第一节:介绍
1 课程概述
本课程是 DeepLearning.AI 与 Anthropic 合作打造的 Agent Skills 专项课程,由回归讲师 Elie Schoppik 主讲。
在本课程中,我们将探讨 Skills 如何赋能 Claude 及其他 AI 智能体执行复杂任务。技能通过向智能体提供专门的指令和知识来扩展其能力。
- 理解 Skills 的工作原理
- 掌握创建 Skills
- 构建适用于不同场景的 Skills(包括编程、研究、数据分析等)
2 什么是 Skills ?
2.1 什么是 Agent Skills?
Agent Skills 是一种扩展智能体能力的模块化指令集合。通过技能,Claude 和其他 AI 智能体可以获得执行特定任务的新能力。
Skills 是文件夹形式的指令集合,用于扩展智能体的能力,赋予其专门的知识来执行任务。
2.2 Skills 的核心特点
- 开放标准:Skills 现在是一个开放标准,采用标准化格式,可与任何兼容的智能体产品配合使用
- 一次构建,多处部署:你可以构建一次技能,然后在多个智能体产品中部署使用
- 渐进式披露:技能的名称和描述始终存在于智能体的上下文窗口中,但只有当用户请求与技能描述匹配时,才会加载其余指令
3 使用 Skills 所需的工具
智能体需要以下基本工具集来使用技能:
- 文件系统访问:读取和写入文件
- Bash 工具:执行代码
这些工具使智能体能够执行技能所需的任何命令。
3.1 工具来源和使用方式
模式一:自研AI应用
实现方式:开发者需手动实现文件系统工具和Bash工具
特点:从零构建,完全自主控制
示例代码:自行编写 class MyBashTool、class MyFileSystemTool
模式二:基于框架(如LangChain)实现方式:框架内置了文件系统工具和Bash工具的插件
使用流程:在 tools 列表中添加框架提供的现成工具 -> 应用部署上线 -> 用户创建针对业务SOP的SKILL文件夹 -> Agent内部自动调用文件系统工具和Bash工具来执行文件读写或Python脚本
python
from langchain.agents import AgentExecutor
from langchain.tools import BashTool, FileSystemTool
# 框架自带 Bash 和文件系统工具
tools = [
BashTool(),
FileSystemTool(),
# 加上你的技能工具
YourSkillTool()
]模式三:成熟产品(如Claude Desktop)
- 实现方式:产品内部已内置文件系统工具和Bash工具
- 使用流程:用户只需上传SKILL文件夹,无需关心底层实现,Claude自动完成文件读写和Python脚本执行
核心结论三种模式本质相同,均遵循Agent-Skills范式:以标准化的SKILL.md作为唯一输入,底层工具实现与上层技能描述解耦,确保技能描述文件具有跨平台可移植性
4 Skills 的组合使用
智能体可以将 Skills 与 MCP 和 子智能体 结合,创建强大的智能工作流:
| 组合方式 | 说明 |
|---|---|
| Skills + MCP | 使用 MCP 从外部源获取数据,然后依靠技能来处理数据或高效检索数据 |
| Skills + 子智能体 | 将任务委托给具有隔离上下文的子智能体,子智能体本身也可以使用技能获取专业知识 |
5 课程内容概览
本课程将涵盖以下内容:
-
Claude AI 入门
- 创建一个营销活动技能
- 结合预建的 Excel 和 PowerPoint 技能
-
内容创建和数据分析工作流
- 创建两个技能
- 使用 Claude API 进行测试
-
Claude Code 代码审查
- 使用技能进行代码审查和测试
-
研究智能体构建
- 使用 Claude Agent SDK 构建研究智能体
- 使用技能整合研究结果
6 何时使用 Skills?
当你有一个反复要求智能体实现的工作流时,与其每次都解释相同的工作流,不如将其打包成一个技能,让智能体自动知道该做什么。
第二节:Skills 的意义
1 Skills 是什么
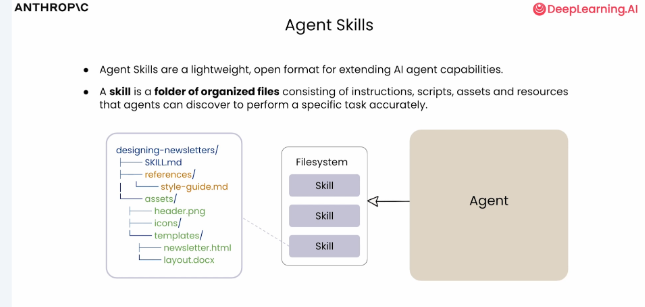
- 一种轻量、开放的格式,用于扩展 AI agent 能力
- 一个组织好的文件夹,由以下部分组成:
- 指令 | Instructions
- 脚本 | Scripts
- 资产与资源 | Assets and resources
2 在哪里用 Skills ?
2.1 Skills 的用武之地
- 领域专业知识 | Domain Expertise
- 可重复的工作流程 | Repeatable Workflow
- 新能力 | New Capabilities
2.2 使用场景
- 领域专业知识
- 品牌规范与模板
- 法务审核流程
- 数据分析方法论
- 可重复的工作流程
- 每周营销活动复盘
- 客户电话准备流程
- 季度业务复盘
- 新能力
- 制作演示文稿
- 生成 Excel 表或 PDF 报告
- 搭建 MCP 服务器
2.3 没有 Skills 会怎样
- 每次都要重新描述指令与需求
- 每次都要重新打包参考资料与支持文件
- 难以保证流程或产出始终一致
3 渐进式披露
渐进式披露 一种层级化的信息组织与加载策略,核心思想是按需、分层次地向AI智能体暴露信息,以优化上下文窗口利用效率
渐进式披露的三层模型:
├── 第一层:元数据(Metadata) → 始终加载
├── 第二层:指令(Instructions) → 触发时加载
└── 第三层:资源(Resources) → 按需加载1.YAML前置元数据(始终加载)
加载策略 :始终加载到系统提示(System Prompt)中
目的 :给AI智能体提供全局上下文,使其知道有哪些能力可用
类比:图书的目录和索引------无需阅读全书,但知道书里有什么内容
# 示例:SKILL.md 的 YAML 头
---
name: marketing_analysis
description: 分析多渠道数字营销数据,计算转化漏斗、效率指标,并给出预算调整建议。
inputs:
- file: Excel/CSV,包含 Date, Campaign_Name, Channel, Impressions, Clicks, Conversions, Spend, Revenue, Orders 等字段
outputs:
- Markdown/Excel 表格,含各项指标与建议
version: 1.0.0
author: analyst_team
---2.Markdown正文(触发时加载)
加载策略 :触发时加载------当智能体识别到用户意图匹配该技能时,才将完整指令注入上下文
目的 :避免一次性加载所有SOP占满上下文窗口,节省token
类比:用户点击目录中的章节标题,才翻开对应页面阅读
## 输入
- 数据源:Google Analytics 导出CSV
- 时间范围:最近30天
## 漏斗指标(按渠道)
- 展示量 → 点击量 → 转化率
## 效率指标(按渠道)
- CPA(单次获客成本)
- ROAS(广告支出回报率)
## 输出表格
| 渠道 | 展示量 | 点击量 | 转化率 |
|------|--------|--------|--------|
| SEO | | | |
## 预算重新分配
- 基于ROAS优化分配策略3. 资源文件(按需加载)
加载策略 :按需加载------只有当执行流程需要具体数据或脚本时,才读取对应资源
