联合隐空间
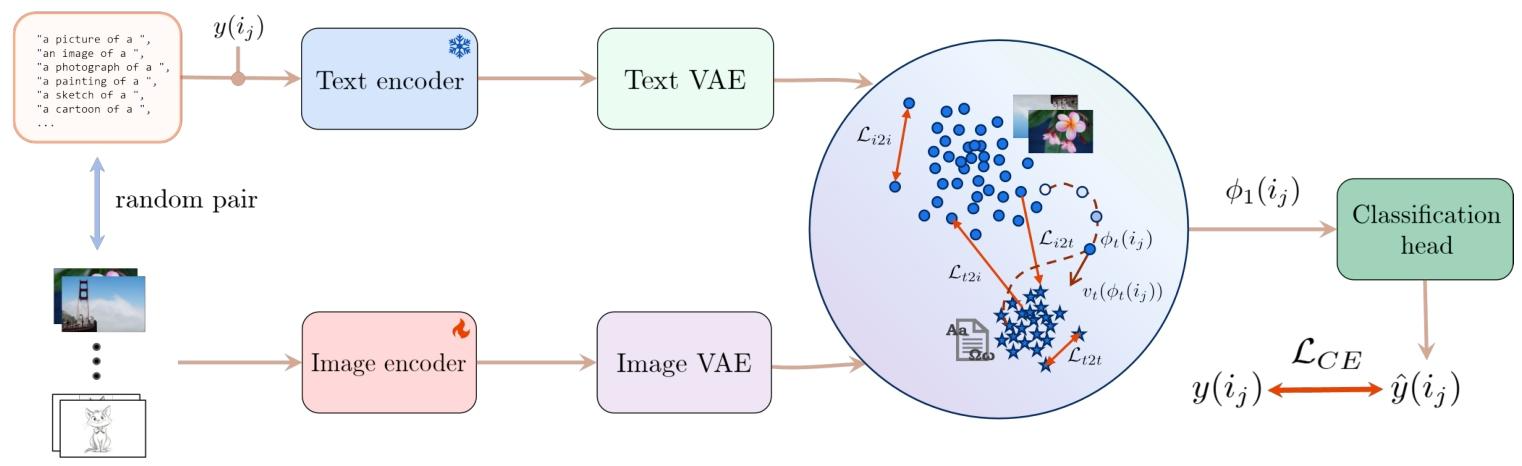



Joint Latent Space定义
联合隐空间 = 把图像、文本(或多种模态),压缩映射到同一个低维抽象空间里
让不同类型的数据能用同一套坐标、距离规则来比较、对齐
图像:图片数据
文本:文字数据
隐空间:VAE 压缩后的抽象特征空间(不是原始像素 / 文字)
联合:图像、文本共用一套空间,不再是两个独立空间
普通分开隐空间(不联合)
图像 VAE → 图像隐空间
文本 VAE → 文本隐空间
两个空间完全独立,坐标、距离不互通,没法直接比,模态鸿沟
联合隐空间(核心)
强制图像、文本,映射到同一个空间:
图像特征、文本特征,都落在同一个高维球 / 欧氏空间里,可以直接算距离、做对齐
L_i2t 图像→文本损失,模态鸿沟直接被抹平
四个损失函数的计算




ϕi
英文标准读法名称:phi音标:/faɪ/(和英文单词 fly 押韵)
中文通用译法斐 / 普西 / 菲(深度学习领域最常读 斐)

L_i2t 和 L_t2i 的结果是否一样
虽然数值一样,但反向传播更新的网络不同:
L_i2t:主要更新图像编码器,让图像特征往文本靠
L_t2i:主要更新文本编码器,让文本特征往图像靠
通俗举例
只有 L_i2t:图像拼命往文本贴,文本一动不动,文本锚点太死板
加上 L_t2i:双向互相靠近,文本也会微调,让对齐更灵活、更稳定
L_i2t 含义


为啥不是图像向量映射到文本向量
因为要用文本当 "稳定锚点",去矫正图像
如果反过来,把图像映射到文本空间,文本不动、图像动,解决不了领域偏移问题
文本向量:超级稳定
不管猫长啥样,a photo of cat 语义永远是猫,不受画风、环境干扰
图像向量:超级不稳定
照片猫、素描猫、油画猫,特征差别巨大,领域偏移很严重
两种选择
方案 A:文本映射进图像空间,文本变灵活一点,用稳定的文本,拉着所有画风的图像往猫靠拢。抹平领域偏移,完美实现领域泛化
方案 B:图像映射进文本空间,文本死死不动,图像拼命往文本贴。会导致图像特征被强行压成一样,丢失细节,泛化能力变差
通俗类比
文本 = 家长(标准答案,稳定不动)
图像 = 一群调皮学生(各种画风猫,乱跑)
现在做法:家长走进学生圈子(文本映射进图像空间)
家长在学生堆里,把乱跑的学生一个个拉回队伍学生再调皮,都被拉成一类 → 抹平差异
反过来做法:学生全部冲进家长家里(图像映射进文本空间)
家长站死不动,学生全部硬挤进去学生之间差异直接被抹掉,模型学不到细节,测试不行
技术上真正的原因
图像空间:维度大、自由度高,能容纳各种画风、领域变化
文本空间:维度固定、语义刚性,空间太死板
把图像塞进文本空间,空间太挤,图像多样性直接丢失把文本塞进图像空间,空间足够大,还能约束图像聚拢
损失的介绍


τ,名称:tau;音标:/taʊ/
penalize ˈpiːnəlaɪz v. 使处于不利地位,不公正地对待;处罚,惩罚,处以刑罚;(体育运动中)判罚
This explicitly penalizes the network for relying on domain-specific shortcuts
这一做法会明确惩罚网络,使其不能依赖特定领域的捷径特征
shortcuts:捷径特征、投机特征,快捷方式
intra-class variance 类内方差
intra 内的,在内的
align the modality distributions of the same class 同类别的模态分布对齐
projection heads that project uni-modal features into a shared latent space
将单模态特征投影到共享隐空间的投影头
uni-modal 单模态的

难正样本对(Hard Positive Pairs)------ 简单说就是:语义上是同一类,但特征长得很不一样、模型很难判断是 "正样本" 的配对
什么是投影头(Projection Head)
backbone ˈbækbəʊn
n. 脊骨,脊柱;支柱,骨干;骨气,毅力;<美>书脊;(聚合分子的)主链;主干网络
投影头 = 一层简单的神经网络(通常是 2 层全连接),专门把单模态特征,"挪到 / 对齐到" 共享(联合)隐空间
v_t 本质就是文本模态的投影头
专门用来把图像、文本各自的原始特征,映射到同一个联合隐空间的小网络层
为什么叫 "头"?
主干网络(backbone):VAE 编码器,负责提取原始单模态特征
头(head):接在主干最后面的小网络,像 "帽子" 一样扣在后面,所以叫投影头
InfoNCE

模态 k→模态 l 的对比学习损失:让同一张样本的两个模态特征(正样本)相似度尽可能大,让批量里其他所有样本的模态特征(负样本)相似度尽可能小
k = 图像模态,l = 文本模态
L_k2l = 图像到文本的 InfoNCE 对比损失

假设一个批次有 3 张图:猫、狗、狐狸,取猫的图像特征
正样本:猫的文本
负样本:狗的文本、狐狸的文本
InfoNCE 做的事:
强制让猫图 ↔ 猫文本最匹配,猫图 ↔ 狗文本、猫图 ↔ 狐狸文本尽可能不匹配