第二十五章:C++11(下)
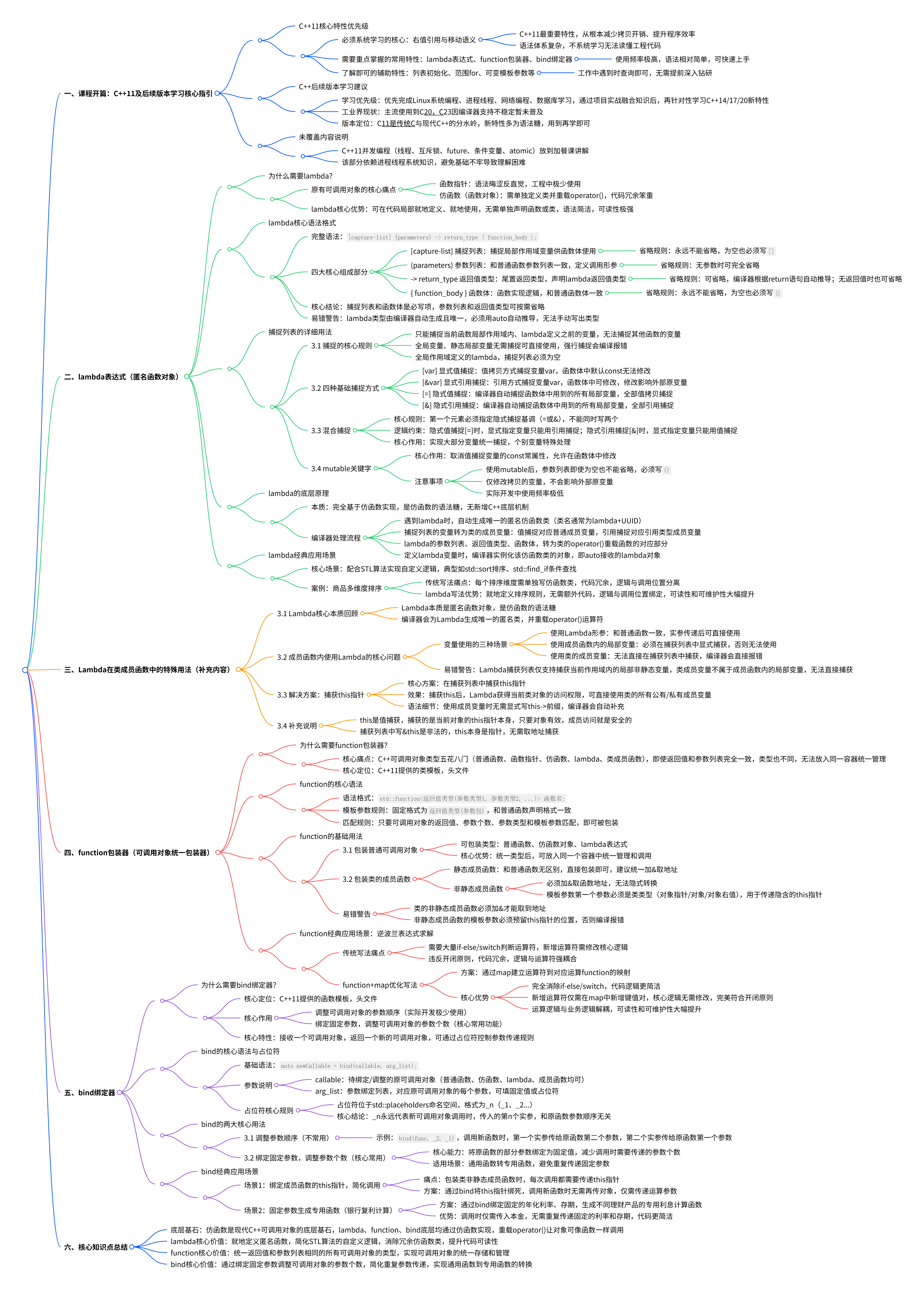
一、课程开篇:C++11及后续版本学习核心指引
1. C++11核心特性优先级
- 必须系统学习的核心 :右值引用与移动语义,是C++11最重要的特性,属于雪中送炭的语法,从根本上减少了C++的拷贝开销,提升了程序效率,且语法体系复杂,不系统学习无法读懂工程代码。
- 需要重点掌握的常用特性:lambda表达式、function包装器、bind绑定器,使用频率极高,语法相对简单,可快速上手。
- 了解即可的辅助特性:列表初始化、范围for、可变模板参数等,工作中遇到时结合AI快速查询即可,无需提前深入钻研。
2. C++后续版本学习建议
- C++14/17/20暂时无需作为学习重点,优先完成Linux系统编程、进程线程、网络编程、数据库的学习,通过项目实战将已有知识融合,再针对性学习C++新特性。
- 工业界目前主流使用到C++20,C++23因编译器支持不稳定暂未普及,新特性大多是语法糖,工作中用到时再学习完全足够。
- C++11是传统C++与现代C++的分水岭,C++11及之后的语法风格更贴近现代化编程语言,和C++98/03的传统写法有明显区别。
3. 未覆盖内容说明
C++11的并发编程(线程、互斥锁、future、条件变量、atomic)放到加餐课讲解,该部分依赖进程线程的系统知识,避免基础不牢导致理解困难。
二、lambda表达式(匿名函数对象)
1. 为什么需要lambda?
