大模型推理瓶颈七层分析模型
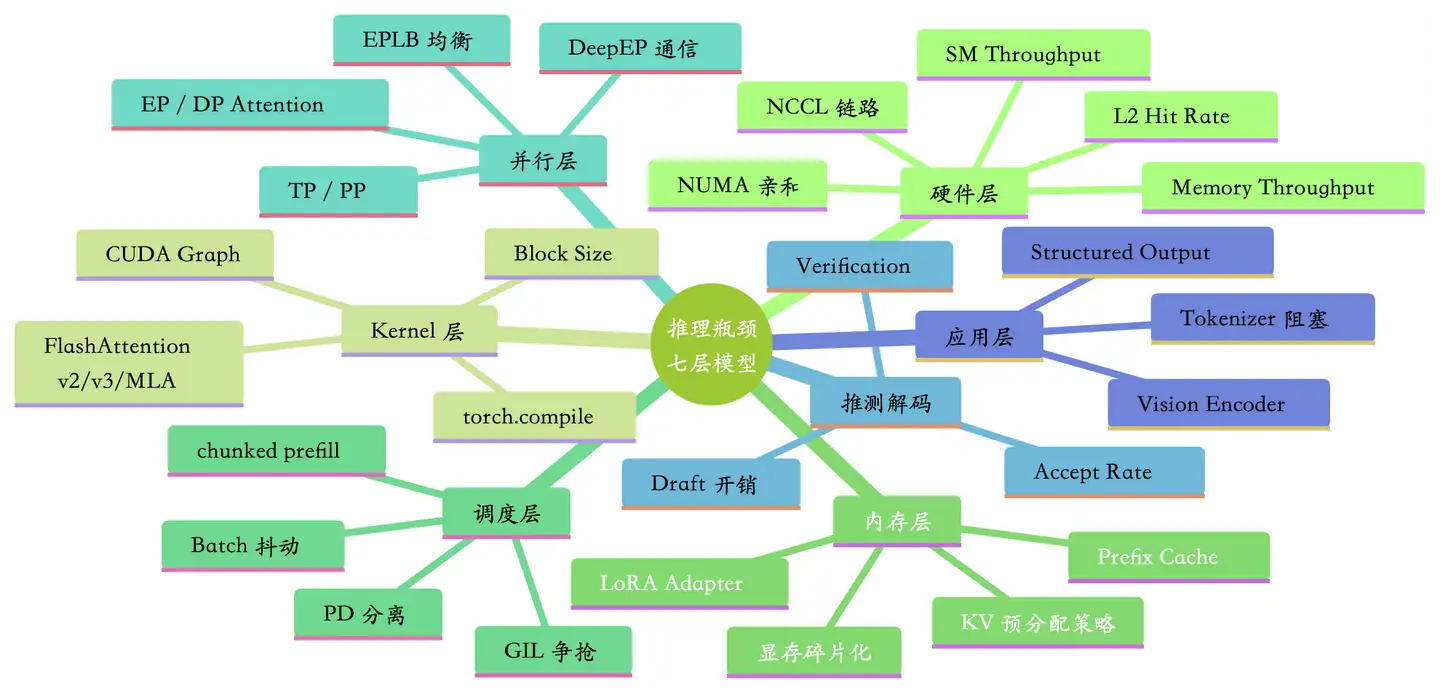
该模型是 LLM 推理优化领域的标准化全链路诊断框架 ,类比计算机网络 OSI 七层模型的设计思想,将端到端推理流程从用户请求入口到硬件物理执行,按抽象层级做了分层解耦。核心价值是解决传统优化中 "头痛医头、脚痛医脚" 的问题,实现自上而下排查、自下而上优化的标准化流程,让工程师可以系统性定位根因、精准落地优化方案。
七层的逻辑顺序严格遵循端到端数据流:应用层 → 调度层 → 推测解码层 → 并行层 → Kernel 层 → 内存层 → 硬件层,上层依赖下层的能力,下层的瓶颈会直接传导到上层。
1. 应用层(Application Layer)
核心定位
推理服务的最上层,是用户请求的入口与出口,聚焦端到端业务逻辑的非模型计算瓶颈,也是最容易被忽略、但优化 ROI 极高的一层。
关键原理
LLM 推理的端到端延迟 = 模型计算延迟 + 业务逻辑处理延迟。绝大多数线上服务的卡顿,并非来自 GPU 模型计算,而是 CPU 侧的业务逻辑阻塞、预处理 / 后处理耗时过高,导致 GPU 空转、利用率长期低下。
核心瓶颈与深度解析
-
Tokenizer 阻塞
分词(文本转 Token ID)、反分词(Token ID 转文本)是纯 CPU 计算任务,无法被 GPU 加速。长文本场景下,单条请求的分词耗时可达数十毫秒,多并发时会出现 CPU 排队,导致请求无法及时送入 GPU,GPU 处于空闲等待状态。
典型场景:32K 以上超长上下文输入、多并发对话场景,Tokenizer 线程池满负荷,成为整个服务的吞吐量瓶颈。
-
Structured Output(结构化输出)
JSON、函数调用等结构化输出,通常通过约束解码、正则匹配、格式校验实现,会在解码的每一步引入额外的 CPU 计算,甚至需要多次调用模型验证格式,大幅增加单 Token 生成延迟。
典型场景:Agent 工具调用、RAG 结构化解析场景,开启结构化输出后,服务吞吐量普遍下降 30% 以上。
-
Vision Encoder(多模态视觉编码器)
多模态大模型中,图像输入需要先经过 Vision Encoder 编码为视觉特征,再送入 LLM 主干。视觉编码器的计算量随图像分辨率、数量线性增长,且通常和文本解码共享 GPU 资源,会抢占显存与算力。
典型场景:多图输入、高清图像解析场景,视觉编码耗时占端到端延迟的 60% 以上,成为核心瓶颈。
工业界工程实践
-
Tokenizer 优化:采用多线程 / 进程池隔离分词任务,使用 FastTokenizer、SentencePiece C++ 版本等高性能分词库;对超长文本做异步预分词,极端场景下将 Tokenizer 部署到独立 CPU 节点,和 GPU 推理节点完全解耦。
-
结构化输出优化:使用基于 CFG(上下文无关文法)的约束解码(如 Outlines、Guidance),替代低效的循环正则校验;将格式校验逻辑后置,仅在生成结束后做一次校验;启用 vLLM、TensorRT-LLM 等推理引擎原生支持的 guided decoding 加速。
-
多模态优化:将 Vision Encoder 和 LLM 主干做部署解耦,用独立的 GPU/TPU 做视觉编码;对图像做降采样、批量编码;缓存高频输入图像的视觉特征,避免重复计算。
典型踩坑场景
把 Tokenizer 和推理逻辑放在同一个 Python 主线程,GIL 锁导致分词和模型推理串行执行,GPU 利用率长期低于 30%;结构化输出用循环调用模型的方式重试校验,导致延迟指数级上升。