目的 :进一步优化资源利用,避免加载未使用的文件
类比:引用参考文献时,才去书架取那本书
resources:
- data/template.csv # 模板文件
- scripts/calculate_roas.py # 计算脚本
- config/budget_rules.yaml # 预算规则4 Excel Skills 在AI智能体中的实现
痛点场景 :重复向Claude下达Excel数据分析指令(清洗规则、图表样式、公式模板),每次都要重复沟通
Skills解决⽅案 :将Excel数据分析全流程封装为Skills,包含:数据清洗规范、常⽤公式、图表模板、异常值处理规则
核⼼收益 :⼀次封装、永久复用,AI⾃动遵循标准,无需人工干预,提升⼀致性和效率
实操演示 :Claude.ai中调用预置
Excel Skills,完成营销数据自动化分析
4.1 目录结构与文件说明
# 基础目录结构(以营销分析为例)
analyzing-marketing-campaign/
├── SKILL.md
└── references/
└── budget_relocation_rules.md
# 完整目录结构(Excel技能)
excel-skill/
├── SKILL.md # 主说明文档,描述 Skill 用途、输入输出、核心流程
├── scripts/ # 可执行脚本目录
│ ├── process_data.py # 数据处理脚本
│ └── recalc.py # 公式重算脚本
└── references/ # 参考文件目录,存放参考规则、模板、辅助文档等
├── example_input.xlsx # 输入样例
├── output_template.xlsx # 输出模板
└── rules.md # 规则说明文档4.2 SKILL.md 内容
SKILL.md 通常包含 YAML Frontmatter(元数据区块),以及详细的任务描述、输入输出格式、核心指标和操作流程。例如:
markdown
---
name: analyzing-marketing-campaign
description: 分析多渠道数字营销数据,计算转化漏斗、效率指标,并给出预算调整建议。
inputs:
- file: Excel/CSV,包含 Date, Campaign_Name, Channel, Impressions, Clicks, Conversions, Spend, Revenue, Orders 等字段
outputs:
- Markdown/Excel 表格,含各项指标与建议
---
## 任务流程
1.读取 Excel/CSV 数据。
2.计算各渠道 CTR(点击率)、CVR(转化率)。
3.计算 ROAS(广告回报率)、CPA(获客成本)、净利润等效率指标。
4.输出对比表格,生成分析解读与预算建议。
## 公式示例
-CTR% = Clicks / Impressions * 100
-CVR% = Conversions / Clicks * 100
-ROAS = Revenue / Spend
-CPA = Spend / Conversions
-Net Profit = Revenue - (Spend + 其它成本)4.3 Excel Skills 的实现与案例
4.3.1 常见 Excel 自动化任务
- 数据汇总与统计(如销售总额、最大单笔交易)
- 条件格式化(如根据状态标记行颜色)
- 多表合并(如客户与订单表按 ID 合并)
- 批量文件生成(如根据模板自动生成邀请函、产品文档)
- 数据过滤、排序与导出
4.3.2 Excel Skill 实现的技术路线
工具选择
- pandas:适合批量数据处理、分析、导出
- openpyxl:适合复杂格式、公式、Excel 特性操作
工作流程
- 选择工具:根据需求选择 pandas 或 openpyxl
- 创建/加载文件:新建或读取工作簿
- 数据处理:增删改查、公式、格式化
- 保存文件:写回 Excel
- 公式重算:如涉及公式,需用 recalc.py 脚本进行重算(openpyxl 仅写入公式字符串,不计算结果)
- 错误校验与修复:Skill 应返回 JSON 报告所有错误类型和位置,便于二次修正
实践建议与最佳实践
- 明确 Skill 的输入输出标准,示例文件放在
references目录- 所有脚本应有
异常处理与错误报告能力,便于 Agent 自动修复- 复杂逻辑建议
分模块实现,主流程在 SKILL.md 中清晰描述- Excel 公式相关操作建议
分离脚本处理,避免直接在 openpyxl 中计算- 尽量输出
中间结果与最终数据,便于人工或 Agent 二次校验
5 总结
Skills 为 AI Agent 提供了专业化、标准化、可复用的能力扩展载体,极大提升了自动化办公与复杂数据处理的效率。
Excel Skill 作为典型案例,通过 SKILL.md 元数据、脚本与参考文件的组合,实现了从数据读取、处理、输出到结果校验的自动化全流程。未来,随着 Skill 生态丰富,AI Agent 将能像积木一样组合各种能力,满足更多元的业务需求。
第三节:从 Agent 角度思考 Skills
Agent核心痛点:通用大模型无领域知识、复杂任务易偏离、长上下文易迷失;
Skills如何赋能Agent:
- 赋予领域专业知识(如前端开发、科研、财务分析);
- 固化标准工作流,避免任务拆解混乱;
- 隔离上下文,减少无关信息干扰;
对比Prompt与Skills:Prompt是临时指令,Skills是Agent的"长期记忆"和"行为准则"
第四节:Skills vs Tools, MCP, and Subagents
1 智能体生态系统概览
在智能体生态系统中,各种技术如 MCP、Skills、Tools 和 Subagents 共同协作:
- MCP 服务器:提供所需的上下文
- Subagents:用于多线程和并行处理
- Skills:用于可重复的主线程工作流
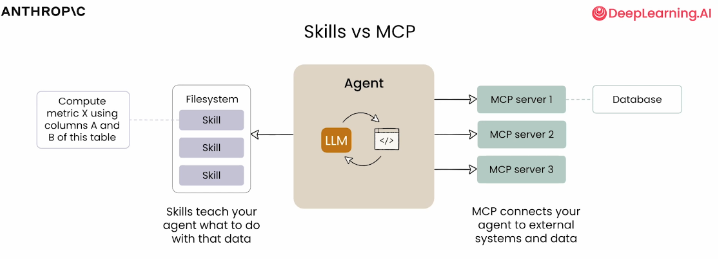
2 Skills vs MCP
| 对比维度 | MCP | Skills |
|---|---|---|
| 核心功能 | 连接智能体与外部系统和数据 | 定义可重复的工作流 |
| 数据来源 | 外部数据库等 | 利用 MCP 提供的工具和数据 |
| 使用场景 | 获取模型不知道的外部数据 | 教智能体如何处理这些数据 |
- MCP 就像带来所有底层工具和资源的连接器,当利用外部数据计算指标、研究和计算数据时,所有底层工具和资源都可以通过 MCP 服务器外部提供
- Skills 就像使用这些工具构建特定工作流的可重复流程
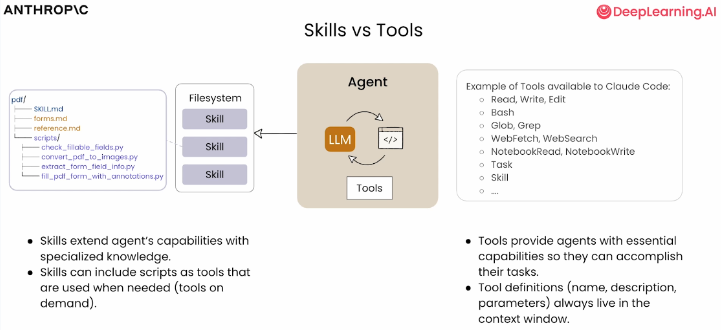
3 Skills vs Tools
想象你有一些工具:锤子、锯子和钉子。
你有一个技能:如何建造书架。
区别
| Tools(工具) | Skills(技能) |
|---|---|
| 提供访问文件系统的方式 | 扩展智能体的能力,提供专业知识和指令 |
| 提供底层能力来生成、读取技能 | 引入需要执行的额外文件和脚本 |
| 支持文件编辑、执行代码、加载技能 | 创建可预测的工作流 |
重要特性
- 工具定义(名称、描述、参数)始终存在于上下文窗口中
- 技能是渐进式加载的,只在需要时加载
- 如果某个工具不是每次对话都需要,通过仅在需要时加载可以节省大量 token
4 Skills vs Subagents
什么是Subagents?