在lambda出现之前,C++的可调用对象只有两类,均存在明显痛点:
- 函数指针:语法晦涩难懂,定义格式与常规类型完全不同,是C++中最反直觉的语法之一,工程中不到万不得已不会使用。
- 仿函数(函数对象) :需要单独定义一个类并重载
operator(),哪怕只需要一个简单的逻辑,也要写完整的类结构,代码冗余、过于笨重。
lambda表达式完美解决了上述问题,它可以在代码局部就地定义、就地使用,无需单独声明函数或类,语法简洁,可读性极强。
2. lambda表达式的核心语法格式
lambda是C++11引入的匿名函数对象,完整语法格式如下:
cpp
[capture-list] (parameters) -> return_type { function_body };四个核心组成部分详解:
| 组成部分 | 说明 | 省略规则 |
|---|---|---|
| capture-list 捕捉列表 | 用于捕捉当前局部作用域的变量,供lambda函数体使用,是lambda最特殊的部分 | 永远不能省略 ,哪怕为空也必须写[] |
| (parameters) 参数列表 | 和普通函数的参数列表一致,定义调用时需要传入的形参 | 无参数时可以完全省略 |
| -> return_type 返回值类型 | 尾置返回类型,声明lambda的返回值类型 | 可省略,编译器会根据函数体中的return语句自动推导;无返回值时也可省略 |
| { function_body } 函数体 | 函数的实现逻辑,和普通函数体完全一致 | 永远不能省略 ,哪怕为空也要写{} |
核心结论:lambda表达式中,捕捉列表和函数体是必写项,参数列表和返回值类型可根据场景省略。
基础用法代码示例
cpp
#include <iostream>
using namespace std;
int main()
{
// 完整写法:两数相加的lambda
auto addFunc = [](int a, int b)->int { return a + b; };
cout << addFunc(1, 2) << endl; // 输出3
// 省略返回值类型:编译器自动推导返回int
auto addFunc2 = [](int a, int b) { return a + b; };
cout << addFunc2(3, 4) << endl; // 输出7
// 省略参数列表和返回值:无参无返回值
auto sayHello = [] { cout << "hello C++11" << endl; };
sayHello(); // 输出hello C++11
// 两数交换的lambda
int a = 0, b = 1;
auto swapFunc = [](int& x, int& y) {
int tmp = x;
x = y;
y = tmp;
};
swapFunc(a, b);
cout << a << ":" << b << endl; // 输出1:0
return 0;
}易错警告:lambda的类型由编译器自动生成,且每个lambda的类型都是唯一的,我们无法手动写出,必须使用
auto让编译器自动推导,也可以传给模板参数或用decltype获取类型。
3. 捕捉列表的详细用法
捕捉列表是lambda的核心,解决了「lambda函数体想使用外部局部作用域变量」的问题,无需通过参数传递,直接捕捉即可使用。
3.1 捕捉的核心规则
- lambda只能捕捉当前函数局部作用域内、lambda定义之前的变量,无法捕捉其他函数的变量。
- 全局变量、静态局部变量无需捕捉,可直接在lambda函数体中使用,强行捕捉反而会编译报错。
- lambda表达式如果定义在全局作用域,捕捉列表必须为空(无局部变量可捕捉)。
3.2 捕捉的四种基础方式
| 捕捉写法 | 类型 | 说明 |
|---|---|---|
[var] |
显式值捕捉 | 以值拷贝的方式捕捉变量var,函数体中无法修改该变量(默认被const修饰) |
[&var] |
显式引用捕捉 | 以引用的方式捕捉变量var,函数体中可修改该变量,且修改会影响外部原变量 |
[=] |
隐式值捕捉 | 编译器自动捕捉lambda函数体中用到的所有局部变量,全部以值拷贝的方式捕捉 |
[&] |
隐式引用捕捉 | 编译器自动捕捉lambda函数体中用到的所有局部变量,全部以引用的方式捕捉 |
基础捕捉代码示例
cpp
#include <iostream>
using namespace std;
int main()
{
int a = 0, b = 1, c = 2, d = 3;
// 1. 显式值捕捉a,显式引用捕捉b
auto func1 = [a, &b] {
// a++; 报错:值捕捉的变量默认是const,无法修改
