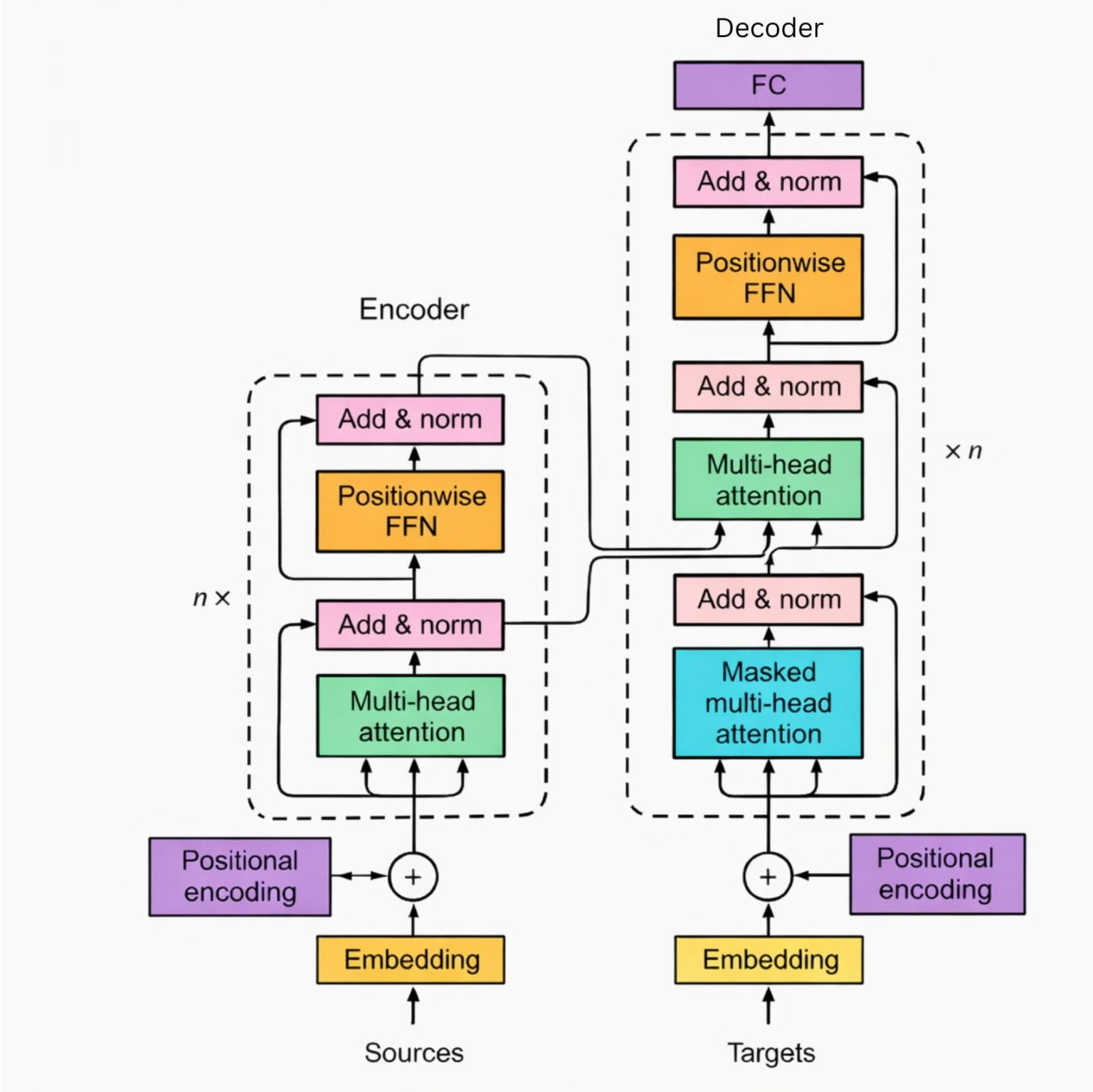
Transformer 编码器堆叠的 Encoder 层之间,和多头注意力模块内部各独立单注意力头之间,在 QKV 上处理的区别
flyfish
以Encoder 举例
从属关系
1 个 Encoder 层 = 包含 1 个多头注意力模块
1 个多头注意力模块 = 包含 8 个独立的单注意力头
很多个 Encoder 层 上下堆叠,就是 Transformer 编码器
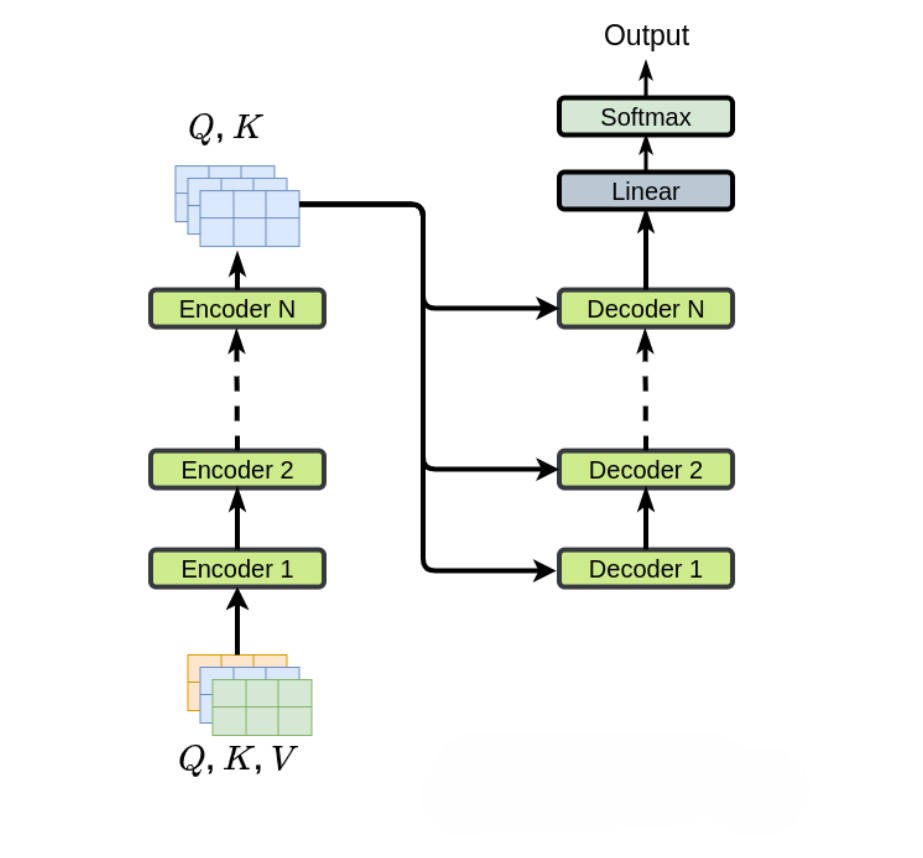
Encoder 层堆起来 = Transformer 整个编码器,Encoder层、也可以叫 Encoder Block 。
一个 Encoder 层 内部,自带一整个「多头注意力」,包含好多个注意力头(标准8个头)。
层级从属关系
从小到大:
- 单个注意力头 (头1、头2 ... 头8)
↓ - 8个小头合在一起 = 一个多头注意力模块 MHA
↓ - 一个多头注意力 + 残差归一化 + FFN前馈网络 = 一个完整 Encoder 层
↓ - 6个 Encoder 层堆起来 = Transformer 整个编码器
维度一:层与层之间(第1层 Encoder、第2层 Encoder、第3层......)
