一个独立开发者,靠一份 markdown 驱动 Claude Code, 用 20 天跑通 9 个包的 monorepo 工程
当 AI 编程从"自动补全"变成"自主写代码",独立开发者真正缺的不是 AI 的能力,而是约束 AI 的方法。 这篇文章想分享我用一份 markdown skill + Claude Code 跑出来的一个完整工程案例,以及我踩出来的方法论:SDD(Spec-Driven Development)。
一、写在前面:我为什么要写这个项目
先把结论说在前面:这是一个反产品的项目。
我做了一个叫 smile-design 的 AI 设计工程智能体------面向前端工程师、UI 设计师和产品经理,能 BYOP(Bring Your Own Project)接入用户已有的 vite 项目,做设计系统切换、DOM 精修、审美检查、生成可运行的前端工程......听起来像是要冲 v0、Pencil、Replit、Claude Design 一波的样子。
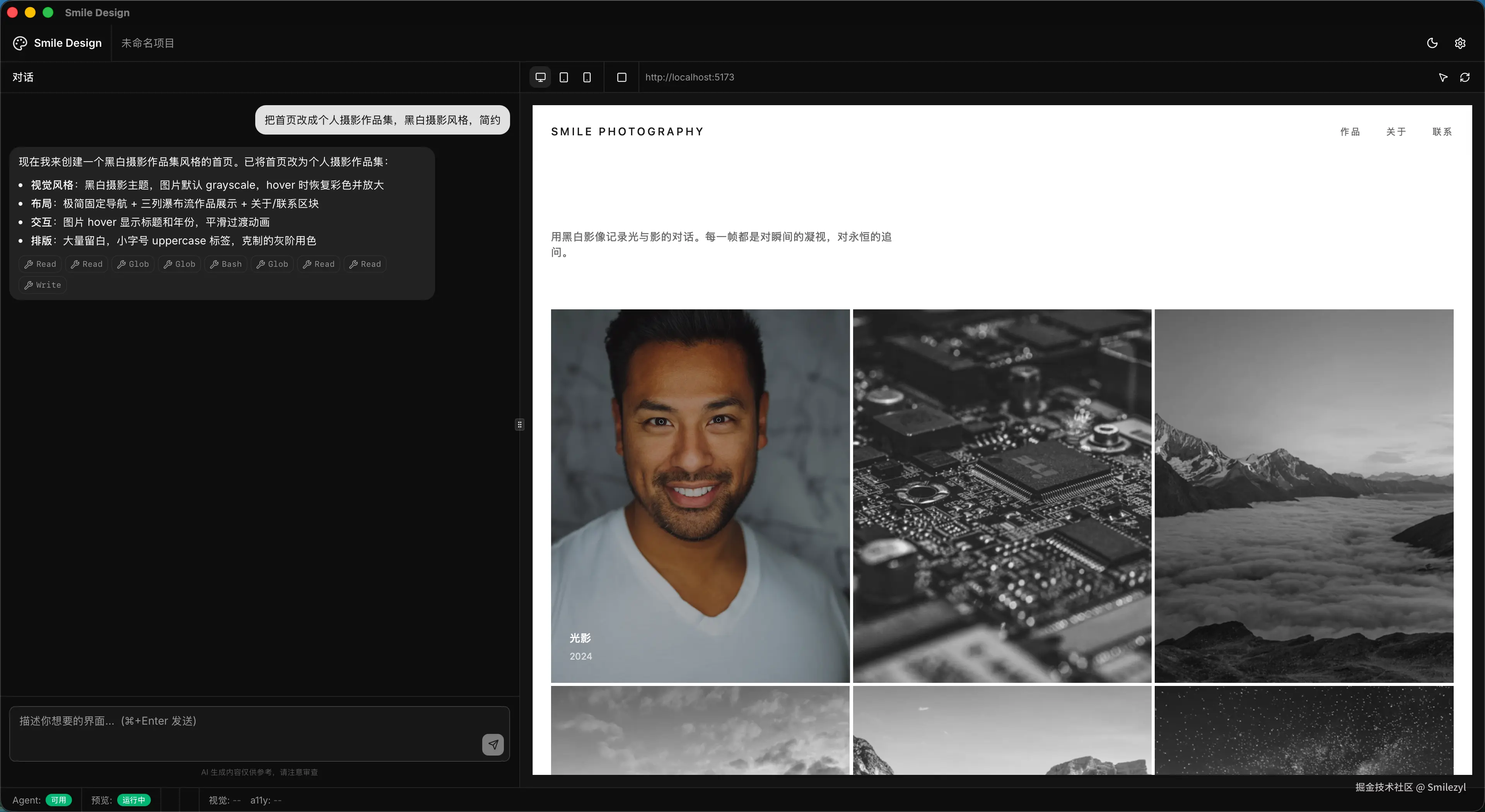
但它的真实目的,不是和这些产品竞争,我也知道那样做也是自不量力的。
它真正想交付的,是 specs/ + memory/ + PROGRESS.md 三件套------一个独立开发者用 AI 编程跑通中等规模工程的全流程开源现场。产品功能本身只是案例载体。
为什么要做这种"反产品"的项目?因为我自己被一个问题困扰了很久:
AI 编程的能力上限早已超过独立开发者能驾驭的程度,但绝大多数独立开发者用 AI 写代码,最终都死在了"上下文遗忘"和"决策无沉淀"上。另外就是在实际企业大型复杂项目的开发中该如何应用 SDD(规范驱动开发),尤其是那些老旧项目又该如何融入 AI 编程的工作流。相信这是很多开发者和企业都在思考和实践的真实场景问题。如果你的项目非常重要,例如金融或者大型生产制造系统,你还信任 AI 生成的代码吗?
你也一定见过这种场景:早上 9 点和 AI 一起设计了一个非常优雅的架构,下午 3 点新开会话改一个 bug,AI 完全不记得早上的决策,给你写出一坨完全相反的实现。一个月后回来读自己的代码,看到一段奇怪的 if-else,问 AI"为什么这么写",AI 说"我建议把它简化一下"------然后把当初为了绕过某个第三方 SDK 坑写的关键防护代码删了。
这不是 AI 的问题。是工作流的问题。
我想把这个工作流问题彻底搞清楚,所以我做了 smile-design。它的产品功能可能永远不会上架,但它的 spec、它的 memory、它的 PROGRESS,全部公开摆在那里,给任何想搞清楚"AI 编程在真实工程里到底怎么用"的人当参考。
二、什么是 SDD:把"想清楚再写"变成可执行约束
SDD 全称 Spec-Driven Development------规范驱动开发。这个词不是我发明的,GitHub Spec Kit、Anthropic 内部的 SDD 实践都在用。但落到独立开发者 + AI 的场景里,有一个非常微妙但关键的区别:
传统 SDD 是"写规范给人看",AI 时代的 SDD 是"写规范给 AI 看"。
这两件事的输入要求和输出形态完全不同:
-
给人看的规范,可以模糊、可以省略、可以"心领神会"
-
给 AI 看的规范,必须可执行、可验证、可追溯------否则 AI 会用它无穷的幻觉来填充你留下的所有空白