b++; // 引用捕捉可修改,影响外部的b
return a + b;
};
cout << func1() << endl; // 输出0+2=2
cout << "外部b=" << b << endl; // 输出b=2
// 2. 隐式值捕捉:用到a、b、c,自动捕捉,未用到的d不捕捉
auto func2 = [=] {
return a + b + c;
};
cout << func2() << endl; // 输出0+2+2=4
// 3. 隐式引用捕捉:用到a、c、d,自动引用捕捉
auto func3 = [&] {
a++;
c++;
d++;
};
func3();
cout << a << " " << b << " " << c << " " << d << endl; // 输出1 2 3 4
return 0;
}3.3 混合捕捉
混合隐式捕捉+显式捕捉,可实现「大部分变量统一捕捉,个别变量特殊处理」,核心规则:
- 混合捕捉时,第一个元素必须指定隐式捕捉的基调(
=或&),不能同时写两个。 - 逻辑不能自相矛盾:隐式值捕捉
[=]时,显式指定的变量只能用引用捕捉;隐式引用捕捉[&]时,显式指定的变量只能用值捕捉。
cpp
#include <iostream>
using namespace std;
int main()
{
int a = 0, b = 1, c = 2, d = 3;
// 混合捕捉:所有变量默认值捕捉,唯独b用引用捕捉
auto func4 = [=, &b] {
// a++; 报错:值捕捉默认const
b++;
c++; // 报错:值捕捉默认const
d++; // 报错:值捕捉默认const
};
// 混合捕捉:所有变量默认引用捕捉,唯独a用值捕捉
auto func5 = [&, a] {
// a++; 报错:值捕捉默认const
b++;
c++;
d++;
};
func5();
cout << a << " " << b << " " << c << " " << d << endl; // 输出0 3 4 5
return 0;
}3.4 mutable关键字
值捕捉的变量默认被const修饰,无法在lambda函数体中修改,mutable关键字可以取消值捕捉变量的常属性,核心注意点:
- 使用
mutable后,参数列表即使为空也不能省略 ,必须写()。 - 仅取消值捕捉变量的常属性,变量依旧是外部变量的拷贝,修改后不会影响外部原变量。
- 实际开发中使用频率极低。
cpp
#include <iostream>
using namespace std;
int main()
{
int a = 0, b = 1;
// mutable取消值捕捉的const属性,参数列表()不可省略
auto func6 = [a, &b]() mutable {
a++; // 不再报错,修改的是拷贝的a
b++;
cout << "lambda内a=" << a << endl; // 输出a=1
};
func6();
cout << "外部a=" << a << endl; // 输出a=0,外部原变量不受影响
cout << "外部b=" << b << endl; // 输出b=2,引用捕捉受影响
return 0;
}4. lambda的底层原理
lambda表达式底层没有新增任何C++机制,完全基于仿函数实现,编译器对lambda的处理流程如下:
- 遇到lambda表达式时,编译器会自动生成一个唯一的、匿名的仿函数类 ,类名通常是
lambda+UUID(UUID是唯一标识符,保证不同lambda的类名不冲突)。 - 捕捉列表中的变量,会变成该仿函数类的成员变量:值捕捉对应普通成员变量,引用捕捉对应引用类型的成员变量。
- lambda的参数列表、返回值类型、函数体,会变成该仿函数类的
operator()重载函数的对应部分。 - 定义lambda变量时,编译器会实例化该仿函数类的一个对象,这就是我们用
auto接收的lambda对象。
核心结论:lambda本质上就是编译器帮我们自动生成了一个仿函数类并实例化对象,和我们手动写仿函数的效果完全一致,只是语法上做了极致简化。
5. lambda的经典应用场景
lambda最核心的应用场景是配合STL算法,实现自定义的逻辑,最典型的就是std::sort排序、std::find_if条件查找。
场景1:商品多维度排序
传统写法需要为每个排序维度写一个单独的仿函数,代码冗余且可读性差;lambda可以就地定义排序规则,代码简洁且逻辑一目了然。
cpp
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
using namespace std;
// 商品结构体
