合模型可能就是正解
比如 Qwen3.5 的 hybrid attention
8.1 Qwen3.5 的 hybrid attention 是另一类问题
Qwen3.5 这条线的 hybrid attention,和"滑窗 + 全局注意力"的 hybrid 不是一回事。它更接近:
text
多数层 linear_attention,少数层 full_attention。常见默认模式可以理解为每 4 层里 3 层 linear、1 层 full;实际 checkpoint 也可能直接给出自己的 layer_types。
图里两类层在推理时的缓存对象完全不同:
| 层类型 | 缓存对象 | 是否随上下文长度 T 线性增长 |
|---|---|---|
| full attention | 标准 K/V cache | 是 |
| linear attention / GDN / Mamba-like | 固定大小 state,例如 conv_state + recurrent_state |
基本不是 |
8.2 Full attention 的缓存
Full attention 层每生成一个新 token,都要把新的 K/V 追加进去。所以单层缓存字节数近似是:
text
bytes ≈ T × 2 × n_kv × d × s其中:
T是上下文长度;n_kv是 KV 头数;d是 head dim;s是 dtype 字节数。
这意味着 full attention 的 decode 成本和内存带宽压力会随着上下文增长。
8.3 Linear attention 的缓存更像状态寄存器
Linear attention / GDN 层的缓存不是"整段历史 K/V 列表",而是固定大小状态:
text
state = conv_state + recurrent_state可以抽象成:
text
new_state = f(old_state, q_t, k_t, v_t)
o_t = g(new_state, q_t)它的 decode 不需要回头扫描所有历史 token,而是更新固定状态。
这会带来两个直接后果:
- 计算复杂度不随上下文长度线性增长;
- 内存带宽压力小很多,因为 decode 时读写的是固定大小 state,而不是整段历史 K/V。
8.4 为什么这段值得写进文章?
它可以帮读者理解:
不同模型结构下,"缓存"的物理对象并不总是同一类东西。
Full attention 的缓存是历史 K/V 列表;linear/recurrent attention 的缓存更像状态槽位。于是,当我们讨论 prefix cache、KV cache、cache edit、microcompact 时,不能只用一种后端假设套所有模型。
但这节一定要加边界:
text
Qwen3.5 hybrid attention 是用于理解不同缓存物理形态的旁支案例;
它不能作为 Claude Mycro 架构的直接证据。总结
Codex 和 Claude Code 的缓存工程,本质上代表了两种范式:
Codex 的精髓是:把对话历史维护成严格 append-only log,用稳定会话键和 WebSocket delta 延续窗口。
Claude Code 的精髓是:把 prompt 当成结构化缓存文档,用显式 breakpoint、cache edit 和 cache break detector 管理后端 KV cache。
如果你做自研 Agent,最稳按这个顺序演进:
text
第一步:稳定 prompt 形状,普通回合 append-only。
第二步:把 compact 变成显式 boundary,不要每轮总结。
第三步:接入 cached_tokens / cache_read / TTFT 观测。
第四步:多副本时做 prefix-aware routing。
第五步:再引入显式 cache_control。
第六步:只有在后端语义可证明正确时,才做 cache_reference/cache_edits。最后强调:
text
不要每轮总结历史。
不要把 summary 插到历史中间。
不要每轮把动态 context 放到 old history 前。
不要让 tool schema 顺序漂。
不要把 provider/header/reasoning 配置每轮重新计算。
不要在没有后端协议支持时幻想中段删除还能复用后缀 KV。这才是前缀缓存工程真正难的地方:不是"开一个 cache 参数",而是把 Agent 的上下文、工具、压缩、子任务、路由、遥测全部组织成一个稳定的、可解释的缓存系统。并且借这个点,也告诉大家Agent并不仅仅是一个客户端的纯开发控制哲学,一个具备真正自研深度的产品是需要打通训练、推理、harness agent工程三位一体的。
因为claude code在这个时间上做的复杂度和细节远大于Codex,下一篇我们进入真正进阶模型的claude code的深度讲解和实验环节