Subagent 是一种为执行单一、明确定义的任务而专门构建的特化 AI Agent。它并非孤立工作,而是通常在一个 Orchestrator(编排器)的协调下,与其他 Subagent 协同完成复杂的用户请求。
Subagents 在多智能体系统中扮演着重要角色,它们通过专业化分工、独立上下文、可定制性和多种交互模式,提升了开发效率和代码质量
4.1 Subagents 的工作方式
主智能体可以生成或创建Subagents,子代理可以向父智能体报告。这些子代理可以通过以下方式创建:
- Claude Code
- Agent SDK
- 自定义实现
4.2 Subagents 的价值
| 特性 | 说明 |
|---|---|
| 隔离上下文 | 提供独立的上下文环境 |
| 有限权限 | 限制工具使用权限 |
| 技能访问 | 每个子代理可以访问特定的技能 |
4.3 应用场景
主智能体可以作为编排器,利用所需的技能。子代理可以实现相同理念,使用特定技能。
示例:一个专门的代码审查子代理,其唯一任务是分析和审查代码库,并利用技能来指定你、你的团队或公司如何进行代码审查。
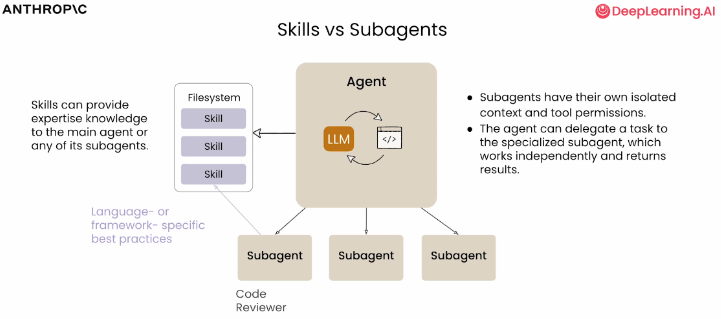
4.4 Subagents拆分模式
模式1:由「预置Skill」强制拆分 (适合标准化业务)
优势:完全可控,适合标准化的重复业务,不会出现Agent乱拆分任务的情况,适合企业内部的流程自动化
用户需求 → 加载预置Skill → Skill内置了固定的子任务拆分规则 → Agent按照Skill的规则自动启动对应Subagents
你提前写好了一个企业月度财报生成Skill,这个Skill已经提前定义好了拆分步骤:
启动「财务数据查询Subagent」:负责调用MCP拉取远程数据库的销售、库存数据
启动「财报计算Subagent」:负责调用本地Python工具计算利润率、营收增长率等指标
启动「财报文案生成Subagent」:负责将计算结果整理成正式财报文本
启动「文件导出Subagent」:负责将结果保存为PDF文件
当用户发起「生成4月财报」的需求时,Agent会直接加载这个Skill,按照Skill提前写好的拆分规则,自动启动4个分工明确的Subagents,不需要临时推理拆分模式2:由「Agent自主推理拆分」 (适合非标准化复杂业务)
适配场景:适合非标准化的开放型任务,比如用户提出的需求没有固定流程,需要Agent自主决策
用户需求 → Agent自主理解任务复杂度 → 通过大模型推理,自动拆分为多个子任务 → 为每个子任务启动对应的Subagents
用户说「帮我策划一场周末的亲子露营活动」,Agent没有预置的「露营策划Skill」,它会自主推理拆分:
启动「场地查询Subagent」:调用MCP拉取周边露营地的信息
启动「物资采购Subagent」:调用本地电商API查询露营装备的价格和库存
启动「天气查询Subagent」:调用第三方天气API确认周末的天气情况
启动「文案整理Subagent」:将所有信息整理成完整的露营方案
Agent是通过大模型的上下文推理能力来完成拆分的,它会自己判断需要哪些能力的Subagents,甚至可以动态创建新的Subagents,不需要提前预置Skill实际生产中,很少会只用一种模式,大部分场景都是 「预置Skill作为基础框架,Agent在Skill的框架内自主调整拆分」:
- 你提前写好一个「通用财报生成Skill」,定义了必须包含「数据查询→计算→文案→导出」四个步骤
- 当用户需要生成4月财报时,Agent会按照Skill的框架启动四个Subagents
- 但如果用户额外要求「增加用户留存率指标」,Agent会自主推理,额外启动一个「留存率计算Subagent」,在Skill的框架内动态调整拆分逻辑
4.5 Subagents实现方式
官方提供了两种轻量化和分布式两种方案,完全可以根据你的需求选择:
- 轻量版:单Claude实例内部动态拆分Subagents(90%开发者用这个)
- 分布式版:多Claude实例跨服务器协作(复杂企业级场景)
方案1:轻量版Subagents (单Claude实例实现,无需额外部署)这是Claude官方最推荐的入门方案,完全不需要部署多个Claude服务,只用一个Claude API密钥就能实现Subagents,所有逻辑都运行在你的本地服务器或者云函数上
核心原理
Claude本身自带多智能体推理能力,你只需要通过
提示词告诉Claude:
- 你需要拆分任务为多个子任务
- 为每个子任务分配专属的「角色」(比如数据库查询专员、数据分析专员)
- 让每个子角色自主调用工具/API完成任务
- 最后汇总所有子角色的结果
方案2:分布式Subagents (多Claude实例跨服务器协作,对应你的疑问)当你的任务复杂度极高,需要多个独立的Agent服务分别处理不同的子任务,并且每个子Agent都需要调用专属的Claude模型(比如有的用Sonnet处理文本,有的用Opus处理复杂推理),这时候才需要部署多个Claude实例在不同服务器上
┌─────────────────────────────────────────────────────────┐
│ 主调度Agent服务(部署在服务器A) │
│ 角色:接收用户需求,拆分任务,调用各个子Agent的API │
│ 调用的Claude模型:claude-3-sonnet │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ 数据库查询子Agent服务(部署在服务器B) │
│ 角色:调用MCP拉取远程数据库数据,用Claude处理查询逻辑 │
│ 调用的Claude模型:claude-3-sonnet │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ 数据分析子Agent服务(部署在服务器C) │
│ 角色:用Claude Opus处理复杂的指标计算逻辑 │
│ 调用的Claude模型:claude-3-opus │
└─────────────────────────────────────────────────────────┘| 对比维度 | 单Claude实例内部动态拆分Subagents | 分布式多Agent跨服务器部署 |
|---|---|---|
| 实现工具 | 直接用Claude官方Web应用/API控制台 + 提示词模板 + Skills | 必须用Claude API密钥+ 自主编写代码 + 云服务器部署 |
| 开发成本 | 极低,5分钟就能跑通Demo | 较高,需要懂API调用、服务部署、网络配置 |