所以 SDD 在 AI 时代的真正定义是:把每一个工程决策(WHY、WHAT、HOW、验收标准、边界条件、约束)写成一份结构化的 markdown,作为 AI 写代码的唯一真理来源。
这份 markdown 在
smile-design里长这样(节选自specs/下任意一个 sprint 文件):
ini
## 目标(WHY)
一句话:解决什么问题,对谁有价值。
## 功能描述(WHAT)
### 用户故事
- 作为 [角色],我想 [操作],以便 [价值]
### 验收标准(Given/When/Then)
- Given: [前置] / When: [操作] / Then: [预期结果]
### 边界条件
- [条件]:[处理方式]
## 技术方案(HOW)
### 文件变更计划
| 操作 | 路径 | 说明 |
## 任务分解(TASKS)
- [ ] T-x.x.1 ...注意里面那条核心原则------验收标准必须用 Given/When/Then 描述,不能是"系统正常工作"这种模糊话。这条规则的存在不是为了仪式感,而是因为:AI 看到模糊的验收标准,会自动用它的幻觉填空,然后给你写一段它觉得"应该正常工作"的代码。
三、三源同步:解决"AI 写得越多,上下文越散"
光有 spec 还不够。一个中等规模工程会有几十个 sprint、上百个任务,光靠 spec 文件,AI 依然会陷入"翻不完所有 spec"的上下文爆炸。
所以 SDD 在 smile-design 里固化成了三源同步------三个文件源,各管一摊:
| 文件 | 内容 | 写入时机 |
|---|---|---|
PROGRESS.md |
任务进度状态([ ] 待办 / [🔄] 进行 / [⏸️] 等验证 / [✅] 完成) |
每次任务推进 |
specs/<feature>.md |
任务的 WHY/WHAT/HOW + 验收 + 边界 | Spec 阶段创建,实现中可更新 |
MEMORY.md + memory/<category>/*.md |
跨任务的经验积累------决策、坑、约定、第三方集成细节 | 触发条件命中时写入 |
每一种文件都有非常严格的"什么不该写"约束:
-
PROGRESS.md不写实现细节(只写状态) -
specs/不写跨任务经验(只写本任务的方案和验收) -
memory/不写任务进度(只写"踩过的坑 + 做过的非显而易见取舍")这种切分让每一份文件都能保持薄、可读、可懒加载。AI 启动一个新任务时,只需要:
-
读
PROGRESS.md找到下一个[ ]任务 -
读对应的
specs/<feature>.md了解方案 -
扫
MEMORY.md滚动窗口(最近 20 条索引) -
按任务关键字命中
memory/<cat>/*.md详情整个上下文加载在几千 token 之内,不会被海量历史决策挤爆。
更关键的是------每个任务结束时,AI 必须强制做"三向同步" :把 PROGRESS 状态改完成、把 spec 任务勾选 x、把新发现的决策/坑/约定 draft 到 memory 里。一个都不能少。
这条规则是 SDD 在独立开发者场景下最有杠杆的一条。它把"经验沉淀"从一件靠自觉的事变成了流程必经环节。
四、Phase A→B→C→D:把 AI 编程的随机性关进笼子里
光有"应该写什么文件"还不够。smile-design 项目里每一个任务的执行流程,被严格切成了四个 Phase,禁止跳步:
ini
Phase A --- 任务开始
读 PROGRESS.md → 找下一个 [ ] 任务
