1. ViT简介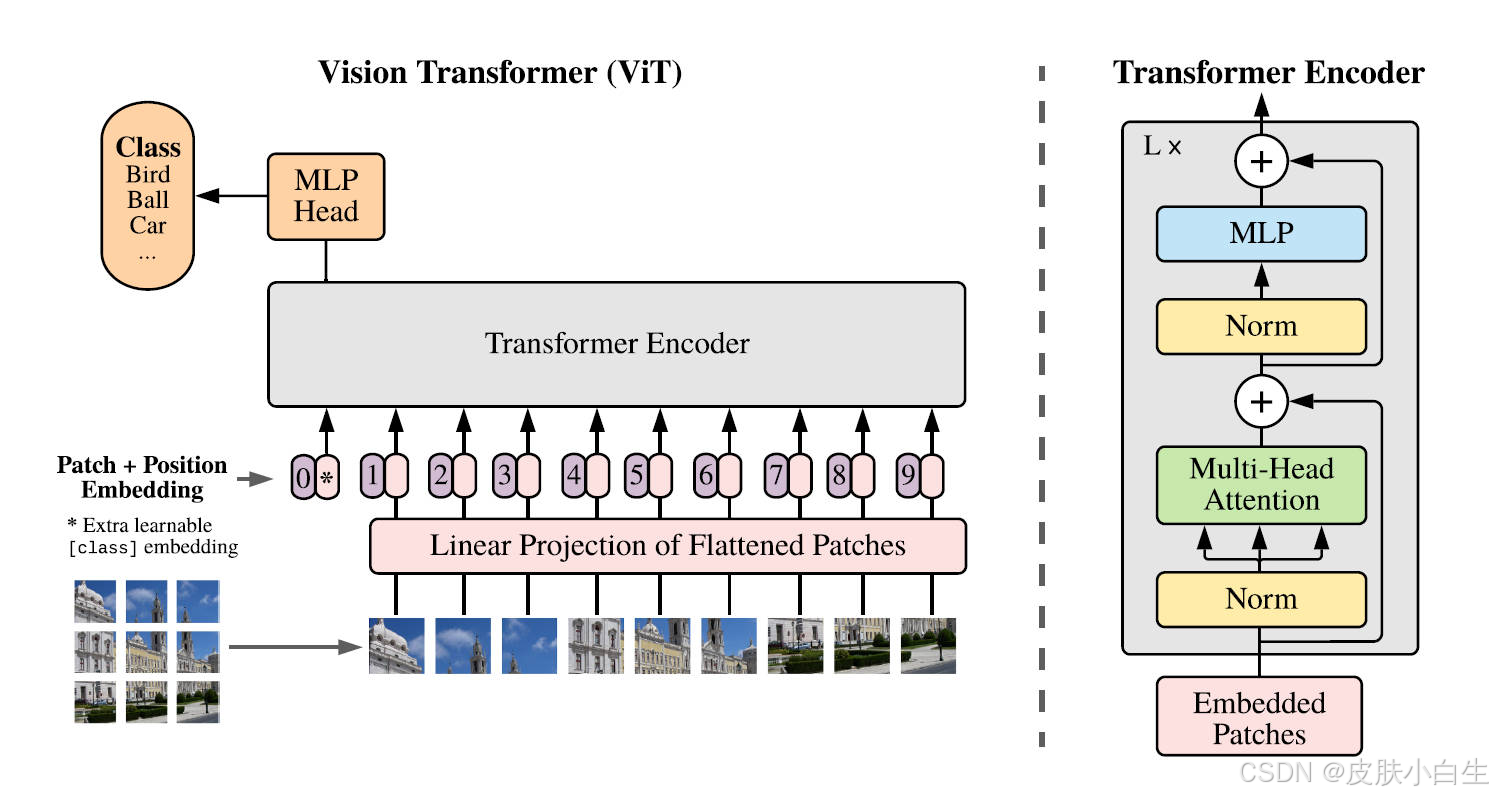
1.1 ViT的由来
论文链接:https://arxiv.org/abs/2010.11929
源码地址:https://github.com/google-research/vision_transformer
ViT(Vision Transformer)是Google团队在2020年提出的将Transformer架构应用于图像分类任务的模型。其核心创新在于将图像分割为序列化的图像块(patches),并通过标准的Transformer Encoder处理这些块。它成功地将Transformer架构(最初用于自然语言处理任务,如BERT)应用于计算机视觉领域。VIT的核心创新在于它完全摒弃了传统的卷积神经网络(CNN)结构,而是直接将图像视为序列数据来处理,这为多模态模型研究开辟了新道路。论文《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》首次证明了Transformer在视觉任务中的可扩展性(模型越大效果越好),成为CV领域的里程碑。
好的,我们来梳理一下BERT模型的核心要点: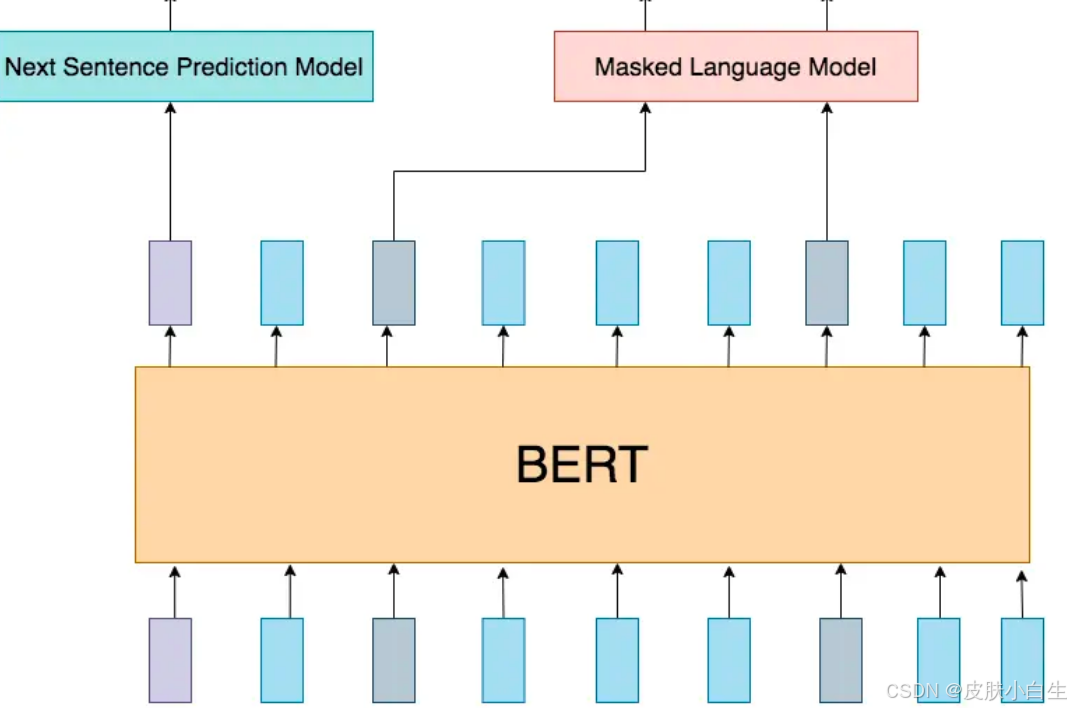
1. 输入表示
- 文本序列:输入是一条文本序列 S = \[w_1, w_2, \\dots, w_n\]。
- 词嵌入:每个词 w_i 通过嵌入层转换为向量 \\mathbf{e}_i \\in \\mathbb{R}\^d。
- 特殊标记 :
[CLS]:位于序列开头,其输出向量用于分类任务(如NSP)。[SEP]:分隔句子(如NSP任务中的句子对)。[MASK]:在MLM任务中替换被遮蔽的词。
2. 训练任务
(a) 下一句预测(Next Sentence Prediction, NSP)
- 输入格式 :
\\text{\[CLS\]} \\quad \\text{句子A} \\quad \\text{\[SEP\]} \\quad \\text{句子B} \\quad \\text{\[SEP\]}
- 任务目标:二分类预测句子A和B是否连续(50%正样本,50%负样本)。
- 输出 :
[CLS]位置的输出向量 \\mathbf{h}*{\\text{CLS}} 通过分类器预测:P(\\text{IsNext}) = \\sigma(\\mathbf{W} \\cdot \\mathbf{h}*{\\text{CLS}} + b)
(b) 遮蔽语言模型(Masked Language Model, MLM)
- 遮蔽策略 :随机选择15%的词进行遮蔽:
- 80%替换为
[MASK] - 10%替换为随机词
- 10%保持不变
- 80%替换为
- 任务目标 :基于上下文预测被遮蔽的词 w_i:
P(w_i \| \\mathbf{h}*i) = \\text{softmax}(\\mathbf{W}*{\\text{vocab}} \\cdot \\mathbf{h}_i) (\\mathbf{h}_i 为位置 i 的输出向量)
3. 模型架构
BERT基于Transformer编码器堆叠而成:
- 多层结构:由 L 层相同的Transformer编码器层组成(如BERT-base: L=12)。
- 单层操作 (以第 l 层为例): \\begin{align\*} \\mathbf{H}\^{(l)} \&= \\text{MultiHeadAttention}\\left(\\mathbf{Q}\^{(l-1)}, \\mathbf{K}\^{(l-1)}, \\mathbf{V}\^{(l-1)}\\right) \\ \\mathbf{H}\^{(l)}*{\\text{norm}} \&= \\text{LayerNorm}\\left(\\mathbf{H}\^{(l-1)} + \\mathbf{H}\^{(l)}\\right) \\ \\mathbf{H}\^{(l)}* {\\text{ffn}} \&= \\text{FFN}\\left(\\mathbf{H}\^{(l)}*{\\text{norm}}\\right) \\ \\mathbf{H}\^{(l)}* {\\text{out}} \&= \\text{LayerNorm}\\left(\\mathbf{H}\^{(l)}*{\\text{norm}} + \\mathbf{H}\^{(l)}*{\\text{ffn}}\\right) \\end{align\*}
- 输出:最后一层输出 \\mathbf{H}\^{(L)} 用于下游任务。
4. 与ViT的关联
如您所述,ViT(Vision Transformer)借鉴了BERT的架构思想:
- 输入处理:图像分块 \\to 类似词嵌入的线性投影。
- CLS标记 :ViT的
[class]标记对应BERT的[CLS],用于分类。 - 编码器堆叠:均使用Transformer编码器提取全局特征。
注:BERT的核心创新在于通过双向上下文建模(MLM)和句子关系建模(NSP)预训练通用表示,为下游任务提供强大的迁移能力。
VIT的基本原理
VIT的灵感来源于Transformer模型(如BERT),它通过自注意力机制捕捉长距离依赖关系。在图像处理中,VIT首先将输入图像分割成固定大小的补丁(patches)。假设图像尺寸为H \\times W,并被分割成N个补丁,每个补丁尺寸为P \\times P。然后,这些补丁被线性嵌入成一个序列:
\\mathbf{z}*0 = \[\\mathbf{x}* {\\text{class}}; \\mathbf{x}_p\^1 \\mathbf{E}; \\mathbf{x}_p\^2 \\mathbf{E}; \\cdots; \\mathbf{x}*p\^N \\mathbf{E}\] + \\mathbf{E}*{\\text{pos}}
其中,\\mathbf{x}*p\^i是第i个补丁的向量表示,\\mathbf{E}是嵌入矩阵,\\mathbf{E}*{\\text{pos}}是位置编码(用于保留空间信息)。这个序列随后输入到Transformer编码器中,其结构与BERT类似,包含多头自注意力层和前馈神经网络层。
自注意力机制的关键公式为:
\\text{Attention}(\\mathbf{Q}, \\mathbf{K}, \\mathbf{V}) = \\text{softmax}\\left(\\frac{\\mathbf{Q}\\mathbf{K}\^T}{\\sqrt{d_k}}\\right)\\mathbf{V}
这里,\\mathbf{Q}, \\mathbf{K}, \\mathbf{V}分别是查询、键和值矩阵,d_k是维度缩放因子。通过堆叠多个这样的层,VIT能够学习图像的全局特征,而无需卷积操作。
VIT的优势与重要性
VIT的成功证明了Transformer架构的普适性:它不仅能处理文本序列(如语言任务),还能直接应用于图像数据。这打破了传统视觉模型的局限,因为CNN通常需要手工设计的卷积核来捕捉局部特征,而VIT通过自注意力全局建模图像内容。实验显示,在大规模数据集(如ImageNet)上,VIT在分类任务中达到了与CNN相当甚至更好的性能。
更重要的是,VIT开启了多模态模型研究的新篇章。多模态模型旨在统一处理不同类型的数据(如文本、图像、视频),VIT作为"backbone"(骨架结构),可以被轻松扩展到其他领域。例如,后续模型如DALL-E和CLIP结合了VIT的视觉编码器和文本Transformer,实现了跨模态生成和理解。在AIGC研究中,VIT提供了强大的基础架构,使AI能够生成高质量图像或视频内容。
VIT在AIGC中的应用
在人工智能生成内容(AIGC)领域,VIT常作为核心组件被集成到大模型中。例如:
- 图像生成:模型如VQ-VAE结合VIT的Transformer解码器,能从潜在空间生成逼真图像。
- 视频理解:通过扩展VIT处理视频帧序列,模型可以分析动态内容。
- 多模态融合:VIT的编码器输出可以与文本Transformer的输出对齐,实现图文互译(如生成图像描述)。
总之,VIT不仅是一个高效的图像分类工具,更是推动AI向统一多模态模型发展的关键里程碑。它在研究AIGC时确实绕不过去,因为它提供了可扩展、高效的架构基础。
1.2 ViT的核心挑战与解决方案