2. 调度层(Scheduling Layer)
核心定位
推理服务的 "交通指挥中心",聚焦多用户请求的批处理调度策略,核心目标是在保证延迟 SLA 的前提下,最大化 GPU 利用率与服务吞吐量,是在线推理服务的核心优化层。
关键原理
LLM 推理分为两个算力特性完全不同的阶段,混合调度会导致严重的算力浪费:
-
Prefill(预填充)阶段:一次性处理用户输入的全量上下文,计算密集型,高算力占用、高并行度,耗时随序列长度平方增长。
-
Decode(解码)阶段 :自回归逐 Token 生成,访存密集型,单步计算量小、并行度低,单步耗时基本恒定。
同时,线上请求的到达时间、序列长度、生成长度均为随机值,不合理的调度会导致 Batch 抖动、GPU 空转、长尾延迟飙升。
核心瓶颈与深度解析
-
PD 分离(Prefill & Decode 分离调度)
传统连续批处理(Continuous Batching)会把 Prefill 和 Decode 请求放在同一个 Batch 里执行,Decode 阶段的小计算量会拖慢 Prefill 的大计算量,导致 GPU 算力无法被打满。
典型场景:服务同时存在长文本 Prefill 请求和短文本 Decode 请求,GPU 利用率波动极大,平均低于 40%。
-
Chunked Prefill(分块预填充)
超长上下文的 Prefill 请求(如 128K 上下文)会独占 GPU 数十甚至数百毫秒,导致后续的 Decode 请求被阻塞,出现 "长尾延迟",甚至触发超时。
典型场景:RAG 超长文档输入场景,单条 Prefill 请求导致其他用户的对话生成卡顿,P99 延迟是平均延迟的 10 倍以上。
-
Batch 抖动
线上请求的到达符合泊松分布,请求长度、生成长度随机,会导致 Batch 大小忽大忽小:Batch 太小时 GPU 算力浪费,Batch 太大时单请求延迟超标。
典型场景:低峰期 GPU 利用率极低,高峰期延迟超标,无法平衡吞吐与延迟。
-
GIL 争抢
Python 的 GIL 锁导致多线程无法真正并行,调度线程、预处理线程、推理线程争抢 GIL,导致调度不及时,请求无法及时送入 GPU,GPU 出现周期性空闲间隙。
工业界工程实践
-
PD 分离调度:将 Prefill 和 Decode 请求分为两个独立队列,分配不同的 GPU 时间片,用高优先级小 Batch Decode 队列保证生成流畅度,用低优先级大 Batch Prefill 队列最大化算力利用率,代表方案为 vLLM 的 PD 分离、TGI 预填充调度优化。
-
Chunked Prefill:将超长 Prefill 序列切分为 512/1024/2048 Token 的固定 Chunk,分多步执行,每执行完一个 Chunk 就让出 GPU 资源,处理等待中的 Decode 请求,彻底避免长尾阻塞。
-
Batch 抖动优化:采用动态批处理 + 等待超时机制,设置最小 Batch 大小、最大等待时间,在保证延迟的前提下尽可能凑大 Batch;使用请求回填(Backfill)策略,在 Decode 的间隙插入 Prefill 请求,填充 GPU 空闲时间。
-
GIL 优化:将调度逻辑、预处理逻辑用 C++ 实现(如 vLLM 的 C++ 核心),或用多进程隔离,避免和 Python 推理线程争抢 GIL;使用 Asyncio 异步框架实现非阻塞调度。
典型踩坑场景
盲目增大 Batch 大小,导致单请求延迟超标,同时显存占用过高引发 OOM;未做 Chunked Prefill,超长上下文请求直接打满 GPU,导致服务可用性大幅下降。