1. 指代对象
上下堆叠的每一个完整 Encoder 层
比如:第1层、第2层、第3层 ...... 第6层
2. 输入关系(串行)
第1层输入:词嵌入+位置编码
第2层输入:必须是第1层整个 Encoder 层算完的输出
第3层输入:必须是第2层算完的输出
层和层是严格串行,不能并行,后一层依赖前一层结果。
3. QKV 权重关系
每一层 Encoder 都有自己 独立、专属、不共享 的一套 Wq、Wk、WvW_q、W_k、W_vWq、Wk、Wv
第1层:有自己的 Wq1,Wk1,Wv1W_{q1},W_{k1},W_{v1}Wq1,Wk1,Wv1
第2层:有另一套完全不一样的 Wq2,Wk2,Wv2W_{q2},W_{k2},W_{v2}Wq2,Wk2,Wv2
互相参数不共用、不通用、不复用
4. QKV 生成规则
每一层用上一层传下来的特征 X
用自己专属的 Wq,Wk,WvW_q,W_k,W_vWq,Wk,Wv
重新做一次全新线性投影 ,生成属于本层独有的一份全局 QKV
每层自己造自己的 QKV,和别的层毫无关系。
维度二:同一层内部 各个注意力头之间(同层里 头1、头2 ...... 头8)
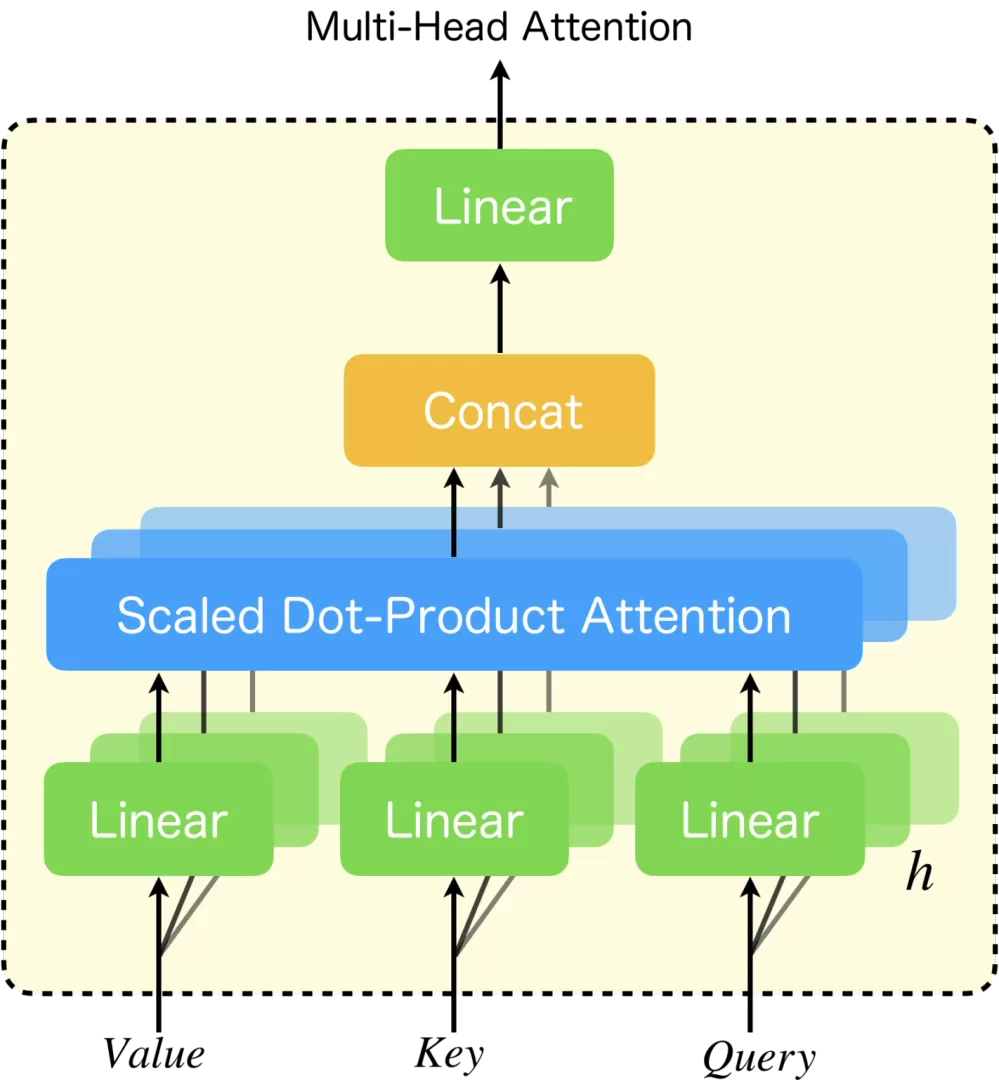