传统Transformer处理图像时面临三个问题:
- 图像信息的高维性:像素级序列化会导致计算量爆炸。
- 缺乏归纳偏差:CNN的平移不变性和局部感受野特性在Transformer中缺失。
- 网格数据不适配:图像是网格结构,而Transformer需序列输入。
解决方案:
- 将图像分割为固定大小的块(如16 \\times 16),每个块视为一个"视觉单词"。
- 通过线性投影将块展平为向量,形成序列输入。
1.3 ViT模型架构
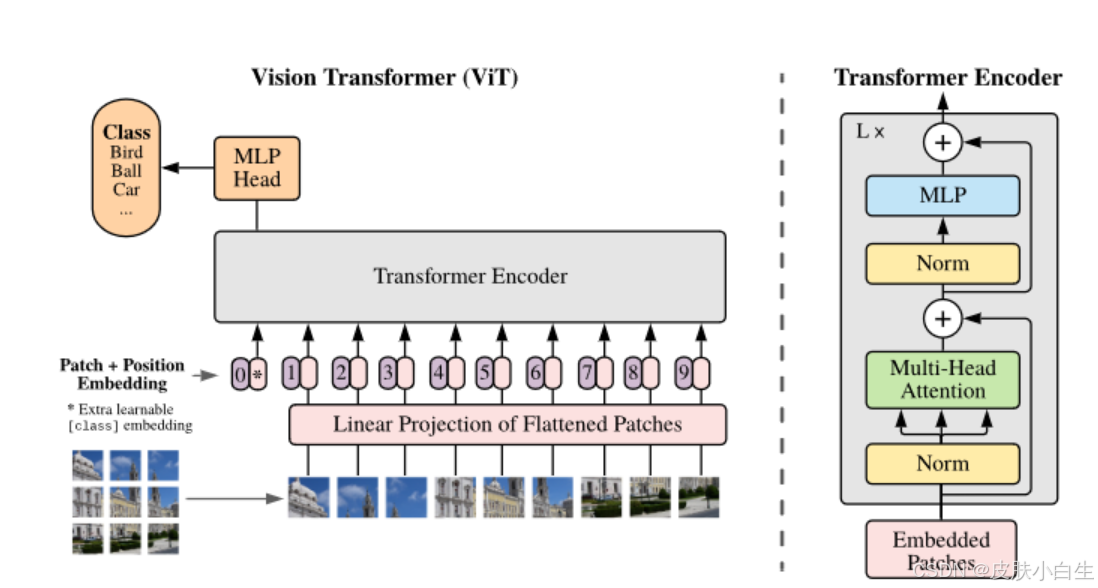
模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder
- MLP Head(最终用于分类的层结构)
模型由三部分组成:
-
Embedding层 :
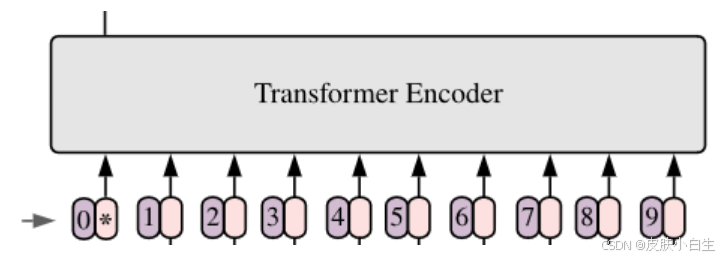
- 图像分割:输入224 \\times 224图像划分为\\frac{224}{16} \\times \\frac{224}{16} = 196个块。
- 线性投影:每个块\[16, 16, 3\]通过卷积层映射为768维向量(即 \\mathbb{R}\^{196 \\times 768})。
- 添加位置嵌入(可学习向量):保留空间信息。
- 插入
[class]标记:作为分类特征载体。
图像数据转换为Transformer输入的过程
图像数据通常以三维矩阵形式存在,形状为
[H, W, C](高度、宽度、通道数)。Transformer架构要求输入为二维矩阵[num_token, token_dim],因此需要通过Embedding层进行转换。图像分块处理
将输入图像划分为固定大小的非重叠块(Patches)。以ViT-B/16为例,输入图像尺寸为224x224,每个Patch大小为16x16。划分后得到196个Patches(224/16=14,14x14=196)。
每个Patch的数据维度为
[16, 16, 3](假设输入图像为RGB格式)。这些Patch需要通过线性变换映射到一维向量空间。线性映射实现
通过卷积层实现线性映射。使用卷积核大小为16x16,步长为16,输出通道数为768的卷积操作。输入
[224, 224, 3]经过卷积后变为[14, 14, 768]。将高度和宽度维度展平,得到
[196, 768]的二维矩阵。此时的数据格式符合Transformer的输入要求,每个token对应一个Patch的嵌入表示。代码实现示例
pythonimport torch import torch.nn as nn class PatchEmbedding(nn.Module): def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768): super().__init__() self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x): x = self.proj(x) # [B, C, H, W] -> [B, E, H/P, W/P] x = x.flatten(2) # [B, E, H*W/P^2] x = x.transpose(1, 2) # [B, N, E] return x维度变换细节
输入图像假设为
[1, 3, 224, 224](批量大小为1)。经过卷积后变为[1, 768, 14, 14]。展平空间维度得到[1, 768, 196],转置后变为[1, 196, 768],即196个768维的token序列。位置编码添加
Transformer本身不具备位置信息感知能力,通常需要添加位置编码。位置编码与token嵌入相加,保留空间位置信息。位置编码矩阵维度为
[num_token, token_dim],与token嵌入维度一致。-
图像块(patch)是如何被转换成一个768维的token嵌入向量的,以及为什么使用卷积层(CNN)是一种更优的方法。
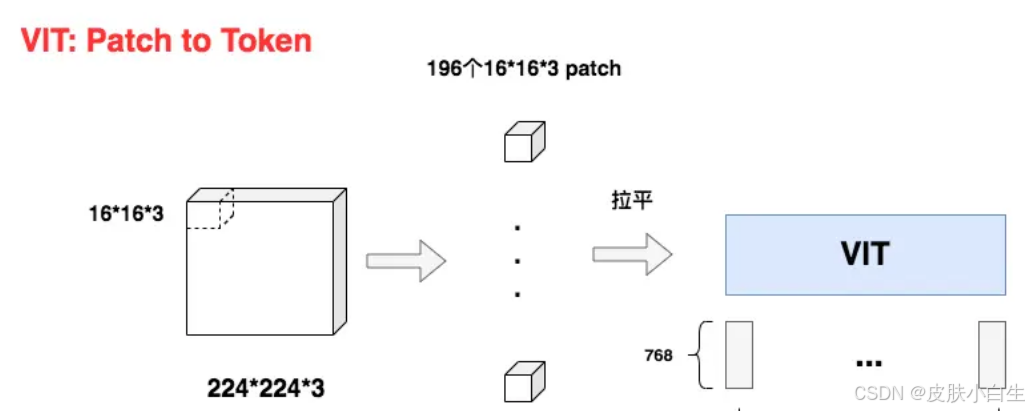
-
直接展平的问题(如你所述) : 将每个
16x16x3的块展平成一个1x768的向量,最直观的方法是:缺点:
-
将红色通道(R)的
16x16个像素值依次排成一列(长度256)。 -
将绿色通道(G)的
16x16个像素值依次排成一列(长度256)。 -
将绿色通道(B)的
16x16个像素值依次排成一列(长度256)。 -
将这
3个256维的向量首尾相接(concatenate),形成一个1x768维的向量。 -
现在我们要把它切成小patch,每个patch的尺寸设为16 (P=16 ),则每个patch下图片的大小为
16*16*3。则容易计算出共有224∗22416∗16 = 196\frac{224*224}{16*16} = 19616∗16224∗224 = 196个patch。
不难看出每个patch对应着一个token,将每个patch展平,则得到输入矩阵X,其大小为
(196, 768),也就是每个token是768维。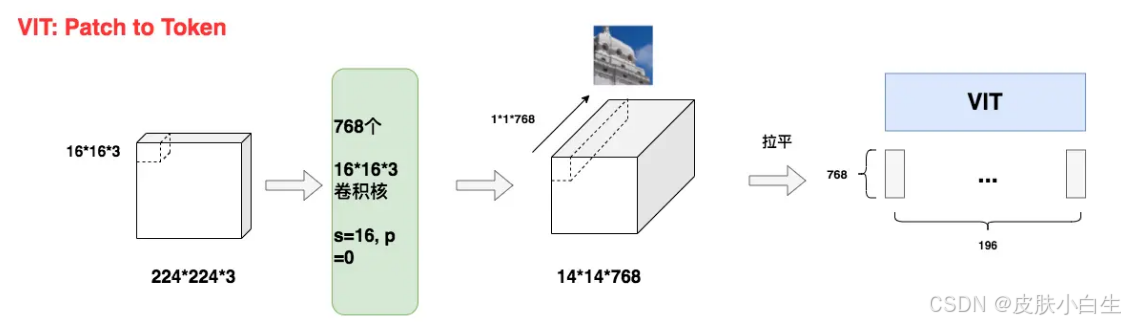
-
空间信息割裂 :正如你提到的,原本在图像中空间位置上相邻的像素点(例如
(i, j)位置的R, G, B值),在展平后的向量中,它们的距离可能很远(R_i_j在向量的开头附近,B_i_j在向量的结尾附近)。这破坏了像素间的局部空间关系。 -
通道信息割裂 :同一个像素点的
R, G, B三个值在展平向量中也分开了。它们本应紧密相关来表示该点的颜色。 -
缺乏特征提取:这种展平方式仅仅是对原始像素值进行了简单的重排,没有进行任何形式的特征学习或提取。它假设所有的像素和通道在构成token时具有同等的重要性,并且其原始排列顺序(即空间位置顺序)就是最优的表示方式。这显然是一种非常原始且表达能力有限的方式。
-
-
使用卷积层作为解决方案: Vision Transformer (ViT) 采用了另一种更聪明、更有效的方法:使用一个卷积层来将图像块投影到token嵌入空间。
- 操作 :使用
768个卷积核(filters)。每个卷积核的尺寸是16x16x3(即与一个图像块的大小完全相同)。卷积的步长(stride)设置为16,并且不进行填充(padding=0)。 - 数学过程 :
- 输入图像:
224x224x3 - 卷积核尺寸:
16x16x3(宽 x 高 x 输入通道数) - 卷积核数量:
768(输出通道数) - 步长:
16 - 填充:
0 - 输出特征图尺寸计算: H_{out} = \\lfloor \\frac{H_{in} - H_{kernel} + 2 \\times Padding}{Stride} \\rfloor + 1 = \\lfloor \\frac{224 - 16 + 0}{16} \\rfloor + 1 = \\lfloor \\frac{208}{16} \\rfloor + 1 = 13 + 1 = 14 W_{out} = \\lfloor \\frac{W_{in} - W_{kernel} + 2 \\times Padding}{Stride} \\rfloor + 1 = \\lfloor \\frac{224 - 16 + 0}{16} \\rfloor + 1 = \\lfloor \\frac{208}{16} \\rfloor + 1 = 13 + 1 = 14
- 输出特征图尺寸:
14x14x768
- 输入图像:
- 物理意义 :
- 每个
16x16x3的卷积核覆盖的区域正好是一个16x16的图像块(因为kernel_size=16x16,stride=16,padding=0)。 - 卷积操作本身可以看作是在该图像块上进行一个加权求和(点积),得到一个标量值。这个过程可以理解为对该图像块应用了一个特定的"特征检测器"。
- 因为有
768个不同的卷积核,每个卷积核学习去检测图像块中不同的特征模式(如边缘、纹理、颜色分布等)。 - 对于输入图像上的每一个
16x16的图像块(位置(i, j)),应用768个卷积核后,会得到768个标量值。这768个值就构成了该图像块对应的1x768维的token嵌入向量。 - 输出特征图的尺寸
14x14x768正好对应14x14=196个token,每个token是768维。
- 每个
- 操作 :使用