| 适用场景 | 90%的标准化业务场景:比如客服、内容生成、简单数据分析 | 复杂企业级业务:多团队协作、跨系统调用、高并发、安全隔离 |
| 可控性 | 弱:所有逻辑都在Claude内部,无法自定义工具、无法限制子Agent权限 | 强:可以完全自定义每个子Agent的能力、权限、部署环境 |
5 总结
原生大语言模型(LLM)只能生成文本,无法直接执行真实操作、访问外部数据,所有智能体Agent的能力扩展都依赖三类组件
| 组件 | 定位 | 运行位置 | 核心作用 |
|---|---|---|---|
| Skills | 智能体的工作流大脑 | 和Agent同环境 | 是封装好的垂直领域任务模板,包含任务说明、执行逻辑、参考资料,教会Agent「应该做什么、按什么流程做」,可以快速让通用Agent落地到特定业务场景 |
| Tools | 智能体的本地执行手脚 | 和Agent同运行环境 | 为LLM提供本地原生操作能力,比如执行Python脚本、读写本地文件、调用本地计算器,让Agent可以完成本地轻量操作 |
| MCP(模型上下文协议) | 安全的远程能力网关 | 独立部署在远程服务器 |
中间代理,让Agent可以安全调用远程系统/数据,同时隔离Agent和外部资源的直接权限,避免暴露敏感配置 |
5.1 MCP介绍
远程服务器上的MCP本质是一个轻量化的API网关服务,它负责3件事:
- 接收Agent发来的标准化MCP请求
- 按照预先配置的权限,代理访问外部资源(比如远程数据库、第三方API)
- 将执行结果按照MCP协议格式返回给Agent
它不会暴露外部资源的原生账号密码,只会把Agent的请求转发到目标服务,并做权限校验
MCP是「安全的中转站」,它不会把数据库的账号密码直接暴露给Agent,而是作为中间代理:只开放你预先配置好的有限权限,比如只能读取指定的几张表,只能执行查询不能修改数据,从根源上避免了Agent误操作或者被攻击后泄露数据库权限
只有需要对外部数据进行操作时,才需要使用MCP,如果对本地数据库中的数据进行读写等,只需要使用tools
标准化的接入协议现在的MCP是Anthropic联合OpenAI等厂商推出的通用协议,你只需要按照协议标准开发一次MCP服务,就可以让所有支持MCP的Agent(比如Claude Agent、GPT-4 Agent)直接调用,不需要为不同的Agent单独写适配代码
可以统一管理所有外部能力你可以在同一个MCP网关下对接多个外部服务:比如同时对接远程数据库、企业API、云存储服务,Agent只需要通过统一的MCP协议调用,不需要记住每个服务的调用方式
可以做请求的审计和限流作为中转站,MCP可以记录所有Agent的调用请求,比如谁调用了哪个数据库、执行了什么查询,还可以限制Agent的调用频率,避免大量请求打垮远程数据库
5.2 Skills, Tools, MCP配合使用
用户发起任务 → 2. Agent加载对应领域的Skills → 3. Skills解析任务,识别到需要远程数据 → 4. Agent调度MCP服务,发起远程请求 → 5. MCP作为安全中转站,连接远程资源(比如公司云端数据库)拉取数据 → 6. Agent调用本地Tools完成本地计算/文件存储等操作 →7. 返回最终结果给用户
第五节:预设 Skills 探索
1 探索官方预设Skill(GitHub仓库)
官方入口
机制说明:Skills explained
Office 文档类 Skills(四件套目录)xlsx:skills/xlsx
docx:skills/docx
pdf:skills/pdf
pptx:skills/pptx
预设Skill统一遵循标准化文件夹结构
2 Skill Creator
局限性 :之前你只能凭感觉写指令,效果好不好也不太可控。整个过程更像是在碰运气,而不是在做工程,没办法验证技能是否真的生效。一旦跑出问题,就只能靠猜,再一点点去调
说白了,当时缺的就是一套像样的验证手段。做完一个技能,只能多跑几次,感觉差不多就继续往前。一旦模型 变化或场景复杂一点,问题往往要等结果出错了才会暴露
skill-creator 本身就是一个Skill,它的目的是帮助你构建、迭代和发布其他 Skill。实现真正的测试能力、可量化的结果评分、盲测 A/B 对比以及自动优化触发机制的工具,最关键的是:这一切都不需要写代码
2.1 两种Skill校验方式
方式1:终端手动校验(开发者模式)
使用
GitHub skill‑creator/scripts/quick_validate.py脚本,校验Skill文件夹结构、文件合规性
- 进入skills仓库根目录后执行
python skill-creator/scripts/quick_validate.py 目标Skill文件夹路径- 示例:校验xlsx技能:
python skill-creator/scripts/quick_validate.py skills/xlsx
方式2:Claude内prompt校验(便捷模式)
- 将GitHub的 skill‑creator 完整文件夹,放入本地指定skills目录
- 在Claude聊天框输入:
"使用 Skill Creator 对 [技能名称] 运行评估"/"使用 Skill Creator 对 [技能名称] 进行基准测试"/"使用 Skill Creator 优化 [技能名称] 的描述词"等- Claude调用skill‑creator能力,自动扫描、分析、给出优化建议
3 Claude Desktop:Skill Creator
它是什么:Claude Desktop 里的一个能力开关,用来让 Desktop 识别并加载本地 Skills,并在你修改后触发更新(
监听变化动态更新)
开启Claude Desktop Skill Creator开关
- 打开Claude Desktop客户端
- 进入设置(Settings)→ 找到 Capabilities(能力)
- 开启 Skill Creator 开关
官方说明:开启后,Claude才会监听本地指定目录、加载自定义Skill、识别文件修改并实时更新
使用方式(最小闭环):
- 从官方仓库挑选一个 skill(优先选最简单、依赖少的)
- copy 到本地 Skills 目录(保持原始结构,先不要"扁平化")
- 只改一处(例如 prompt)并记录改动点
- 通过 Skill Creator 触发 update
- 回到 Desktop 测试:输入一个最小样例,确认行为是否变化
- Skill必须放入指定目录:仅