3. 推测解码层(Speculative Decoding Layer)
核心定位
针对 LLM 自回归解码固有延迟的加速层,聚焦投机解码的收益与开销平衡,是当前提升生成速度的核心技术之一。
关键原理
LLM 自回归解码的固有缺陷是:每生成一个 Token,都需要做一次完整的模型前向传播,即使 GPU 算力很强,也只能逐 Token 生成,延迟无法被有效降低。
推测解码(投机解码)的核心逻辑是:用一个小的 Draft 模型快速生成 K 个候选 Token,再用目标大模型做一次前向传播,并行验证这 K 个 Token 的正确性,接受所有连续的正确 Token,一次性生成多个 Token,从而减少大模型的前向传播次数,降低端到端延迟。
核心公式:理论加速比 ≈ 1 + 单轮平均接受 Token 数,接受率是决定加速效果的核心指标。
核心瓶颈与深度解析
-
Accept Rate(接受率)
Draft 模型生成的候选 Token,被大模型验证通过的比例。接受率越低,投机解码的收益越小,甚至会出现负优化。
典型场景:代码生成、专业领域推理场景,小 Draft 模型和大模型的分布差异大,接受率低于 30%,加速效果几乎为 0。
-
Draft 开销
Draft 模型的推理耗时是投机解码的固定成本。如果 Draft 模型的推理耗时超过了节省的大模型前向传播耗时,就会出现负优化。
典型场景:Draft 模型选型过大,或 Draft 和大模型共享同一张 GPU,抢占大模型的显存与算力,导致整体延迟上升。
-
Verification(验证过程)
大模型对 Draft 生成的 K 个 Token 的并行验证过程,其实现效率直接影响加速效果。低效的验证会引入额外的计算开销,抵消投机解码的收益。
典型场景:验证过程未做 KV Cache 复用,每次验证都重新计算 KV,导致显存占用飙升,验证耗时过长。
工业界工程实践
-
接受率优化:选用和大模型同架构、同训练语料的小模型作为 Draft 模型(如 Llama-70B 搭配 Llama-7B);采用 Medusa 多头预测层、EAGLE、n-gram 投机解码等无独立 Draft 模型的方案,大幅提升接 受率;根据历史接受率动态调整候选 Token 数 K,自适应平衡收益与开销。
-
Draft 开销优化:将 Draft 模型和大模型部署在不同 GPU 上做流水线并行,避免算力抢占;对 Draft 模型做量化、蒸馏,进一步降低推理延迟;优先采用无 Draft 模型的改进方案,彻底规避额外开销。
-
验证过程优化:优化 KV Cache 复用逻辑,验证时仅增量计算新增 Token 的 KV,而非全量重计算;将 K 个 Token 的验证合并为一次矩阵运算,最大化 GPU 并行度;代表方案为 vLLM 的 Speculative Decoding、TensorRT-LLM 的 Medusa 支持。
典型踩坑场景
盲目开启投机解码,未做接受率测试,在专业领域场景下接受率极低,导致延迟反而上升;Draft 模型和大模型共享同一张 GPU,导致大模型的 Batch 大小被压缩,吞吐量大幅下降。
4. 并行层(Parallelism Layer)
核心定位
70B 以上大规模大模型推理的基础层,聚焦多卡 / 多节点分布式推理的模型切分与通信优化,解决单卡无法放下大模型的问题,同时最大化多卡的线性加速比。
关键原理
大模型参数量超过单卡显存上限时,必须通过分布式并行策略,将模型参数、计算任务切分到多张 GPU 上,协同完成推理。并行策略的核心矛盾是:切分越细,单卡显存占用越低,但通信开销越大,线性加速比越低。优化的核心目标是:在满足显存要求的前提下,最小化通信开销,最大化多卡加速效率。