-
总结 :ViT 使用一个步长等于块尺寸(
stride=16)、无填充、卷积核尺寸等于块尺寸(16x16x3)且数量等于嵌入维度(768)的卷积层,将图像分割并投影到token嵌入空间。这种方法通过可学习的卷积权重,有效地将每个图像块转换成一个768维的特征向量(token embedding),克服了简单展平的缺点,并为Transformer模型提供了良好的输入表示。 -
为什么卷积更好:
- 学习特征表示:卷积核的权重是在训练过程中从数据中学习得到的。网络自动学习如何组合图像块内的像素和通道信息,以形成更有意义的特征表示,而不是依赖手工设计的规则化展平方式。
- 保留空间相关性 :卷积操作在计算时,会同时考虑一个卷积核覆盖区域内所有相邻像素的值及其通道信息(因为核尺寸是
16x16x3)。这使得生成的token向量能够隐式地编码原始图像块中像素间的空间关系和通道关系。 - 可学习的特征提取器 :
768个不同的卷积核相当于768个不同的特征提取器。它们共同作用,将原始的像素块转换到一个更高维、更具判别性的嵌入空间,为后续的Transformer层处理做好准备。
理解问题
您的问题是关于如何将一个16x16x3的图像块(例如RGB图像的一个小区域)拉平成1x768维度的向量。原始数据维度是高度16、宽度16、通道数3(如红、绿、蓝),总元素数为16×16×3=768。您提到了一种常见方法:将每个通道单独拉平成向量后拼接(即"通道优先"方法),但担心这会导致同一个像素的三个通道值在向量中距离变远,从而丢失空间关联性。此外,您认为这类方法"太规则化、太主观",意思是它们依赖于人为定义的顺序,缺乏灵活性。
在图像处理中,拉平操作本质上是将多维数据转换为向量形式,这通常用于输入到机器学习模型(如全连接网络)。但不同的拉平策略会影响数据的表示效果。下面我将逐步分析这个问题,并提供几种可行的解决方案。
分析用户提到的方法:通道优先拼接
您描述的方法是将每个通道的16x16矩阵拉平成256维向量(因为16×16=256),然后按通道顺序拼接。数学上,假设图像块表示为张量A \\in \\mathbb{R}\^{16 \\times 16 \\times 3},则:拉平第一个通道:C_1 = \\text{flatten}(A_{:,:,1}) \\in \\mathbb{R}\^{256}拉平第二个通道:C_2 = \\text{flatten}(A_{:,:,2}) \\in \\mathbb{R}\^{256}拉平第三个通道:C_3 = \\text{flatten}(A_{:,:,3}) \\in \\mathbb{R}\^{256}最终向量:V = \[C_1, C_2, C_3\] \\in \\mathbb{R}\^{768}
-
-
缺点 :通道值分离 :同一个像素的三个通道值在原始块中是局部相关的(如位置(i,j)的R_{ij}、G_{ij}、B_{ij}相邻),但在向量V中,它们被分开了。例如,R_{ij}在索引k处,G_{ij}在k+256处,B_{ij}在k+512处(假设顺序索引)。这可能导致模型难以捕捉通道间的交互。规则化和主观性:这种方法固定了通道顺序(如先红后绿再蓝),忽略了不同通道的语义关系(如颜色相关性)。如果通道顺序变化(如BGR),结果会不同,体现了人为规则的局限性。
改进方法:像素优先拼接
-
为了解决通道值分离问题,一种替代方法是"像素优先"拼接:将每个像素的三个通道值作为一个组,然后拉平所有像素组。这样,同一个像素的通道值在向量中保持连续。
步骤:
-
对于每个像素位置(i,j),提取通道值:P_{ij} = \[A_{i,j,1}, A_{i,j,2}, A_{i,j,3}\] \\in \\mathbb{R}\^3。
-
将所有像素的P_{ij}按顺序拼接:先遍历行或列(如行优先顺序)。
- 例如,行优先:从i=1到16,j=1到16,依次取P_{11}, P_{12}, \\dots, P_{1616}。
-
最终向量:V = \[P_{11}, P_{12}, \\dots, P_{1616}\] \\in \\mathbb{R}\^{768}。
-
数学上,这相当于将张量重塑为向量: V = \\text{reshape}(A, (1, 768)) 但顺序是像素优先而非通道优先。
优点:
-
通道值邻近:同一个像素的R_{ij}、G_{ij}、B_{ij}在向量中相邻(例如,索引k到k+2),便于模型处理颜色信息。
-
空间信息保留:像素顺序(如行优先)保留了部分空间关系。
-
缺点:
-
仍然主观:像素顺序(行优先或列优先)是人为设定的,如果图像旋转或翻转,表示会变化。
-
空间关系部分丢失:尽管像素间顺序保留了局部位置,但二维结构被简化为一维,可能丢失更复杂的空间模式。
讨论主观性问题
所有拉平方法(包括通道优先和像素优先)都存在主观性和规则化问题,因为它们依赖于预设的遍历顺序(如通道顺序、行/列顺序)。这可能导致:
-
信息损失:原始二维结构被压缩,空间相关性减弱。
-
鲁棒性差:顺序变化(如通道交换)会改变向量表示,影响模型性能。
-
缺乏灵活性:这些方法没有自适应学习数据的内在结构。
-
为了减少主观性,建议在拉平之前或之后使用特征提取技术,让模型自动学习最优表示。以下是几种实用方案:
1. 使用卷积神经网络(CNN)自动学习特征
-
原理:CNN能保留空间和通道关系,通过卷积层自动提取特征,避免手动拉平的主观性。
-
步骤 :
- 将16x16x3块输入CNN(如一个小的卷积层)。
- CNN输出特征图(例如,经过池化或Flatten层),然后作为向量使用。
-
优点:卷积操作局部连接像素和通道,学习权重自适应,减少人为规则。
-
代码示例 (Python + Keras):
pythonfrom tensorflow.keras.layers import Input, Conv2D, Flatten from tensorflow.keras.models import Model # 定义输入:16x16x3图像块 input_layer = Input(shape=(16, 16, 3)) # 添加卷积层学习特征(例如,使用32个3x3滤波器) x = Conv2D(32, (3, 3), activation='relu')(input_layer) # 拉平输出(自动处理顺序) output = Flatten()(x) # 构建模型 model = Model(inputs=input_layer, outputs=output) # 输出维度取决于卷积层,但可通过设计调整为768维注意:输出维度可能不是768,但可以通过调整层大小(如添加更多层或调整滤波器)匹配目标维度。
2. 嵌入或主成分分析(PCA)
- 原理 :使用降维或嵌入技术学习数据驱动的表示。
- PCA:对拉平后的向量应用PCA,提取主成分,减少维度并捕捉主要变异。
- 嵌入层:在神经网络中,添加嵌入层将输入映射到低维空间。
- 优点:自适应数据分布,减少规则化。
- 数学形式:假设V是拉平向量,PCA可表示为: V_{\\text{pca}} = W \\cdot V 其中W是学习到的投影矩阵。
3. 混合方法:结合像素优先和标准化
- 步骤 :
- 使用像素优先方法拉平:V = \[P_{11}, P_{12}, \\dots, P_{1616}\]。
- 应用标准化(如归一化或通道标准化)以减少通道顺序的影响。
- 在输入模型前添加可学习组件(如全连接层)。
- 优点:简单易实现,部分缓解主观性。
总结与建议
-
基本选择:如果您必须手动拉平,推荐"像素优先"方法,因为它保持了同一个像素的通道值邻近。例如,在Python中,使用NumPy实现:
pythonimport numpy as np # 假设block是16x16x3的NumPy数组 vector = block.reshape((1, -1), order='C') # 'C'表示行优先顺序 # 输出维度为1x768这里
order='C'指定行优先顺序,您可以根据需要调整(如order='F'为列优先)。 -
高级建议:在实际应用中(如深度学习),避免直接手动拉平。优先使用CNN或其他特征提取模型,让数据驱动表示学习。这能显著减少主观性并提升性能。如果您有具体应用场景(如分类或检测),我可以提供更针对性的方案。
-
如果您能分享更多上下文(如为什么需要拉平成768维向量),我可以进一步优化建议。希望这个回答对您有帮助!