%APPDATA%\Anthropic\Claude\skills (Windows)有效- 必须开启Skill Creator开关:不开开关,本地Skill完全无法加载
- Skill必须是完整文件夹:不能只放单个文件,必须保留完整目录结构
- 实时更新前提:
指定目录 + 开启开关,两个条件同时满足
第六节:自定义 Skills
本节将深入剖析 Skills 的组成结构,并手把手演示如何从零构建高质量 Skills。随后,我们将通过两个实战示例------"基于讲义自动生成练习题"与"时间序列数据特征分析"------将所学知识付诸实践
回顾一下,我们创建的每个 Skills 都有一个必需的 SKILL.md 文件,其中包含需要 name 和 description 的 YAML 前置元数据。在底层的 SKILL.md 中,我们有 Skills 的内容,以及对脚本或任何附加文本文件、必需资源的引用,这些资源只有在需要时才会加载
1 Skills 基础规范
核心必需配置(SKILL.md)
每个自定义技能必须包含 SKILL.md,
内置 YAML 元数据:分必填字段(name、description)和可选元数据字段(可按需补充扩展配置,丰富技能兼容性)
| 必填字段 | 约束条件 |
|---|---|
| name | • 最多 64 个字符 • 只能包含小写字母、数字和连字符 • 不能以连字符开头或结尾 • 必须与父目录 name 匹配 • 建议使用动名词形式(动词+ing) |
| description | • 最多 1024 个字符 • 不能为空 • 应 descriptionSkills 的功能以及何时使用它 • 应包含帮助智能体识别相关任务的具体关键词 |
| 可选字段 | 约束条件 |
|---|---|
| license(许可证) | 许可证名称或对许可证文件的引用 |
| compatibility(兼容性) | 最多 500 个字符,指示环境要求 |
| metadata(元数据) | 任意键值对 |
| allowed-tools(允许的工具) | 预批准工具的空格分隔列表(实验性功能) |

正文编写规范
内容控制在 500 行以内,复杂内容拆分至外部单独文件
采用分步式写作,明确输入 / 输出格式、使用示例按场景选择自由度:
高自由度 (只说目标是什么,不限定代码、不限定步骤、不限定工具,允许模型发挥)
中自由度 (给模板 / 范例 / 伪代码,有参考,但允许微调)
低自由度(强制指定每一步命令、脚本、文件、执行顺序,必须调用指定脚本、指定参数、指定流程,不允许 AI 自由发挥、不能改步骤)
资源引用仅一级目录,禁止多层嵌套

可选扩展目录
/scripts:存放运行脚本,需完善注释与异常处理/references:存放参考文档、规则说明,长文档添加目录/assets:模板、图表、数据、配置等静态资源
| 目录 | 内容 | 备注 |
|---|---|---|
| /scripts | - 清晰记录依赖项 - 脚本有清晰的文档 - 错误处理明确且有帮助 | 注意:在您的说明中明确 Claude 是应执行该脚本,还是将其作为参考阅读。 |
| /references | - 包含代理在需要时可阅读的附加文档。 - 保持单个参考文件的专注性。 | 注意:对于超过 100 行的参考文件,在顶部包含内容目录。这确保代理能看到完整范围。 |
| /assets | - 模板: - 文档模板 - 配置模板 - 图像: - 图表 - 标志 - 数据文件: - 查找表 - 模式 |
2 实战案例讲解
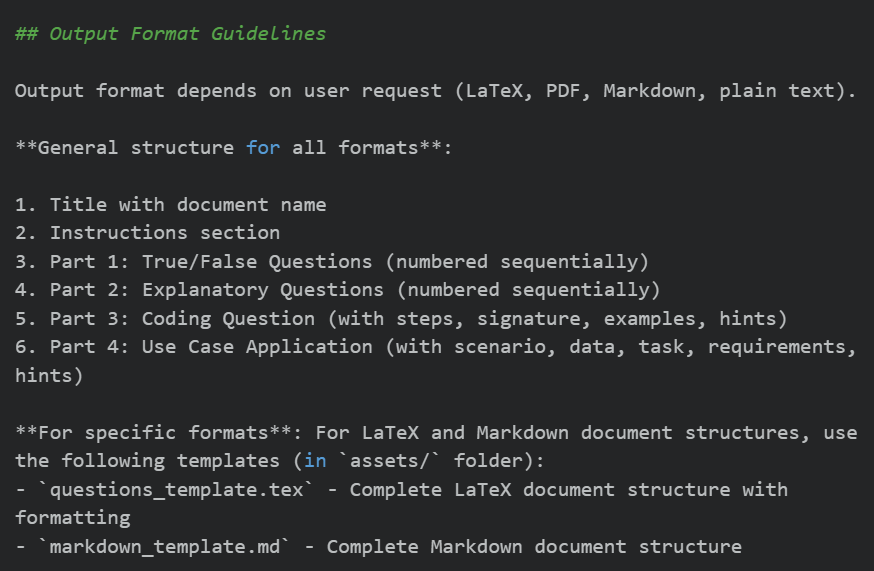
案例 1:generating-practice-questions 练习题生成技能
- 核心能力:基于讲义、笔记自动生成判断题、选择题、简答题、应用题
- 支持格式:Markdown、TXT、PDF、LaTeX
- 设计亮点 :
自动提取学习目标、核心知识点、案例素材
采用模板化设计,通过 assets 目录挂载 Markdown/LaTeX 输出模板
题目难度分层,结构标准化

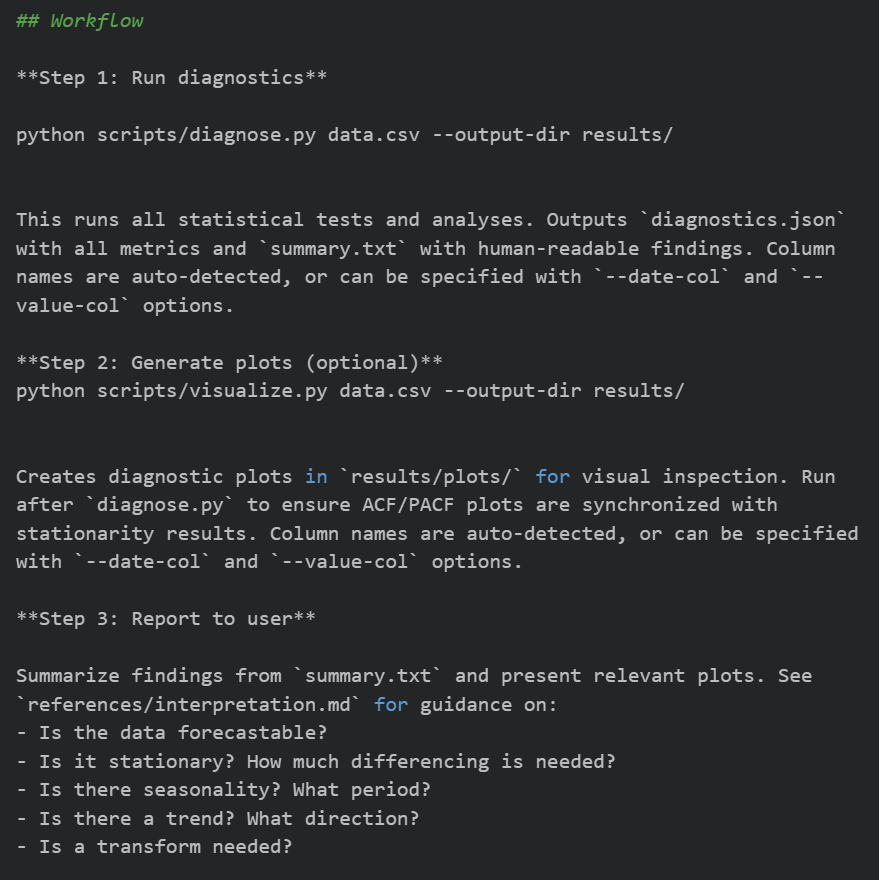
案例 2:analyzing-time-series 时间序列分析技能(低自由度)
- 核心能力:自动识别数据趋势、季节性、平稳性、异常值
- 标准化三步工作流
步骤 1:执行统计诊断,输出量化指标
步骤 2:生成可视化图表(可选)
步骤 3:结合参考文档,输出分析结论- 技术实现:通过 /scripts 调用 Python 脚本完成数据分析

3 claude 上手操作
安装官方技能库
- 打开 Claude Code,输入
/plugin- 找到 Marketplace → Add Marketplace(官方插件市场)
- 输入仓库地址 anthropics/skills
- 下载成功后,就可以在你的Claude中看到对应的插件
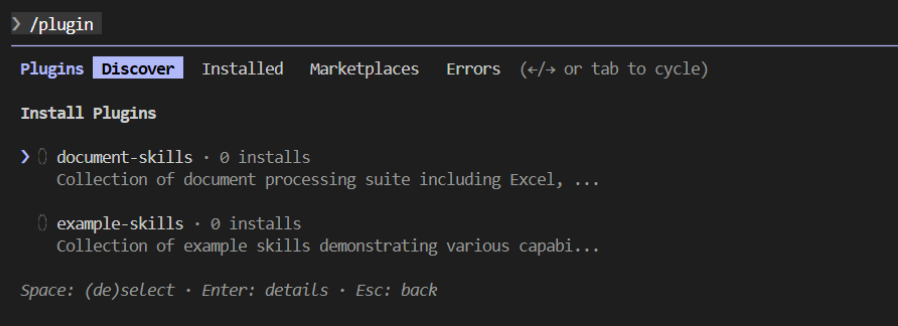
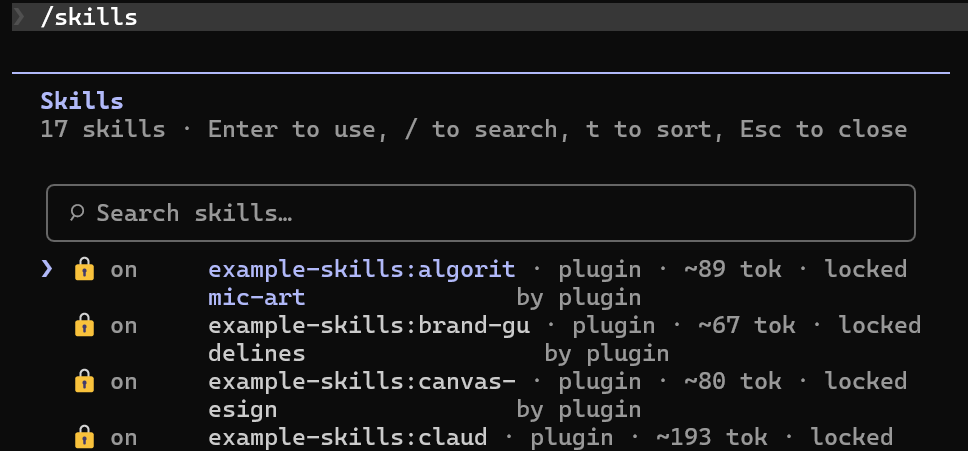
Skills管理
- document-skills 主要包括处理 Excel、Powerpoint、word、pdf 文件;example-skills 则是示例技能。安装对应技能范围
- 重启客户端,输入
/skills查看已启用技能

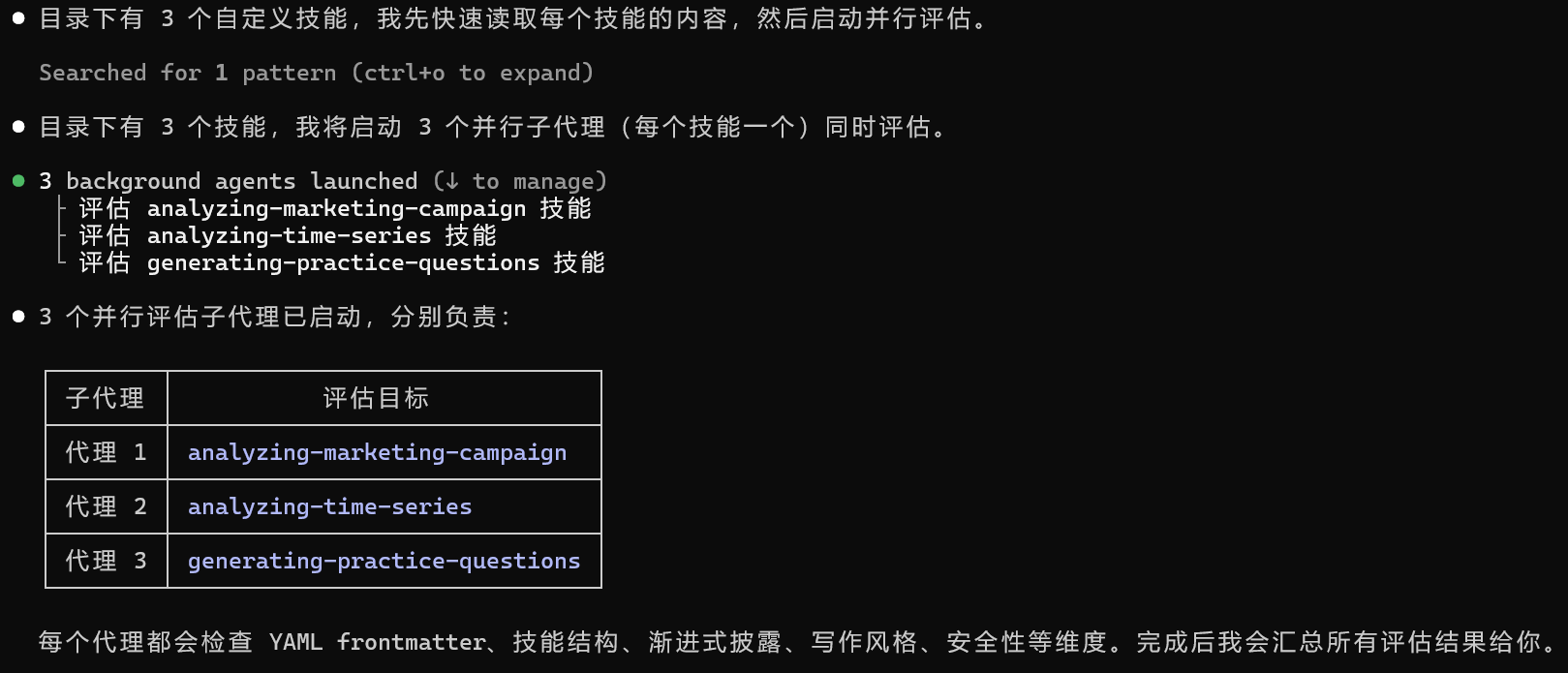
使用官方
skill-creator 技能进行技能合规评测
- 支持多子代理并行评估,分工检查技能规范
- 指令作用:检测自定义技能是否符合命名、结构、格式最佳实践,输出优化建议
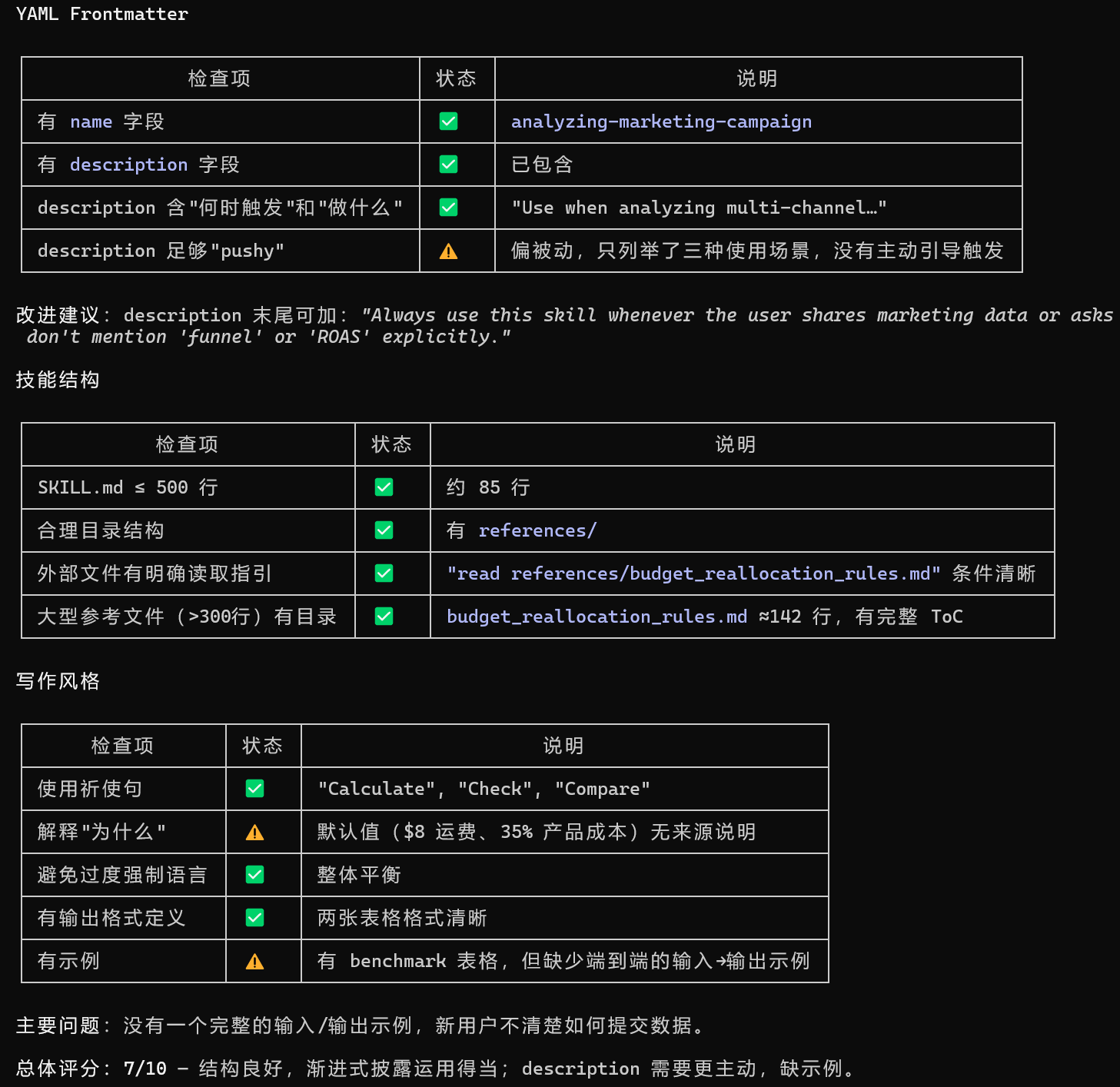
请使用 skill-creator 技能,评估 ./6.Creating Custom Skills(自定义skills) 目录下的所有自定义技能,检查是否符合官方最佳实践。启用两个并行子代理,每个子代理分别单独评估一个自定义技能。
第七节:使用 Claude API 的 Skills
之前我们学习的都是使用Claude Desktop调用Skills,在这节中主要学习:如何用 Claude API 去调用这些Skills
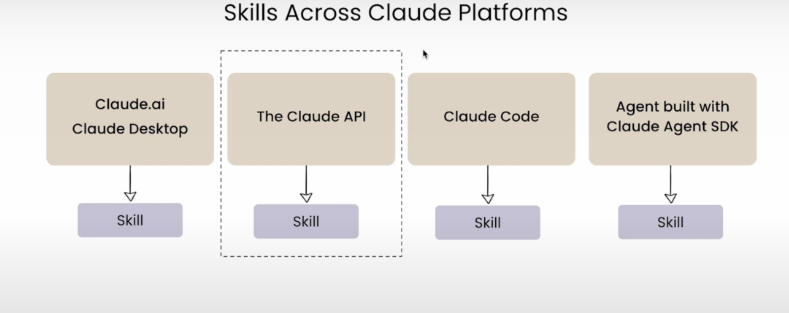
重要注意事项:Skills不互通
你在 Claude AI 和 Claude Desktop 中创建的Skills不会在 Claude API 或 Claude Code 中共享
建议是将常用的技能保存到一个 git 仓库里,这样在不同环境中都能快速部署