struct Goods
{
string _name; // 商品名
double _price; // 价格
int _evaluate; // 评价分数
Goods(const char* str, double price, int evaluate)
:_name(str), _price(price), _evaluate(evaluate)
{}
};
// 传统写法:价格升序仿函数
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;
}
};
// 传统写法:价格降序仿函数
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
int main()
{
vector<Goods> v = {
{ "苹果", 2.1, 5 },
{ "香蕉", 3, 4 },
{ "橙子", 2.2, 3},
{ "菠萝", 1.5, 4 }
};
// 传统写法:传仿函数
sort(v.begin(), v.end(), ComparePriceLess());
// 现代写法:lambda实现价格升序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price < g2._price;
});
// lambda实现价格降序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price > g2._price;
});
// lambda实现评价升序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate < g2._evaluate;
});
// lambda实现评价降序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate > g2._evaluate;
});
return 0;
}优势对比:传统写法需要为每个排序规则写一个完整的仿函数类,而lambda直接在sort函数内定义规则,无需额外代码,逻辑和调用位置绑定,可读性拉满。
三、 Lambda在类成员函数中的特殊用法(补充内容)
3.1 Lambda核心本质回顾
Lambda的本质是一个匿名函数对象 ,是仿函数的语法糖,编译器会为Lambda表达式生成一个唯一的匿名类,并重载operator()运算符。
3.2 成员函数内使用Lambda的核心问题
在成员函数内部编写Lambda时,变量的使用分为三种场景,前两种与全局Lambda规则一致,第三种是核心难点:
- 使用Lambda形参:和普通函数一致,实参传递给形参后可直接使用,无需额外处理。
- 使用成员函数内的局部变量:必须在Lambda的捕获列表中显式捕获该局部变量,否则无法使用。
- 使用类的成员变量 :无法直接在捕获列表中捕获类的成员变量,编译器会直接报错。
【易错警告】Lambda的捕获列表,仅支持捕获当前作用域内的局部非静态变量,类的成员变量不属于成员函数内的局部变量,因此无法直接捕获。
3.3 解决方案:捕获this指针
针对成员函数内Lambda无法访问类成员变量的问题,C++提供了标准解决方案:在捕获列表中捕获this指针。
- 捕获this指针后,Lambda获得当前类对象的访问权限,可直接使用类的所有成员变量(公有/私有均可)。
- 使用成员变量时,无需显式书写
this->前缀,编译器会自动补充,代码更简洁。
3.4 完整可运行代码示例
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
class A
{
public:
void f()
{
// 成员函数内的局部变量
int i = 10;
// 核心:捕获this指针 + 局部变量i
// 捕获this后,可直接使用成员变量_a1、_a2
auto add1 = [this, i](int x, int y)->int {
return x + y + i + _a1 + _a2;
};
cout << add1(1, 2) << endl;
}
private:
// 类的成员变量
int _a1 = 1;
int _a2 = 2;
};
int main()
{
A().f(); // 输出结果:16 (1+2+10+1+2)
return 0;
}【补充说明】
- 捕获列表中的
this是值捕获,捕获的是当前对象的this指针本身,只要this指向的对象有效,Lambda内的成员变量访问就是安全的。 - 捕获列表中写
&this是非法的,this本身就是指针,无需再取地址捕获。
四、function包装器(可调用对象统一包装器)
1. 为什么需要function包装器?