建议更优方法:使用特征提取
-
Transformer Encoder :
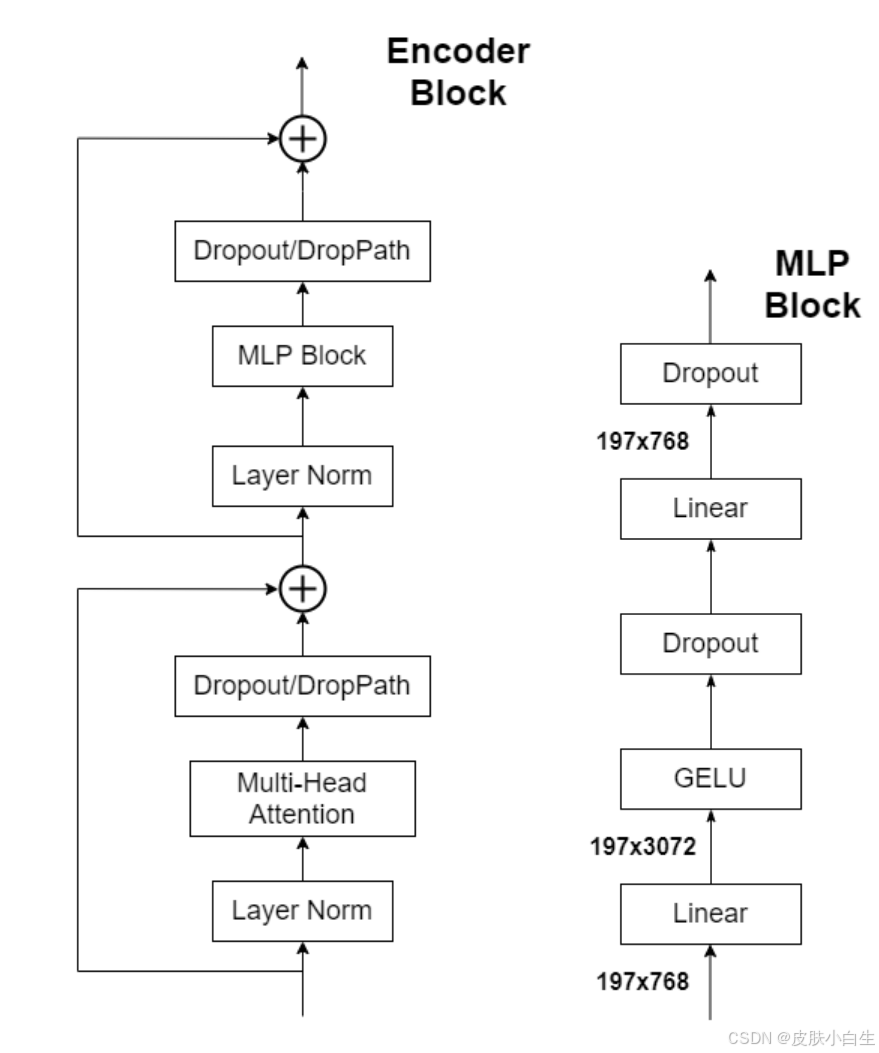
- 堆叠L层Encoder Block(如ViT-Base中L=12)。
- 每层含多头自注意力(Multi-Head Attention)和MLP模块,辅以LayerNorm与残差连接。
Transformer Encoder 结构解析
Transformer Encoder 通过重复堆叠相同的编码器块(Encoder Block)构建深度模型,每个块包含以下核心组件:
Multi-Head Attention 机制
多头注意力层通过并行计算多组注意力权重,捕获输入序列中不同位置的依赖关系。其计算过程可分解为:
- 将输入分别投影到查询(Q)、键(K)、值(V)空间
- 按头数分割张量后计算缩放点积注意力: \\text{Attention}(Q,K,V)=\\text{softmax}(\\frac{QK\^T}{\\sqrt{d_k}})V
- 拼接各头输出并通过线性变换得到最终结果
Layer Normalization
层归一化对每个样本的特征维度进行标准化,缓解深层网络训练中的梯度问题: \\text{LayerNorm}(x)=\\gamma\\frac{x-\\mu}{\\sqrt{\\sigma\^2+\\epsilon}}+\\beta 其中\\mu和\\sigma为特征的均值和标准差,\\gamma和\\beta为可学习参数。
前馈神经网络(MLP Block)
由两层全连接层和激活函数构成: \\text{FFN}(x)=\\max(0,xW_1+b_1)W_2+b_2 中间隐藏层通常扩展维度至输入维度的4倍。
Dropout 正则化
在注意力权重计算和MLP输出处应用dropout,随机置零部分激活值以防止过拟合:
- 注意力dropout作用于softmax后的权重矩阵
- 前馈网络dropout应用于每个全连接层输出
残差连接
每个子层(注意力/前馈网络)均采用残差连接,保留原始输入信息: \\text{Output}=\\text{LayerNorm}(x+\\text{Sublayer}(x)) 这种结构设计使得梯度能够有效反向传播至底层。
代码实现时通常将上述组件封装为可复用的Encoder Layer,通过配置层数参数实现深度堆叠。典型实现示例如下:
pythonclass TransformerEncoderLayer(nn.Module): def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1): super().__init__() self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout) self.linear1 = nn.Linear(d_model, dim_feedforward) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) def forward(self, src, src_mask=None): x = src x = x + self.dropout1(self.self_attn(x, x, x, attn_mask=src_mask)[0]) x = self.norm1(x) x = x + self.dropout2(self.linear2(F.relu(self.linear1(x)))) return self.norm2(x)Token Embedding
在ViT中,Token Embedding的作用是将输入图像分块后的Patch转换为向量表示。假设输入经过Patch处理后得到形状为(196, 768)的矩阵,其中196表示Patch数量,768表示每个Patch的维度。Token Embedding矩阵E的形状为(768, 768),通过矩阵乘法将输入X转换为嵌入表示:
X_{TE} = X \\cdot E
原始输入X仅由预处理生成,而Token Embedding参与模型训练,通过梯度更新优化向量表示。E的第二维可以自由设定,例如(768, x),以调整嵌入维度。
Position Embedding
位置编码用于为模型提供Patch的位置信息。ViT中采用1-D绝对位置编码,形状为(196, 768),表示196个Patch的位置向量。以下是ViT论文中实验过的四种方案:
方案一:无位置编码
直接忽略位置信息,将Patch视为无序集合,效果显著较差。
方案二:1-D绝对位置编码
分为函数式(如Transformer的三角函数编码)和可学习式(ViT采用)。后者通过训练学习位置向量,表示Patch的绝对位置。
方案三:2-D绝对位置编码
将位置向量拆分为x轴和y轴两部分,分别编码Patch在图像中的二维坐标。
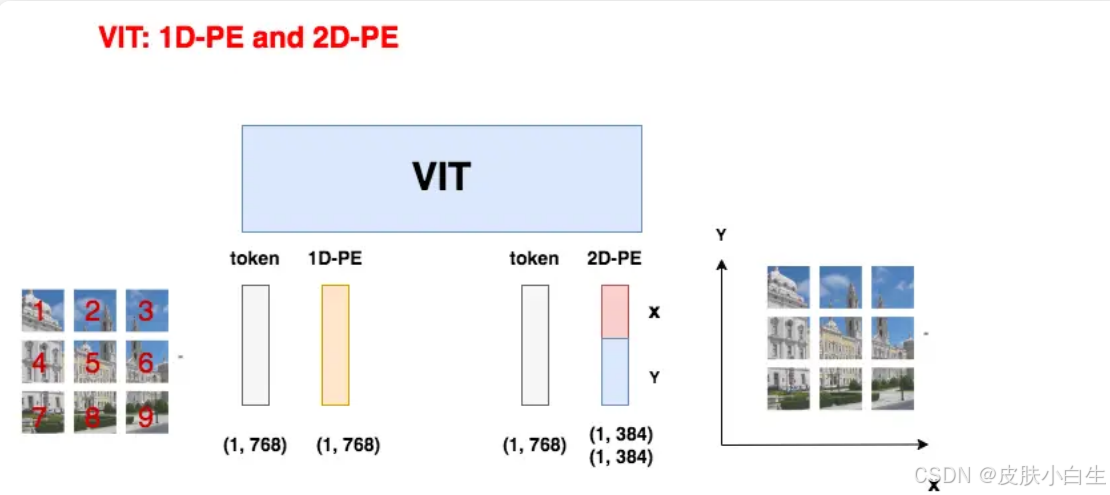
方案四:相对位置编码
关注Patch间的相对位置关系,通过偏置项(bias)引入Attention计算中。采用Clip操作限制参数量,例如设定k=2时,超出范围的相对位置用固定向量替代。
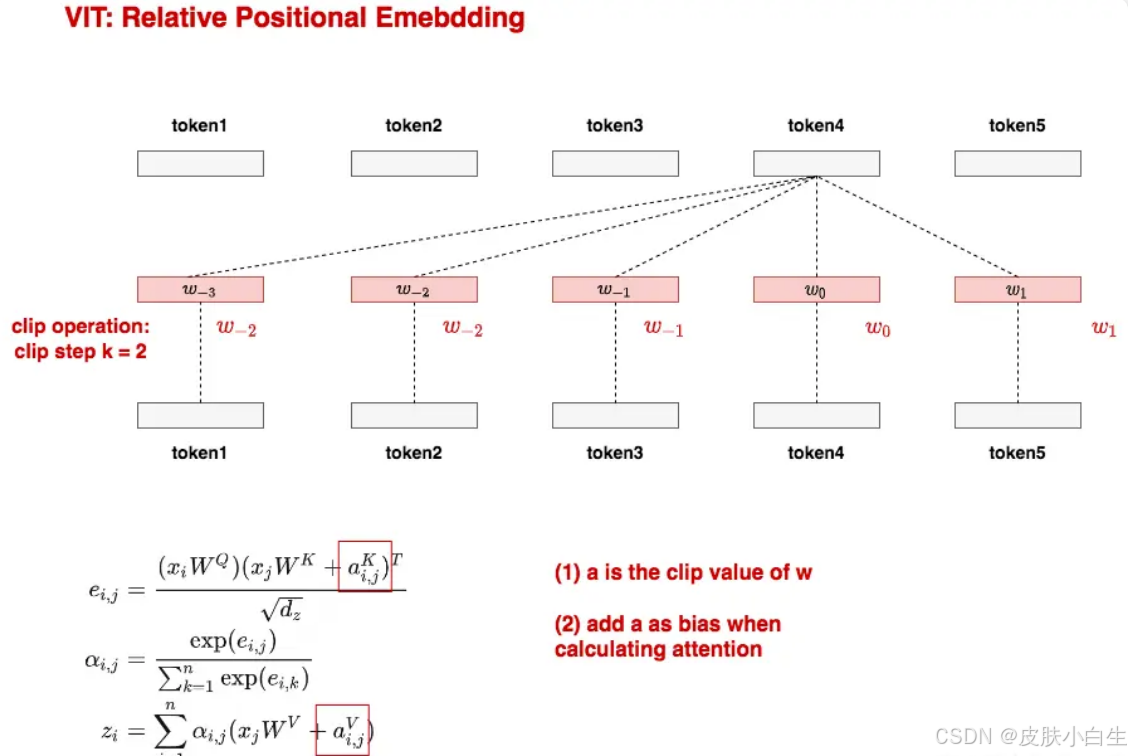
实验结果对比
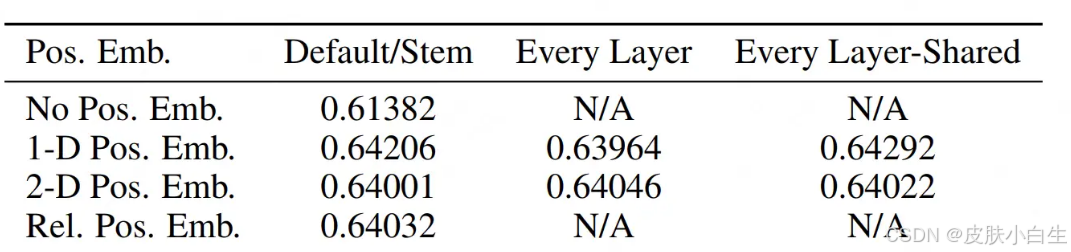
-
无位置编码:性能显著下降。
-
1-D绝对编码:效果与其他方案相近,实现简单,被选为最终方案。
-
ViT通过大量消融实验验证设计选择,例如分类头(
<cls>)的添加方式,体现了严谨的工程方法论。 -
2-D绝对编码:与1-D方案效果接近,但计算复杂度更高。
-
相对位置编码:性能与绝对编码相当,但实现更复杂。
-
MLP Head :
- 仅提取
[class]标记的输出向量(\\mathbb{R}\^{768}),通过全连接层分类。
Transformer Encoder的输出处理
在ViT-B/16模型中,输入形状为
[197, 768],其中197表示197个token(包括1个[class]token和196个图像块token),768是每个token的嵌入维度。Transformer Encoder的输出保持与输入相同的形状[197, 768]。分类任务仅需关注
[class]token对应的输出向量,即从[197, 768]中提取[1, 768]的向量。这一步骤通过简单的切片操作实现。MLP Head的结构设计
MLP Head的结构根据训练数据规模有所不同:
- ImageNet21K训练时 :采用两层线性层(Linear)中间加入tanh激活函数,结构为
Linear → tanh → Linear。这种设计可能有助于捕捉更复杂的特征表示。 - ImageNet1K或自定义数据训练时:仅使用单层线性层(Linear)即可满足需求。这种简化可能避免过拟合并提升训练效率。
实现示例代码
pythonimport torch import torch.nn as nn class MLPHead(nn.Module): def __init__(self, in_dim, out_dim, use_two_layer=False): super().__init__() if use_two_layer: self.mlp = nn.Sequential( nn.Linear(in_dim, in_dim), nn.Tanh(), nn.Linear(in_dim, out_dim) ) else: self.mlp = nn.Linear(in_dim, out_dim) def forward(self, x): # x shape: [batch_size, num_tokens, hidden_dim] cls_token = x[:, 0, :] # Extract [class] token return self.mlp(cls_token)关键注意事项
[class]token的位置 :默认情况下,[class]token是输入序列的第一个token(索引0),需确保切片操作正确。- 激活函数的选择:若采用两层结构,tanh激活函数可替换为其他非线性函数(如GELU),但需与原论文保持一致。
- 迁移学习的调整:当模型从ImageNet21K迁移到较小数据集时,简化MLP Head结构可能提升性能并减少计算开销。
- 仅提取
2. ViT工作原理详解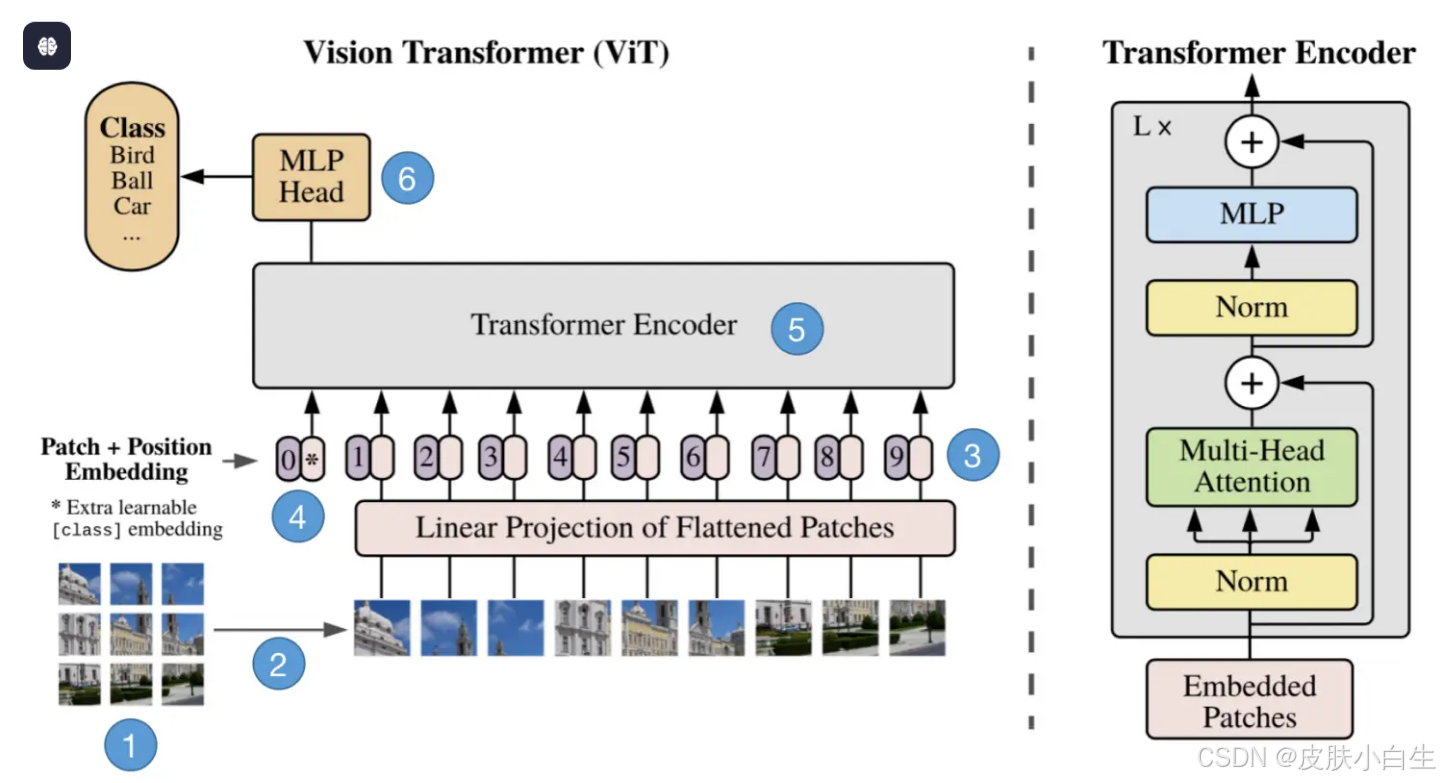
2.1 图像分块与序列化
设输入图像\\mathbf{X} \\in \\mathbb{R}\^{H \\times W \\times C},块大小P \\times P:
- 块数量N = \\frac{H}{P} \\times \\frac{W}{P}。
