deque
1、初识deque
deque,我们可以理解为是vector和list的结合体。
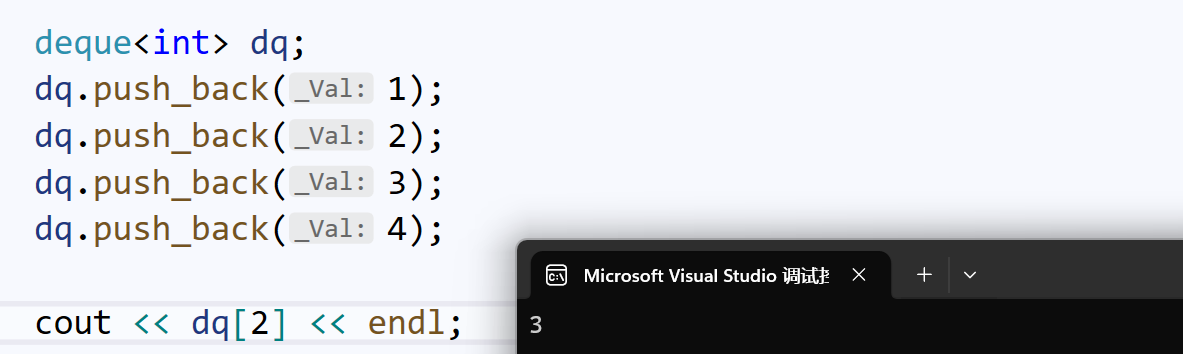
deque支持尾部操作:
cpp
void deque_test1()
{
deque<int> dq;
dq.push_back(1);
dq.push_back(2);
dq.push_back(3);
dq.push_back(4);
}deque支持重载 :
deque支持头部操作:
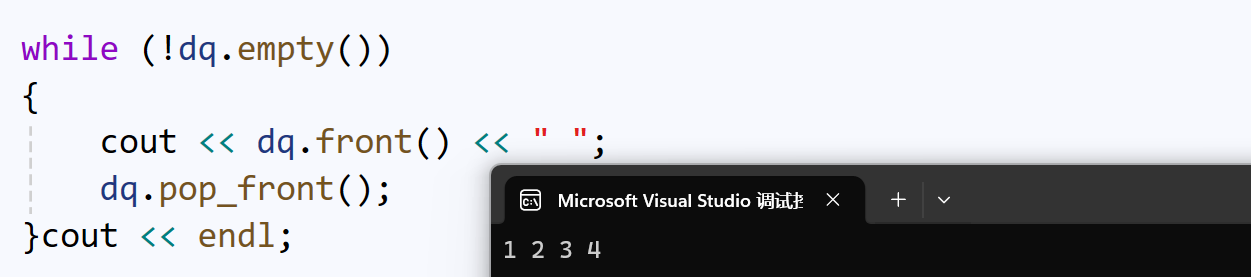
当然deque头部的插入、删除操作,和随机位置的插入、删除操作,效率也比较好。
那么,deque能否取代vector和list呢?
我们先来了解vector和list的优缺点。
2、vector和list的优缺点
首先是vector。
vector存储数据的空间是连续的,所以vector有两个很明显的优点:
- 支持快速的下标随机访问。
- 尾部插入、删除的效率很高。
但是vector也有两个很明显的缺点:
- 头部的操作,和随机位置的操作,其效率不高。
- 单个数据的插入,时间复杂度是O(N);而N个数据的插入,(随着N增大)时间复杂度变为O(N2)。
- 插入存在扩容。
- 扩容方式为异地扩容的可能性很大,但是如果是2倍扩容,随着空间的增大,扩容次数会逐渐减少。
- 扩容也存在一定空间浪费。(开了100个,只用5个)
其次是list。
list存储数据的空间是不连续的,所以list相比vector有一个很明显的缺点:
- 不支持快速的下标随机访问
- 如果要支持,那么访问的时间复杂度就为O(N),效率不太高
但是list相比vector也有两个优点:
- 头部和随机位置的操作效率更高。
- 不需要扩容,可以根据需要,申请或释放节点空间。
其实,vector还有一个优点:CPU高速缓存访问命中率高,数据访问效率高。list相比就不高。
那什么是CPU高速缓存访问命中率呢?
2.1、CPU高速缓存访问命中率
计算机存储内容的方式主要有这些:
- 硬盘(磁盘)
- 内存
- 缓存(寄存器)
| 存储方式 | 优点 | 缺点 |
|---|---|---|
| 硬盘 | 永久储存(只要不坏);价格便宜 | 存储效率低;块头更大 |
| 内存 | 存储快、效率高;块头小 | 带电存储,断电即丢失;价格贵 |
| 缓存 | 更小;更快 | 更贵 |
所占空间小的数据,如int,使用寄存器就能搞定:
而所占空间比较大的数据(如string),就可能会放入缓存。
比如现在有一个范围for,要访问string对象s:
cpp
void test2()
{
string s;
for (auto e : s)
{
// ...