C++中的可调用对象类型五花八门:普通函数、函数指针、仿函数对象、lambda表达式、类的成员函数,它们的类型完全不同,即使返回值和参数列表完全一致,也无法放到同一个容器中统一管理。
std::function是C++11提供的类模板 ,头文件<functional>,它可以把返回值和参数列表相同的所有可调用对象,包装成统一的function类型,解决了可调用对象类型不统一的问题。
2. function的核心语法
cpp
#include <functional>
// 语法格式
std::function<返回值类型(参数类型1, 参数类型2, ...)> 函数名;- 模板参数是固定格式:
返回值类型(参数包),和普通函数的声明格式一致。 - 只要可调用对象的返回值、参数个数、参数类型和模板参数匹配,就可以被该function对象包装。
3. function的基础用法
3.1 包装普通可调用对象
cpp
#include <iostream>
#include <functional>
#include <vector>
using namespace std;
// 1. 普通函数
int f(int a, int b)
{
return a + b;
}
// 2. 仿函数类
struct Functor
{
int operator() (int a, int b)
{
return (a + b) * 10;
}
};
int main()
{
// 包装普通函数
function<int(int, int)> f1 = f;
cout << f1(1, 2) << endl; // 输出3
// 包装仿函数对象
function<int(int, int)> f2 = Functor();
cout << f2(1, 2) << endl; // 输出30
// 包装lambda表达式
auto lambdaFunc = [](int a, int b) { return (a + b) * 20; };
function<int(int, int)> f3 = lambdaFunc;
cout << f3(1, 2) << endl; // 输出60
// 核心优势:统一类型后,可放入同一个容器
vector<function<int(int, int)>> funcV = { f, Functor(), lambdaFunc };
for (auto& func : funcV)
{
cout << func(1, 2) << endl; // 依次输出3、30、60
}
return 0;
}3.2 包装类的成员函数
包装类的成员函数有特殊规则,核心是处理隐含的this指针:
- 静态成员函数:和普通函数无区别,直接包装即可,建议统一加
&取地址。 - 非静态成员函数:第一个参数必须是类类型(对象指针/对象/对象右值),用于传递this指针,且必须加
&取函数地址。
cpp
#include <iostream>
#include <functional>
using namespace std;
class Plus
{
public:
Plus(int n = 10) :_n(n) {}
// 静态成员函数
static int plusi(int a, int b)
{
return a + b;
}
// 非静态成员函数
double plusd(double a, double b)
{
return (a + b) * _n;
}
private:
int _n;
};
int main()
{
// 包装静态成员函数
function<int(int, int)> f4 = &Plus::plusi;
cout << f4(1, 1) << endl; // 输出2
// 包装非静态成员函数:第一个参数为对象指针
function<double(Plus*, double, double)> f5 = &Plus::plusd;
Plus ps;
cout << f5(&ps, 1.1, 1.1) << endl; // 输出(1.1+1.1)*10=22
// 包装非静态成员函数:第一个参数为对象右值
function<double(Plus&&, double, double)> f6 = &Plus::plusd;
cout << f6(Plus(), 1.1, 1.1) << endl; // 输出22
return 0;
}易错警告:
- 类的非静态成员函数必须加
&才能取到地址,普通函数名可隐式转为函数地址,成员函数不行。- 非静态成员函数的模板参数中,必须预留this指针的位置,否则类型不匹配编译报错。
4. function的经典应用场景:逆波兰表达式求解
逆波兰表达式(后缀表达式)求解是经典的栈应用题,传统写法需要大量if-else/switch判断运算符,新增运算符时需要修改核心逻辑;使用function+map可以实现运算符和运算逻辑的解耦,新增运算符无需修改核心代码。
步骤1:传统写法的痛点
cpp
#include <iostream>
#include <vector>
#include <stack>
#include <string>
using namespace std;
// 传统写法
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
for (auto& str : tokens) {
// 判断是运算符还是操作数
if (str == "+" || str == "-" || str == "*" || str == "/") {
// 取栈顶两个操作数,注意顺序:先出的是右操作数
int right = st.top();
st.pop();
int left = st.top();
st.pop();
// 大量if-else判断运算符,新增运算符需要修改这里
switch (str[0]) {
case '+': st.push(left + right); break;
case '-': st.push(left - right); break;
case '*': st.push(left * right); break;
case '/': st.push(left / right); break;
}
}
else {
// 操作数入栈
st.push(stoi(str));
}
}
return st.top();
}
};痛点:每新增一个运算符(如%、&、|),都需要修改switch语句,违反开闭原则;代码冗余,逻辑和运算符强耦合。
步骤2:function+map优化写法
cpp
#include <iostream>
#include <vector>
#include <stack>
#include <string>
#include <map>
#include <functional>
using namespace std;
// 优化写法
class Solution {
public:
int evalRPN(vector<string>& tokens) {
// 建立运算符到对应运算函数的映射,统一用function包装
map<string, function<int(int, int)>> opFuncMap = {
{"+", [](int a, int b) {return a + b; }},
{"-", [](int a, int b) {return a - b; }},
{"*", [](int a, int b) {return a * b; }},
{"/", [](int a, int b) {return a / b; }}
};
stack<int> st;
for (auto& str : tokens) {
// 判断是否为运算符
if (opFuncMap.count(str)) {
int right = st.top();
st.pop();
int left = st.top();
st.pop();
// 直接通过map找到对应运算函数,无需if-else
st.push(opFuncMap[str](left, right));
}
else {
st.push(stoi(str));
}
}
return st.top();
}
};核心优势:
- 完全消除了if-else/switch,代码逻辑更简洁。
- 新增运算符时,只需要在map中新增一行键值对,核心逻辑完全不用修改,完美符合开闭原则。
- 运算逻辑和业务逻辑解耦,可读性和可维护性大幅提升。
五、bind绑定器
1. 为什么需要bind绑定器?