第二个关键重点:两大使用环境区别使用 Claude + Skills 一共分为两种场景:
(1)客户端使用场景 :在 Claude 桌面端、Claude Code 等软件中,直接导入自定义 Skills。官方内置运行环境与文件能力,AI 可直接读取 Skills规则,按照标准化流程完成任务,全程手动操作,无需调用 API
(2)API 开发场景 :自研应用或自动化程序通过
Claude API接入 AI 能力。由于 API 无法直接访问本地文件,需要借助「代码执行工具」提供云端沙箱运行环境,搭配「Files API」上传技能文件与数据,在隔离环境中执行技能流程,最终返回结果,既实现了技能自动化,又保障本地设备安全
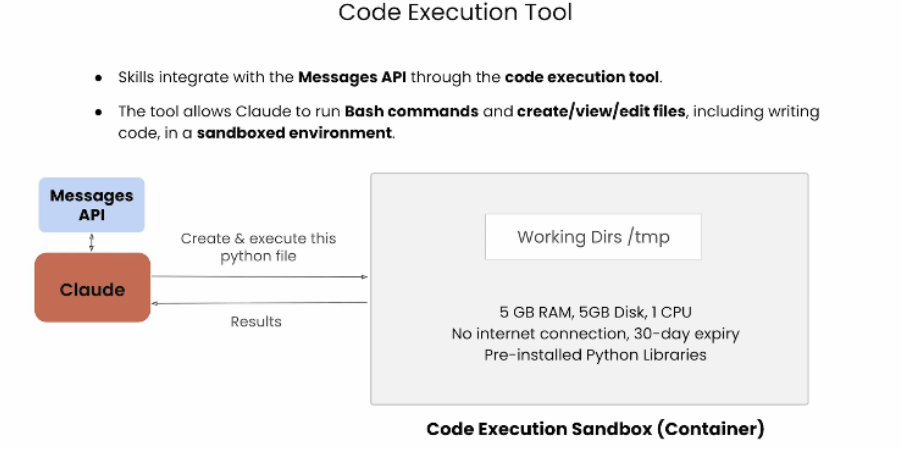
1 代码执行工具
当我们开始探索 Messages API 时,我们会用到代码执行工具。代码执行工具允许 Claude 运行 Bash 或 Shell 命令,来完成我们在使用技能时看到的所有操作:创建、查看、编辑文件,以及编写代码,所有这些都在一个
沙箱环境中进行
代码执行工具让我们的应用能够拥有一个独立的专属容器,用于执行代码和操作文件系统。正如你所看到的技能能实现的所有功能,这对于读取我们的技能、在技能中执行代码,以及处理我们可能想要编辑、查看和创建的其他文件来说至关重要为了让你更直观地理解这一点,当我们集成代码执行工具时,相当于给 Claude 提供了一个执行沙箱或容器
当我们让 Claude 创建并执行文件时,这些操作会在一个安全且隔离的环境中进行。该环境对内存、磁盘、CPU 等资源都有限制,更重要的是,它
没有互联网连接,并且预装了一些开箱即用的库。因此,它并非适用于所有类型的编码环境。这里有一些需要注意的限制
注意:这种无互联网连接的限制是 Messages API 特有的。当我们在 Claude AI 或 Claude Desktop 中使用代码执行工具时,我们是可以访问互联网的,并且可以下载和安装包
2 Files API
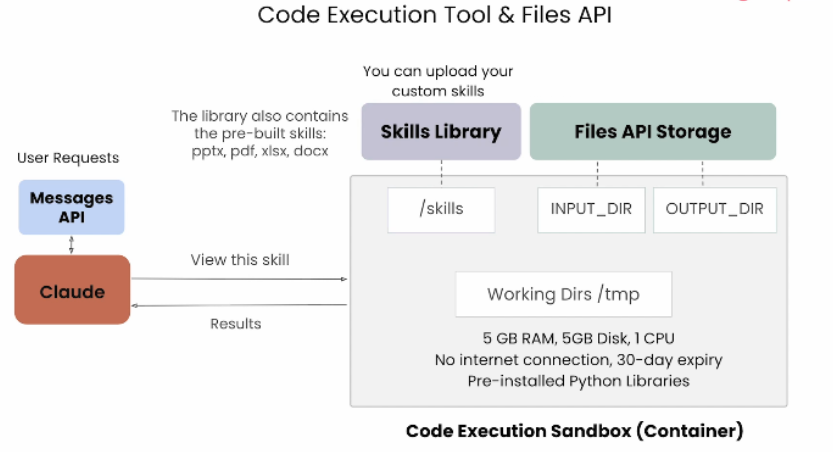
Claude API 包含一组名为
Files API的接口,用于上传和下载可以在容器内运行和处理的文件Claude 的代码执行工具在端的,没有权限访问你本地电脑中需要处理的文件,所以需要通过Files API 把你电脑的文件 → 传到沙箱,沙箱处理完的文件 → 传回你电脑
Skills 在 Claude API 使用中如何存放?不管是你自己写的自定义技能,还是官方技能,在 API 运行时,都会统一放到
「沙箱容器内部的固定文件夹」,代码执行工具读取这个文件夹里的 Skills 文件,才能正常调用
3 实例
python
# 生成练习题 Skills 示例
# 导入工具 + 环境变量
from dotenv import load_dotenv
import anthropic
from anthropic.lib import files_from_dir
_ = load_dotenv()
# 创建客户端
client = anthropic.Anthropic()
# 上传第一个自定义技能
skill = client.beta.skills.create(
display_title="Practice Question Generator",
files=files_from_dir("./custom_skills/generating-practice-questions"),
betas=["skills-2025-10-02"]
)
print(f"Skill ID: {skill.id}")
# 上传要处理的讲义文件
file_object = client.beta.files.upload(
file=open("./lecture_notes/notes04.tex", "rb"),
)
# 发送请求让 Claude 执行技能
response = client.beta.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=4096,
betas=["code-execution-2025-08-25","skills-2025-10-02", "files-api-2025-04-14"],
container={
"skills": [{
"type": "custom",
"skill_id": skill.id,
"version": "latest"}]
},
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Generate practice questions in Markdown format from these lecture notes"},
{"type": "container_upload", "file_id": file_object.id}
]
}],
tools=[{
"type": "code_execution_20250825",
"name": "code_execution"
}]
)
# 打印 Claude 做了什么
file_id = None
for block in response.content:
if block.type == 'bash_code_execution_tool_result':
# File ID is in the tool result
if hasattr(block, 'content') and hasattr(block.content, 'content'):
for result_block in block.content.content:
if hasattr(result_block, 'file_id'):
file_id = result_block.file_id
break
# 下载生成好的文件
if file_id:
# Download the file
file_content = client.beta.files.download(
file_id=file_id,
betas=["files-api-2025-04-14"]
)
# Save to disk
with open("notes04.md", "wb") as f:
file_content.write_to_file(f.name)# 告诉 Claude API:我要开启哪些「内测功能」:允许你上传技能 → 允许 Claude 运行代码 → 允许上传 / 下载文件