- 每个块展平为\\mathbf{x}_p \\in \\mathbb{R}\^{P\^2 C}。
2.2 线性投影与位置嵌入
投影矩阵与位置嵌入公式解析
投影矩阵\\mathbf{W}_p \\in \\mathbb{R}\^{(P\^2 C) \\times D}的作用是将图像块线性映射到D维潜在空间。输入图像被分割为N个大小为P \\times P \\times C的块(C为通道数),每个块展平为P\^2C维向量后与投影矩阵相乘。
块嵌入与分类标记的拼接公式为: \\mathbf{z}*0 = \[\\mathbf{x}* {\\text{class}}; \\mathbf{x}_p\^1 \\mathbf{W}_p; \\mathbf{x}_p\^2 \\mathbf{W}*p; \\dots\] + \\mathbf{E}*{\\text{pos}}
其中:
- \\mathbf{x}_{\\text{class}}是可学习的分类标记
- \\mathbf{x}_p\^i表示第i个图像块的展平向量
- \\mathbf{E}_{\\text{pos}}为位置嵌入矩阵,维度为\\mathbb{R}\^{(N+1) \\times D}
维度说明
- 输入块维度:P \\times P \\times C展平为P\^2C维向量
- 投影后维度:每个块通过\\mathbf{W}_p映射为D维向量
- 输出序列长度:N+1(N个图像块+1个分类标记)
- 位置嵌入维度:与输出序列维度匹配,每个位置对应D维向量
实现要点
- 投影矩阵\\mathbf{W}_p通常通过全连接层实现
- 位置嵌入可采用可学习参数或正弦编码
- 分类标记\\mathbf{x}_{\\text{class}}参与最终分类任务
2.3 Transformer Encoder处理
- 输入序列\\mathbf{z}*0 \\in \\mathbb{R}\^{(N+1) \\times D}通过L层Encoder:
\\mathbf{z}'*l = \\text{MSA}(\\text{LayerNorm}(\\mathbf{z}*{l-1})) + \\mathbf{z}* {l-1}
\\mathbf{z}_l = \\text{MLP}(\\text{LayerNorm}(\\mathbf{z}'_l)) + \\mathbf{z}'_l
2.4 分类输出
- 取
[class]标记对应的输出\\mathbf{z}*L\^0,输入MLP Head:\\hat{\\mathbf{y}} = \\text{MLP}*{\\text{head}}(\\mathbf{z}_L\^0)
以下是针对您提供的输入序列 \\mathbf{z}_0 \\in \\mathbb{R}\^{(N+1) \\times D} 通过 L 层 Encoder 的公式解释。我将逐步分析该过程,确保解释清晰、可靠。公式描述了 Transformer 模型中常见的 Encoder 层结构,其中涉及 Multi-head Self-Attention (MSA)、Layer Normalization (LayerNorm)、多层感知机 (MLP) 和残差连接。这些组件共同作用,以高效处理序列数据。
1. 输入序列介绍
- 输入序列 \\mathbf{z}_0 表示初始状态,维度为 (N+1) \\times D,其中 N 是序列长度(例如,序列中的元素数量),D 是特征维度(例如,每个元素的嵌入维度)。
- 该序列通过 L 层 Encoder 进行处理,每层输出一个更新后的序列 \\mathbf{z}_l(其中 l 表示层索引,从 1 到 L)。
2. Encoder 层结构
每层 Encoder 包含两个主要子步骤:首先应用 MSA 和残差连接,然后应用 MLP 和残差连接。公式如下:
\\mathbf{z}'*l = \\text{MSA}(\\text{LayerNorm}(\\mathbf{z}*{l-1})) + \\mathbf{z}_{l-1}$$ $$\\mathbf{z}_l = \\text{MLP}(\\text{LayerNorm}(\\mathbf{z}'_l)) + \\mathbf{z}'_l
我将逐步解释这些步骤。
步骤 1: 应用 MSA 和残差连接
- 输入:上一层的输出 \\mathbf{z}_{l-1}(对于第 1 层,输入是 \\mathbf{z}_0)。
- Layer Normalization :首先对 \\mathbf{z}*{l-1} 应用 LayerNorm。这是一个归一化操作,旨在稳定训练过程。具体来说: \\text{LayerNorm}(\\mathbf{z}*{l-1}) 它计算每个序列元素的均值和方差,并进行缩放和平移,以减少内部协变量偏移。
- MSA (Multi-head Self-Attention):接下来应用 MSA 到归一化后的序列。MSA 是自注意力机制的扩展,允许模型同时关注序列的不同部分。其核心是计算查询(Query)、键(Key)和值(Value)矩阵: \\text{MSA}(\\mathbf{x}) = \\text{Concat}(\\text{head}_1, \\text{head}_2, \\dots, \\text{head}_h) \\mathbf{W}\^O 其中每个头 \\text{head}_i 定义为: \\text{head}_i = \\text{Attention}(\\mathbf{x}\\mathbf{W}_i\^Q, \\mathbf{x}\\mathbf{W}_i\^K, \\mathbf{x}\\mathbf{W}_i\^V) 而 \\text{Attention} 函数为: \\text{Attention}(\\mathbf{Q}, \\mathbf{K}, \\mathbf{V}) = \\text{softmax}\\left(\\frac{\\mathbf{Q}\\mathbf{K}\^T}{\\sqrt{d_k}}\\right)\\mathbf{V} 这里,h 是注意力头的数量,\\mathbf{W}_i\^Q, \\mathbf{W}_i\^K, \\mathbf{W}_i\^V 是投影矩阵,d_k 是键维度。
- 残差连接 :MSA 的输出与原始输入 \\mathbf{z}*{l-1} 相加: \\mathbf{z}'*l = \\text{MSA}(\\text{LayerNorm}(\\mathbf{z}*{l-1})) + \\mathbf{z}*{l-1} 这一步确保梯度在反向传播时不会消失,并保留原始信息。
步骤 2: 应用 MLP 和残差连接
- 输入:上一步的中间输出 \\mathbf{z}'_l。
- Layer Normalization:再次应用 LayerNorm 到 \\mathbf{z}'_l: \\text{LayerNorm}(\\mathbf{z}'_l) 这进一步稳定特征分布。
- MLP (多层感知机):应用一个前馈神经网络,通常包含两个线性变换和激活函数(如 ReLU)。MLP 在特征维度上操作: \\text{MLP}(\\mathbf{x}) = \\mathbf{W}_2 \\cdot \\text{ReLU}(\\mathbf{W}_1 \\mathbf{x} + \\mathbf{b}_1) + \\mathbf{b}_2 其中 \\mathbf{W}_1 和 \\mathbf{W}_2 是权重矩阵,\\mathbf{b}_1 和 \\mathbf{b}_2 是偏置向量。
- 残差连接:MLP 的输出与中间输入 \\mathbf{z}'_l 相加: \\mathbf{z}_l = \\text{MLP}(\\text{LayerNorm}(\\mathbf{z}'_l)) + \\mathbf{z}'_l 这再次强化了残差学习,帮助模型学习复杂模式。
3. 整体流程和输出
- 整个过程从 \\mathbf{z}_0 开始,通过 L 层 Encoder 迭代应用上述步骤。
- 最终输出 \\mathbf{z}_L 是经过所有层处理后的序列,维度仍为 (N+1) \\times D,但包含了更高层次的表示,适用于下游任务(如分类或翻译)。
- 关键优势:残差连接和 LayerNorm 的组合使模型能够处理深层网络,避免梯度问题,同时 MSA 和 MLP 提供了强大的特征提取能力。
4. 实际应用示例
在 Transformer 模型中,这种 Encoder 结构常用于处理序列数据(如自然语言处理)。例如,输入 \\mathbf{z}_0 可能代表一个句子的嵌入序列,Encoder 层逐步学习序列的上下文依赖关系。
如果您有特定问题(如实现细节、参数设置或相关数学证明),请提供更多信息,我可以进一步扩展解释!