核心瓶颈与深度解析
-
TP/PP(张量并行 / 流水线并行)
-
张量并行(TP):将模型的权重矩阵按行 / 列切分到多张 GPU,每次计算都需要多卡间通信同步结果,通信开销和序列长度正相关,适合短序列场景。
-
流水线并行(PP):将模型的层按阶段切分到多张 GPU,前向传播时逐层流水线执行,通信开销仅在相邻卡之间,和模型层数正相关,适合长序列、大模型场景。
典型场景:70B 模型用 2 卡 TP 部署,长序列场景下通信耗时占比超过 50%,多卡加速比仅 1.2x,远低于理论值 2x。
-
-
EP/DP Attention(专家并行 / 数据并行)
-
专家并行(EP):针对 MoE 混合专家模型,将不同的 Expert 层切分到不同的 GPU,仅路由到对应 Expert 的 Token 需要通信,是 MoE 模型的核心并行策略。
-
数据并行(DP):将完整的模型复制到多张 GPU,不同的请求 Batch 分到不同的卡,无模型通信开销,仅需最后同步结果,适合小模型、高吞吐场景。
典型场景:MoE 模型的 Expert 路由不均匀,部分卡的 Expert 负载过高,其他卡空闲,出现 "木桶效应",整体吞吐量上不去。
-
-
EPLB 均衡(专家并行负载均衡)
MoE 模型中,Token 的路由由门控网络决定,若大量 Token 被路由到少数几个 Expert,会导致这些 Expert 所在的 GPU 成为瓶颈,其他 GPU 算力浪费。
典型场景:通用语料推理时,门控网络集中路由到通用领域的 Expert,专业领域的 Expert 几乎无负载,GPU 利用率差异超过 80%。
-
DeepEP 通信
MoE 模型的专家并行中,Token 的路由需要跨卡的 All-to-All 通信,传统的 NCCL All-to-All 开销极高,是 MoE 推理的核心通信瓶颈。
典型场景:16 卡 EP 部署的 MoE 模型,通信耗时占推理总耗时的 60% 以上,成为核心瓶颈。
工业界工程实践
-
并行策略选型最佳实践:
-
7B/13B 模型:单卡可部署,优先用 DP 提升吞吐量,无需 TP/PP;
-
34B/70B 模型:2-8 卡部署,优先用 PP+TP 混合并行,长序列场景优先 PP,短序列高吞吐场景优先 TP;
-
175B 以上 / MoE 模型:多节点部署,EP+TP+PP 三维并行,优先保证 Expert 的负载均衡。
-
-
通信优化:采用 NCCL、HCCL 等高性能通信库,开启 GPUDirect RDMA,降低跨卡 / 跨节点通信延迟;MoE 场景使用 DeepEP、FastMoE 等专用通信库,优化 All-to-All 通信开销;实现通信和计算重叠,在模型前向计算的同时发起下一层的通信,隐藏通信延迟。
-
负载均衡优化:MoE 模型推理时,采用辅助门控损失、Token 路由均衡策略,避免 Expert 集中负载;动态调整 Expert 的分配,将高负载的 Expert 拆分到多卡,低负载的 Expert 合并到单卡;代表方案为 DeepSpeed-MoE、Megatron-LM 分布式并行优化。
典型踩坑场景
盲目使用高维度 TP,如 70B 模型用 8 卡 TP,导致通信开销远大于计算开销,多卡加速比极低;MoE 模型未做负载均衡优化,Expert 负载不均,导致多卡部署的吞吐量甚至低于单卡。
5. Kernel 层(Kernel Layer)
核心定位
GPU 计算的核心执行层,聚焦CUDA 算子的实现与优化,是软件栈中离硬件最近的一层,决定了 GPU 算力的实际利用率(FLOPS 利用率)。
关键原理