}
}系统访问e保存的数据,大致有两个规则:
- 检查要访问的数据是否存在缓存中,若在,就命中,直接访问。
- 若不在,就不命中,先把内存中的数据加载到缓存,再进行访问。
命中的条件,是要访问的数据存在缓存中。而数据存入缓存,也存在一种很有意思的现象:
假如我们一共有100个字节的数据,每次只访问4字节。通常,需要访问4字节就加载4字节到缓存。但是接下来可能有8字节、16字节甚至全部100字节都要访问。
而加载4字节,与加载更多字节(假设64字节)的消耗相差不大。
那么此时,需要访问4字节,就会加载64字节到缓存。这就类似于搬东西每次多搬一点以减少搬运次数的道理。
(假设加载到缓存的内容的空间是距离不大的)由于vector的存储空间是连续的,命中率就高;而list的空间是不连续的,命中率就低。
3、deque的实现
要搞明白deque能否取代vector和list,我们还要看看deque的具体实现。
deque存储数据的方式,我们可以理解为:几个长度固定的短小数组串在一起。
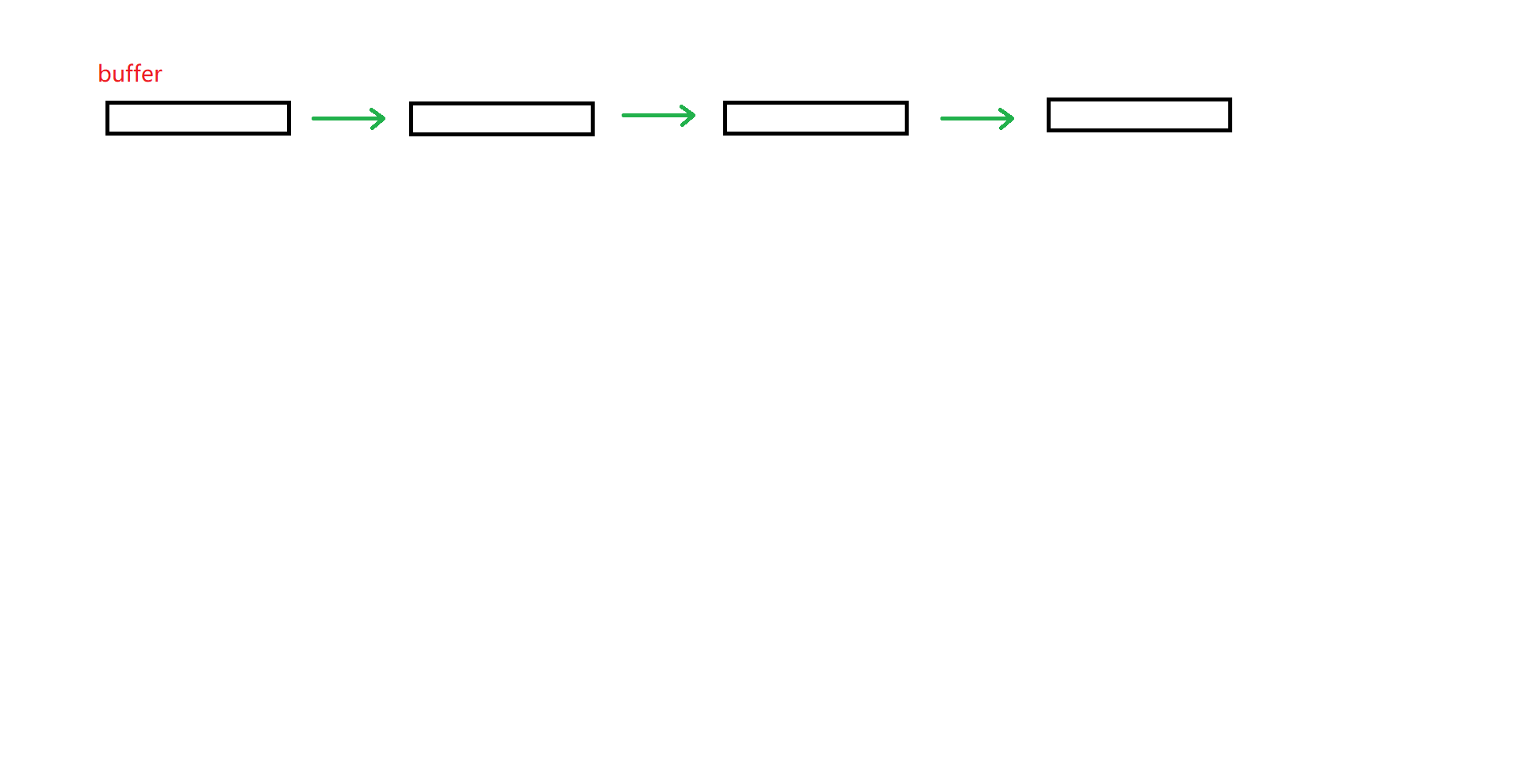