std::bind是C++11提供的函数模板 ,头文件<functional>,它本质是一个函数适配器,核心作用有两个:
- 调整可调用对象的参数顺序(实际开发中使用极少)。
- 绑定固定参数,调整可调用对象的参数个数(核心常用功能)。
bind接收一个可调用对象,返回一个新的可调用对象,我们可以通过占位符控制新可调用对象的参数传递规则。
2. bind的核心语法与占位符
2.1 基础语法
cpp
#include <functional>
using namespace std::placeholders; // 占位符所在命名空间
// 语法格式
auto newCallable = bind(callable, arg_list);callable:需要被绑定/调整的原可调用对象(普通函数、仿函数、lambda、成员函数均可)。arg_list:参数绑定列表,对应原可调用对象的每一个参数,可填:- 固定值:将原参数绑定为固定值,调用新可调用对象时无需传递。
- 占位符
_n:_1代表新可调用对象的第1个实参,_2代表第2个实参,以此类推。
2.2 占位符核心规则
老师反复强调的核心结论:
_n永远代表新可调用对象调用时,传入的第n个实参 ,和原函数的参数顺序无关。例如:
bind(func, _2, _1),调用新函数时,第一个实参会传给原函数的第二个参数,第二个实参会传给原函数的第一个参数。
3. bind的两大核心用法
3.1 调整参数顺序(不常用)
cpp
#include <iostream>
#include <functional>
using namespace std;
using namespace placeholders;
// 原函数:两数相减
int Sub(int a, int b)
{
return (a - b) * 10;
}
int main()
{
cout << Sub(1, 2) << endl; // 原调用:(1-2)*10 = -10
// 调整参数顺序:原函数a接收新函数的第二个参数,b接收第一个参数
auto bSub1 = bind(Sub, _2, _1);
cout << bSub1(1, 2) << endl; // 等价于Sub(2,1) = (2-1)*10=10
return 0;
}3.2 绑定固定参数,调整参数个数(核心常用)
这是bind最核心的用途,将原函数的部分参数绑定为固定值,减少调用时需要传递的参数个数。
cpp
#include <iostream>
#include <functional>
using namespace std;
using namespace placeholders;
int Sub(int a, int b)
{
return (a - b) * 10;
}
// 三参数函数
int SubX(int a, int b, int c)
{
return (a - b - c) * 10;
}
int main()
{
// 1. 绑定第二个参数为10,新函数只需要传第一个参数
auto bSub2 = bind(Sub, _1, 10);
cout << bSub2(1) << endl; // 等价于Sub(1,10) = (1-10)*10=-90
// 2. 绑定第一个参数为10,新函数只需要传第二个参数
auto bSub3 = bind(Sub, 10, _1);
cout << bSub3(1) << endl; // 等价于Sub(10,1) = (10-1)*10=90
// 3. 多参数函数绑定:绑死第一个参数为100,新函数传后两个参数
auto sub5 = bind(SubX, 100, _1, _2);
cout << sub5(5, 1) << endl; // 等价于SubX(100,5,1) = (100-5-1)*10=940
// 4. 多参数函数绑定:绑死第二个参数为100,新函数传第一、第三个参数
auto sub6 = bind(SubX, _1, 100, _2);
cout << sub6(5, 1) << endl; // 等价于SubX(5,100,1) = (5-100-1)*10=-960
// 5. 多参数函数绑定:绑死第三个参数为100,新函数传前两个参数
auto sub7 = bind(SubX, _1, _2, 100);
cout << sub7(5, 1) << endl; // 等价于SubX(5,1,100) = (5-1-100)*10=-960
return 0;
}4. bind的经典应用场景
场景1:绑定成员函数的this指针,简化调用
包装类的非静态成员函数时,每次调用都需要传递this指针,使用bind可以将this指针绑死,调用时无需再传,大幅简化代码。
cpp
#include <iostream>
#include <functional>
using namespace std;