LLM 推理的所有计算,最终都会转化为 GPU 上的 CUDA Kernel 函数执行。算子的实现效率,直接决定了 GPU 的理论算力能被发挥多少。大模型推理的核心算子是矩阵乘法(GEMM)、Attention 算子、LayerNorm、激活函数等,其中 Attention 和 GEMM 占了 90% 以上的计算耗时。
核心瓶颈与深度解析
-
FlashAttention v2/v3/MLA
传统的 Attention 算子实现,需要将 Q、K、V、Softmax 结果、Attention 输出全部写入显存,带来极大的显存带宽占用,是推理的核心访存瓶颈。
FlashAttention 的核心逻辑是:通过 IO 感知的分块计算(Tiling),将计算拆分为多个小块,所有中间结果都保存在 GPU 的 SRAM 中,仅在计算结束后写入显存,大幅减少显存 IO 次数,同时降低显存占用,提升计算速度。v2 优化了非对称序列长度的分块策略,v3 针对 Hopper 架构的 Tensor Core 做了优化,MLA/GQA 进一步减少了 K/V 的访存量。
典型场景:长上下文推理场景,未使用 FlashAttention 的 Attention 算子耗时占比超过 70%,显存占用极高,OOM 频发。
-
CUDA Graph
传统的 PyTorch eager 模式下,每个算子都需要 CPU 向 GPU 发起一次调度,单次调度开销几微秒到几十微秒。LLM 解码阶段,单步前向传播有数百个算子,累计的调度开销可达数毫秒,占解码延迟的 30% 以上。
CUDA Graph 的核心逻辑是:将一整轮前向传播的算子序列,捕获为一个静态的计算图,一次性提交给 GPU 执行,仅需一次 CPU 调度,大幅减少调度开销。
典型场景:小 Batch 解码场景,CPU 调度开销占比超过 40%,GPU 利用率低。
-
Block Size(算子分块大小)
CUDA 算子的执行,是按 Block 为单位调度到 SM 上的。Block 大小(每个 Block 的线程数)直接决定了 SM 的占用率、缓存命中率、并行度。Block 大小不合适,会导致 SM 的算力无法被充分利用。
典型场景:算子的 Block 大小设置为 128,而 GPU 的 SM 最佳占用率需要 256 线程,导致 SM 占用率低于 50%,算力浪费。
-
torch.compile
PyTorch 2.0 推出的即时编译(JIT)工具,通过 TorchInductor 将 PyTorch 模型编译为优化后的 CUDA Kernel,自动做算子融合、循环展开、向量化等优化,减少访存开销,提升执行效率。
典型场景:自定义算子、小众模型结构,没有手工优化的 CUDA Kernel,eager 模式下执行效率极低。
工业界工程实践
-
Attention 算子优化:全场景启用 FlashAttention v2/v3,针对 MLA/GQA 做适配,长上下文场景必须开启;结合 PagedAttention(分页 Attention),进一步提升显存利用率与计算效率;代表方案为 FlashAttention 官方实现、vLLM 的 PagedAttention。
-
调度开销优化:解码阶段全量启用 CUDA Graph,对固定 Batch 大小、固定序列长度的计算图做预捕获与复用;针对动态 Batch 场景,使用多 CUDA Graph 池,预捕获不同 Batch 大小的计算图,避免运行时重新捕获;通过算子融合,将多个小算子(如 LayerNorm + 激活函数、MatMul+Bias)融合为一个大 Kernel,减少 Kernel 启动次数与访存开销。