3. 模型参数配置
| 模型类型 | Layers (L) | Hidden Size (D) | MLP Size | Heads |
|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 |
| ViT-Large | 24 | 1024 | 4096 | 16 |
| ViT-Huge | 32 | 1280 | 5120 | 16 |
4. 结果分析
ViT在ImageNet-21K等大规模数据集上表现优异:
- 相比ResNet,ViT-Large在ImageNet-21K的Top-1精度提升4%以上。
- 训练成本高,但预训练后迁移到小数据集(如ImageNet-1K)效果显著。
- 局限性:小数据集上弱于CNN,需大量数据才能发挥优势。
注:ViT的提出推动了后续视觉Transformer模型(如Swin Transformer)的发展,解决了局部建模与计算效率问题。
好的,我将为您整理关于 ViT 模型的详细解析,重点说明其核心结构和关键设计。以下是结构化内容:
1. 模型概述
Vision Transformer (ViT) 是首个将 Transformer 架构完全应用于图像识别的模型。其核心思想是将图像划分为若干 patch,并将每个 patch 视为一个 token。在 ImageNet-21K(3亿数据)预训练后,ViT-L/16 在 ImageNet-1K 上达到 88.55% top-1 准确率。
2. 模型架构
2.1
图像到块的转换(Image to Patches)
ViT 的第一步是将输入图像分割成固定大小的块(patches),以便将图像转换为序列形式,类似于NLP中的词序列(tokens)。假设输入图像尺寸为高度 H、宽度 W、通道数 C(例如RGB图像的 C=3),块大小设置为 P \\times P(为简化,通常 P_1 = P_2 = P)。块数量 N 的计算公式为: N = \\frac{H}{P} \\times \\frac{W}{P} 要求 H 和 W 必须能被 P 整除,否则模型无法处理(会抛出异常)。每个块的原始维度是 P \\times P \\times C,然后通过扁平化操作(flattening)将其转换为一维向量,长度为 P \\times P \\times C。最终,整个图像被表示为序列 X \\in \\mathbb{R}\^{N \\times D},其中 D = P \\times P \\times C 是每个块的嵌入维度,N 是序列长度(相当于NLP中的token序列)。
这一步的目的是降低计算复杂度(避免直接处理高分辨率图像),并使数据适应Transformer架构。在代码中,常用 Rearrange 函数实现维度转换,例如将形状 B \\times C \\times H \\times W(batch size, channels, height, width)转换为 B \\times N \\times D。
Patch Embedding 层
数学上,这通过线性变换实现: E = X \\cdot W + b,其中 W \\in \\mathbb{R}\^{D \\times d_{\\text{model}}} 是权重矩阵,b \\in \\mathbb{R}\^{d_{\\text{model}}} 是偏置向量。这步确保了每个块被表示为低维特征向量,便于Transformer处理。
- 输入处理:图像 \\mathbf{X} \\in \\mathbb{R}\^{H \\times W \\times C} 被分割为 N 个 P \\times P 的 patch。
- 线性映射:通过卷积层实现展平与投影: \\mathbf{E} \\in \\mathbb{R}\^{(P\^2 \\cdot C) \\times D} 例如 224 \\times 224 \\times 3 输入(P=16)→ 14 \\times 14 \\times 768 → 展平为 196 \\times 768。
- Class Token :添加可训练参数 \\mathbf{x}*{\\text{class}} \\in \\mathbb{R}\^{1 \\times D},拼接后得到: \\mathbf{z}*0 = \[\\mathbf{x}*{\\text{class}}; \\mathbf{x}\^1\\mathbf{E}, \\cdots, \\mathbf{x}\^N\\mathbf{E}\] + \\mathbf{E}*{\\text{pos}} 维度变为 (N+1) \\times D(如 197 \\times 768)。
块维度映射(Patch Embedding)
扁平化后的块向量维度 D 可能过大或不适合后续处理,因此ViT添加一个全连接层(线性层)进行维度缩放。这步称为块嵌入(patch embedding),将原始维度 D 映射到目标维度 d_{\\text{model}}(通常 d_{\\text{model}} \< D)。操作如下:
- 输入:扁平化序列 X \\in \\mathbb{R}\^{N \\times D}
- 输出:映射后序列 E \\in \\mathbb{R}\^{N \\times d_{\\text{model}}},其中 d_{\\text{model}} 是预设的嵌入维度。
2.2 位置编码(Position Embedding)
最终,位置嵌入矩阵 P \\in \\mathbb{R}\^{N \\times d_{\\text{model}}} 与块嵌入 E 相加: Z = E + P。这步输出 Z \\in \\mathbb{R}\^{N \\times d_{\\text{model}}},融合了块内容和位置信息。
- 作用:实验表明,1D 位置编码提升准确率 ≈3%(0.61382 → 0.64206)。
- 特性 :
- 使用可训练参数 \\mathbf{E}_{\\text{pos}} \\in \\mathbb{R}\^{(N+1) \\times D}。
- 不同位置编码的余弦相似度可视化显示局部相关性(如图示 7 \\times 7 网格的相似度分布)。
位置信息嵌入(Position Embedding)
与NLP类似,ViT需要编码块在序列中的位置信息,因为图像块的空间顺序对分类至关重要。位置嵌入(position embedding)通过特定公式生成位置编码,并与块嵌入相加。标准公式基于正弦和余弦函数,确保位置信息可学习且能处理长序列: \\text{PE}*{(pos, 2i)} = \\sin\\left(\\frac{pos}{10000\^{2i / d* {\\text{model}}}}\\right) \\text{PE}*{(pos, 2i+1)} = \\cos\\left(\\frac{pos}{10000\^{2i / d*{\\text{model}}}}\\right) 其中:
- pos 是块在序列中的位置(从0到 N-1)
- i 是维度索引(从0到 d_{\\text{model}}/2 - 1)
- d_{\\text{model}} 是嵌入维度。
2.3 Transformer Encoder
Transformer 编码器(Transformer Encoder)
编码器是ViT的核心,由多个相同的块堆叠而成(深度 L)。每个编码器块包括层归一化(LayerNorm)、多头自注意力(Multi-Head Attention)和多层感知机(MLP)。输入序列 Z_{\\text{cls}} \\in \\mathbb{R}\^{(N+1) \\times d_{\\text{model}}} 经过以下处理:
- 层归一化(LayerNorm):稳定训练,对每个特征维度归一化。
- 多头自注意力(Multi-Head Attention):将输入分为多个头(heads),每个头独立计算注意力权重。公式上,给定查询 Q、键 K、值 V(均来自输入),注意力输出为: \\text{Attention}(Q, K, V) = \\text{softmax}\\left(\\frac{QK\^T}{\\sqrt{d_k}}\\right)V 其中 d_k 是键维度(通常 d_k = d_{\\text{model}} / \\text{heads})。多头机制允许模型捕获不同子空间的关系,提升特征丰富性(如图像中的局部和全局关联)。
- 残差连接和MLP:注意力输出后添加残差连接,再经MLP(全连接层 + 激活函数如GELU)处理。输出维度不变。
多个编码器块堆叠后,输出序列仍为 \\mathbb{R}\^{(N+1) \\times d_{\\text{model}}}。多头注意力的优势在于综合多角度信息(类似不同人对图像的注意点),增强模型鲁棒性。
- 基本单元 :由 L 个相同 Block 堆叠而成,每个 Block 包含: \\begin{align\*} \\mathbf{z}'*l \&= \\text{MHA}(\\text{LN}(\\mathbf{z}*{l-1})) + \\mathbf{z}_{l-1} \\ \\mathbf{z}_l \&= \\text{MLP}(\\text{LN}(\\mathbf{z}'_l)) + \\mathbf{z}'_l \\end{align\*}
- 关键组件 :
- Multi-Head Attention (MHA):多头自注意力机制。
- MLP Block :两层全连接,中间含 GELU 激活: \\text{MLP}(\\mathbf{x}) = \\text{FC}*{4D}(\\text{GELU}(\\text{FC}*{D}(\\mathbf{x})))
- 归一化:采用 LayerNorm(LN),优于 BatchNorm。
- 正则化:Dropout 或 DropPath(后者效果更优)。
类别信息嵌入(Class Token)
ViT 仅使用Transformer的编码器部分(无解码器),因此需要专门的方式生成分类输入。为此,添加一个可学习的类别token(cls_token),这是一个额外向量,维度为 1 \\times d_{\\text{model}}。它与位置嵌入后的序列进行拼接(concatenation),序列长度变为 N+1:
- 输入序列: Z \\in \\mathbb{R}\^{N \\times d_{\\text{model}}}
- cls_token: C_{\\text{cls}} \\in \\mathbb{R}\^{1 \\times d_{\\text{model}}}
- 输出序列: Z_{\\text{cls}} = \\text{concat}(C_{\\text{cls}}, Z) \\in \\mathbb{R}\^{(N+1) \\times d_{\\text{model}}}
cls_token 在训练中学习,并作为整个序列的"总结"向量,用于后续分类。序列维度从 N \\times d_{\\text{model}} 扩展到 (N+1) \\times d_{\\text{model}}。
2.4 MLP Head
多层感知机头(MLP Head)用于分类
最终,从Transformer编码器输出的序列中提取cls_token对应的向量(位置为0),输入到MLP Head进行分类:
- 输入:cls_token向量 v_{\\text{cls}} \\in \\mathbb{R}\^{1 \\times d_{\\text{model}}}(从序列中取出)
- 处理:先应用层归一化,然后通过全连接层和激活函数(如GELU),最后输出分类概率。
- 输出:维度 \\mathbb{R}\^{1 \\times K},其中 K 是类别数。通过softmax函数获得概率分布。
数学上,MLP Head可表示为: y = \\text{softmax}(W_2 \\cdot \\text{GELU}(W_1 \\cdot \\text{LayerNorm}(v_{\\text{cls}}) + b_1) + b_2) 其中 W_1, W_2 是权重矩阵,b_1, b_2 是偏置。
- 预训练阶段:结构为 Linear → tanh → Linear。
- 微调阶段:简化为单个 Linear + Softmax。
3. 模型配置(ViT-B/16 示例)
| 参数 | 值 |
|---|---|
| Patch Size | 16 \\times 16 |
| Layers (L) | 12 |
| Hidden Size (D) | 768 |
| MLP Size | 3072(4 \\times D) |
| Heads | 12 |
数据流示例:
- 输入 224 \\times 224 \\times 3 → Patch Embedding → 196 \\times 768
- 拼接 Class Token → 197 \\times 768
- 加位置编码 → Transformer Encoder × 12 → 197 \\times 768
- 取 Class Token 输出 → MLP Head → 分类结果
4. Hybrid 架构
- 设计 :CNN(ResNet50)提取特征 + ViT 处理。
- ResNet50 改造:StdConv2d + GroupNorm + 调整 Block 分布(移动 stage4 至 stage3)。