我们给这些短小数组取名为buffer。为了记录每一个buffer存在的位置以便未来访问数据,我们还需要一个中控数组:
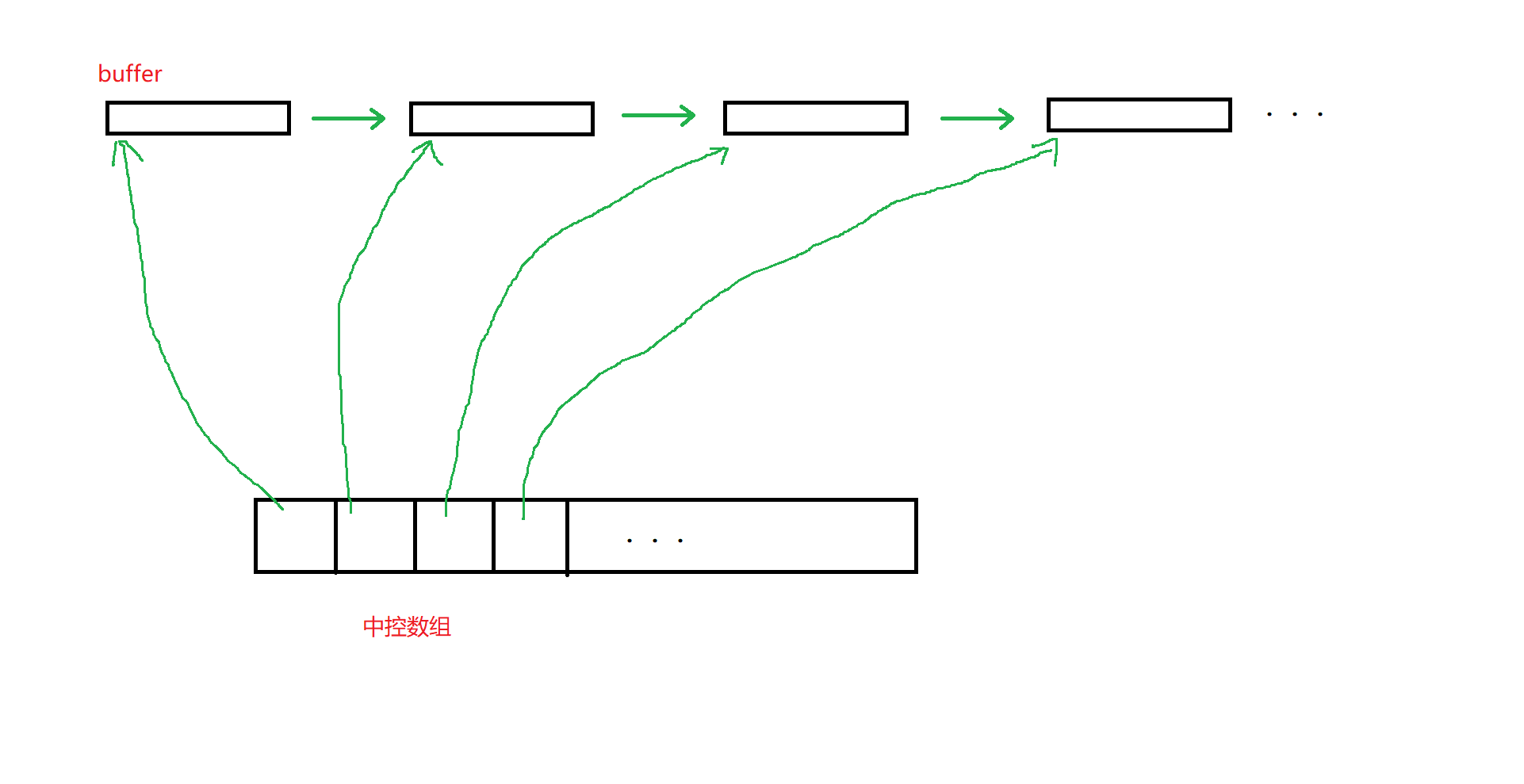
中控数组,其实是指针数组,存储的是每一个buffer的指针。
那么相对于vector和list,deque的优势就凸显出来了:
- 扩容方面:存储数据的每一个buffer,其本身不扩容,只是中控数组可能会扩容。
- 浪费方面:每一个buffer存储的元素个数可以规定比较小,那么浪费就减少。
- CPU高速缓存:每一个buffer的空间是连续的,命中率相比list提高了。
- 下标随机访问:
- 假设我们要访问第i个数据:
- 确定在哪一个buffer中:x = i / 10
- 确定在这个buffer的哪一个位置:y = i % 10
- 假设我们要访问第i个数据:
接着,我们来看看deque的迭代器:
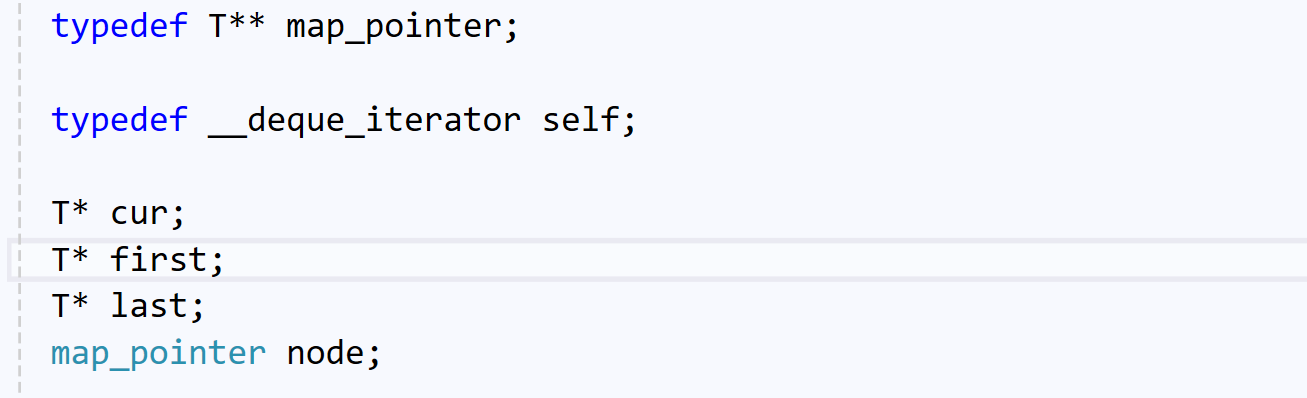