-
算子编译优化:对自定义模型、无手工优化 Kernel 的模型,使用 torch.compile 开启全图编译,设置 inductor 后端,针对 GPU 架构做优化;对核心算子,使用 CUTLASS 实现的手工优化 GEMM 算子,针对 Tensor Core 做极致优化;针对不同 GPU 架构(Ampere/Hopper/Ada),做针对性编译,开启对应的指令集优化。
典型踩坑场景
未开启 FlashAttention,使用 PyTorch 原生的 Attention 实现,长序列场景下延迟极高,显存占用超标;盲目使用 CUDA Graph,对动态序列长度、动态 Batch 的场景频繁重新捕获计算图,导致额外开销,反而降低了性能0。
6. 内存层(Memory Layer)
核心定位
LLM 推理的 "生命线",聚焦显存的分配、复用、管理策略,核心解决 "显存不足" 和 "访存低效" 两大核心问题,是决定推理服务最大并发、最大上下文长度的关键层。
关键原理
LLM 推理的显存占用分为两大部分:
-
模型权重显存:固定占用,和模型参数量、量化精度正相关(如 70B FP16 模型需要 140GB 显存);
-
动态显存:随并发数、序列长度线性增长,核心是 KV Cache 显存,占动态显存的 90% 以上。
大模型推理的核心矛盾是:KV Cache 的显存占用,是限制服务并发数与上下文长度的核心瓶颈。同时,频繁的显存分配 / 释放会导致显存碎片化,进一步降低显存利用率,引发 OOM。
核心瓶颈与深度解析
-
KV 预分配策略
传统的推理实现中,KV Cache 是随 Token 生成动态分配的,每生成一个 Token,就申请一次显存。频繁的动态分配会带来显存开销,同时导致显存碎片化。
典型场景:高并发长序列场景,频繁的显存分配导致显存碎片化,明明还有 20% 的空闲显存,却出现 OOM。
-
Prefix Cache(前缀缓存)
很多场景下,用户的请求有大量重复的前缀上下文,如 RAG 的系统提示词、相同的文档上下文、多轮对话的历史消息。传统实现中,每次请求都会重新计算并存储这些前缀的 KV Cache,造成显存与算力的双重浪费。
典型场景:RAG 服务,所有用户的请求都带有相同的系统提示词和检索到的文档,重复计算前缀 KV,导致显存占用翻倍,吞吐量下降 50%。
-
显存碎片化
GPU 显存的分配是以块为单位的,频繁的申请和释放不同大小的显存块,会导致显存中出现大量不连续的空闲块,这些空闲块无法被分配给大的连续显存请求,最终导致显存利用率低下,引发 OOM。
典型场景:服务运行一段时间后,并发能力越来越差,最终出现 OOM,重启服务后恢复正常,就是典型的显存碎片化问题。
-
LoRA Adapter
LoRA 微调的模型,推理时需要加载多个 LoRA Adapter 权重,每个 Adapter 都需要占用额外的显存,同时切换 Adapter 会带来额外的开销,影响服务的并发与延迟。
典型场景:多租户的 LoRA 推理服务,同时加载数十个 LoRA Adapter,显存被大量占用,无法支撑高并发。
工业界工程实践
-
KV Cache 管理优化:采用分页式 KV Cache(PagedAttention),借鉴操作系统的虚拟内存管理,将 KV Cache 按固定大小的页块分配,逻辑连续的 KV Cache 可以存放在物理不连续的显存页中,彻底解决显存碎片化问题,显存利用率提升 3-5 倍;使用显存池(Memory Pool),提前为每个请求预分配最大生成长度的 KV Cache 显存,复用已释放的显存块,避免运行时动态分配的开销。
-