using namespace placeholders;
class Plus
{
public:
Plus(int n = 10) :_n(n) {}
double plusd(double a, double b)
{
return (a + b) * _n;
}
private:
int _n;
};
int main()
{
Plus pd;
// 未绑定:每次调用都需要传对象
function<double(Plus&&, double, double)> f6 = &Plus::plusd;
cout << f6(Plus(), 1.1, 1.1) << endl; // 必须传对象
// bind绑定this指针,新函数只需要传两个运算参数
auto f7 = bind(&Plus::plusd, Plus(), _1, _2);
auto f7 = bind(&Plus::plusd, Plus(), _1, _2);
//相当于:function<double(double, double)> f7 = bind(&Plus::plusd, Plus(), _1, _2);
cout << f7(1.1, 1.1) << endl; // 无需再传对象,直接传运算参数
cout << f7(2.2, 1.1) << endl; // 等价于Plus().plusd(2.2,1.1)=33
return 0;
}场景2:固定参数生成专用函数(银行复利计算)
通过bind绑定固定的利率和存期,生成不同理财产品的专用计算函数,无需每次调用都传递重复的固定参数。
cpp
#include <iostream>
#include <functional>
using namespace std;
using namespace placeholders;
int main()
{
// 通用复利计算lambda:参数为【年化利率、本金、存期】,返回总利息
auto calcCompoundInterest = [](double rate, double money, int year)->double {
double ret = money;
for (int i = 0; i < year; i++)
{
ret += ret * rate; // 复利:本年利息计入下一年本金
}
return ret - money; // 返回总利息
};
// 绑定固定利率和存期,生成不同理财产品的计算函数
// 3年期,年化2.5%,仅需传入本金
function<double(double)> func3_2_5 = bind(calcCompoundInterest, 0.025, _1, 3);
// 5年期,年化2.5%,仅需传入本金
function<double(double)> func5_2_5 = bind(calcCompoundInterest, 0.025, _1, 5);
// 10年期,年化2.5%,仅需传入本金
function<double(double)> func10_2_5 = bind(calcCompoundInterest, 0.025, _1, 10);
// 200年期,年化2.5%,仅需传入本金
function<double(double)> func200_2_5 = bind(calcCompoundInterest, 0.025, _1, 200);
// 计算100万本金在不同存期的利息
double principal = 1000000;
cout << "3年期利息:" << func3_2_5(principal) << endl;
cout << "5年期利息:" << func5_2_5(principal) << endl;
cout << "10年期利息:" << func10_2_5(principal) << endl;
cout << "200年期利息:" << func200_2_5(principal) << endl;
return 0;
}补充说明(复利的力量):
单利计算:100万,年化2.5%,200年利息=100万 * 2.5% * 200 = 500万。
复利计算:100万,年化2.5%,200年利息约1.38亿,是单利的27倍,这就是巴菲特所说的「复利的力量」。
六、核心知识点总结
- 仿函数是现代C++可调用对象的底层基石 :lambda表达式、function包装器、bind绑定器,底层最终都是通过仿函数实现的,重载
operator()让对象可以像函数一样调用。 - lambda核心价值:就地定义匿名函数,简化STL算法的自定义逻辑,消除冗余的仿函数类,提升代码可读性。
- function核心价值:统一返回值和参数列表相同的所有可调用对象的类型,实现可调用对象的统一存储和管理。
- bind核心价值:通过绑定固定参数,调整可调用对象的参数个数,简化重复参数的传递,实现通用函数到专用函数的转换。