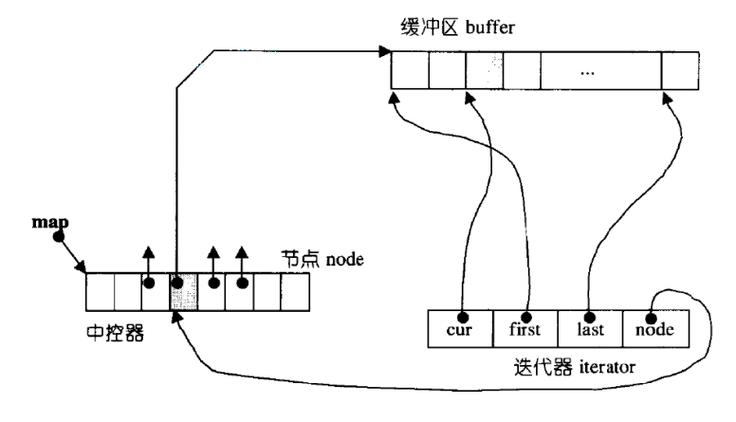
iterator中有四个成员:
- cur:指向当前的数据
- first:指向当前数据所在buffer的第一个元素
- last:指向当前数据所在buffer的最后一个元素的下一个位置
- node:指向的是当前buffer地址,存在中控函数中的指针变量的地址
所以,我们可以发现,cur、first、last的类型是T*(数据的指针类型),node的类型是T**。
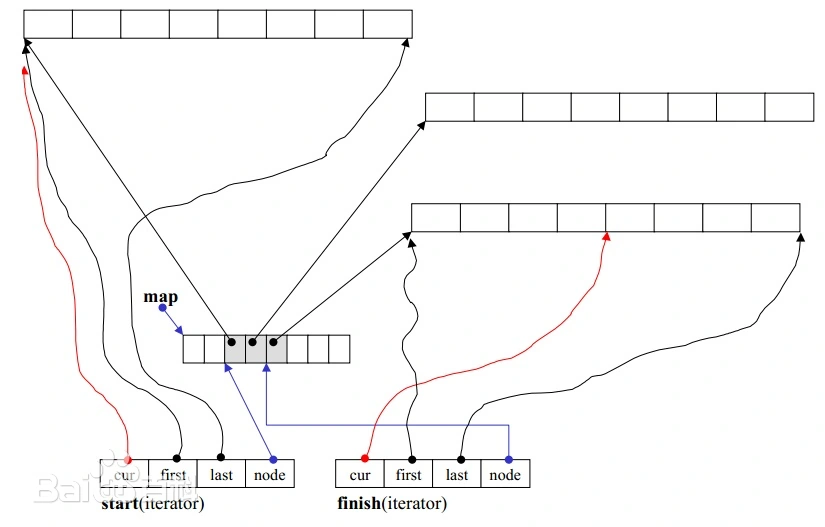
我们再看看deque整个的结构:
我们根据一个简单的范围for打印数据,完成对deque的初步认识:
cpp
void test3()
{
deque<int> dq = { 1,2,3,4 };
auto it = dq.begin();
while (it != dq.end())
{
cout << *it << " ";
++it;
}cout << endl;