缓存复用优化:开启 Prefix Cache,对重复的前缀上下文实现 KV Cache 的全局复用,仅计算一次前缀 KV,所有请求都可以复用,支持自动前缀匹配、LRU 缓存淘汰策略;多轮对话中,仅增量计算新增的对话内容的 KV,复用历史对话的 KV Cache,避免全量重计算;代表方案为 vLLM 的 Automatic Prefix Caching。
-
显存碎片化治理:使用显存池统一管理显存的申请与释放,避免频繁的 cudaMalloc/cudaFree;采用分页式显存管理,彻底解决连续显存分配的问题;定期做显存碎片整理,合并空闲的显存块。
-
LoRA 推理优化:实现 LoRA 权重的动态加载与卸载,将不活跃的 LoRA 权重卸载到 CPU 内存,仅在使用时加载到 GPU 显存;采用 LoRA 算子融合,将 LoRA 的计算和主干模型的矩阵乘法融合,减少算子开销。
典型踩坑场景
未做 KV Cache 的复用,多轮对话每次都全量重计算,导致长对话场景延迟越来越高,显存占用越来越大;动态分配 KV Cache,导致服务运行一段时间后出现显存碎片化,频繁 OOM。
7. 硬件层(Hardware Layer)
核心定位
推理性能的 "天花板",聚焦底层硬件的物理性能与资源利用,决定了推理服务的理论性能上限,所有上层的优化都无法突破硬件的物理限制。
关键原理
LLM 推理的性能,最终由硬件的两大核心指标决定:
-
算力(FLOPS):GPU 的计算能力,决定了 Prefill 阶段的最大速度;
-
显存带宽(Memory Bandwidth):GPU 的显存读写速度,决定了 Decode 阶段的最大速度(Decode 阶段是访存密集型,算力利用率通常低于 20%)。
同时,多卡间的通信链路、CPU 与内存的性能,也会直接影响推理服务的整体性能。
核心瓶颈与深度解析
-
Memory Throughput(显存带宽)
LLM 解码阶段,每生成一个 Token,都需要从显存中读取完整的模型权重,权重的读取量 = 模型参数量 × 量化精度。如果显存带宽不足,权重读取的耗时会成为解码延迟的核心瓶颈。
理论公式:单 Token 解码延迟下限 ≈ (模型参数量 × 量化精度) / 显存带宽。例如:70B INT4 模型,权重大小 35GB,A100 的显存带宽 1.6TB/s,理论下限约 21.875ms/Token。
典型场景:低 Batch 解码场景,显存带宽利用率超过 90%,算力利用率低于 20%,完全被显存带宽瓶颈限制。
-
SM Throughput(SM 吞吐量)
GPU 的流多处理器(SM)是实际执行计算的单元,SM 的数量、频率、Tensor Core 的性能,决定了 GPU 的理论算力上限。Prefill 阶段是计算密集型,性能完全由 SM 的吞吐量决定。
典型场景:长序列 Prefill 场景,SM 利用率超过 90%,显存带宽利用率低,完全被算力瓶颈限制。
-
L2 Hit Rate(二级缓存命中率)
GPU 的 L2 缓存位于 SM 和显存之间,读写速度比显存快一个数量级。如果算子的实现能让数据尽可能命中 L2 缓存,就能大幅减少显存 IO,提升执行速度。
典型场景:算子分块策略不合理,导致 L2 缓存命中率低于 30%,频繁访问显存,算子执行效率极低。
-
NCCL 链路
多卡分布式推理时,卡间通信的带宽与延迟,直接决定了并行策略的效率。NVLink 的带宽远高于 PCIe,是多卡并行的核心硬件基础。
典型场景:多卡部署时,卡间仅用 PCIe 4.0 x16 连接,带宽 32GB/s,远低于 NVLink 的 600GB/s,通信耗时占比超过 50%,多卡加速比极低。