读 specs/<sprint>.md → 了解 WHY/WHAT/HOW + 验收
读 MEMORY.md + 命中的 memory/<cat>/*.md → 加载历史决策
Phase B --- 任务进行中
PROGRESS 状态 → [🔄]
按 spec 实现;spec 有缺陷先更新 spec
新决策 / 新坑 → 暂停实现,先草稿到 memory/
Phase C --- 任务完成等待验证
输出验证清单(需求驱动,不是读实现反推)
PROGRESS 状态 → [⏸️],停下等用户测试
Phase D --- 测试通过三向同步
PROGRESS → [✅]
spec - [ ] → - [x],更新元数据
memory:draft 定稿 → 索引追加 → 推翻处理这四个 Phase 看起来很官僚,但每一条都是踩着血出来的:
Phase A 的强制读取------为什么必须读三件套?因为我试过不读。AI 在不知道历史决策的情况下,三天里把一个早就拍板"不自建 Agent Loop"的项目,重新长出了一个 LangChain 集成层。读上下文不是仪式,是防 AI 幻觉的必经之路。
Phase B 的"先更新 spec 再继续" ------为什么实现中发现 spec 有缺陷,要先回头改 spec?因为如果你直接改代码,spec 就和代码失同步了。下一次 AI 读 spec 时,它会按错的方案去做后续任务,形成雪崩式偏差。Spec 是真理来源,代码不是。Debug Spec, not Code。
Phase C 的"需求驱动验证" ------这是我反复踩过的最大的坑。AI 写完代码后,如果你让它自己写测试,它会读自己写的实现,然后写出"这段代码确实按它写的方式运行"的测试。听起来对,实际上完全没用------测试只验证了"代码按 AI 想的方式运行",没验证"代码是否满足用户需求"。
正确的姿势是:闭眼想"用户拿到这个功能会怎么用 / 会踩哪些边界 / 错误怎么恢复",先把验证清单列出来,再对照实现查漏。 不是反过来。
这条规则在 SDD skill 里被写成"反作弊"原则,是整个方法论里最反直觉、但最有效的一条。
Phase D 的"暂停等待人工" ------AI 不能自己宣布任务完成。必须用户手动测试通过、回复"测试通过"四个字,才进入三向同步。这条规则把"人在环中"从一句口号变成了流程红线。
五、为什么是一份 markdown skill:可读、可改、可 fork
我一开始想过把这套方法论做成一个 SaaS 产品、一个 IDE 插件、一个独立 CLI------后来发现都不对。
最终的形态非常朴素:一份 markdown 文件,800 多行,叫 SKILL.md,放进 ~/.claude/skills/spec/ 就能用。
它是 Claude Code 的 skill 机制------一种"用 markdown 教 AI 怎么干活"的协议。把 SKILL.md 拷过去,在 Claude Code 里输入 /spec 我想做一个 X 功能,整套 Phase A→D 流程就跑起来了。
为什么是 markdown?因为:
-
AI 看得懂:markdown 是 Claude 训练数据里浓度最高的格式之一,AI 能严格遵循里面的指令
-
人也看得懂 :你可以打开
SKILL.md一行一行读它在让 AI 做什么,没有黑盒 -
可以 fork:不喜欢"三源同步"想换"两源"?打开文件改就行。不需要等我发版本
-