}deque有两个iterator成员:

start的cur指向deque的首元素,finish的cur指向deque末尾元素的下一位。
所以deque的begin()返回的是迭代器start,end()返回的是迭代器finish:

由于cur固定了,那么迭代器所在的buffer就确定了,那么first, last, node就确定了。
所以重载==和重载!=的行为是比较cur:

重载*的行为是访问cur指向的数据:

对于重载前置++,有两种情况:
- 如果++完it还在当前buffer内,直接++cur。
- 如果++完it出了buffer(it.cur == it.last):
- 更换新的迭代器it,其node是原来迭代器的node + 1
- first = node, cur = frist,last通过buffer的固定长度推导得出


我们再来看看deque的push_back, push_front。
假设push_back(val)。
对于当前deque的finish,如果其中的cur != last,直接在finish的cur插入val,finish的cur++: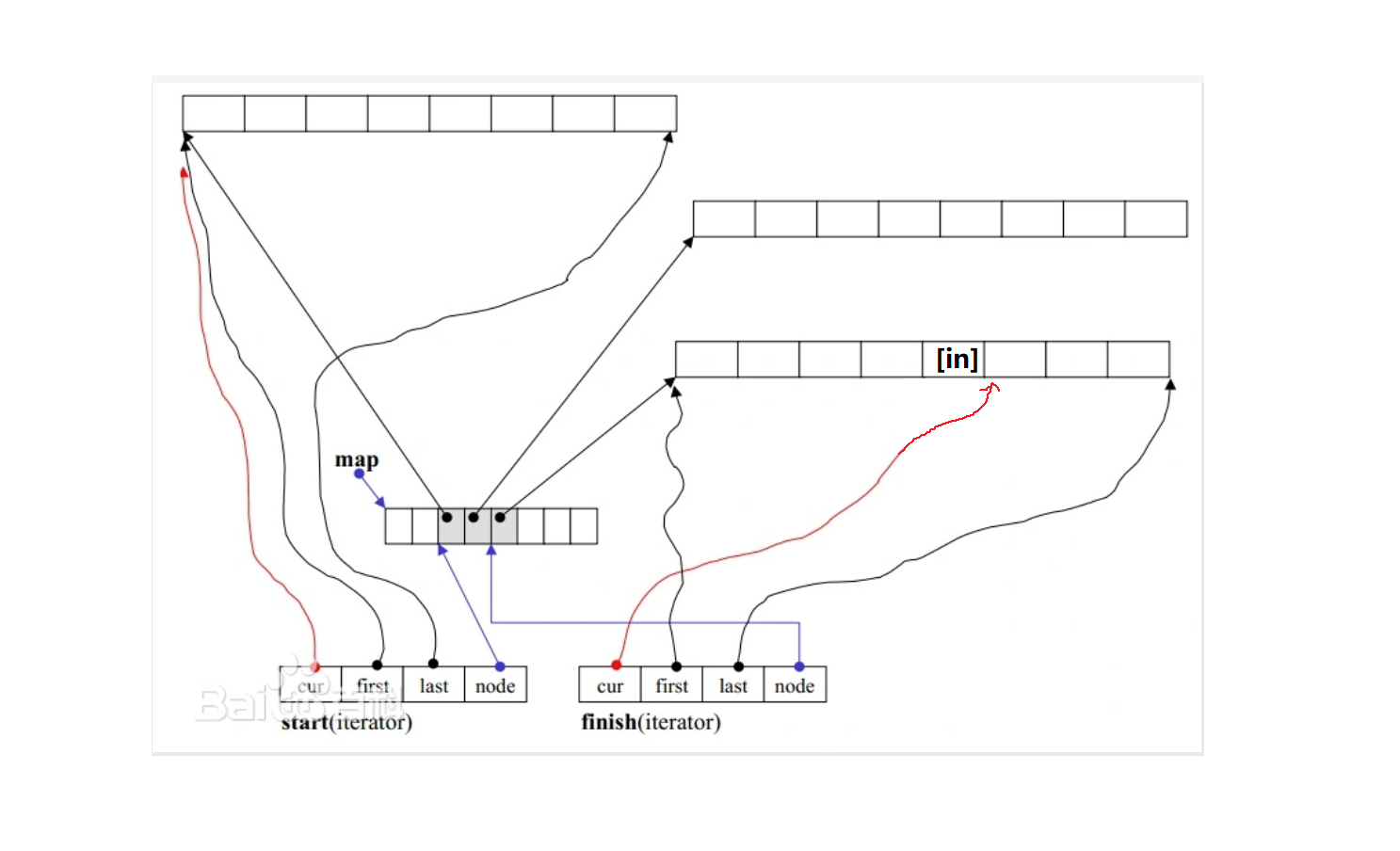
如果finish的cur == last,说明当前小buffer数组塞满了,那么:
- 开辟新的小buffer,假设新的小buffer的指针为ptr
- map(中控数组)也应该有一个指向最后一个有效元素的指针(假设为end)。将ptr存入end位置,然后end跳到下一个位置
- ptr给finish的first,ptr的指针&ptr给finish的node
- 根据buffer的固定长度,推导出last
- *first给值val,然后cur指向first的下一位
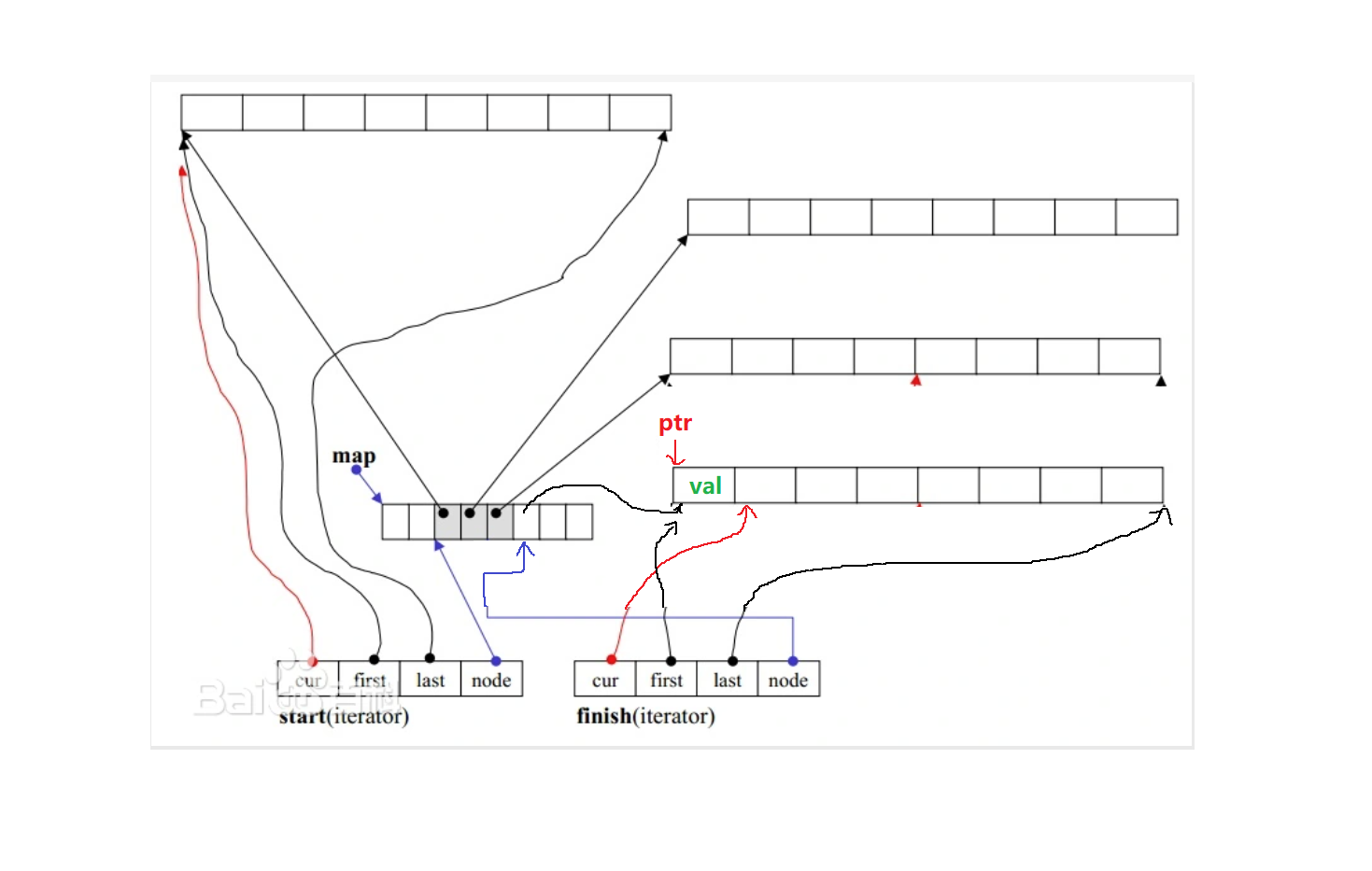
假设push_front(val)。
可能存在当前deque的第一个buffer还没有塞满的情况,所以此时:
- first--, cur--
- *cur = val
如果此时第一个buffer塞满了:
- 开辟新的小buffer作为deque的第一个小buffer。假设新的小buffer的指针为ptr
- map(中控数组)也应该有一个指向第一个有效元素的指针(假设为begin)。begin跳到前一个位置,然后begin存下ptr
- node指向之前的node的前一个位置,即node - 1
- first赋值ptr,根据buffer的固定长度推导出last
- cur指向last的前一位,*cur = val
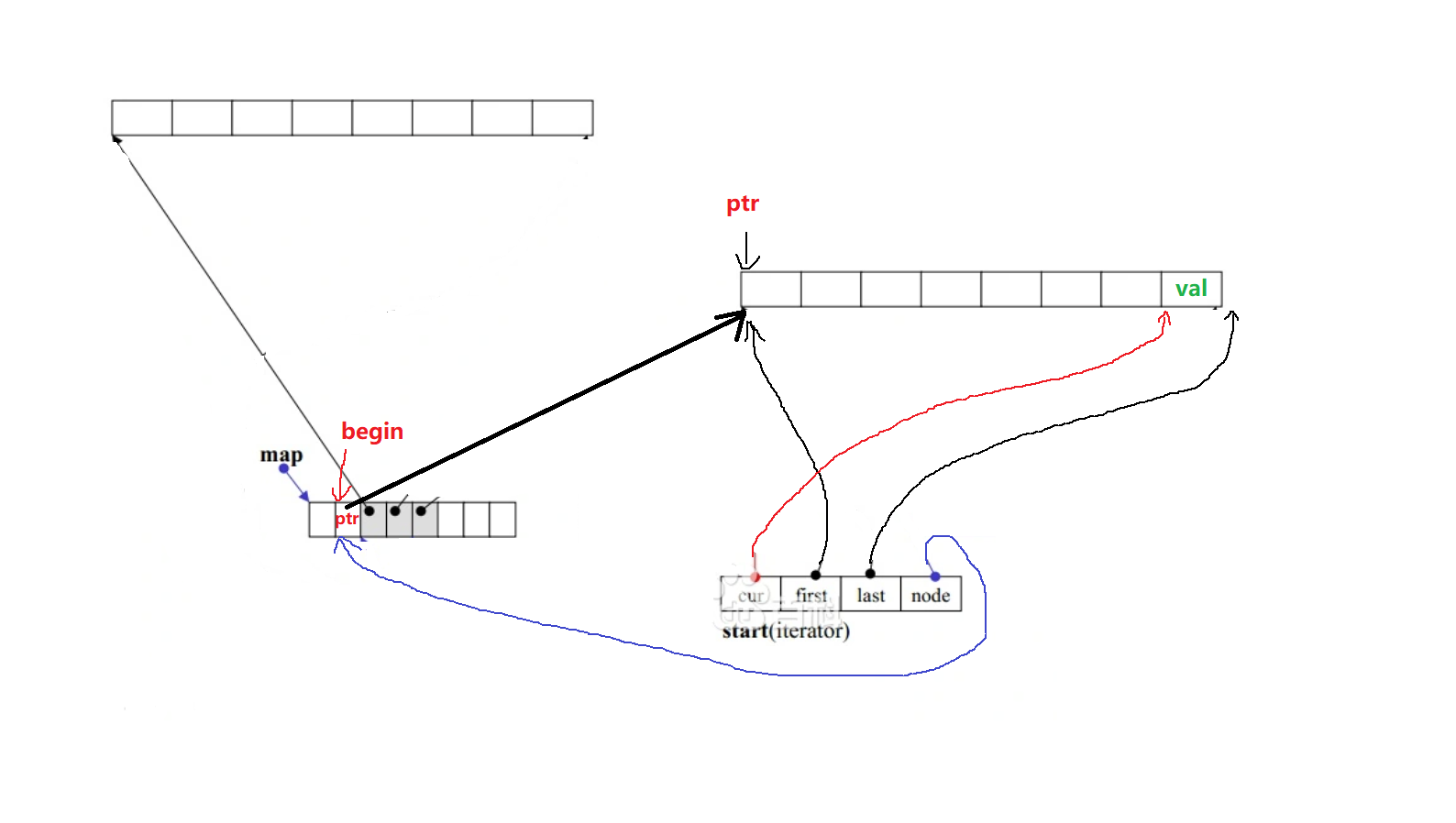
deque的pop_back, pop_front也是类似的思路,即搞明白是否释放小buffer,以及迭代器参数的调整。
插入操作时,中控数组不一定扩容。
我们可以看到实际存储数据的所有指针,并没有占满map。这种设计减少了map扩容的次数。
4、deque的局限性
至此,我们就比较清楚地认识到,deque的头插、头删、尾插、尾删的时间复杂度都是O(1),效率都比较好。
同时,由于deque有多个空间连续的小buffer,CPU高速缓存命中率也不错。