-
NUMA 亲和
多 CPU 节点的服务器中,每个 CPU 对应一个 NUMA 节点,有独立的内存和 PCIe 通道。如果 GPU 绑定到了错误的 NUMA 节点,CPU 访问 GPU 的延迟会大幅上升,导致调度开销、数据传输开销增加。
典型场景:CPU 和 GPU 的 NUMA 绑定错误,导致 PCIe 传输延迟翻倍,CPU 调度开销大幅上升,GPU 利用率出现周期性空闲。
工业界工程实践
-
硬件选型最佳实践:高吞吐在线推理场景,优先选择高显存带宽的 GPU(如 H100 3.35TB/s、A100 1.6TB/s),解码速度和显存带宽正相关;长上下文 Prefill 场景,优先选择高算力、多 SM 的 GPU;多卡部署场景,必须选择带 NVLink 的机型,优先保证卡间通信带宽,避免 PCIe 瓶颈。
-
硬件性能优化:算子优化时,通过合理的分块策略、数据复用,优先提升 L2 缓存命中率;开启 GPU 的 Boost 模式,保证 SM 的频率稳定在最高值,避免降频导致的性能波动;针对 GPU 架构做针对性优化,如 Hopper 架构开启 FP8 张量核心加速,Ampere 架构开启 TF32 加速。
-
通信与 CPU 优化:多卡部署时,开启 GPUDirect RDMA,优化 NCCL 通信参数,设置正确的 NCCL 拓扑,最大化通信带宽;做 NUMA 亲和性绑定,将 GPU 对应的 PCIe 通道绑定到对应的 NUMA 节点,将推理进程、预处理进程绑定到对应的 CPU 核心,避免跨 NUMA 访问;高并发场景下,使用高性能的 CPU 与大带宽内存,避免 CPU 侧成为瓶颈。
典型踩坑场景
多卡部署时,未开启 NVLink,仅用 PCIe 通信,导致多卡加速比极低;未做 NUMA 绑定,CPU 和 GPU 跨 NUMA 节点访问,导致数据传输延迟大幅上升,GPU 利用率低下。
七层模型的核心价值与标准化优化流程
核心价值
-
分层解耦,避免优化盲区:将推理全链路拆分为独立的层级,每个层级的瓶颈权责清晰,不会出现 "只优化底层算子,却忽略上层应用层 Tokenizer 阻塞" 的无效优化。
-
标准化排查路径:提供了自上而下的排查思路,优先优化 ROI 高的上层(应用层、调度层),再深入底层(Kernel、硬件层),避免过早陷入底层细节优化,浪费人力。
-
全链路性能评估:可以基于这个模型,构建全链路的性能监控体系,每个层级设置对应的监控指标,快速定位瓶颈根因。
标准化优化流程(自上而下)
-
第一步:应用层排查:监控端到端延迟中预处理 / 后处理的耗时占比,解决 Tokenizer 阻塞、结构化输出开销、视觉编码瓶颈,保证 GPU 不会因为 CPU 侧业务逻辑空闲。
-
第二步:调度层优化:优化请求的批处理调度策略,开启 PD 分离、Chunked Prefill,解决 Batch 抖动问题,提升 GPU 的平均利用率,保证延迟 SLA。
-
第三步:推测解码层评估:根据业务场景,评估投机解码的收益,选择合适的方案,提升生成速度,避免负优化。
-
第四步:并行层选型:针对模型规模,选择最优的分布式并行策略,最小化通信开销,最大化多卡加速比。
-
第五步:内存层治理:优化 KV Cache 管理,开启分页 KV、前缀缓存,解决显存碎片化问题,最大化显存利用率,提升服务并发数。
-
第六步:Kernel 层极致优化:开启 FlashAttention、CUDA Graph、算子融合,提升算子执行效率,最大化 GPU 的 FLOPS 利用率。
-
第七步:硬件层瓶颈突破:基于硬件的理论上限,评估优化的空间,若上层优化已经达到硬件上限,升级硬件配置。