# "code-execution-2025-08-25":开启「代码执行工具」,没有它 → Claude 只能聊天,不能执行任何代码
# "skills-2025-10-02":开启「Skills 技能系统」,允许你上传自定义技能文件夹到 Claude,允许 Claude 调用你上传的技能,允许使用官方技能(如 docx、pdf、xlsx),没有它 → 你上传了技能也用不了
# "files-api-2025-04-14":开启「文件上传 / 下载系统」,允许你把本地文件上传到 Claude 的沙箱,允许 Claude 把生成的文件传回给你(下载)。支持 .tex、.csv、.md、.docx、.py 等各种文件,没有它 → 传不了文件,也拿不到生成结果
betas=["code-execution-2025-08-25","skills-2025-10-02", "files-api-2025-04-14"], 第八节:使用 Claude Code 的 Skills
1 Claude Code 核心工作原理
整体运行三阶段(循环执行)
Claude Code 接收任意任务后,会持续循环以下三个阶段,自动调整步骤、自主修正问题:
- 收集上下文:自动读取项目文件、代码结构、报错日志、目录信息、Git 状态等,理解你的项目与需求
- 采取行动:调用各类工具,执行读文件、改代码、运行命令、搜索内容、创建文件等操作
- 验证结果 :运行测试、检查命令输出、核对修改效果,判断任务是否完成,失败则自动重试
补充:简单任务仅需「收集上下文」;代码修复、项目改造需要完整三轮循环;复杂重构会大量反复验证
智能体两大核心驱动模型(推理核心)
- 负责思考、理解需求、分析代码逻辑、拆解复杂任务、决策下一步操作
- 可选模型 :
(1)Sonnet:日常开发、高频常规任务(编码、简单调试、普通文档),追求性价比和响应速度,优先选它,能满足绝大多数开发需求
(2)Opus:复杂架构、深层 bug、深度业务分析、大型项目梳理,不介意更高成本,需要顶级推理能力,优先选它- 支持随时切换 :会话中使用
/model命令、或启动命令claude --model 名称切换模型工具(执行核心)
- 仅有模型只能文字回复,工具是 Claude Code 成为智能体的关键
- 内置原生工具能力:读取 / 编辑 / 创建文件、终端命令执行、代码运行、全局文件搜索、Git 操作、联网检索等
- 运行逻辑:每完成一步工具调用,会接收返回结果,基于新信息继续决策,形成闭环
- 实操案例(修复测试报错) :
① 运行测试 → ② 读取错误日志 → ③ 搜索关联代码文件 → ④ 阅读源码理解问题 → ⑤ 编辑代码修复 → ⑥ 重新运行测试验证
能力扩展体系内置工具是基础能力,还可通过多层
扩展强化功能:Skills、MCP 外部连接、自动化钩子、子智能体、智能体团队,满足复杂定制化需求
2 Claude Code 可访问的资源范围
在项目目录中启动 Claude Code 后,拥有以下合法访问权限(
需用户授权):
- 完整项目目录:当前文件夹及所有子目录的文件,全面理解项目结构
- 终端权限:本地可运行的所有命令(打包、依赖安装、Git、脚本运行等)
- Git 信息:查看当前分支、未提交修改、提交历史、代码变更记录
- 项目规则文件:自动读取 CLAUDE.md,加载项目专属规范与要求
- 自定义扩展 :已配置的 MCP 服务、技能、子智能体、钩子等扩展能力
核心优势:区别于普通单文件代码助手,全局理解整个项目,支持跨文件联动修改、全局问题排查
3 会话管理机制
基础会话特性
Claude Code 会在您工作时将您的对话
本地保存。每条消息、工具使用和结果都会被存储,这使得回溯、恢复和分叉会话成为可能。在 Claude 进行代码更改之前,它还会对受影响的文件进行快照,以便您在需要时可以恢复。会话是短暂的,与 claude.ai 不同,Claude Code 在会话之间没有持久内存。每个新会话都从头开始。Claude 不会随着时间的推移"学习"您的偏好,也不会记住您上周处理过什么。如果您希望 Claude 在会话之间了解某些内容,请将其放入您的CLAUDE.md文件中
跨分支工作规则每个 Claude Code 对话都是一个与
当前目录绑定的会话(会话"专属"于某个目录,数据单独存储、文件访问范围限定在该目录及子目录,不同目录会话互不干扰)。会话不能查看所有文件夹,默认只访问当前绑定目录,跨目录访问需手动授权,且受权限规则限制。当您恢复时,您只会看到该目录中的会话。Claude 会查看您当前分支的文件。当您切换分支时,Claude 会看到新分支的文件,但您的对话历史记录保持不变。即使切换后,Claude 也会记住您讨论过的内容。由于会话与目录绑定,您可以通过使用git worktrees运行并行 Claude 会话,这会为各个分支创建单独的目录(为每个分支创建单独目录,实现多个 Claude 会话并行运行,避免文件修改冲突)
会话恢复与分叉当您使用
claude --continue或claude --resume恢复会话时,您将使用相同的会话 ID 从上次中断的地方继续。新消息会附加到现有对话中。您的完整对话历史记录会恢复,但会话范围的权限不会。您需要重新批准这些权限如果需要新建分支尝试不同的方法而不影响原始会话,请使用
--fork-session标志,这会创建一个新的会话 ID,同时保留会话框原有的对话历史记录。原始会话保持不变。与恢复一样,分叉会话不会继承会话范围的权限在多个终端中使用相同的会话 :如果您在多个终端中恢复相同的会话,两个终端都会写入同一个会话文件。来自两者的消息会交错显示,就像两个人写在同一个笔记本上一样。不会损坏任何内容,但对话会变得混乱。每个终端在会话期间只看到自己的消息,但如果您稍后恢复该会话,您将看到所有交错的消息。对于从相同起点进行的并行工作,请使用
--fork-session为每个终端提供自己的干净会话
bash
claude --continue --fork-session- 你在终端当前文件夹下运行claude,开启对话,生成:session1.jsonl(原会话)
- 聊了 10 轮后,你想试新方案
- 在终端输入!claude --fork-session -p "."命令(claude版本不同,输入的命令不同)
- Claude 复制 session1 前 10 轮历史,新建 session-.jsonl(分叉会话)
- 你接下来的对话 只写进分叉对话中进行,原对话内容不动
- 本质是在 ~/.claude/projects/<项目目录>/ 下创建一个新的jsonl,区分与原jsonl
- 可以通过会话id恢复会话
4 上下文窗口机制