零依赖:没有运行时、没有服务、没有订阅、没有 API key------就是一个文件
-
演进可追溯 :我把 0.0.1 / 0.0.2 / 0.0.3 三版历史 SKILL 一起开源(
smilezyl2023/smile-spec),任何人都能看到这套方法论是怎么一版版长出来的整个
smile-design项目(9 个 packages、14 个 MCP tools、Tauri 桌面壳、npm 多包发布、DMG 分发)从 Phase 0 第一行代码到 Phase 6 npm 发布闭环,全程由这一份 800 行的 markdown 驱动 Claude Code 跑出来。
六、给独立开发者的几条具体建议
如果你正在用 AI 编程做一个有点规模的项目,有几条建议(都是我自己踩出来的):
1. 先建立"真理来源",再开始写代码
不管你用 SDD 还是别的什么方法论,开工前一定要回答清楚:当 AI 和你(或两次 AI 自己)记忆冲突时,以什么文件为准?
这个文件最好不是聊天记录、不是脑子里、不是 README------它必须是结构化的、可被 AI 加载的、有版本控制的。
smile-design 的答案是 specs/<feature>.md。你的项目可以是别的,但必须有这个文件。
2. 给 AI 写"什么不能做"比"什么要做"更重要
我在 CLAUDE.md 里有一段叫"禁止依赖"的清单:LangChain/LangGraph、Electron、Jest、Vercel AI SDK、Ink CLI......每一条背后都是踩过的坑。
AI 默认会去抓"最热门"的方案。但热门方案不一定适合你的项目。把"不能做"的边界明确写出来,AI 才不会反复给你引荐"业界标准实践"。
3. 把"经验沉淀"做成流程必经环节,不要靠自觉
memory/ 这个目录在我项目里最有价值的不是任何单条记录,而是它的存在本身让 AI 不能再"假装没看到坑" 。每个任务结束时,AI 必须问自己"这次发现了新决策/新坑/新约定吗?"------这个问题被强制问出来,沉淀就发生了。
如果你不强制,沉淀永远不会自然发生。
4. 强制人在环中
AI 不能自己宣布完成。每个任务必须人工测试一遍,回复"测试通过"才能合并。
这条会显著拉慢速度。但它是独立开发者唯一能在 AI 大量自主写代码的情况下保持"我还在掌控这个项目"的方式。
如果你做的是一个长期维护的项目,这点慢是值得的。
5. 把方法论开源出来
我一开始没想开源 SKILL.md,觉得"自己用就好了"。后来发现,开源带来的最大好处不是别人帮我改,而是:当我知道"这个文件别人会读",我会被迫把它写得更清晰、更自洽、更经得起推敲。
写文档给别人看,会反向倒逼你把方法论本身打磨得更好。这是一个我没预料到的副作用。
七、最后
这个项目想表达的核心观点其实只有一句: AI 编程时代,独立开发者真正稀缺的不是 AI 的能力,而是约束 AI 的方法论。
smile-design 是一份现场记录,smile-spec 是这份记录所依赖的方法论。两个 repo 都开源在 GitHub 上,欢迎任何想搞清楚"AI 编程在真实工程里到底怎么用"的同行翻一翻。
-
方法论 skill:
github.com/smilezyl2023/smile-spec如果这套方法论对你有帮助,给两个 repo 点个 star 就是对一个独立开发者最大的鼓励。
如果你不同意里面的任何一条,欢迎在 issue 里和我吵架------我相信任何方法论都需要被反复挑战才能变得更好。