展开画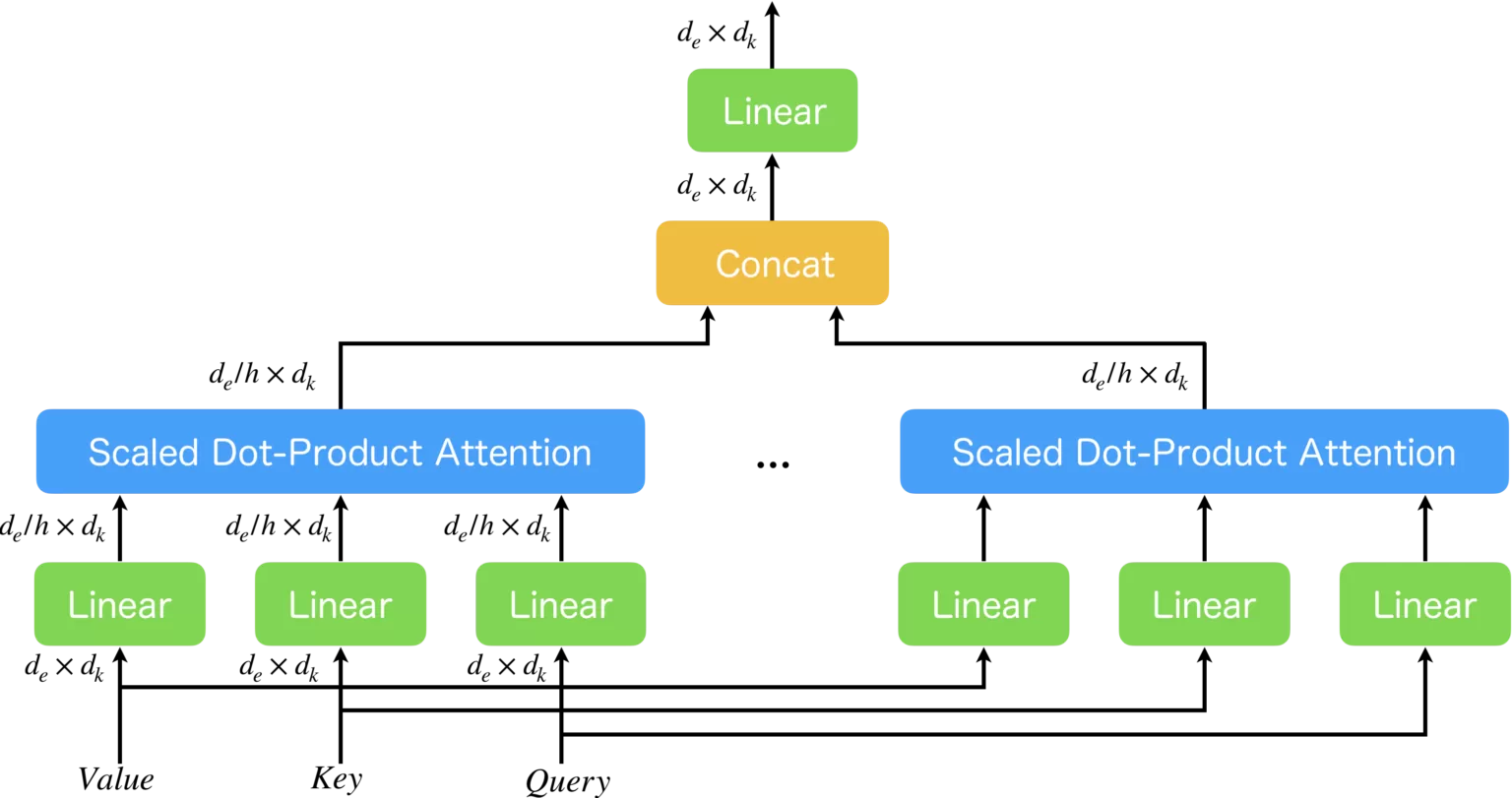
1. 指代对象
卡在同一个 Encoder 层内部 的 8 个小头
都属于同一层多头注意力里面,不分属不同层。
2. 输入关系(并行)
8 个注意力头 共享同一个输入特征 X
就是当前这个 Encoder 层的输入,大家共用一份原始输入,8 个头可以同时并行计算,不用互相等待。
3. QKV 权重关系
同层 8 个头,全程共用同一套 Wq、Wk、WvW_q、W_k、W_vWq、Wk、Wv
不是每个头单独配一套权重
整一层就只有一套公共投影权重
4. QKV 生成与分配规则
- 用同层唯一一套 Wq,Wk,WvW_q,W_k,W_vWq,Wk,Wv
- 只做一次线性投影 ,生成整层唯一一份完整全局 QKV
- 把这一份全局 QKV 按特征维度切成 8 份
- 头1拿第1块、头2拿第2块......每个头只拿自己那一小片 QKV
- 每个头用自己分到的分片 QKV 单独跑注意力公式
所有头的 QKV 源头完全一样 ,都是从同一份大 QKV 切出来的,只是各用各的片段。
上面回答了 Transformer 中多头注意力机制下,每个注意力头执行点积注意力公式时,输入的 QKV 是否为相同来源、是否共享同一份投影后的 QKV?
当看架构图的时候,不要遗漏那个n