Claude 的上下文窗口包含您的对话历史记录、文件内容、命令输出、CLAUDE.md 文件、加载的技能和系统指令。随着您的工作,上下文会逐渐填满。Claude 会自动压缩,但对话早期的一些指令可能会丢失。将持久规则放入 CLAUDE.md 文件中,并运行
/context以查看哪些内容占用了空间手动优化:
- 命令
/context:查看上下文占用情况- 命令
/compact:手动压缩清理上下文(只存在内存 / 会话临时状态里)- 优化方案:固定规则放
CLAUDE.md,大型参考文档改用按需加载的技能
5 Claude Code 全扩展能力详解
| 功能 | 作用 | 何时使用 | 示例 |
|---|---|---|---|
| CLAUDE.md | 每个对话都会加载的持久上下文 | 项目约定,"总是做"规则 | "使用 pnpm,而不是 npm。在提交前运行测试" |
| Skills | Claude 可以使用的指令、知识和工作流程 | 可重用内容、参考文档、可重复任务 | /review 运行您的代码审查清单(内置技能指令,绑定了一套「代码审查流程」);带有端点模式的 API 文档技能 |
| 子智能体 | 返回摘要结果的隔离执行上下文 | 上下文隔离、并行任务、专业工作者 | 读取许多文件但只返回关键发现的研究任务 |
| 智能体团队 | 协调多个独立的 Claude Code 会话 |
并行研究、新功能开发、使用竞争假设进行调试 | 生成审阅者以同时检查安全性、性能和测试 |
| MCP | 连接到外部服务 | 外部数据或操作 | 查询您的数据库、发布到 Slack、控制浏览器 |
| 钩子 | 在事件上运行的确定性脚本 |
可预测的自动化,不涉及 LLM(在.claude/hooks/目录下创建一个after_edit脚本文件,就会在修改文件后自动调用) |
例如,每次文件编辑后运行 ESLint |
6 关键补充总结
- Claude Code 核心本质:本地智能体框架 + 大模型推理 + 原生工具,是开发者专属 AI 工具
- 所有扩展都是为了「定制化、自动化、隔离化」开发流程,适配不同项目复杂度
- 和网页版 Claude、Claude API 定位完全区分:本地 IDE 赋能开发,是编码场景专属工具
- 所有操作围绕「智能体循环」展开,理解收集 - 执行 - 验证,就能完全掌握 Claude Code 运行逻辑
第九节:使用 Claude Agent SDK 构建实战级研究智能体
Claude API(最底层,只有文字对话)
↓
Claude Agent SDK(开发框架:智能体、工具、子代理、技能引擎)
↓
Claude Code(成品软件,内置SDK,提示词直接操控)
你公司要做一个「内部 AI 办公系统」
公司员工打开网页
输入:帮我整理本周所有项目进度
AI 自动:
- 读取内部 Git 代码
- 读取内部 OA 文档
- 读取 Notion 知识库
自动分工:
- 子代理 A:查代码提交记录
- 子代理 B:查会议纪要
- 子代理 C:汇总写成周报
自动发到企业微信群
使用 claude SDK 定制化开发:
- 自己控制子代理数量、权限
- 自己对接公司内部系统
- 自己做登录、权限、页面
- 自己定义专属「公司技能 SOP」1 核心架构:团队式智能体设计
采用分工协作架构,模拟工程团队工作模式:
| 架构层级 | 概念隐喻 (Metaphor) | 代码组件 (SDK Component) | 本案具体实现 (Implementation) |
|---|---|---|---|
| The Brain | 指挥官 / 编排者 | Main Agent + TaskTool |
负责理解需求,加载技能制定计划,分派任务,最后合成报告 |
| The Arms | 专家 / 执行者 | AgentDefinition (Sub-agents) |
Docs Researcher (查文档) Repo Analyzer (跑代码) Web Researcher (搜视频) |
| Process | 标准作业程序 (SOP) | SkillTool |
learning-a-tool: 一个定义了"如何学习新工具"的标准流程技能 |
| Connectivity | 外部连接器 | MCP Server |
Notion MCP: 用于将生成的 Markdown 报告写入云端 Notion 页面 |
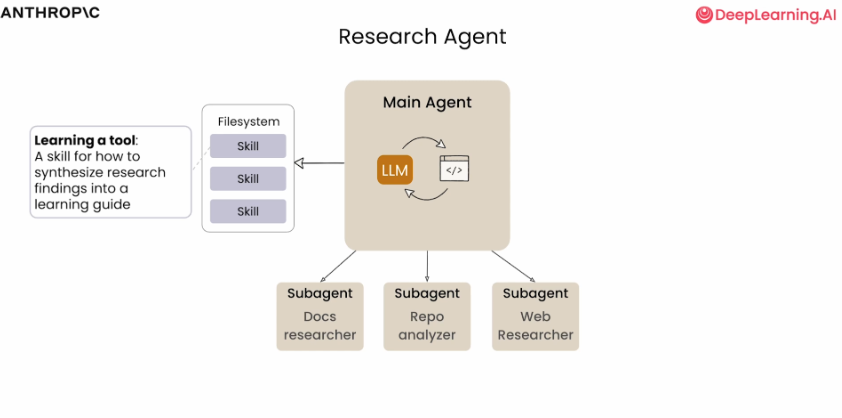
关键区别 :在本案例中,技能 (Skill) 是专门给主智能体用的 ,作为其规划的指导手册;而子智能体 (Sub-agents) 则是去执行具体脏活累活的
2 工作流演示:研究 "MinerU"
阶段 1:规划 & 渐进式披露
用户给出核心需求:需要一份 MinerU 学习指南,并要求先出计划
主智能体
自动加载项目内 learning-a-tool 技能(标准化工作流程手册),按照规范制定调研方案渐进式加载核心作用
SDK 不会一次性把所有技能文档全部塞进上下文:
- 初始只加载技能名称,不占用大量 Token
- 需要使用该技能时,才加载核心 SKILL.md
- 涉及深度流程时,再按需加载附属文档
✅ 目的:控制上下文开销,防止内容溢出、减少 token 消耗
阶段 2:并行执行主智能体依靠内置
TaskTool(任务调度工具),同时派发任务给 3 个子智能体,无需排队等待三个专家分工独立作业:
- Docs Researcher:专门查阅官方文档,了解基础功能与设计
- Repo Analyzer:通过 git clone 下载源码,分析项目结构与代码逻辑
- Web Researcher:全网检索、查找 YouTube 视频教程与社区经验
核心优势:多任务并行同时运行,互不阻塞,大幅提升复杂调研效率
阶段 3:合成(结果统一整理)三个子智能体全部完成调研后,将各自结果汇总给主智能体
主智能体自动在本地生成标准化、结构化文件:
- README.md:整体学习路线、学习难度、时间预估
- resources.md:统一整理官网、仓库、教程、参考链接
- examples/:自动编写入门 Demo 代码
👉 把零散的调研信息,整合为可直接使用的成套学习资料
阶段 4:基于 MCP 完成成果交付下达最终指令:将整理好的资源文档同步到 Notion
智能体调用 Notion 专属 MCP 工具:mcp_notion_append_block_children
自动处理格式:读取本地 Markdown 文件,转为 Notion 富文本块格式
最终效果:本地文件自动写入云端 Notion 页面,实现跨系统成果交付
Claude安装
Claude Code 超详细完整指南(手把手)-最新版-2026版