- 输出:14 \\times 14 \\times 1024 → 1 \\times 1 卷积 → 14 \\times 14 \\times 768 → 展平为 196 \\times 768。
- 性能 :
- 少量微调时优于纯 ViT。
- 充分训练后(如 14 epochs),ViT-L/16 与 Res50+ViT-L/16 准确率趋近。
5. 关键结论
- 位置编码对性能提升显著(+3%),但编码方式(1D/2D)影响较小。
- LayerNorm + DropPath 的组合优化了训练稳定性。
- 纯 Transformer 在大规模预训练下可匹配 CNN-Transformer 混合模型性能。
ViT模型配置与超参数选择分析
Vision Transformer(ViT)是一种基于自注意力机制的视觉模型,它在图像识别任务中表现出色。以下我将基于您提供的信息,逐步分析模型配置、超参数选择、实验设计和领域影响,确保回答结构清晰、真实可靠。
1. ViT模型变体及其配置
ViT有多个变体,主要包括ViT-B/16(基础版)、ViT-L/16(大版)和ViT-H/14(超大版)。这些变体的主要区别在于模型深度和隐藏层维度:
- 模型深度:指Transformer编码器的层数,例如ViT-B/16的层数较少,而ViT-H/14的层数更多。
- 隐藏层维度:指每个注意力头的维度大小,维度越大,模型容量越高。
这些配置差异直接影响模型的参数量和计算复杂度。例如,ViT-B/16的参数量约为86.6百万,而ViT-H/14则高达633.5百万,这表明更大的模型能捕获更复杂的特征,但需要更多计算资源。
2. 超参数选择与优化
在训练ViT时,研究人员会根据数据集大小调整超参数,以优化模型性能。关键超参数包括:
- 学习率:用于控制参数更新的步长。对于小数据集,学习率通常较低(例如0.001),以避免过拟合;对于大数据集(如ImageNet),学习率可能更高(例如0.01),以加速收敛。
- 权重衰减:用于正则化模型,防止过拟合。权重衰减值通常在0.0001到0.01之间,具体值取决于数据集大小和模型复杂度。
- 其他超参数:如批量大小、优化器类型(常用Adam或SGD),这些也会根据GPU资源和数据分布进行调整。
实验表明,超参数的选择至关重要。例如,在ImageNet上,ViT通过调整学习率和权重衰减,实现了较高的准确率。当使用更大数据集(如ObjectNet)进行预训练时,ViT-H/14的性能显著提升,这得益于精细的超参数调优。
3. 实验设计分析
ViT的性能在多个基准测试中进行了评估,以下基于ImageNet和小样本学习设置进行分析。
ImageNet表现
在ImageNet数据集上,ViT变体的表现如下表所示(数据基于您提供的实验结果):
| 模型 | Top-1准确率 (%) | Top-5准确率 (%) | 参数量 (百万) |
|---|---|---|---|
| ResNet50 | 80.858 | 95.434 | 25.6 |
| ViT-B/16 | 81.072 | 95.318 | 86.6 |
| ViT-L/16 | 79.662 | 94.638 | 304.3 |
| ViT-H/14 | 88.552 | 98.694 | 633.5 |
分析:
- ViT-B/16在Top-1准确率上略高于ResNet50(81.072% vs. 80.858%),但参数量更大。
- ViT-H/14表现出最佳性能(Top-1 88.552%),尤其在更大数据集预训练下,Top-1准确率在ObjectNet上达到61.7%。这归因于其更大的模型容量和有效的超参数配置。
- 性能差异部分源于ViT的自注意力机制,它能更好地捕获全局特征,而ResNet依赖卷积操作。
小样本学习能力
在少量标注数据的情况下,ViT展现出强大的适应性:
- 相比于ResNet,ViT在few-shot学习设置下表现更优。随着训练样本数量增加,ViT的性能优势更明显,例如在样本数从n=10增至n=100时,准确率提升显著。
- 这可能源于ViT的自注意力机制能快速学习新任务的特征表示,而不依赖大量数据。
4. 领域影响
ViT的成功对计算机视觉领域产生了深远影响,推动了学术界和工业界的创新。
学术界与工业界反响
- 后续研究:ViT激发了多种改进变体,如DeiT(Data-efficient Image Transformers),它通过知识蒸馏等技术提高了数据效率。ViT还被扩展至其他任务,如目标检测(使用ViT作为骨干网络)和语义分割。
- 工业应用:ViT已成为工业级视觉系统的重要组件,例如在自动驾驶、医疗影像分析中应用广泛,因其高效处理高分辨率图像的能力。
CLIP 模型说明文档
模型概述
CLIP(Contrastive Language-Image Pretraining)由 OpenAI 研发,旨在探索计算机视觉模型的鲁棒性,并通过零样本学习(zero-shot)方式实现任意图像分类任务。该模型采用对比学习框架,通过最大化(图像,文本)对的相似性进行训练。
技术细节
- 架构特性 :
- 图像编码器:基于 ViT-L/14 的视觉 Transformer
- 文本编码器:掩码自注意力 Transformer
- 训练目标:对比损失函数 \\mathcal{L}_{\\text{contrastive}}
- 变体版本: 原始实现包含 ResNet 和 Vision Transformer 两种图像编码器,本文档对应 Vision Transformer 版本。
python
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(
text=["a photo of a cat", "a photo of a dog"],
images=image,
return_tensors="pt",
padding=True
)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 图像-文本相似度分数
probs = logits_per_image.softmax(dim=1) # 通过 softmax 获取类别概率
适用范围
- 主要用途 :
- 计算机视觉鲁棒性研究
- 零样本图像分类任务探索
- 跨模态表示学习分析
- 适用对象: 人工智能研究人员(非商业部署场景)
使用限制
-
非适用场景:
- 商业部署或未经验证的工业应用
- 监控、人脸识别等敏感领域
- 多语言任务(仅支持英语)
-
性能约束:
- 模型性能受分类体系影响显著
- 需针对具体任务进行领域内测试
训练数据
- 数据来源 :
- 公开网络爬取(过滤暴力/成人内容)
- 标准化数据集(如 YFCC100M)
- 数据偏差: 数据分布偏向互联网活跃群体(发达国家、年轻男性用户为主)
性能评估
模型在以下典型任务中表现优异:
- 细粒度分类(Food101)
- OCR 文本识别
- 纹理分类
- 跨模态检索
伦理声明
使用前需充分评估模型在特定场景下的偏差和局限性,严禁用于可能引发社会伦理问题的应用场景。
总结
ViT 将图像分类问题转化为序列处理问题:图像分割为块(序列化)→ 维度映射 → 添加位置和类别信息 → Transformer编码器提取特征 → MLP分类。关键创新在于使用Transformer处理图像块序列,避免了传统卷积神经网络(CNN)的归纳偏置,从而在大型数据集上表现优异。整个过程确保了高效率和可扩展性,公式和结构设计均与NLP Transformer高度一致。
对未来研究方向的影响
ViT展示了非卷积结构在视觉任务中的潜力,促进了新研究方向:
- 结合自注意力与卷积:研究者探索混合架构,以融合ViT的全局感知和CNN的局部特征提取优势。
- 数据规模的重要性:ViT强调了大规模预训练数据的必要性,推动了对数据增强、无监督学习的研究。
- 架构设计原则:ViT促使重新思考模型设计,例如如何优化Transformer的效率和可扩展性。
总之,ViT通过合理的模型配置和超参数选择,在图像识别任务中取得了突破性进展。其性能优势在小样本学习和大数据集上尤为明显,并对未来视觉模型发展产生了持久影响。如果您有具体问题或需要更深入的分析,请随时补充!
pythonimport torch from torch import nn from einops import rearrange, repeat from einops.layers.torch import Rearrange
主体结构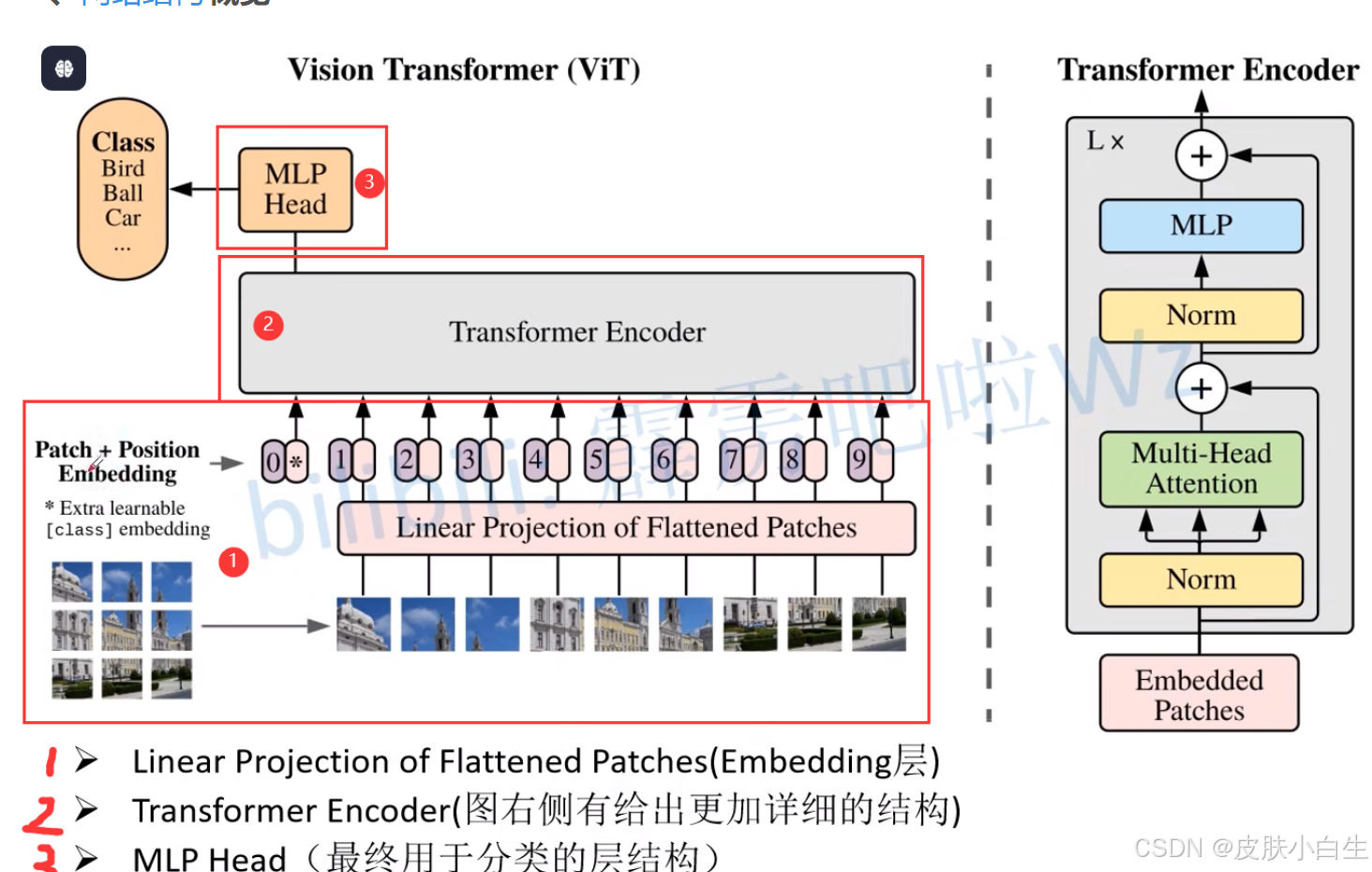
python
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)以下是针对Vision Transformer(ViT)模型实现的详细解析:
模型结构解析
Vision Transformer将图像分割为多个小块(patch),通过Transformer架构处理这些块序列。
1. 初始化参数
- 图像与块尺寸
设图像尺寸为H \\times W,块尺寸为P_h \\times P_w,需满足整除条件:H \\mod P_h = 0且W \\mod P_w = 0。 - 块数量计算
块总数n_p为: n_p = \\frac{H}{P_h} \\times \\frac{W}{P_w} - 块维度
每个块展平后的维度为d_p = C \\times P_h \\times P_w(C为通道数)。
2. 核心组件
python
# 块嵌入层:将图像重组为块序列
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_height, p2=patch_width),
nn.Linear(patch_dim, dim) # 映射到隐空间维度 dim
)
# 位置编码与类别标记
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) # 可学习位置编码
self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) # 分类标记
# Transformer编码器
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
# 分类头
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)3. 前向传播流程
-
块嵌入
输入图像X \\in \\mathbb{R}\^{B \\times C \\times H \\times W}通过
to_patch_embedding转换为块序列X_p \\in \\mathbb{R}\^{B \\times n_p \\times d}。 -
添加类别标记
将可学习的
cls_token复制B次并与块序列拼接: X_{\\text{cat}} = \[\\text{cls_token} \\parallel X_p\] \\in \\mathbb{R}\^{B \\times (n_p+1) \\times d} -
位置编码
加入位置编码E_{\\text{pos}}(截取前n_p+1个向量): X_{\\text{pos}} = X_{\\text{cat}} + E_{\\text{pos}}
-
Transformer处理
通过多层Transformer编码器: Z = \\text{Transformer}(X_{\\text{pos}})
-
池化与分类
- 选项1(cls):取第一个位置(类别标记)的输出:z_{\\text{cls}} = Z\[:,0\]
- 选项2(mean):对所有块取平均:z_{\\text{mean}} = \\frac{1}{n_p+1} \\sum_{i=0}\^{n_p} Z\[:,i\]
- 最终通过分类头预测:\\hat{y} = \\text{mlp_head}(z)
关键设计说明
- 位置编码:使用可学习参数,而非固定正弦函数。
- 池化策略 :
cls模式依赖类别标记,mean模式对所有块平均。 - 维度对齐 :
dim_head控制每个注意力头的维度d_h,满足d = \\text{heads} \\times d_h。
此实现完整遵循ViT的经典设计,适用于图像分类任务。
Transformer
python
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x这是一个标准的Transformer模块实现代码,主要用于自然语言处理任务。以下是对代码的详细解析:
1. 初始化函数 __init__
python
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads=heads,
dim_head=dim_head,
dropout=dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim,
dropout=dropout))
]))dim: 输入特征维度depth: Transformer层数(例如12层)heads: 多头注意力头数dim_head: 每个注意力头的维度mlp_dim: 前馈网络隐藏层维度- 结构说明 :
- 使用
nn.ModuleList构建多层结构 - 每层包含两个子模块:
PreNorm + Attention: 带前置层归一化的注意力机制PreNorm + FeedForward: 带前置层归一化的前馈网络
- 使用
2. 前向传播 forward
python
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x # 残差连接
x = ff(x) + x # 残差连接
return x- 遍历所有层
- 每层执行: \\begin{align} x \&= \\text{Attention}(x) + x \\ x \&= \\text{FFN}(x) + x \\end{align}
- 残差连接确保梯度有效传播
3. 关键组件
注意力机制:
- 核心计算: \\text{Attention}(Q,K,V) = \\text{softmax}\\left(\\frac{QK\^T}{\\sqrt{d_k}}\\right)V
- 多头实现: \\text{MultiHead}(Q,K,V) = \\text{Concat}(\\text{head}_1,...,\\text{head}_h)W\^O
前馈网络:
- 典型结构: \\text{FFN}(x) = \\text{ReLU}(xW_1 + b_1)W_2 + b_2
4. 数学表示
对于输入序列 X \\in \\mathbb{R}\^{n \\times d}:
- 注意力输出: Z = \\text{LayerNorm}(X + \\text{Attention}(X))
- 最终输出: Y = \\text{LayerNorm}(Z + \\text{FFN}(Z))
该实现遵循了Transformer的标准架构,适用于各种序列建模任务。
Attention
python
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)这个代码实现了一个基于多头注意力机制的模块,常用于Transformer架构中。下面我将逐步解析其结构和功能:
1. 初始化方法 (__init__)
python
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()参数说明:
dim:输入特征维度heads:注意力头数量(默认8)dim_head:每个注意力头的维度(默认64)dropout:Dropout概率
关键组件:
-
维度计算:
- 总特征维度: \\text{inner_dim} = \\text{heads} \\times \\text{dim_head}
- 缩放因子: \\text{scale} = (\\text{dim_head})\^{-0.5} (用于稳定梯度)
-
投影层:
to_qkv:通过单个线性层同时生成查询(Query)、键(Key)、值(Value) \\text{to_qkv}: \\mathbb{R}\^{d} \\to \\mathbb{R}\^{3 \\times (\\text{heads} \\cdot d_h)}to_out:输出投影层(含Dropout),当满足 \\text{heads}=1 且 d_h = d 时简化为恒等映射
2. 前向传播 (forward)
python
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)计算流程:
-
生成QKV:
pythonqkv = self.to_qkv(x).chunk(3, dim=-1) # 分割为[q,k,v]输入张量 \\mathbf{X} \\in \\mathbb{R}\^{B \\times N \\times d} 经线性变换后分割为三个张量
-
多头重组:
pythonq, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.heads), qkv)重塑张量维度: \\mathbb{R}\^{B \\times N \\times (h \\cdot d_h)} \\to \\mathbb{R}\^{B \\times h \\times N \\times d_h}
-
注意力计算:
pythondots = torch.matmul(q, k.transpose(-1, -2)) * self.scale attn = self.attend(dots) # softmax归一化计算过程: \\text{Attention}(\\mathbf{Q},\\mathbf{K},\\mathbf{V}) = \\text{softmax}\\left( \\frac{\\mathbf{Q}\\mathbf{K}\^\\top}{\\sqrt{d_k}} \\right)\\mathbf{V}
-
输出处理:
pythonout = rearrange(out, 'b h n d -> b n (h d)') # 合并多头 return self.to_out(out) # 投影输出最终输出维度保持与输入一致: \\mathbb{R}\^{B \\times N \\times d}
3. 数学表示
给定输入 \\mathbf{X} \\in \\mathbb{R}\^{B \\times N \\times d} :
- 生成投影矩阵: \\mathbf{Q}, \\mathbf{K}, \\mathbf{V} = \\text{split}(\\mathbf{X}\\mathbf{W}_{qkv})
- 缩放点积注意力: \\mathbf{A} = \\text{softmax}\\left( \\frac{\\mathbf{Q}\\mathbf{K}\^\\top}{\\sqrt{d_k}} \\right)
- 加权输出: \\mathbf{Z} = \\mathbf{A}\\mathbf{V}
- 输出投影: \\mathbf{Output} = \\mathbf{Z}\\mathbf{W}_o
该模块完整实现了标准的多头注意力机制,适用于各类序列建模任务。
Transformer 中的注意力机制详解(QKV计算过程)
1. 向量点乘与相似度计算
向量点乘(Dot Product)
向量点乘是衡量两个向量之间相似度的基础方法。给定两个n维向量\\vec{a}和\\vec{b},其点乘计算为: \\vec{a} \\cdot \\vec{b} = \\sum_{i=1}\^{n} a_i b_i = \|\\vec{a}\| \|\\vec{b}\| \\cos\\theta 其中\\theta是两个向量之间的夹角。点乘结果具有以下性质:
- 正值表示向量方向相似(夹角小于90度)
- 零值表示向量正交(夹角等于90度)
- 负值表示向量方向相反(夹角大于90度)
在实际应用中,点乘计算可以通过高效的矩阵乘法实现,这对Transformer的大规模计算至关重要。
相似度计算示例
考虑两个3维向量: \\vec{a} = \[1, 2, 3\], \\quad \\vec{b} = \[4, 5, 6\] 计算过程:
- 逐元素相乘:1×4=4,2×5=10,3×6=18
- 求和:4 + 10 + 18 = 32
这个较大的正值表明两个向量在方向上较为接近。如果计算\\vec{a}和-\\vec{b}的点乘,结果将是-32,表示方向相反。
在实际的注意力机制中,这种点乘计算会扩展到矩阵形式,同时计算多个向量对之间的相似度。
2. QKV机制详解
QKV的角色定义
在注意力机制中,三个核心矩阵具有特定语义:
-
Query (Q):表示当前需要关注的内容,相当于信息检索中的"问题"。例如在处理句子"The animal didn't cross the street because it was too tired"时,"it"对应的Query会用来查找其指代对象。每个位置的词都会生成自己的Query向量,用于主动"询问"应该关注哪些其他位置的信息。
-
Key (K):表示可供匹配的特征,相当于信息检索中的"索引键"。每个词都会生成自己的Key,用于与Query匹配。Key可以看作是词的特征表示,决定了它如何响应各种Query。
-
Value (V):表示实际包含的信息内容。当Query与某个Key匹配度高时,对应的Value信息会被更多地提取。Value包含了词的语义信息,是最终被聚合的内容。
生成过程
给定输入序列X \\in \\mathbb{R}\^{n \\times d_{model}}(n个词,每个词d维向量),通过三个可学习权重矩阵生成QKV:
Q = X W\^Q \\quad (W\^Q \\in \\mathbb{R}\^{d_{model} \\times d_k}) \\ K = X W\^K \\quad (W\^K \\in \\mathbb{R}\^{d_{model} \\times d_k}) \\ V = X W\^V \\quad (W\^V \\in \\mathbb{R}\^{d_{model} \\times d_v})
其中d_k和d_v是超参数,通常设置d_k = d_v = d_{model}/h(h为注意力头数)。这些权重矩阵在训练过程中学习,决定了如何从输入表示中提取Query、Key和Value特征。
3. 注意力计算完整流程
(1) 相似度矩阵计算
计算Query与所有Key的点积相似度:
\\text{Similarity} = Q K\^T \\in \\mathbb{R}\^{n \\times n}
每个元素S_{ij}表示第i个Query与第j个Key的相似度。这个矩阵反映了序列中每个位置对其他位置的关注程度。
(2) 缩放与归一化
缩放:为防止点积结果过大导致softmax梯度消失,除以\\sqrt{d_k}: S_{scaled} = \\frac{Q K\^T}{\\sqrt{d_k}}
Masking(可选):在解码器中,为避免未来信息泄露,会添加掩码使得i\>j的位置为-\\infty。这确保了解码时只能关注已生成的部分。
Softmax归一化: A = \\text{softmax}(S_{scaled}) 对每一行进行softmax,确保\\sum_j A_{ij} = 1。这使得注意力权重形成一个概率分布,表示每个位置对当前Query的相对重要性。
(3) 加权求和
将注意力权重应用于Value矩阵:
\\text{Output} = A V \\in \\mathbb{R}\^{n \\times d_v}
这个步骤实现了根据相似度对信息的有选择聚合。例如,在处理代词"it"时,权重矩阵可能会给"animal"和"street"分配较高权重,但最终因为与"animal"的相似度更高而主要聚合其对应的Value信息。这种机制使得模型能够动态地关注最相关的上下文信息。
4. 多头注意力机制
实现细节
投影到子空间: 将Q、K、V分别通过h个不同的线性变换: Q_i = Q W_i\^Q, \\quad K_i = K W_i\^K, \\quad V_i = V W_i\^V 其中W_i\^Q, W_i\^K \\in \\mathbb{R}\^{d_{model} \\times d_k}, W_i\^V \\in \\mathbb{R}\^{d_{model} \\times d_v}
并行计算: 在每个头上独立计算注意力: \\text{head}_i = \\text{Attention}(Q_i, K_i, V_i)
拼接与线性变换 : 将所有头的输出拼接后通过最终投影: \\text{MultiHead} = \\text{Concat}(\\text{head}*1, ..., \\text{head}h) W\^O 其中W\^O \\in \\mathbb{R}\^{h \\cdot d_v \\times d*{model}}
多头优势
- 每个头可以学习不同的注意力模式(如局部/全局、语法/语义等)
- 在翻译任务中,某些头可能专注于位置信息,另一些关注词性关系
- 实验表明,不同头确实会自发地关注不同类型的关系
- 增加了模型的表达能力,允许同时捕捉多种依赖关系
- 通过并行计算保持效率,不会显著增加计算复杂度
5. QKV设计原理
类比信息检索系统
| 组件 | 信息检索 | 注意力机制 |
|---|---|---|
| Query | 搜索关键词 | 当前需要关注的内容 |
| Key | 文档索引 | 可供匹配的特征 |
| Value | 文档内容 | 实际信息表示 |
设计优势
-
解耦匹配与内容:
- Key只需负责匹配,Value负责携带信息,各司其职
- 这种分离允许模型学习更专业的特征表示
-
灵活的信息聚合:
- 通过softmax实现软性注意力,而非硬性选择
- 可以同时关注多个相关位置,按重要性分配权重
-
可并行计算:
- 矩阵运算形式非常适合GPU加速
- 整个注意力计算可以表示为一系列矩阵乘法
实际应用示例
在机器翻译中:
- 当解码器处理"bank"时,Query会同时与"river"和"money"的Key计算相似度
- 根据上下文,可能同时激活金融和地理两种含义的Value
- 最终的表示会是两种意义的加权组合,由上下文决定主导含义
- 这种机制有效解决了自然语言中的一词多义问题
在文本摘要任务中:
- 生成每个词时,Query会寻找原文中最相关的部分
- 重要的句子会获得更高的注意力权重
- 模型可以动态地聚焦于不同部分的原文信息