但是,deque也有缺点:
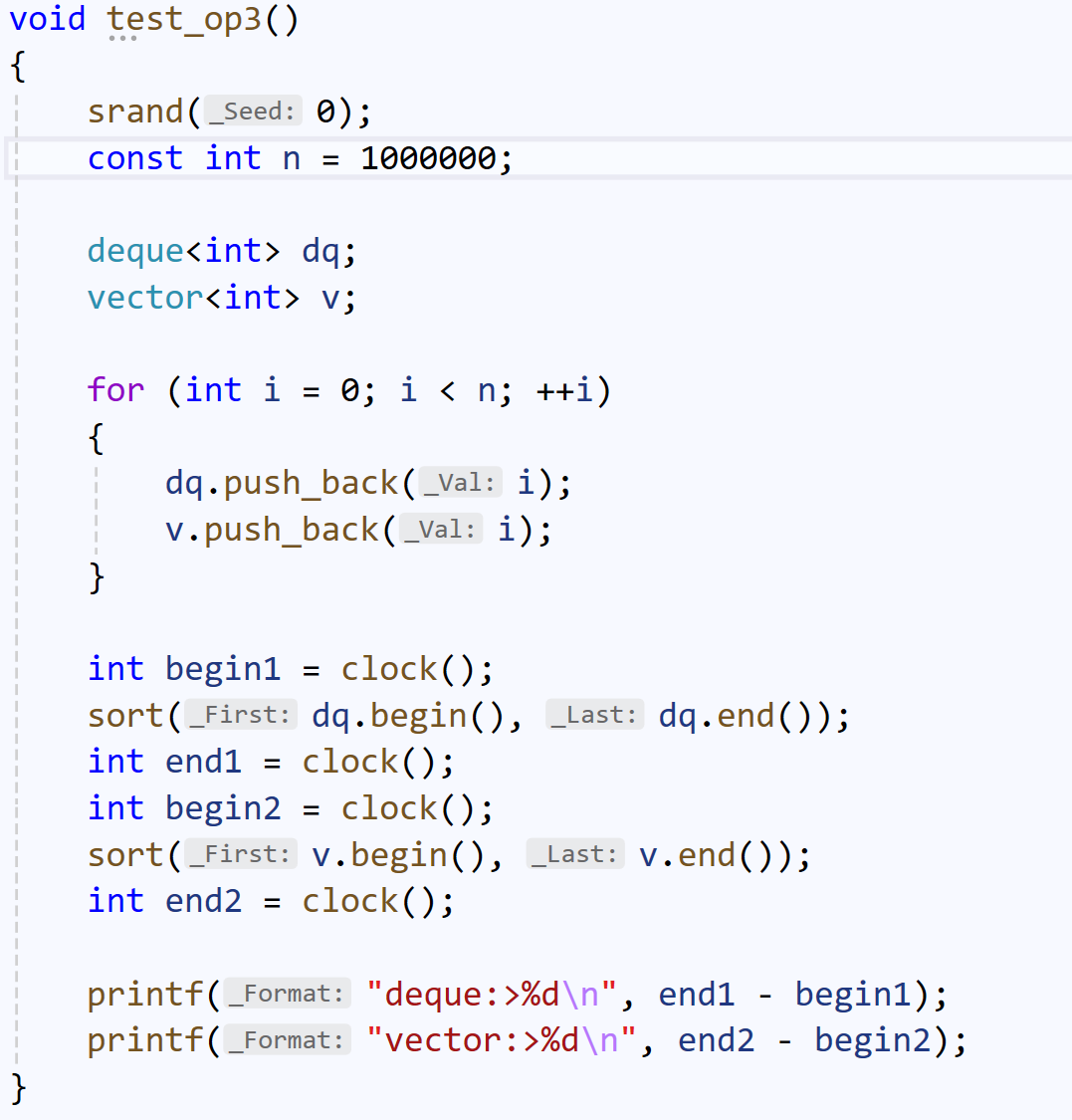
1、deque的随机访问效率不如vector
deque可能存在第一个小buffer还没有填满的情况,这时计算第i个位置就不能直接/10, %10,还需要做特殊处理。
而vector可以直接计算,所以deque的 大量访问,不如vector。
我们可以验证这一点:
2、中间插入、删除效率低。
对于中间的插入、删除,有两种方案:
- 整体挪动,那么时间复杂度为O(N),效率较低。
- 对插入位置所在的小buffer扩容,那么就会影响 访问,因为buffer的长度不固定了,就需要更复杂的计算

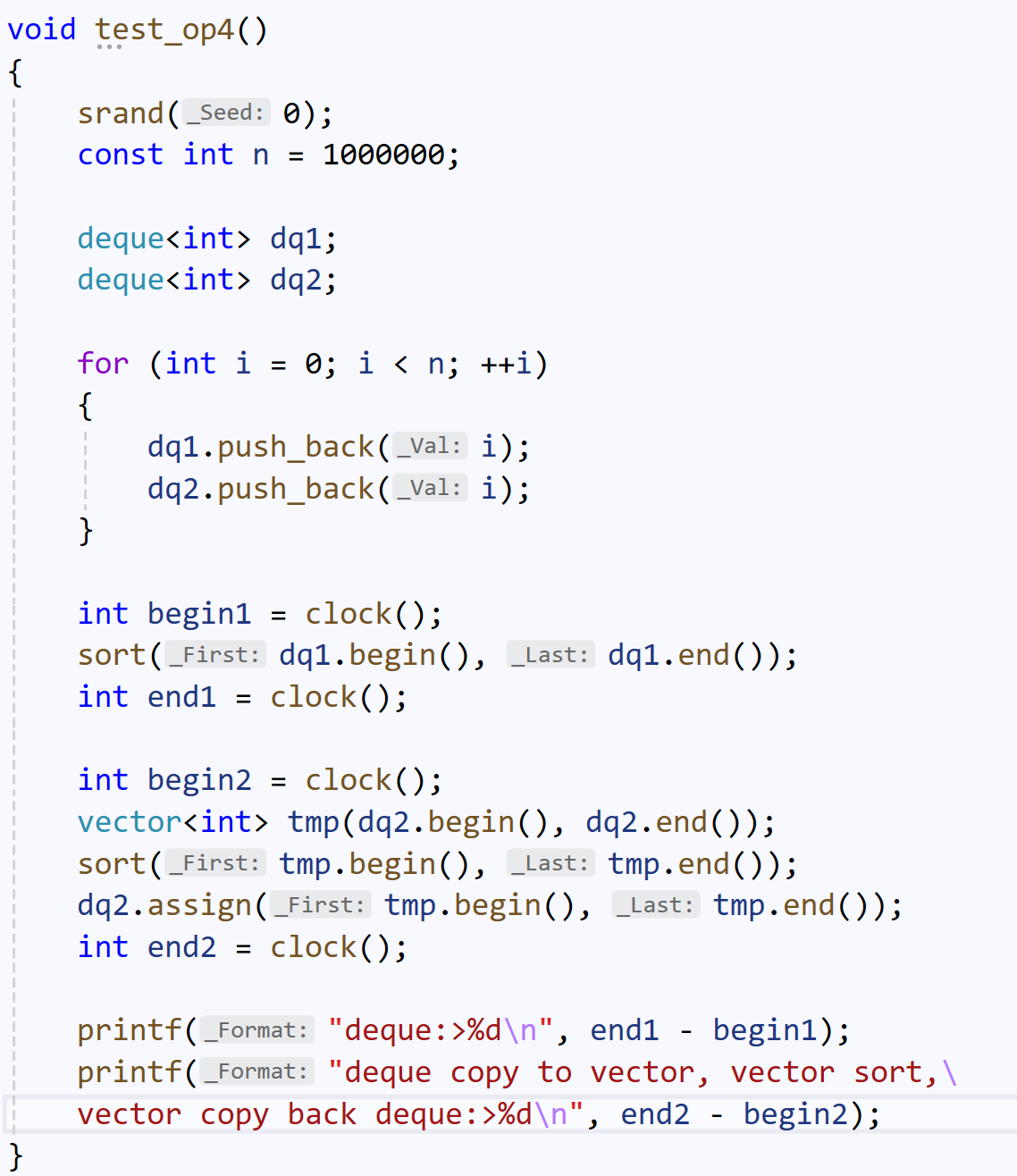

所以,deque最终只能落得个什么都会,什么都不精的下场。
但是deque头插、头删、尾插、尾删的效率高,所以其实际使用场景,就是一些只需要头插、头删、尾插、尾删,且不需要随机访问和中间插入的场景,比如作stack和queue的默认适配容器。